 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNOAir: A Neural Operator for Forecasting Carbon Monoxide Evolution in Cities
Jan 13, 2025



Carbon Monoxide (CO) is a dominant pollutant in urban areas due to the energy generation from fossil fuels for industry, automobile, and domestic requirements. Forecasting the evolution of CO in real-time can enable the deployment of effective early warning systems and intervention strategies. However, the computational cost associated with the physics and chemistry-based simulation makes it prohibitive to implement such a model at the city and country scale. To address this challenge, here, we present a machine learning model based on neural operator, namely, Complex Neural Operator for Air Quality (CoNOAir), that can effectively forecast CO concentrations. We demonstrate this by developing a country-level model for short-term (hourly) and long-term (72-hour) forecasts of CO concentrations. Our model outperforms state-of-the-art models such as Fourier neural operators (FNO) and provides reliable predictions for both short and long-term forecasts. We further analyse the capability of the model to capture extreme events and generate forecasts in urban cities in India. Interestingly, we observe that the model predicts the next hour CO concentrations with R2 values greater than 0.95 for all the cities considered. The deployment of such a model can greatly assist the governing bodies to provide early warning, plan intervention strategies, and develop effective strategies by considering several what-if scenarios. Altogether, the present approach could provide a fillip to real-time predictions of CO pollution in urban cities.
Guided Prompting in SAM for Weakly Supervised Cell Segmentation in Histopathological Images
Nov 29, 2023Cell segmentation in histopathological images plays a crucial role in understanding, diagnosing, and treating many diseases. However, data annotation for this is expensive since there can be a large number of cells per image, and expert pathologists are needed for labelling images. Instead, our paper focuses on using weak supervision -- annotation from related tasks -- to induce a segmenter. Recent foundation models, such as Segment Anything (SAM), can use prompts to leverage additional supervision during inference. SAM has performed remarkably well in natural image segmentation tasks; however, its applicability to cell segmentation has not been explored. In response, we investigate guiding the prompting procedure in SAM for weakly supervised cell segmentation when only bounding box supervision is available. We develop two workflows: (1) an object detector's output as a test-time prompt to SAM (D-SAM), and (2) SAM as pseudo mask generator over training data to train a standalone segmentation model (SAM-S). On finding that both workflows have some complementary strengths, we develop an integer programming-based approach to reconcile the two sets of segmentation masks, achieving yet higher performance. We experiment on three publicly available cell segmentation datasets namely, ConSep, MoNuSeg, and TNBC, and find that all SAM-based solutions hugely outperform existing weakly supervised image segmentation models, obtaining 9-15 pt Dice gains.
Adversarial Approximate Inference for Speech to Electroglottograph Conversion
Mar 28, 2019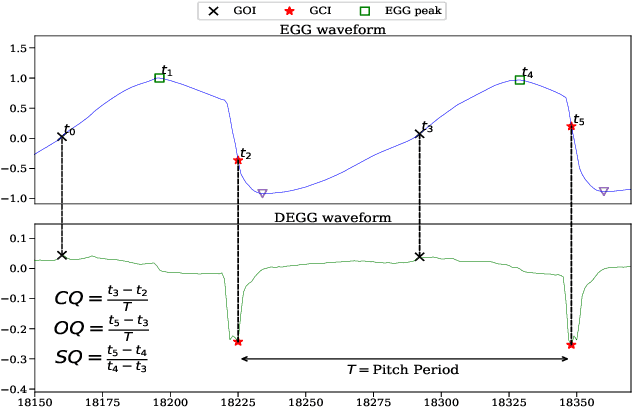
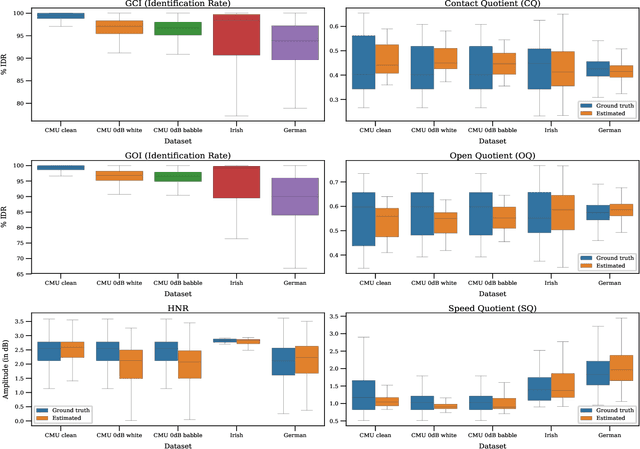

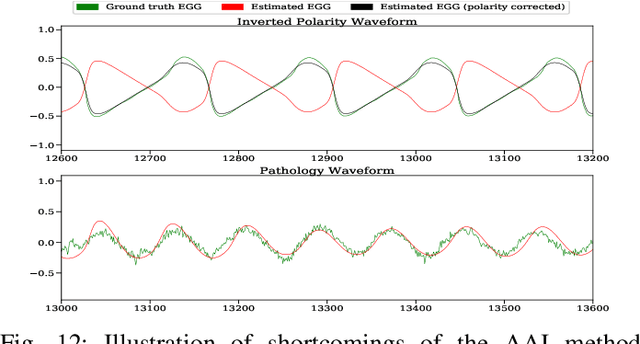
Speech produced by human vocal apparatus conveys substantial non-semantic information including the gender of the speaker, voice quality, affective state, abnormalities in the vocal apparatus etc. Such information is attributed to the properties of the voice source signal, which is usually estimated from the speech signal. However, most of the source estimation techniques depend heavily on the goodness of the model assumptions and are prone to noise. A popular alternative is to indirectly obtain the source information through the Electroglottographic (EGG) signal that measures the electrical admittance around the vocal folds using a dedicated hardware. In this paper, we address the problem of estimating the EGG signal directly from the speech signal, devoid of any hardware. Sampling from the intractable conditional distribution of the EGG signal given the speech signal is accomplished through optimization of an evidence lower bound. This is constructed via minimization of the KL-divergence between the true and the approximated posteriors of a latent variable learned using a deep neural auto-encoder that serves an informative prior which reconstructs the EGG signal. We demonstrate the efficacy of the method to generate EGG signal by conducting several experiments on datasets comprising multiple speakers, voice qualities, noise settings and speech pathologies. The proposed method is evaluated on many benchmark metrics and is found to agree with the gold standards while being better than the state-of-the-art algorithms on a few tasks such as epoch extraction.
Variational Inference with Latent Space Quantization for Adversarial Resilience
Mar 24, 2019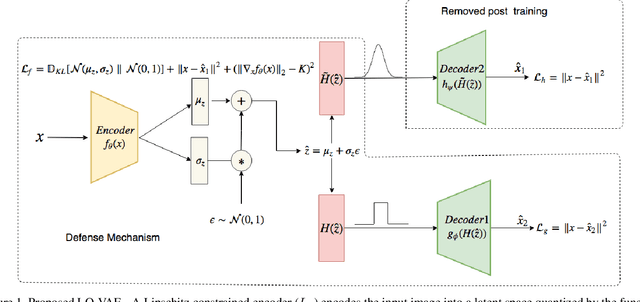
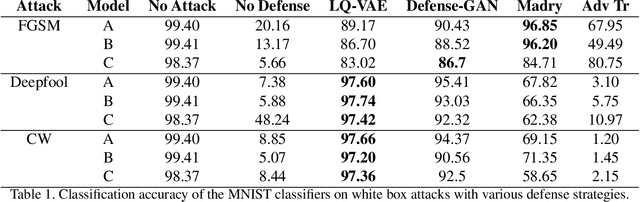
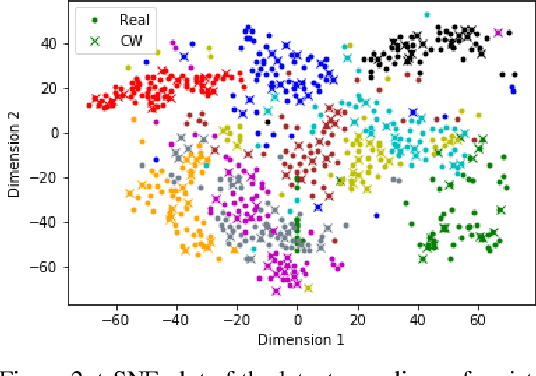
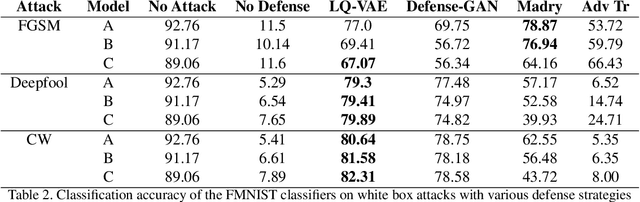
Despite their tremendous success in modelling high-dimensional data manifolds, deep neural networks suffer from the threat of adversarial attacks - Existence of perceptually valid input-like samples obtained through careful perturbations that leads to degradation in the performance of underlying model. Major concerns with existing defense mechanisms include non-generalizability across different attacks, models and large inference time. In this paper, we propose a generalized defense mechanism capitalizing on the expressive power of regularized latent space based generative models. We design an adversarial filter, devoid of access to classifier and adversaries, which makes it usable in tandem with any classifier. The basic idea is to learn a Lipschitz constrained mapping from the data manifold, incorporating adversarial perturbations, to a quantized latent space and re-map it to the true data manifold. Specifically, we simultaneously auto-encode the data manifold and its perturbations implicitly through the perturbations of the regularized and quantized generative latent space, realized using variational inference. We demonstrate the efficacy of the proposed formulation in providing the resilience against multiple attack types (Black and white box) and methods, while being almost real-time. Our experiments show that the proposed method surpasses the state-of-the-art techniques in several cases.