 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Layer-wise Auto-Weighting for Non-Stationary Test-Time Adaptation
Nov 26, 2023
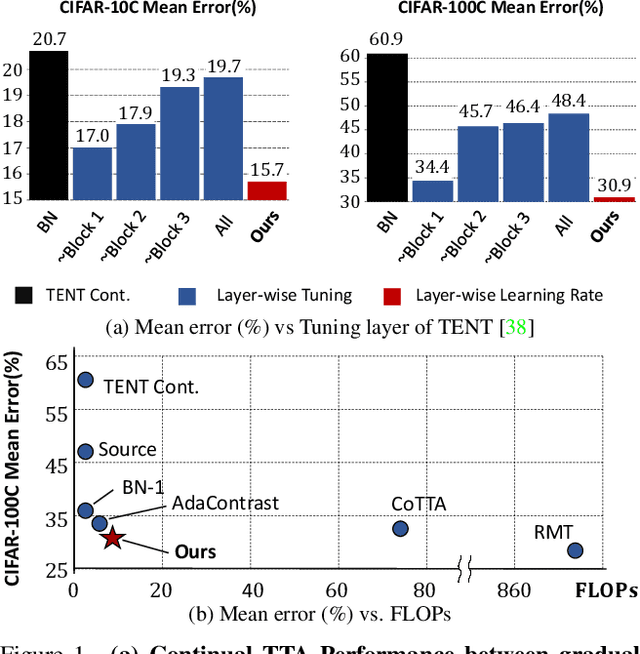

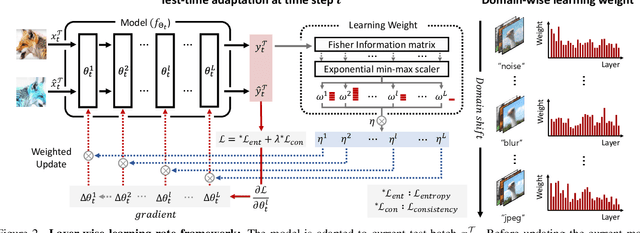
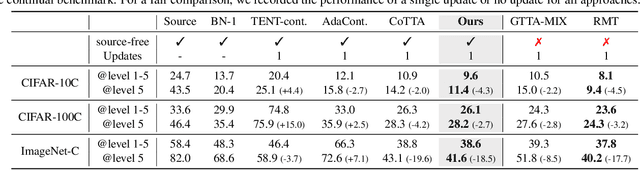
Given the inevitability of domain shifts during inference in real-world applications, test-time adaptation (TTA) is essential for model adaptation after deployment. However, the real-world scenario of continuously changing target distributions presents challenges including catastrophic forgetting and error accumulation. Existing TTA methods for non-stationary domain shifts, while effective, incur excessive computational load, making them impractical for on-device settings. In this paper, we introduce a layer-wise auto-weighting algorithm for continual and gradual TTA that autonomously identifies layers for preservation or concentrated adaptation. By leveraging the Fisher Information Matrix (FIM), we first design the learning weight to selectively focus on layers associated with log-likelihood changes while preserving unrelated ones. Then, we further propose an exponential min-max scaler to make certain layers nearly frozen while mitigating outliers. This minimizes forgetting and error accumulation, leading to efficient adaptation to non-stationary target distribution. Experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C show our method outperforms conventional continual and gradual TTA approaches while significantly reducing computational load, highlighting the importance of FIM-based learning weight in adapting to continuously or gradually shifting target domains.
Maximum Likelihood CFO Estimation for High-Mobility OFDM Systems: A Chinese Remainder Theorem Based Method
Dec 27, 2023Orthogonal frequency division multiplexing (OFDM) is a widely adopted wireless communication technique but is sensitive to the carrier frequency offset (CFO). For high-mobility environments, severe Doppler shifts cause the CFO to extend well beyond the subcarrier spacing. Traditional algorithms generally estimate the integer and fractional parts of the CFO separately, which is time-consuming and requires high additional computations. To address these issues, this paper proposes a Chinese remainder theorem-based CFO Maximum Likelihood Estimation (CCMLE) approach for jointly estimating the integer and fractional parts. With CCMLE, the MLE of the CFO can be obtained directly from multiple estimates of sequences with varying lengths. This approach can achieve a wide estimation range up to the total number of subcarriers, without significant additional computations. Furthermore, we show that the CCMLE can approach the Cram$\acute{\text{e}}$r-Rao Bound (CRB), and give an analytic expression for the signal-to-noise ratio (SNR) threshold approaching the CRB, enabling an efficient waveform design. Accordingly, a parameter configuration guideline for the CCMLE is presented to achieve a better MSE performance and a lower SNR threshold. Finally, experiments show that our proposed method is highly consistent with the theoretical analysis and advantageous regarding estimated range and error performance compared to baselines.
Hawkes-based cryptocurrency forecasting via Limit Order Book data
Dec 21, 2023Accurately forecasting the direction of financial returns poses a formidable challenge, given the inherent unpredictability of financial time series. The task becomes even more arduous when applied to cryptocurrency returns, given the chaotic and intricately complex nature of crypto markets. In this study, we present a novel prediction algorithm using limit order book (LOB) data rooted in the Hawkes model, a category of point processes. Coupled with a continuous output error (COE) model, our approach offers a precise forecast of return signs by leveraging predictions of future financial interactions. Capitalizing on the non-uniformly sampled structure of the original time series, our strategy surpasses benchmark models in both prediction accuracy and cumulative profit when implemented in a trading environment. The efficacy of our approach is validated through Monte Carlo simulations across 50 scenarios. The research draws on LOB measurements from a centralized cryptocurrency exchange where the stablecoin Tether is exchanged against the U.S. dollar.
An Alternate View on Optimal Filtering in an RKHS
Dec 19, 2023Kernel Adaptive Filtering (KAF) are mathematically principled methods which search for a function in a Reproducing Kernel Hilbert Space. While they work well for tasks such as time series prediction and system identification they are plagued by a linear relationship between number of training samples and model size, hampering their use on the very large data sets common in today's data saturated world. Previous methods try to solve this issue by sparsification. We describe a novel view of optimal filtering which may provide a route towards solutions in a RKHS which do not necessarily have this linear growth in model size. We do this by defining a RKHS in which the time structure of a stochastic process is still present. Using correntropy [11], an extension of the idea of a covariance function, we create a time based functional which describes some potentially nonlinear desired mapping function. This form of a solution may provide a fruitful line of research for creating more efficient representations of functionals in a RKHS, while theoretically providing computational complexity in the test set similar to Wiener solution.
Deep Unfolding Network with Spatial Alignment for multi-modal MRI reconstruction
Dec 28, 2023Multi-modal Magnetic Resonance Imaging (MRI) offers complementary diagnostic information, but some modalities are limited by the long scanning time. To accelerate the whole acquisition process, MRI reconstruction of one modality from highly undersampled k-space data with another fully-sampled reference modality is an efficient solution. However, the misalignment between modalities, which is common in clinic practice, can negatively affect reconstruction quality. Existing deep learning-based methods that account for inter-modality misalignment perform better, but still share two main common limitations: (1) The spatial alignment task is not adaptively integrated with the reconstruction process, resulting in insufficient complementarity between the two tasks; (2) the entire framework has weak interpretability. In this paper, we construct a novel Deep Unfolding Network with Spatial Alignment, termed DUN-SA, to appropriately embed the spatial alignment task into the reconstruction process. Concretely, we derive a novel joint alignment-reconstruction model with a specially designed cross-modal spatial alignment term. By relaxing the model into cross-modal spatial alignment and multi-modal reconstruction tasks, we propose an effective algorithm to solve this model alternatively. Then, we unfold the iterative steps of the proposed algorithm and design corresponding network modules to build DUN-SA with interpretability. Through end-to-end training, we effectively compensate for spatial misalignment using only reconstruction loss, and utilize the progressively aligned reference modality to provide inter-modality prior to improve the reconstruction of the target modality. Comprehensive experiments on three real datasets demonstrate that our method exhibits superior reconstruction performance compared to state-of-the-art methods.
A Multi-level Distillation based Dense Passage Retrieval Model
Dec 28, 2023Ranker and retriever are two important components in dense passage retrieval. The retriever typically adopts a dual-encoder model, where queries and documents are separately input into two pre-trained models, and the vectors generated by the models are used for similarity calculation. The ranker often uses a cross-encoder model, where the concatenated query-document pairs are input into a pre-trained model to obtain word similarities. However, the dual-encoder model lacks interaction between queries and documents due to its independent encoding, while the cross-encoder model requires substantial computational cost for attention calculation, making it difficult to obtain real-time retrieval results. In this paper, we propose a dense retrieval model called MD2PR based on multi-level distillation. In this model, we distill the knowledge learned from the cross-encoder to the dual-encoder at both the sentence level and word level. Sentence-level distillation enhances the dual-encoder on capturing the themes and emotions of sentences. Word-level distillation improves the dual-encoder in analysis of word semantics and relationships. As a result, the dual-encoder can be used independently for subsequent encoding and retrieval, avoiding the significant computational cost associated with the participation of the cross-encoder. Furthermore, we propose a simple dynamic filtering method, which updates the threshold during multiple training iterations to ensure the effective identification of false negatives and thus obtains a more comprehensive semantic representation space. The experimental results over two standard datasets show our MD2PR outperforms 11 baseline models in terms of MRR and Recall metrics.
Task Contamination: Language Models May Not Be Few-Shot Anymore
Dec 26, 2023Large language models (LLMs) offer impressive performance in various zero-shot and few-shot tasks. However, their success in zero-shot and few-shot settings may be affected by task contamination, a potential limitation that has not been thoroughly examined. This paper investigates how zero-shot and few-shot performance of LLMs has changed chronologically over time. Utilizing GPT-3 series models and several other recent open-sourced LLMs, and controlling for dataset difficulty, we find that on datasets released before the LLM training data creation date, LLMs perform surprisingly better than on datasets released after. This strongly indicates that, for many LLMs, there exists task contamination on zero-shot and few-shot evaluation for datasets released prior to the LLMs' training data creation date. Additionally, we utilize training data inspection, task example extraction, and a membership inference attack, which reveal further evidence of task contamination. Importantly, we find that for classification tasks with no possibility of task contamination, LLMs rarely demonstrate statistically significant improvements over simple majority baselines, in both zero and few-shot settings.
HyperDeepONet: learning operator with complex target function space using the limited resources via hypernetwork
Dec 26, 2023Fast and accurate predictions for complex physical dynamics are a significant challenge across various applications. Real-time prediction on resource-constrained hardware is even more crucial in real-world problems. The deep operator network (DeepONet) has recently been proposed as a framework for learning nonlinear mappings between function spaces. However, the DeepONet requires many parameters and has a high computational cost when learning operators, particularly those with complex (discontinuous or non-smooth) target functions. This study proposes HyperDeepONet, which uses the expressive power of the hypernetwork to enable the learning of a complex operator with a smaller set of parameters. The DeepONet and its variant models can be thought of as a method of injecting the input function information into the target function. From this perspective, these models can be viewed as a particular case of HyperDeepONet. We analyze the complexity of DeepONet and conclude that HyperDeepONet needs relatively lower complexity to obtain the desired accuracy for operator learning. HyperDeepONet successfully learned various operators with fewer computational resources compared to other benchmarks.
Accommodating Missing Modalities in Time-Continuous Multimodal Emotion Recognition
Nov 16, 2023Decades of research indicate that emotion recognition is more effective when drawing information from multiple modalities. But what if some modalities are sometimes missing? To address this problem, we propose a novel Transformer-based architecture for recognizing valence and arousal in a time-continuous manner even with missing input modalities. We use a coupling of cross-attention and self-attention mechanisms to emphasize relationships between modalities during time and enhance the learning process on weak salient inputs. Experimental results on the Ulm-TSST dataset show that our model exhibits an improvement of the concordance correlation coefficient evaluation of 37% when predicting arousal values and 30% when predicting valence values, compared to a late-fusion baseline approach.
Timely and Efficient Information Delivery in Real-Time Industrial IoT Networks
Nov 22, 2023Enabling real-time communication in Industrial Internet of Things (IIoT) networks is crucial to support autonomous, self-organized and re-configurable industrial automation for Industry 4.0 and the forthcoming Industry 5.0. In this paper, we consider a SIC-assisted real-time IIoT network, in which sensor nodes generate reports according to an event-generation probability that is specific for the monitored phenomena. The reports are delivered over a block-fading channel to a common Access Point (AP) in slotted ALOHA fashion, which leverages the imbalances in the received powers among the contending users and applies successive interference cancellation (SIC) to decode user packets from the collisions. We provide an extensive analytical treatment of the setup, deriving the Age of Information (AoI), throughput and deadline violation probability, when the AP has access to both the perfect as well as the imperfect channel-state information. We show that adopting SIC improves all the performance parameters with respect to the standard slotted ALOHA, as well as to an age-dependent access method. The analytical results agree with the simulation based ones, demonstrating that investing in the SIC capability at the receiver enables this simple access method to support timely and efficient information delivery in IIoT networks.