 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Jan 04, 2024
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this "bag-level" image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We plan to release the benchmark, consisting of 7 datasets, which will contribute to future research in zero-shot recognition.
Calibration-free online test-time adaptation for electroencephalography motor imagery decoding
Nov 30, 2023Providing a promising pathway to link the human brain with external devices, Brain-Computer Interfaces (BCIs) have seen notable advancements in decoding capabilities, primarily driven by increasingly sophisticated techniques, especially deep learning. However, achieving high accuracy in real-world scenarios remains a challenge due to the distribution shift between sessions and subjects. In this paper we will explore the concept of online test-time adaptation (OTTA) to continuously adapt the model in an unsupervised fashion during inference time. Our approach guarantees the preservation of privacy by eliminating the requirement to access the source data during the adaptation process. Additionally, OTTA achieves calibration-free operation by not requiring any session- or subject-specific data. We will investigate the task of electroencephalography (EEG) motor imagery decoding using a lightweight architecture together with different OTTA techniques like alignment, adaptive batch normalization, and entropy minimization. We examine two datasets and three distinct data settings for a comprehensive analysis. Our adaptation methods produce state-of-the-art results, potentially instigating a shift in transfer learning for BCI decoding towards online adaptation.
Beyond Entropy: Style Transfer Guided Single Image Continual Test-Time Adaptation
Nov 30, 2023Continual test-time adaptation (cTTA) methods are designed to facilitate the continual adaptation of models to dynamically changing real-world environments where computational resources are limited. Due to this inherent limitation, existing approaches fail to simultaneously achieve accuracy and efficiency. In detail, when using a single image, the instability caused by batch normalization layers and entropy loss significantly destabilizes many existing methods in real-world cTTA scenarios. To overcome these challenges, we present BESTTA, a novel single image continual test-time adaptation method guided by style transfer, which enables stable and efficient adaptation to the target environment by transferring the style of the input image to the source style. To implement the proposed method, we devise BeIN, a simple yet powerful normalization method, along with the style-guided losses. We demonstrate that BESTTA effectively adapts to the continually changing target environment, leveraging only a single image on both semantic segmentation and image classification tasks. Remarkably, despite training only two parameters in a BeIN layer consuming the least memory, BESTTA outperforms existing state-of-the-art methods in terms of performance.
Image Transformation for IoT Time-Series Data: A Review
Nov 21, 2023In the era of the Internet of Things (IoT), where smartphones, built-in systems, wireless sensors, and nearly every smart device connect through local networks or the internet, billions of smart things communicate with each other and generate vast amounts of time-series data. As IoT time-series data is high-dimensional and high-frequency, time-series classification or regression has been a challenging issue in IoT. Recently, deep learning algorithms have demonstrated superior performance results in time-series data classification in many smart and intelligent IoT applications. However, it is hard to explore the hidden dynamic patterns and trends in time-series. Recent studies show that transforming IoT data into images improves the performance of the learning model. In this paper, we present a review of these studies which use image transformation/encoding techniques in IoT domain. We examine the studies according to their encoding techniques, data types, and application areas. Lastly, we emphasize the challenges and future dimensions of image transformation.
Smuche: Scalar-Multiplicative Caching in Homomorphic Encryption
Dec 26, 2023Addressing the challenge of balancing security and efficiency when deploying machine learning systems in untrusted environments, such as federated learning, remains a critical concern. A promising strategy to tackle this issue involves optimizing the performance of fully homomorphic encryption (HE). Recent research highlights the efficacy of advanced caching techniques, such as Rache, in significantly enhancing the performance of HE schemes without compromising security. However, Rache is constrained by an inherent limitation: its performance overhead is heavily influenced by the characteristics of plaintext models, specifically exhibiting a caching time complexity of $\mathcal{O}(N)$, where $N$ represents the number of cached pivots based on specific radixes. This caching overhead becomes impractical for handling large-scale data. In this study, we introduce a novel \textit{constant-time} caching technique that is independent of any parameters. The core concept involves applying scalar multiplication to a single cached ciphertext, followed by the introduction of a completely new and constant-time randomness. Leveraging the inherent characteristics of constant-time construction, we coin the term ``Smuche'' for this innovative caching technique, which stands for Scalar-multiplicative Caching of Homomorphic Encryption. We implemented Smuche from scratch and conducted comparative evaluations against two baseline schemes, Rache and CKKS. Our experimental results underscore the effectiveness of Smuche in addressing the identified limitations and optimizing the performance of homomorphic encryption in practical scenarios.
Physics-Informed Multi-Agent Reinforcement Learning for Distributed Multi-Robot Problems
Dec 30, 2023The networked nature of multi-robot systems presents challenges in the context of multi-agent reinforcement learning. Centralized control policies do not scale with increasing numbers of robots, whereas independent control policies do not exploit the information provided by other robots, exhibiting poor performance in cooperative-competitive tasks. In this work we propose a physics-informed reinforcement learning approach able to learn distributed multi-robot control policies that are both scalable and make use of all the available information to each robot. Our approach has three key characteristics. First, it imposes a port-Hamiltonian structure on the policy representation, respecting energy conservation properties of physical robot systems and the networked nature of robot team interactions. Second, it uses self-attention to ensure a sparse policy representation able to handle time-varying information at each robot from the interaction graph. Third, we present a soft actor-critic reinforcement learning algorithm parameterized by our self-attention port-Hamiltonian control policy, which accounts for the correlation among robots during training while overcoming the need of value function factorization. Extensive simulations in different multi-robot scenarios demonstrate the success of the proposed approach, surpassing previous multi-robot reinforcement learning solutions in scalability, while achieving similar or superior performance (with averaged cumulative reward up to x2 greater than the state-of-the-art with robot teams x6 larger than the number of robots at training time).
Time Scale Network: A Shallow Neural Network For Time Series Data
Nov 10, 2023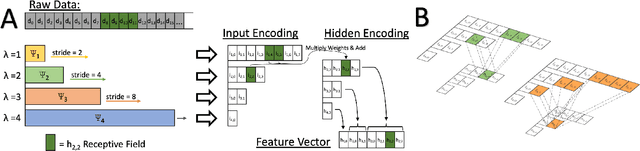
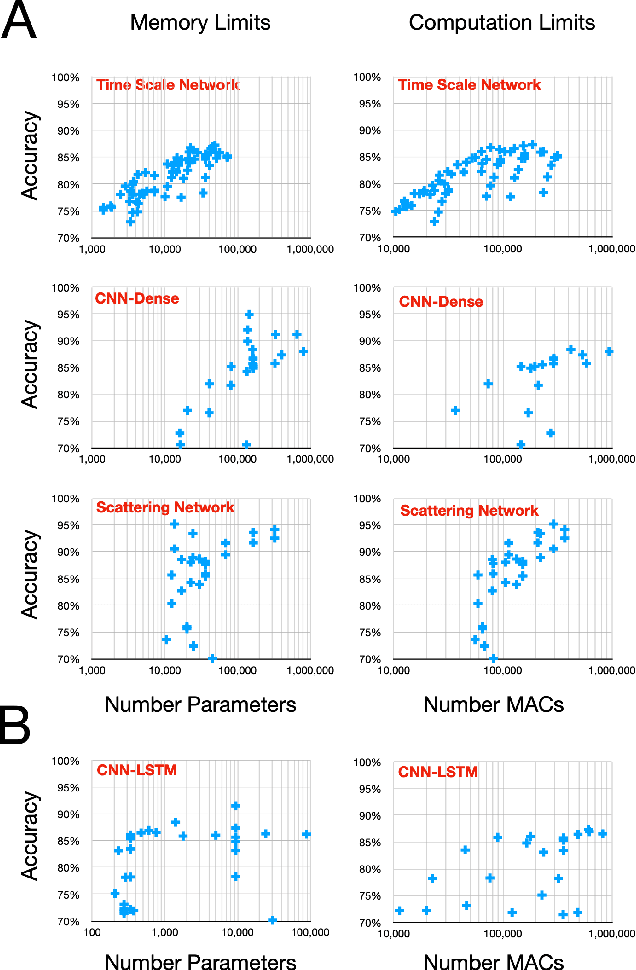
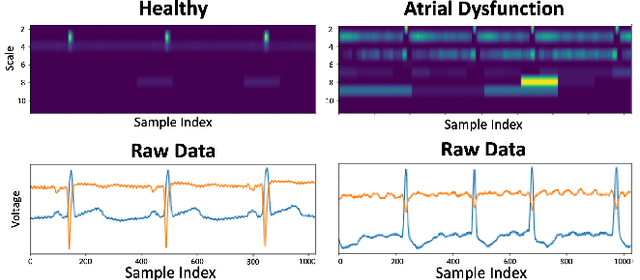
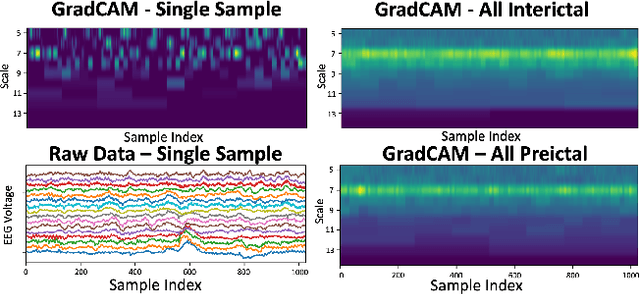
Time series data is often composed of information at multiple time scales, particularly in biomedical data. While numerous deep learning strategies exist to capture this information, many make networks larger, require more data, are more demanding to compute, and are difficult to interpret. This limits their usefulness in real-world applications facing even modest computational or data constraints and can further complicate their translation into practice. We present a minimal, computationally efficient Time Scale Network combining the translation and dilation sequence used in discrete wavelet transforms with traditional convolutional neural networks and back-propagation. The network simultaneously learns features at many time scales for sequence classification with significantly reduced parameters and operations. We demonstrate advantages in Atrial Dysfunction detection including: superior accuracy-per-parameter and accuracy-per-operation, fast training and inference speeds, and visualization and interpretation of learned patterns in atrial dysfunction detection on ECG signals. We also demonstrate impressive performance in seizure prediction using EEG signals. Our network isolated a few time scales that could be strategically selected to achieve 90.9% accuracy using only 1,133 active parameters and consistently converged on pulsatile waveform shapes. This method does not rest on any constraints or assumptions regarding signal content and could be leveraged in any area of time series analysis dealing with signals containing features at many time scales.
DGDNN: Decoupled Graph Diffusion Neural Network for Stock Movement Prediction
Jan 03, 2024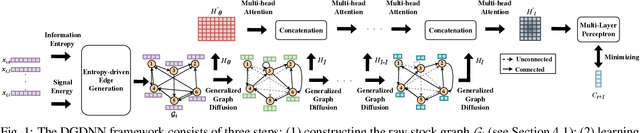
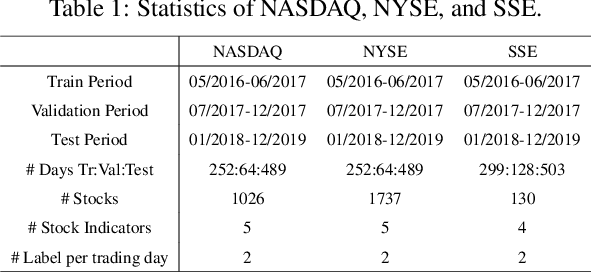
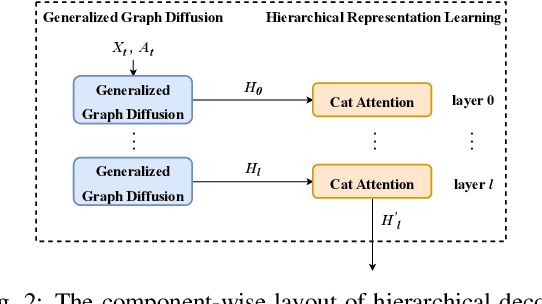
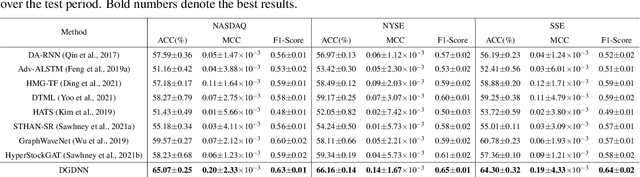
Forecasting future stock trends remains challenging for academia and industry due to stochastic inter-stock dynamics and hierarchical intra-stock dynamics influencing stock prices. In recent years, graph neural networks have achieved remarkable performance in this problem by formulating multiple stocks as graph-structured data. However, most of these approaches rely on artificially defined factors to construct static stock graphs, which fail to capture the intrinsic interdependencies between stocks that rapidly evolve. In addition, these methods often ignore the hierarchical features of the stocks and lose distinctive information within. In this work, we propose a novel graph learning approach implemented without expert knowledge to address these issues. First, our approach automatically constructs dynamic stock graphs by entropy-driven edge generation from a signal processing perspective. Then, we further learn task-optimal dependencies between stocks via a generalized graph diffusion process on constructed stock graphs. Last, a decoupled representation learning scheme is adopted to capture distinctive hierarchical intra-stock features. Experimental results demonstrate substantial improvements over state-of-the-art baselines on real-world datasets. Moreover, the ablation study and sensitivity study further illustrate the effectiveness of the proposed method in modeling the time-evolving inter-stock and intra-stock dynamics.
FullLoRA-AT: Efficiently Boosting the Robustness of Pretrained Vision Transformers
Jan 03, 2024In recent years, the Vision Transformer (ViT) model has gradually become mainstream in various computer vision tasks, and the robustness of the model has received increasing attention. However, existing large models tend to prioritize performance during training, potentially neglecting the robustness, which may lead to serious security concerns. In this paper, we establish a new challenge: exploring how to use a small number of additional parameters for adversarial finetuning to quickly and effectively enhance the adversarial robustness of a standardly trained model. To address this challenge, we develop the novel LNLoRA module, incorporating a learnable layer normalization before the conventional LoRA module, which helps mitigate magnitude differences in parameters between the adversarial and standard training paradigms. Furthermore, we propose the FullLoRA-AT framework by integrating the learnable LNLoRA modules into all key components of ViT-based models while keeping the pretrained model frozen, which can significantly improve the model robustness via adversarial finetuning in a parameter-efficient manner. Extensive experiments on CIFAR-10, CIFAR-100, and Imagenette demonstrate the superiority of our proposed FullLoRA-AT framework. It achieves comparable robustness with full finetuning while only requiring about 5% of the learnable parameters. This also effectively addresses concerns regarding extra model storage space and enormous training time caused by adversarial finetuning.
ODTrack: Online Dense Temporal Token Learning for Visual Tracking
Jan 03, 2024Online contextual reasoning and association across consecutive video frames are critical to perceive instances in visual tracking. However, most current top-performing trackers persistently lean on sparse temporal relationships between reference and search frames via an offline mode. Consequently, they can only interact independently within each image-pair and establish limited temporal correlations. To alleviate the above problem, we propose a simple, flexible and effective video-level tracking pipeline, named \textbf{ODTrack}, which densely associates the contextual relationships of video frames in an online token propagation manner. ODTrack receives video frames of arbitrary length to capture the spatio-temporal trajectory relationships of an instance, and compresses the discrimination features (localization information) of a target into a token sequence to achieve frame-to-frame association. This new solution brings the following benefits: 1) the purified token sequences can serve as prompts for the inference in the next video frame, whereby past information is leveraged to guide future inference; 2) the complex online update strategies are effectively avoided by the iterative propagation of token sequences, and thus we can achieve more efficient model representation and computation. ODTrack achieves a new \textit{SOTA} performance on seven benchmarks, while running at real-time speed. Code and models are available at \url{https://github.com/GXNU-ZhongLab/ODTrack}.