 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Meta-Diversity Search in Complex Systems, A Recipe for Artificial Open-Endedness ?
Dec 01, 2023
Can we build an artificial system that would be able to generate endless surprises if ran "forever" in Minecraft? While there is not a single path toward solving that grand challenge, this article presents what we believe to be some working ingredients for the endless generation of novel increasingly complex artifacts in Minecraft. Our framework for an open-ended system includes two components: a complex system used to recursively grow and complexify artifacts over time, and a discovery algorithm that leverages the concept of meta-diversity search. Since complex systems have shown to enable the emergence of considerable complexity from set of simple rules, we believe them to be great candidates to generate all sort of artifacts in Minecraft. Yet, the space of possible artifacts that can be generated by these systems is often unknown, challenging to characterize and explore. Therefore automating the long-term discovery of novel and increasingly complex artifacts in these systems is an exciting research field. To approach these challenges, we formulate the problem of meta-diversity search where an artificial "discovery assistant" incrementally learns a diverse set of representations to characterize behaviors and searches to discover diverse patterns within each of them. A successful discovery assistant should continuously seek for novel sources of diversities while being able to quickly specialize the search toward a new unknown type of diversity. To implement those ideas in the Minecraft environment, we simulate an artificial "chemistry" system based on Lenia continuous cellular automaton for generating artifacts, as well as an artificial "discovery assistant" (called Holmes) for the artifact-discovery process. Holmes incrementally learns a hierarchy of modular representations to characterize divergent sources of diversity and uses a goal-based intrinsically-motivated exploration as the diversity search strategy.
Continual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning
Nov 30, 2023Self-supervised learning is an efficient pre-training method for medical image analysis. However, current research is mostly confined to specific-modality data pre-training, consuming considerable time and resources without achieving universality across different modalities. A straightforward solution is combining all modality data for joint self-supervised pre-training, which poses practical challenges. Firstly, our experiments reveal conflicts in representation learning as the number of modalities increases. Secondly, multi-modal data collected in advance cannot cover all real-world scenarios. In this paper, we reconsider versatile self-supervised learning from the perspective of continual learning and propose MedCoSS, a continuous self-supervised learning approach for multi-modal medical data. Unlike joint self-supervised learning, MedCoSS assigns different modality data to different training stages, forming a multi-stage pre-training process. To balance modal conflicts and prevent catastrophic forgetting, we propose a rehearsal-based continual learning method. We introduce the k-means sampling strategy to retain data from previous modalities and rehearse it when learning new modalities. Instead of executing the pretext task on buffer data, a feature distillation strategy and an intra-modal mixup strategy are applied to these data for knowledge retention. We conduct continuous self-supervised pre-training on a large-scale multi-modal unlabeled dataset, including clinical reports, X-rays, CT scans, MRI scans, and pathological images. Experimental results demonstrate MedCoSS's exceptional generalization ability across nine downstream datasets and its significant scalability in integrating new modality data. Code and pre-trained weight are available at https://github.com/yeerwen/MedCoSS.
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
Nov 30, 2023Achieving human-like planning and control with multimodal observations in an open world is a key milestone for more functional generalist agents. Existing approaches can handle certain long-horizon tasks in an open world. However, they still struggle when the number of open-world tasks could potentially be infinite and lack the capability to progressively enhance task completion as game time progresses. We introduce JARVIS-1, an open-world agent that can perceive multimodal input (visual observations and human instructions), generate sophisticated plans, and perform embodied control, all within the popular yet challenging open-world Minecraft universe. Specifically, we develop JARVIS-1 on top of pre-trained multimodal language models, which map visual observations and textual instructions to plans. The plans will be ultimately dispatched to the goal-conditioned controllers. We outfit JARVIS-1 with a multimodal memory, which facilitates planning using both pre-trained knowledge and its actual game survival experiences. JARVIS-1 is the existing most general agent in Minecraft, capable of completing over 200 different tasks using control and observation space similar to humans. These tasks range from short-horizon tasks, e.g., "chopping trees" to long-horizon tasks, e.g., "obtaining a diamond pickaxe". JARVIS-1 performs exceptionally well in short-horizon tasks, achieving nearly perfect performance. In the classic long-term task of $\texttt{ObtainDiamondPickaxe}$, JARVIS-1 surpasses the reliability of current state-of-the-art agents by 5 times and can successfully complete longer-horizon and more challenging tasks. The project page is available at https://craftjarvis.org/JARVIS-1
Guided Demonstrations Using Automated Excuse Generation
Nov 30, 2023Teaching task-level directives to robots via demonstration is a popular tool to expand the robot's capabilities to interact with its environment. While current learning from demonstration systems primarily focuses on abstracting the task-level knowledge to the robot, these systems lack the ability to understand which part of the task can be already solved given the robot's prior knowledge. Therefore, instead of only requiring demonstrations of the missing pieces, these systems will require a demonstration of the complete task, which is cumbersome, repetitive, and can discourage people from helping the robot by performing the demonstrations. Therefore, we propose to use the notion of "excuses" to identify the smallest change in the robot state that makes a task, currently not solvable by the robot, solvable -- as a means to solicit more targeted demonstrations from a human. These excuses are generated automatically using combinatorial search over possible changes that can be made to the robot's state and choosing the minimum changes that make it solvable. These excuses then serve as guidance for the demonstrator who can use it to decide what to demonstrate to the robot in order to make this requested change possible, thereby making the original task solvable for the robot without having to demonstrate it in its entirety. By working with symbolic state descriptions, the excuses can be directly communicated and intuitively understood by a human demonstrator. We show empirically and in a user study that the use of excuses reduces the demonstration time by 54% and leads to a 74% reduction in demonstration size.
Virtual Home Staging: Inverse Rendering and Editing an Indoor Panorama under Natural Illumination
Nov 21, 2023We propose a novel inverse rendering method that enables the transformation of existing indoor panoramas with new indoor furniture layouts under natural illumination. To achieve this, we captured indoor HDR panoramas along with real-time outdoor hemispherical HDR photographs. Indoor and outdoor HDR images were linearly calibrated with measured absolute luminance values for accurate scene relighting. Our method consists of three key components: (1) panoramic furniture detection and removal, (2) automatic floor layout design, and (3) global rendering with scene geometry, new furniture objects, and a real-time outdoor photograph. We demonstrate the effectiveness of our workflow in rendering indoor scenes under different outdoor illumination conditions. Additionally, we contribute a new calibrated HDR (Cali-HDR) dataset that consists of 137 calibrated indoor panoramas and their associated outdoor photographs. The source code and dataset are available: https://github.com/Gzhji/Cali-HDR-Dataset.
Robotic Pollination of Apples in Commercial Orchards
Nov 21, 2023This research presents a novel, robotic pollination system designed for targeted pollination of apple flowers in modern fruiting wall orchards. Developed in response to the challenges of global colony collapse disorder, climate change, and the need for sustainable alternatives to traditional pollinators, the system utilizes a commercial manipulator, a vision system, and a spray nozzle for pollen application. Initial tests in April 2022 pollinated 56% of the target flower clusters with at least one fruit with a cycle time of 6.5 s. Significant improvements were made in 2023, with the system accurately detecting 91% of available flowers and pollinating 84% of target flowers with a reduced cycle time of 4.8 s. This system showed potential for precision artificial pollination that can also minimize the need for labor-intensive field operations such as flower and fruitlet thinning.
Transfer learning for day-ahead load forecasting: a case study on European national electricity demand time series
Oct 24, 2023Short-term load forecasting (STLF) is crucial for the daily operation of power grids. However, the non-linearity, non-stationarity, and randomness characterizing electricity demand time series renders STLF a challenging task. Various forecasting approaches have been proposed for improving STLF, including neural network (NN) models which are trained using data from multiple electricity demand series that may not necessary include the target series. In the present study, we investigate the performance of this special case of STLF, called transfer learning (TL), by considering a set of 27 time series that represent the national day-ahead electricity demand of indicative European countries. We employ a popular and easy-to-implement NN model and perform a clustering analysis to identify similar patterns among the series and assist TL. In this context, two different TL approaches, with and without the clustering step, are compiled and compared against each other as well as a typical NN training setup. Our results demonstrate that TL can outperform the conventional approach, especially when clustering techniques are considered.
Quantum-classical simulation of quantum field theory by quantum circuit learning
Nov 27, 2023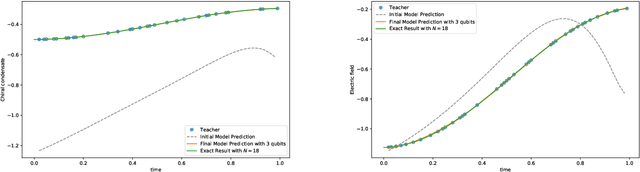
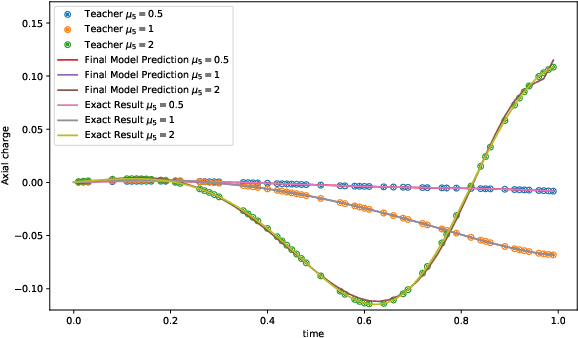
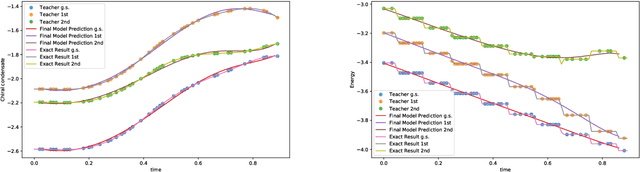
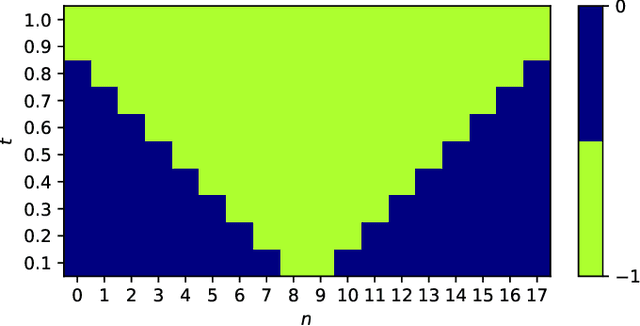
We employ quantum circuit learning to simulate quantum field theories (QFTs). Typically, when simulating QFTs with quantum computers, we encounter significant challenges due to the technical limitations of quantum devices when implementing the Hamiltonian using Pauli spin matrices. To address this challenge, we leverage quantum circuit learning, employing a compact configuration of qubits and low-depth quantum circuits to predict real-time dynamics in quantum field theories. The key advantage of this approach is that a single-qubit measurement can accurately forecast various physical parameters, including fully-connected operators. To demonstrate the effectiveness of our method, we use it to predict quench dynamics, chiral dynamics and jet production in a 1+1-dimensional model of quantum electrodynamics. We find that our predictions closely align with the results of rigorous classical calculations, exhibiting a high degree of accuracy. This hybrid quantum-classical approach illustrates the feasibility of efficiently simulating large-scale QFTs on cutting-edge quantum devices.
Error Performance of Coded AFDM Systems in Doubly Selective Channels
Nov 27, 2023Affine frequency division multiplexing (AFDM) is a strong candidate for the sixth-generation wireless network thanks to its strong resilience to delay-Doppler spreads. In this letter, we investigate the error performance of coded AFDM systems in doubly selective channels. We first study the conditional pairwise-error probability (PEP) of AFDM system and derive its conditional coding gain. Then, we show that there is a fundamental trade-off between the diversity gain and the coding gain of AFDM system, namely the coding gain declines with a descending speed with respect to the number of separable paths, while the diversity gain increases linearly. Moreover, we propose a near-optimal turbo decoder based on the sum-product algorithm for coded AFDM systems to improve its error performance. Simulation results verify our analyses and the effectiveness of the proposed turbo decoder, showing that AFDM outperforms orthogonal frequency division multiplexing (OFDM) and orthogonal time frequency space (OTFS) in both coded and uncoded cases over high-mobility channels.
Streaming Lossless Volumetric Compression of Medical Images Using Gated Recurrent Convolutional Neural Network
Nov 27, 2023Deep learning-based lossless compression methods offer substantial advantages in compressing medical volumetric images. Nevertheless, many learning-based algorithms encounter a trade-off between practicality and compression performance. This paper introduces a hardware-friendly streaming lossless volumetric compression framework, utilizing merely one-thousandth of the model weights compared to other learning-based compression frameworks. We propose a gated recurrent convolutional neural network that combines diverse convolutional structures and fusion gate mechanisms to capture the inter-slice dependencies in volumetric images. Based on such contextual information, we can predict the pixel-by-pixel distribution for entropy coding. Guided by hardware/software co-design principles, we implement the proposed framework on Field Programmable Gate Array to achieve enhanced real-time performance. Extensive experimental results indicate that our method outperforms traditional lossless volumetric compressors and state-of-the-art learning-based lossless compression methods across various medical image benchmarks. Additionally, our method exhibits robust generalization ability and competitive compression speed