 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Computational Pathology Foundation Models using Representational Similarity Analysis
Sep 18, 2025Foundation models are increasingly developed in computational pathology (CPath) given their promise in facilitating many downstream tasks. While recent studies have evaluated task performance across models, less is known about the structure and variability of their learned representations. Here, we systematically analyze the representational spaces of six CPath foundation models using techniques popularized in computational neuroscience. The models analyzed span vision-language contrastive learning (CONCH, PLIP, KEEP) and self-distillation (UNI (v2), Virchow (v2), Prov-GigaPath) approaches. Through representational similarity analysis using H&E image patches from TCGA, we find that UNI2 and Virchow2 have the most distinct representational structures, whereas Prov-Gigapath has the highest average similarity across models. Having the same training paradigm (vision-only vs. vision-language) did not guarantee higher representational similarity. The representations of all models showed a high slide-dependence, but relatively low disease-dependence. Stain normalization decreased slide-dependence for all models by a range of 5.5% (CONCH) to 20.5% (PLIP). In terms of intrinsic dimensionality, vision-language models demonstrated relatively compact representations, compared to the more distributed representations of vision-only models. These findings highlight opportunities to improve robustness to slide-specific features, inform model ensembling strategies, and provide insights into how training paradigms shape model representations. Our framework is extendable across medical imaging domains, where probing the internal representations of foundation models can help ensure effective development and deployment.
Foundational Large Language Models for Materials Research
Dec 12, 2024



Materials discovery and development are critical for addressing global challenges. Yet, the exponential growth in materials science literature comprising vast amounts of textual data has created significant bottlenecks in knowledge extraction, synthesis, and scientific reasoning. Large Language Models (LLMs) offer unprecedented opportunities to accelerate materials research through automated analysis and prediction. Still, their effective deployment requires domain-specific adaptation for understanding and solving domain-relevant tasks. Here, we present LLaMat, a family of foundational models for materials science developed through continued pretraining of LLaMA models on an extensive corpus of materials literature and crystallographic data. Through systematic evaluation, we demonstrate that LLaMat excels in materials-specific NLP and structured information extraction while maintaining general linguistic capabilities. The specialized LLaMat-CIF variant demonstrates unprecedented capabilities in crystal structure generation, predicting stable crystals with high coverage across the periodic table. Intriguingly, despite LLaMA-3's superior performance in comparison to LLaMA-2, we observe that LLaMat-2 demonstrates unexpectedly enhanced domain-specific performance across diverse materials science tasks, including structured information extraction from text and tables, more particularly in crystal structure generation, a potential adaptation rigidity in overtrained LLMs. Altogether, the present work demonstrates the effectiveness of domain adaptation towards developing practically deployable LLM copilots for materials research. Beyond materials science, our findings reveal important considerations for domain adaptation of LLMs, such as model selection, training methodology, and domain-specific performance, which may influence the development of specialized scientific AI systems.
MeasureNet: Measurement Based Celiac Disease Identification
Dec 02, 2024



Celiac disease is an autoimmune disorder triggered by the consumption of gluten. It causes damage to the villi, the finger-like projections in the small intestine that are responsible for nutrient absorption. Additionally, the crypts, which form the base of the villi, are also affected, impairing the regenerative process. The deterioration in villi length, computed as the villi-to-crypt length ratio, indicates the severity of celiac disease. However, manual measurement of villi-crypt length can be both time-consuming and susceptible to inter-observer variability, leading to inconsistencies in diagnosis. While some methods can perform measurement as a post-hoc process, they are prone to errors in the initial stages. This gap underscores the need for pathologically driven solutions that enhance measurement accuracy and reduce human error in celiac disease assessments. Our proposed method, MeasureNet, is a pathologically driven polyline detection framework incorporating polyline localization and object-driven losses specifically designed for measurement tasks. Furthermore, we leverage segmentation model to provide auxiliary guidance about crypt location when crypt are partially visible. To ensure that model is not overdependent on segmentation mask we enhance model robustness through a mask feature mixup technique. Additionally, we introduce a novel dataset for grading celiac disease, consisting of 750 annotated duodenum biopsy images. MeasureNet achieves an 82.66% classification accuracy for binary classification and 81% accuracy for multi-class grading of celiac disease. Code: https://github.com/dair-iitd/MeasureNet
Guided Prompting in SAM for Weakly Supervised Cell Segmentation in Histopathological Images
Nov 29, 2023Cell segmentation in histopathological images plays a crucial role in understanding, diagnosing, and treating many diseases. However, data annotation for this is expensive since there can be a large number of cells per image, and expert pathologists are needed for labelling images. Instead, our paper focuses on using weak supervision -- annotation from related tasks -- to induce a segmenter. Recent foundation models, such as Segment Anything (SAM), can use prompts to leverage additional supervision during inference. SAM has performed remarkably well in natural image segmentation tasks; however, its applicability to cell segmentation has not been explored. In response, we investigate guiding the prompting procedure in SAM for weakly supervised cell segmentation when only bounding box supervision is available. We develop two workflows: (1) an object detector's output as a test-time prompt to SAM (D-SAM), and (2) SAM as pseudo mask generator over training data to train a standalone segmentation model (SAM-S). On finding that both workflows have some complementary strengths, we develop an integer programming-based approach to reconcile the two sets of segmentation masks, achieving yet higher performance. We experiment on three publicly available cell segmentation datasets namely, ConSep, MoNuSeg, and TNBC, and find that all SAM-based solutions hugely outperform existing weakly supervised image segmentation models, obtaining 9-15 pt Dice gains.
3MASSIV: Multilingual, Multimodal and Multi-Aspect dataset of Social Media Short Videos
Mar 28, 2022
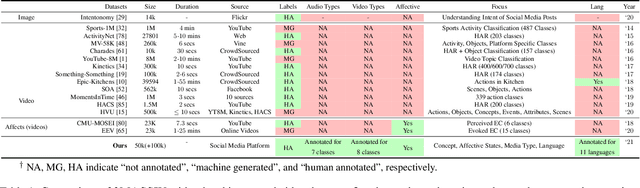

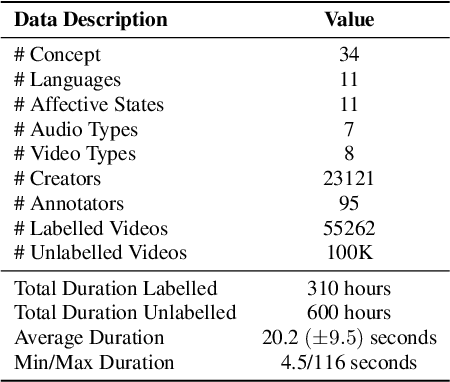
We present 3MASSIV, a multilingual, multimodal and multi-aspect, expertly-annotated dataset of diverse short videos extracted from short-video social media platform - Moj. 3MASSIV comprises of 50k short videos (20 seconds average duration) and 100K unlabeled videos in 11 different languages and captures popular short video trends like pranks, fails, romance, comedy expressed via unique audio-visual formats like self-shot videos, reaction videos, lip-synching, self-sung songs, etc. 3MASSIV presents an opportunity for multimodal and multilingual semantic understanding on these unique videos by annotating them for concepts, affective states, media types, and audio language. We present a thorough analysis of 3MASSIV and highlight the variety and unique aspects of our dataset compared to other contemporary popular datasets with strong baselines. We also show how the social media content in 3MASSIV is dynamic and temporal in nature, which can be used for semantic understanding tasks and cross-lingual analysis.
Few-shot Visual Relationship Co-localization
Aug 26, 2021
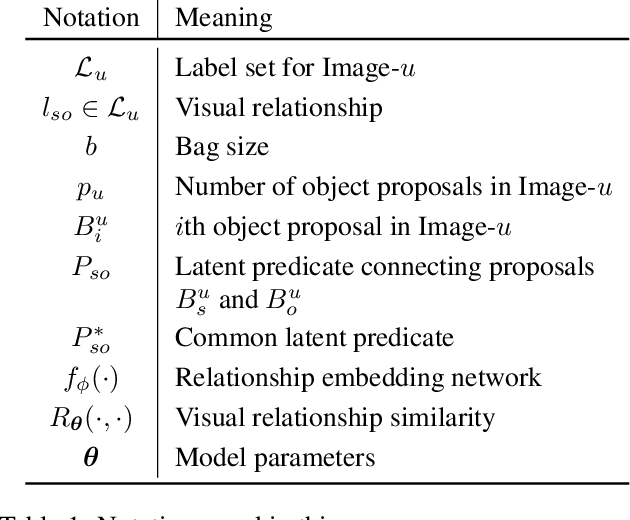
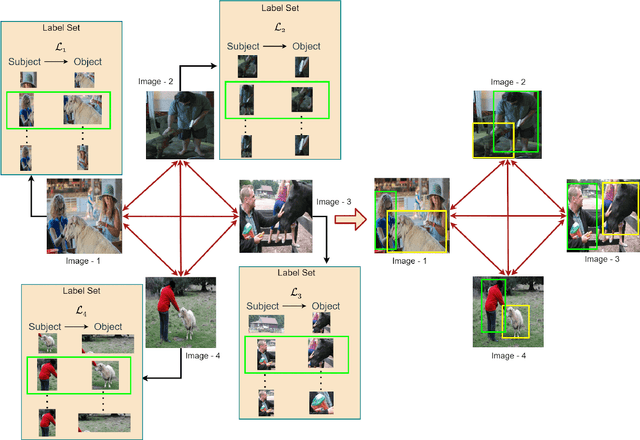
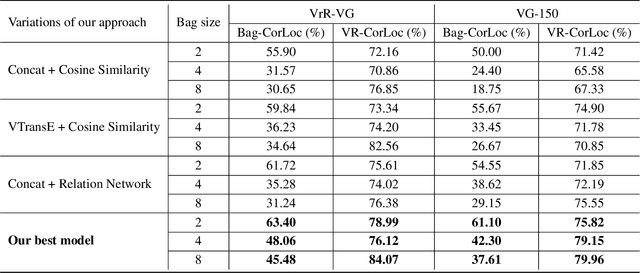
In this paper, given a small bag of images, each containing a common but latent predicate, we are interested in localizing visual subject-object pairs connected via the common predicate in each of the images. We refer to this novel problem as visual relationship co-localization or VRC as an abbreviation. VRC is a challenging task, even more so than the well-studied object co-localization task. This becomes further challenging when using just a few images, the model has to learn to co-localize visual subject-object pairs connected via unseen predicates. To solve VRC, we propose an optimization framework to select a common visual relationship in each image of the bag. The goal of the optimization framework is to find the optimal solution by learning visual relationship similarity across images in a few-shot setting. To obtain robust visual relationship representation, we utilize a simple yet effective technique that learns relationship embedding as a translation vector from visual subject to visual object in a shared space. Further, to learn visual relationship similarity, we utilize a proven meta-learning technique commonly used for few-shot classification tasks. Finally, to tackle the combinatorial complexity challenge arising from an exponential number of feasible solutions, we use a greedy approximation inference algorithm that selects approximately the best solution. We extensively evaluate our proposed framework on variations of bag sizes obtained from two challenging public datasets, namely VrR-VG and VG-150, and achieve impressive visual co-localization performance.