 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Input-Cell Attention Reduces Vanishing Saliency of Recurrent Neural Networks
Oct 27, 2019
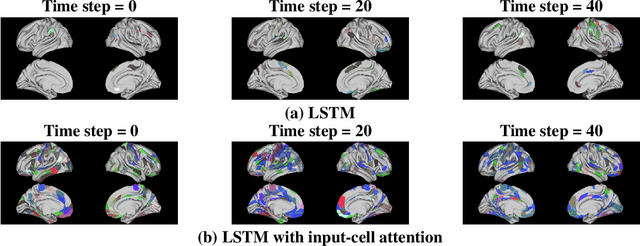
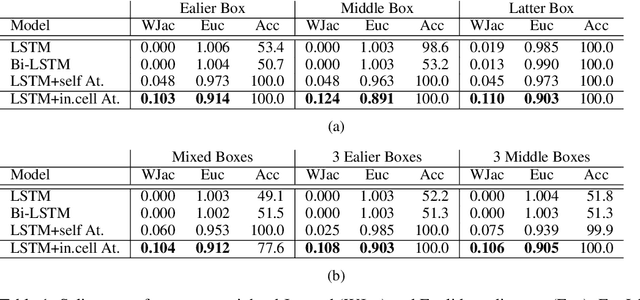
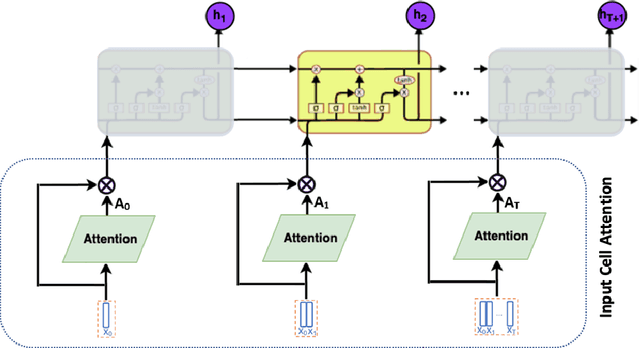
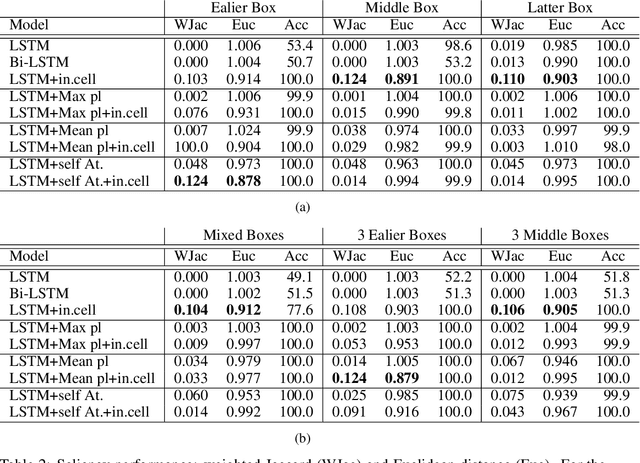
Recent efforts to improve the interpretability of deep neural networks use saliency to characterize the importance of input features to predictions made by models. Work on interpretability using saliency-based methods on Recurrent Neural Networks (RNNs) has mostly targeted language tasks, and their applicability to time series data is less understood. In this work we analyze saliency-based methods for RNNs, both classical and gated cell architectures. We show that RNN saliency vanishes over time, biasing detection of salient features only to later time steps and are, therefore, incapable of reliably detecting important features at arbitrary time intervals. To address this vanishing saliency problem, we propose a novel RNN cell structure (input-cell attention), which can extend any RNN cell architecture. At each time step, instead of only looking at the current input vector, input-cell attention uses a fixed-size matrix embedding, each row of the matrix attending to different inputs from current or previous time steps. Using synthetic data, we show that the saliency map produced by the input-cell attention RNN is able to faithfully detect important features regardless of their occurrence in time. We also apply the input-cell attention RNN on a neuroscience task analyzing functional Magnetic Resonance Imaging (fMRI) data for human subjects performing a variety of tasks. In this case, we use saliency to characterize brain regions (input features) for which activity is important to distinguish between tasks. We show that standard RNN architectures are only capable of detecting important brain regions in the last few time steps of the fMRI data, while the input-cell attention model is able to detect important brain region activity across time without latter time step biases.
Dynamic Filtering of Time-Varying Sparse Signals via l1 Minimization
Feb 22, 2016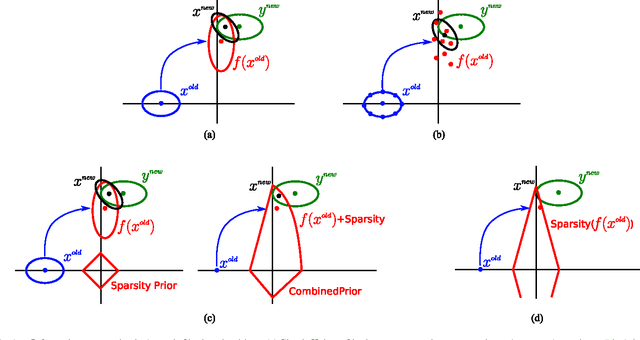
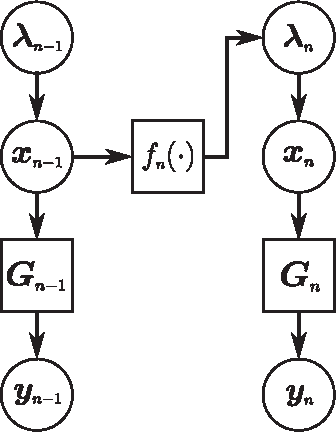
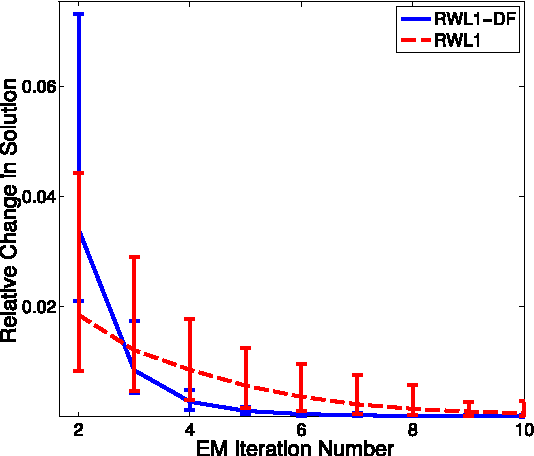
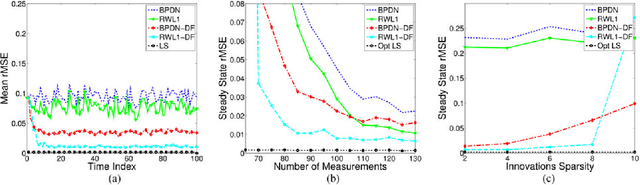
Despite the importance of sparsity signal models and the increasing prevalence of high-dimensional streaming data, there are relatively few algorithms for dynamic filtering of time-varying sparse signals. Of the existing algorithms, fewer still provide strong performance guarantees. This paper examines two algorithms for dynamic filtering of sparse signals that are based on efficient l1 optimization methods. We first present an analysis for one simple algorithm (BPDN-DF) that works well when the system dynamics are known exactly. We then introduce a novel second algorithm (RWL1-DF) that is more computationally complex than BPDN-DF but performs better in practice, especially in the case where the system dynamics model is inaccurate. Robustness to model inaccuracy is achieved by using a hierarchical probabilistic data model and propagating higher-order statistics from the previous estimate (akin to Kalman filtering) in the sparse inference process. We demonstrate the properties of these algorithms on both simulated data as well as natural video sequences. Taken together, the algorithms presented in this paper represent the first strong performance analysis of dynamic filtering algorithms for time-varying sparse signals as well as state-of-the-art performance in this emerging application.
Adaptive Teaching of Temporal Logic Formulas to Learners with Preferences
Jan 27, 2020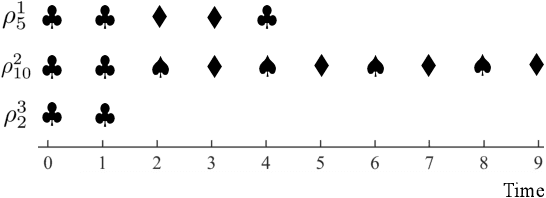

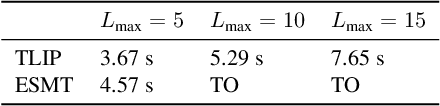
Machine teaching is an algorithmic framework for teaching a target hypothesis via a sequence of examples or demonstrations. We investigate machine teaching for temporal logic formulas -- a novel and expressive hypothesis class amenable to time-related task specifications. In the context of teaching temporal logic formulas, an exhaustive search even for a myopic solution takes exponential time (with respect to the time span of the task). We propose an efficient approach for teaching parametric linear temporal logic formulas. Concretely, we derive a necessary condition for the minimal time length of a demonstration to eliminate a set of hypotheses. Utilizing this condition, we propose a myopic teaching algorithm by solving a sequence of integer programming problems. We further show that, under two notions of teaching complexity, the proposed algorithm has near-optimal performance. The results strictly generalize the previous results on teaching preference-based version space learners. We evaluate our algorithm extensively under a variety of learner types (i.e., learners with different preference models) and interactive protocols (e.g., batched and adaptive). The results show that the proposed algorithms can efficiently teach a given target temporal logic formula under various settings, and that there are significant gains of teaching efficacy when the teacher adapts to the learner's current hypotheses or uses oracles.
Generator Versus Segmentor: Pseudo-healthy Synthesis
Sep 12, 2020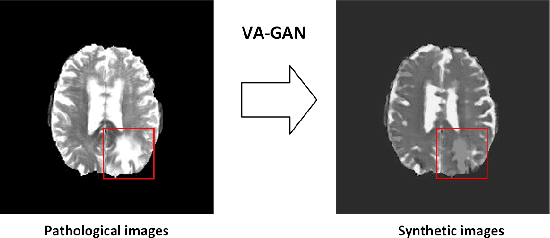
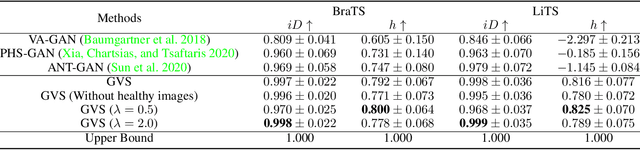
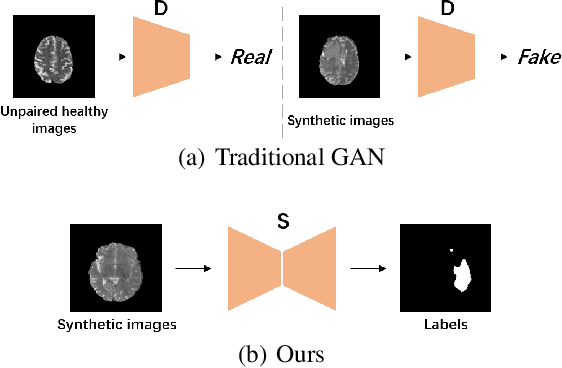
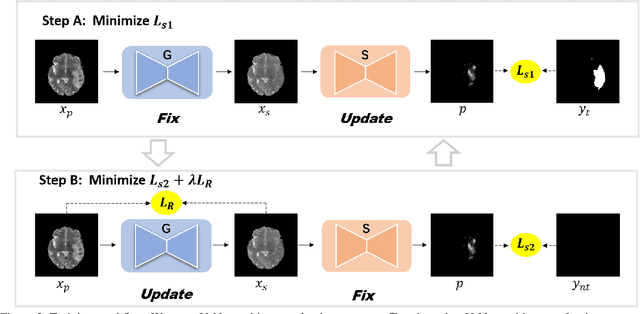
Pseudo-healthy synthesis is defined as synthesizing a subject-specific 'healthy' image from a pathological one, with applications ranging from segmentation to anomaly detection. In recent years, the existing GAN-based methods proposed for pseudo-healthy synthesis aim to eliminate the global differences between synthetic and healthy images. In this paper, we discuss the problems of these approaches, which are the style transfer and artifacts respectively. To address these problems, we consider the local differences between the lesions and normal tissue. To achieve this, we propose an adversarial training regime that alternatively trains a generator and a segmentor. The segmentor is trained to distinguish the synthetic lesions (i.e. the region in synthetic images corresponding to the lesions in the pathological ones) from the normal tissue, while the generator is trained to deceive the segmentor by transforming lesion regions into lesion-free-like ones and preserve the normal tissue at the same time. Qualitative and quantitative experimental results on public datasets BraTS and LiTS demonstrate that the proposed method outperforms state-of-the-art methods by preserving style and removing the artifacts. Our implementation is publicly available at https://github.com/Au3C2/Generator-Versus-Segmentor
Real Time Strategy Language
Jan 21, 2014Real Time Strategy (RTS) games provide complex domain to test the latest artificial intelligence (AI) research. In much of the literature, AI systems have been limited to playing one game. Although, this specialization has resulted in stronger AI gaming systems it does not address the key concerns of AI researcher. AI researchers seek the development of AI agents that can autonomously interpret learn, and apply new knowledge. To achieve human level performance, current AI systems rely on game specific knowledge of an expert. The paper presents the full RTS language in hopes of shifting the current research focus to the development of general RTS agents. General RTS agents are AI gaming systems that can play any RTS games, defined in the RTS language. This prevents game specific knowledge from being hard coded into the system, thereby facilitating research that addresses the fundamental concerns of artificial intelligence.
Powers of layers for image-to-image translation
Aug 13, 2020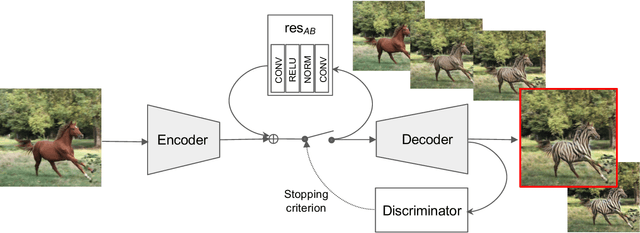
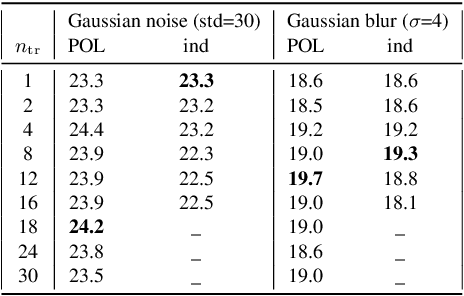
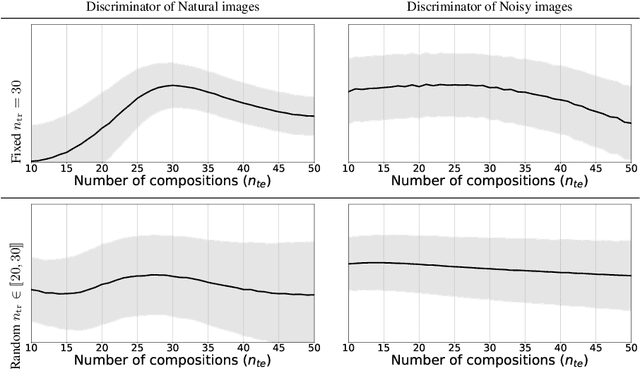
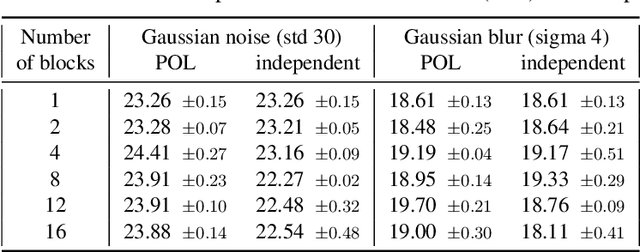
We propose a simple architecture to address unpaired image-to-image translation tasks: style or class transfer, denoising, deblurring, deblocking, etc. We start from an image autoencoder architecture with fixed weights. For each task we learn a residual block operating in the latent space, which is iteratively called until the target domain is reached. A specific training schedule is required to alleviate the exponentiation effect of the iterations. At test time, it offers several advantages: the number of weight parameters is limited and the compositional design allows one to modulate the strength of the transformation with the number of iterations. This is useful, for instance, when the type or amount of noise to suppress is not known in advance. Experimentally, we provide proofs of concepts showing the interest of our method for many transformations. The performance of our model is comparable or better than CycleGAN with significantly fewer parameters.
A Systematic Evaluation of Object Detection Networks for Scientific Plots
Jul 05, 2020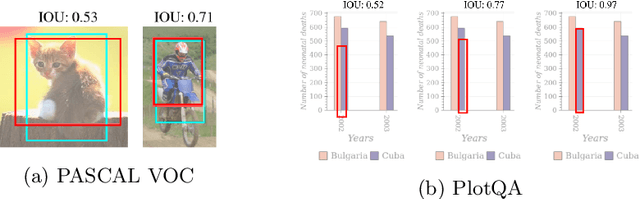
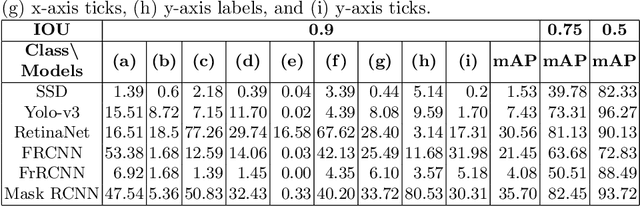

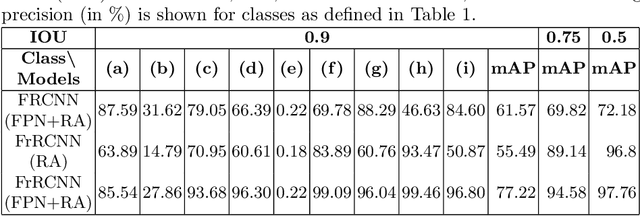
Are existing object detection methods adequate for detecting text and visual elements in scientific plots which are arguably different than the objects found in natural images? To answer this question, we train and compare the accuracy of Fast/Faster R-CNN, SSD, YOLO and RetinaNet on the PlotQA dataset with over 220,000 scientific plots. At the standard IOU setting of 0.5, most networks perform well with mAP scores greater than 80% in detecting the relatively simple objects in plots. However, the performance drops drastically when evaluated at a stricter IOU of 0.9 with the best model giving a mAP of 35.70%. Note that such a stricter evaluation is essential when dealing with scientific plots where even minor localisation errors can lead to large errors in downstream numerical inferences. Given this poor performance, we propose minor modifications to existing models by combining ideas from different object detection networks. While this significantly improves the performance, there are still 2 main issues: (i) performance on text objects which are essential for reasoning is very poor, and (ii) inference time is unacceptably large considering the simplicity of plots. Based on these experiments and results, we identify the following considerations for improving object detection on plots: (a) small inference time, (b) higher precision on text objects, and (c) more accurate localisation with a custom loss function with non-negligible loss values at high IOU (> 0.8). We propose a network which meets all these considerations: It is 16x faster than the best performing competitor and significantly improves upon the accuracy of existing models with a mAP of 93.44%@0.9 IOU.
Strategy for Boosting Pair Comparison and Improving Quality Assessment Accuracy
Oct 01, 2020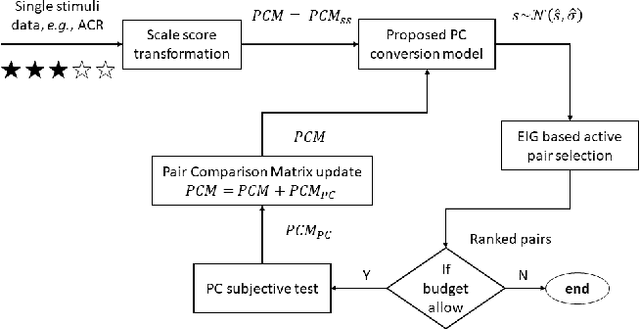
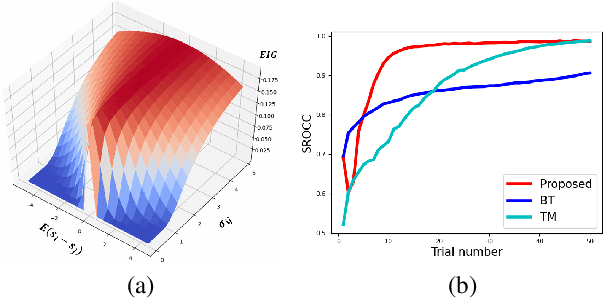
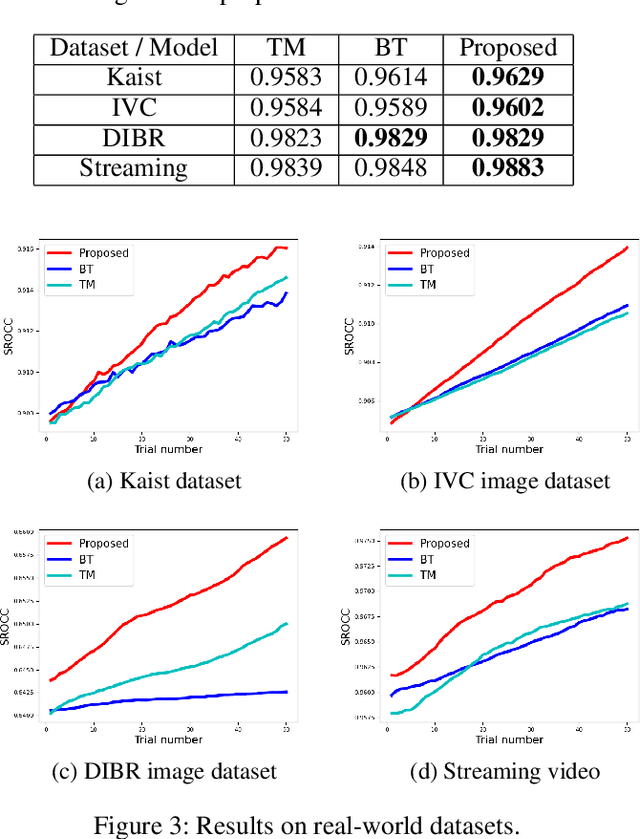
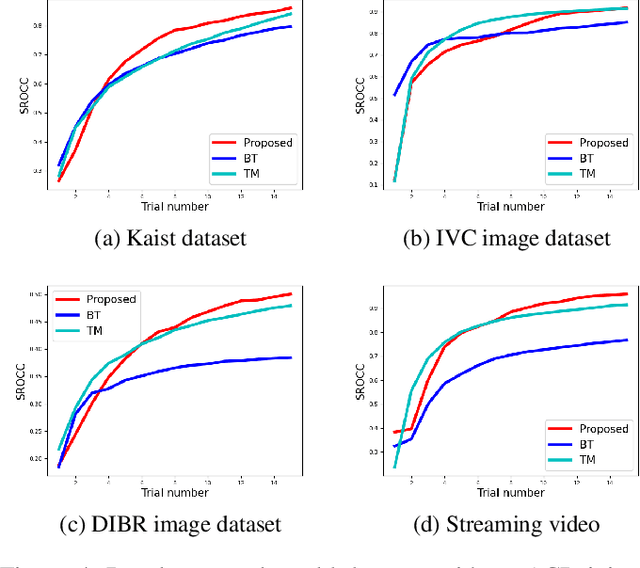
The development of rigorous quality assessment model relies on the collection of reliable subjective data, where the perceived quality of visual multimedia is rated by the human observers. Different subjective assessment protocols can be used according to the objectives, which determine the discriminability and accuracy of the subjective data. Single stimulus methodology, e.g., the Absolute Category Rating (ACR) has been widely adopted due to its simplicity and efficiency. However, Pair Comparison (PC) is of significant advantage over ACR in terms of discriminability. In addition, PC avoids the influence of observers' bias regarding their understanding of the quality scale. Nevertheless, full pair comparison is much more time-consuming. In this study, we therefore 1) employ a generic model to bridge the pair comparison data and ACR data, where the variance term could be recovered and the obtained information is more complete; 2) propose a fusion strategy to boost pair comparisons by utilizing the ACR results as initialization information; 3) develop a novel active batch sampling strategy based on Minimum Spanning Tree (MST) for PC. In such a way, the proposed methodology could achieve the same accuracy of pair comparison but with the compelxity as low as ACR. Extensive experimental results demonstrate the efficiency and accuracy of the proposed approach, which outperforms the state of the art approaches.
PodSumm -- Podcast Audio Summarization
Sep 22, 2020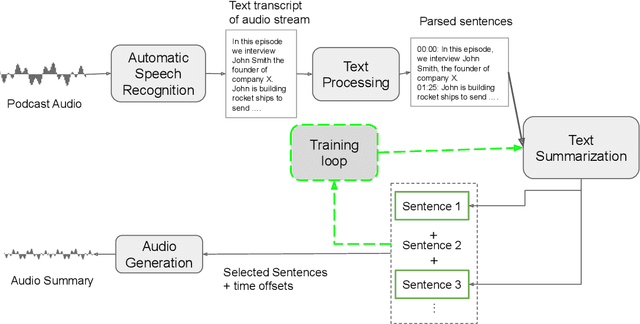
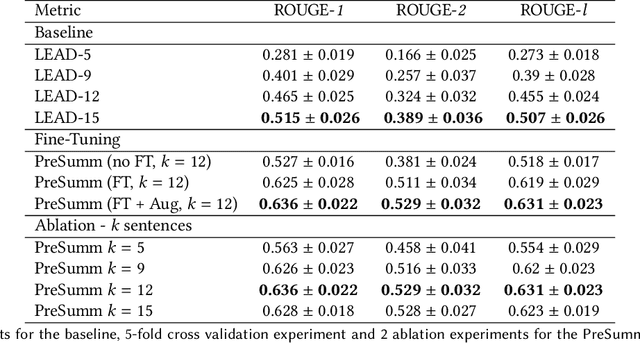
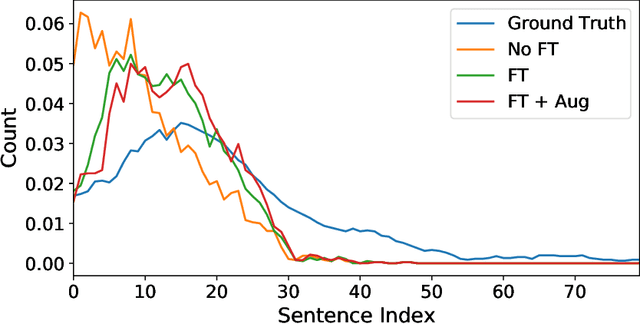
The diverse nature, scale, and specificity of podcasts present a unique challenge to content discovery systems. Listeners often rely on text descriptions of episodes provided by the podcast creators to discover new content. Some factors like the presentation style of the narrator and production quality are significant indicators of subjective user preference but are difficult to quantify and not reflected in the text descriptions provided by the podcast creators. We propose the automated creation of podcast audio summaries to aid in content discovery and help listeners to quickly preview podcast content before investing time in listening to an entire episode. In this paper, we present a method to automatically construct a podcast summary via guidance from the text-domain. Our method performs two key steps, namely, audio to text transcription and text summary generation. Motivated by a lack of datasets for this task, we curate an internal dataset, find an effective scheme for data augmentation, and design a protocol to gather summaries from annotators. We fine-tune a PreSumm[10] model with our augmented dataset and perform an ablation study. Our method achieves ROUGE-F(1/2/L) scores of 0.63/0.53/0.63 on our dataset. We hope these results may inspire future research in this direction.
TrajectoryNet: A Dynamic Optimal Transport Network for Modeling Cellular Dynamics
Feb 09, 2020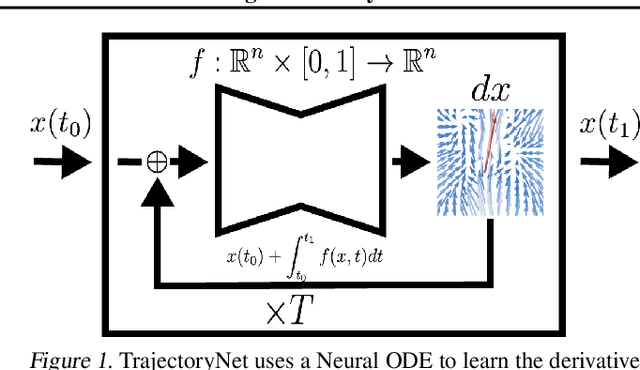
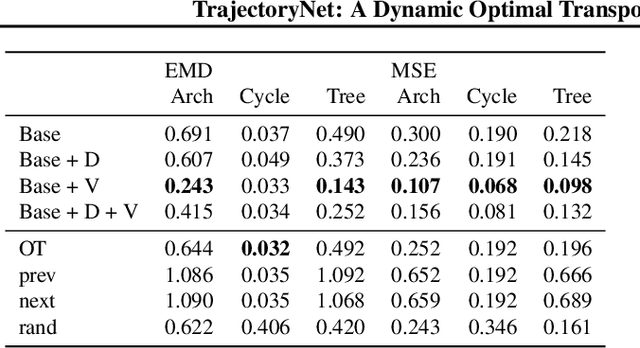
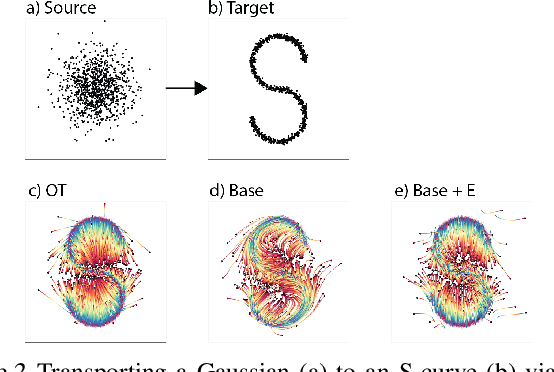
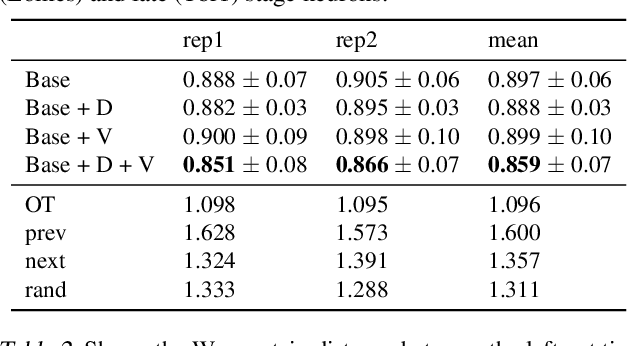
It is increasingly common to encounter data from dynamic processes captured by static cross-sectional measurements over time, particularly in biomedical settings. Recent attempts to model individual trajectories from this data use optimal transport to create pairwise matchings between time points. However, these methods cannot model continuous dynamics and non-linear paths that entities can take in these systems. To address this issue, we establish a link between continuous normalizing flows and dynamic optimal transport, that allows us to model the expected paths of points over time. Continuous normalizing flows are generally under constrained, as they are allowed to take an arbitrary path from the source to the target distribution. We present TrajectoryNet, which controls the continuous paths taken between distributions. We show how this is particularly applicable for studying cellular dynamics in data from single-cell RNA sequencing (scRNA-seq) technologies, and that TrajectoryNet improves upon recently proposed static optimal transport-based models that can be used for interpolating cellular distributions.