 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MGAug: Multimodal Geometric Augmentation in Latent Spaces of Image Deformations
Dec 20, 2023
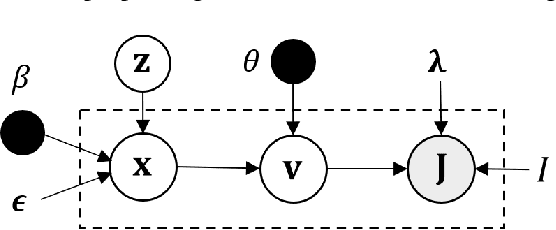
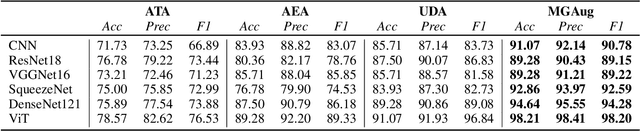
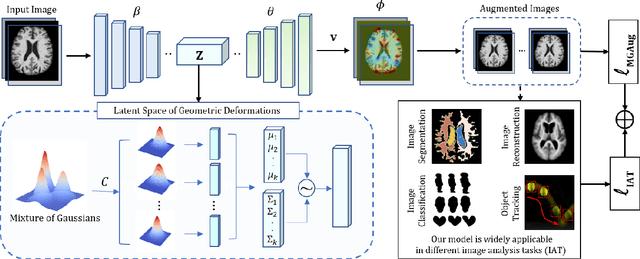
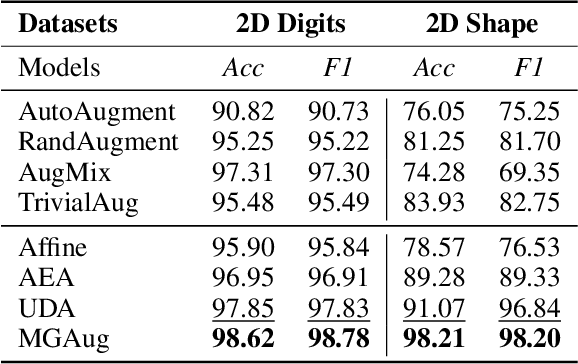
Geometric transformations have been widely used to augment the size of training images. Existing methods often assume a unimodal distribution of the underlying transformations between images, which limits their power when data with multimodal distributions occur. In this paper, we propose a novel model, Multimodal Geometric Augmentation (MGAug), that for the first time generates augmenting transformations in a multimodal latent space of geometric deformations. To achieve this, we first develop a deep network that embeds the learning of latent geometric spaces of diffeomorphic transformations (a.k.a. diffeomorphisms) in a variational autoencoder (VAE). A mixture of multivariate Gaussians is formulated in the tangent space of diffeomorphisms and serves as a prior to approximate the hidden distribution of image transformations. We then augment the original training dataset by deforming images using randomly sampled transformations from the learned multimodal latent space of VAE. To validate the efficiency of our model, we jointly learn the augmentation strategy with two distinct domain-specific tasks: multi-class classification on 2D synthetic datasets and segmentation on real 3D brain magnetic resonance images (MRIs). We also compare MGAug with state-of-the-art transformation-based image augmentation algorithms. Experimental results show that our proposed approach outperforms all baselines by significantly improved prediction accuracy. Our code is publicly available at https://github.com/tonmoy-hossain/MGAug.
MedBench: A Large-Scale Chinese Benchmark for Evaluating Medical Large Language Models
Dec 20, 2023The emergence of various medical large language models (LLMs) in the medical domain has highlighted the need for unified evaluation standards, as manual evaluation of LLMs proves to be time-consuming and labor-intensive. To address this issue, we introduce MedBench, a comprehensive benchmark for the Chinese medical domain, comprising 40,041 questions sourced from authentic examination exercises and medical reports of diverse branches of medicine. In particular, this benchmark is composed of four key components: the Chinese Medical Licensing Examination, the Resident Standardization Training Examination, the Doctor In-Charge Qualification Examination, and real-world clinic cases encompassing examinations, diagnoses, and treatments. MedBench replicates the educational progression and clinical practice experiences of doctors in Mainland China, thereby establishing itself as a credible benchmark for assessing the mastery of knowledge and reasoning abilities in medical language learning models. We perform extensive experiments and conduct an in-depth analysis from diverse perspectives, which culminate in the following findings: (1) Chinese medical LLMs underperform on this benchmark, highlighting the need for significant advances in clinical knowledge and diagnostic precision. (2) Several general-domain LLMs surprisingly possess considerable medical knowledge. These findings elucidate both the capabilities and limitations of LLMs within the context of MedBench, with the ultimate goal of aiding the medical research community.
Inferring the Graph of Networked Dynamical Systems under Partial Observability and Spatially Colored Noise
Dec 18, 2023In a Networked Dynamical System (NDS), each node is a system whose dynamics are coupled with the dynamics of neighboring nodes. The global dynamics naturally builds on this network of couplings and it is often excited by a noise input with nontrivial structure. The underlying network is unknown in many applications and should be inferred from observed data. We assume: i) Partial observability -- time series data is only available over a subset of the nodes; ii) Input noise -- it is correlated across distinct nodes while temporally independent, i.e., it is spatially colored. We present a feasibility condition on the noise correlation structure wherein there exists a consistent network inference estimator to recover the underlying fundamental dependencies among the observed nodes. Further, we describe a structure identification algorithm that exhibits competitive performance across distinct regimes of network connectivity, observability, and noise correlation.
Evaluation of Active Feature Acquisition Methods for Time-varying Feature Settings
Dec 03, 2023Machine learning methods often assume input features are available at no cost. However, in domains like healthcare, where acquiring features could be expensive or harmful, it is necessary to balance a feature's acquisition cost against its predictive value. The task of training an AI agent to decide which features to acquire is called active feature acquisition (AFA). By deploying an AFA agent, we effectively alter the acquisition strategy and trigger a distribution shift. To safely deploy AFA agents under this distribution shift, we present the problem of active feature acquisition performance evaluation (AFAPE). We examine AFAPE under i) a no direct effect (NDE) assumption, stating that acquisitions don't affect the underlying feature values; and ii) a no unobserved confounding (NUC) assumption, stating that retrospective feature acquisition decisions were only based on observed features. We show that one can apply offline reinforcement learning under the NUC assumption and missing data methods under the NDE assumption. When NUC and NDE hold, we propose a novel semi-offline reinforcement learning framework, which requires a weaker positivity assumption and yields more data-efficient estimators. We introduce three novel estimators: a direct method (DM), an inverse probability weighting (IPW), and a double reinforcement learning (DRL) estimator.
ASH: Animatable Gaussian Splats for Efficient and Photoreal Human Rendering
Dec 10, 2023Real-time rendering of photorealistic and controllable human avatars stands as a cornerstone in Computer Vision and Graphics. While recent advances in neural implicit rendering have unlocked unprecedented photorealism for digital avatars, real-time performance has mostly been demonstrated for static scenes only. To address this, we propose ASH, an animatable Gaussian splatting approach for photorealistic rendering of dynamic humans in real-time. We parameterize the clothed human as animatable 3D Gaussians, which can be efficiently splatted into image space to generate the final rendering. However, naively learning the Gaussian parameters in 3D space poses a severe challenge in terms of compute. Instead, we attach the Gaussians onto a deformable character model, and learn their parameters in 2D texture space, which allows leveraging efficient 2D convolutional architectures that easily scale with the required number of Gaussians. We benchmark ASH with competing methods on pose-controllable avatars, demonstrating that our method outperforms existing real-time methods by a large margin and shows comparable or even better results than offline methods.
Online Variational Sequential Monte Carlo
Dec 19, 2023Being the most classical generative model for serial data, state-space models (SSM) are fundamental in AI and statistical machine learning. In SSM, any form of parameter learning or latent state inference typically involves the computation of complex latent-state posteriors. In this work, we build upon the variational sequential Monte Carlo (VSMC) method, which provides computationally efficient and accurate model parameter estimation and Bayesian latent-state inference by combining particle methods and variational inference. While standard VSMC operates in the offline mode, by re-processing repeatedly a given batch of data, we distribute the approximation of the gradient of the VSMC surrogate ELBO in time using stochastic approximation, allowing for online learning in the presence of streams of data. This results in an algorithm, online VSMC, that is capable of performing efficiently, entirely on-the-fly, both parameter estimation and particle proposal adaptation. In addition, we provide rigorous theoretical results describing the algorithm's convergence properties as the number of data tends to infinity as well as numerical illustrations of its excellent convergence properties and usefulness also in batch-processing settings.
Avoiding Data Contamination in Language Model Evaluation: Dynamic Test Construction with Latest Materials
Dec 19, 2023Data contamination in evaluation is getting increasingly prevalent with the emerge of language models pre-trained on super large, automatically-crawled corpora. This problem leads to significant challenges in accurate assessment of model capabilities and generalisations. In this paper, we propose LatestEval, an automatic method leverages the most recent texts to create uncontaminated reading comprehension evaluations. LatestEval avoids data contamination by only using texts published within a recent time window, ensuring no overlap with the training corpora of pre-trained language models. We develop LatestEval automated pipeline to 1) gather latest texts; 2) identify key information, and 3) construct questions targeting the information while removing the existing answers from the context. This encourages models to infer the answers themselves based on the remaining context, rather than just copy-paste. Our experiments demonstrate that language models exhibit negligible memorisation behaviours on LatestEval as opposed to previous benchmarks, suggesting a significantly reduced risk of data contamination and leading to a more robust evaluation. Data and code are publicly available at: https://github.com/liyucheng09/LatestEval.
Teeth Localization and Lesion Segmentation in CBCT Images using SpatialConfiguration-Net and U-Net
Dec 19, 2023The localization of teeth and segmentation of periapical lesions in cone-beam computed tomography (CBCT) images are crucial tasks for clinical diagnosis and treatment planning, which are often time-consuming and require a high level of expertise. However, automating these tasks is challenging due to variations in shape, size, and orientation of lesions, as well as similar topologies among teeth. Moreover, the small volumes occupied by lesions in CBCT images pose a class imbalance problem that needs to be addressed. In this study, we propose a deep learning-based method utilizing two convolutional neural networks: the SpatialConfiguration-Net (SCN) and a modified version of the U-Net. The SCN accurately predicts the coordinates of all teeth present in an image, enabling precise cropping of teeth volumes that are then fed into the U-Net which detects lesions via segmentation. To address class imbalance, we compare the performance of three reweighting loss functions. After evaluation on 144 CBCT images, our method achieves a 97.3% accuracy for teeth localization, along with a promising sensitivity and specificity of 0.97 and 0.88, respectively, for subsequent lesion detection.
Object Detection for Automated Coronary Artery Using Deep Learning
Dec 19, 2023In the era of digital medicine, medical imaging serves as a widespread technique for early disease detection, with a substantial volume of images being generated and stored daily in electronic patient records. X-ray angiography imaging is a standard and one of the most common methods for rapidly diagnosing coronary artery diseases. The notable achievements of recent deep learning algorithms align with the increased use of electronic health records and diagnostic imaging. Deep neural networks, leveraging abundant data, advanced algorithms, and powerful computational capabilities, prove highly effective in the analysis and interpretation of images. In this context, Object detection methods have become a promising approach, particularly through convolutional neural networks (CNN), streamlining medical image analysis by eliminating manual feature extraction. This allows for direct feature extraction from images, ensuring high accuracy in results. Therefore, in our paper, we utilized the object detection method on X-ray angiography images to precisely identify the location of coronary artery stenosis. As a result, this model enables automatic and real-time detection of stenosis locations, assisting in the crucial and sensitive decision-making process for healthcare professionals.
MPI Planar Correction of Pulse Based ToF Cameras
Dec 19, 2023Time-of-Flight (ToF) cameras are becoming popular in a wide span of areas ranging from consumer-grade electronic devices to safety-critical industrial robots. This is mainly due to their high frame rate, relative good precision and the lowered costs. Although ToF cameras are in continuous development, especially pulse-based variants, they still face different problems, including spurious noise over the points or multipath inference (MPI). The latter can cause deformed surfaces to manifest themselves on curved surfaces instead of planar ones, making standard spatial data preprocessing, such as plane extraction, difficult. In this paper, we focus on the MPI reduction problem using Feature Pyramid Networks (FPN) which allow the mitigation of this type of artifact for pulse-based ToF cameras. With our end-to-end network, we managed to attenuate the MPI effect on planar surfaces using a learning-based method on real ToF data. Both the custom dataset used for our model training as well as the code is available on the author's Github homepage.