 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerator Versus Segmentor: Pseudo-healthy Synthesis
Sep 12, 2020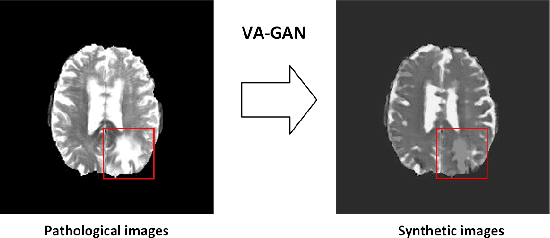
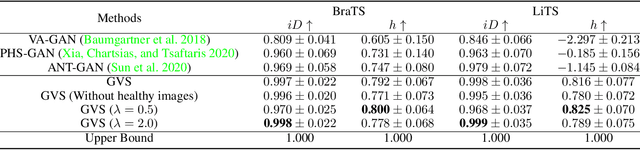
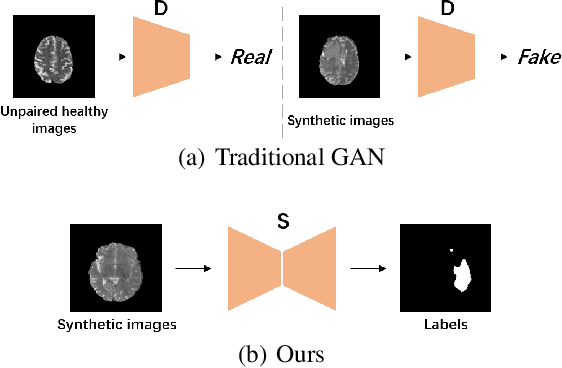
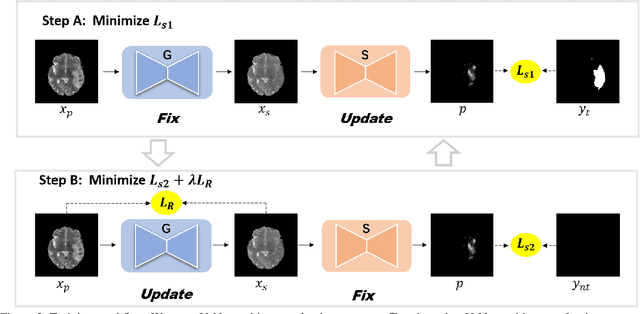
Pseudo-healthy synthesis is defined as synthesizing a subject-specific 'healthy' image from a pathological one, with applications ranging from segmentation to anomaly detection. In recent years, the existing GAN-based methods proposed for pseudo-healthy synthesis aim to eliminate the global differences between synthetic and healthy images. In this paper, we discuss the problems of these approaches, which are the style transfer and artifacts respectively. To address these problems, we consider the local differences between the lesions and normal tissue. To achieve this, we propose an adversarial training regime that alternatively trains a generator and a segmentor. The segmentor is trained to distinguish the synthetic lesions (i.e. the region in synthetic images corresponding to the lesions in the pathological ones) from the normal tissue, while the generator is trained to deceive the segmentor by transforming lesion regions into lesion-free-like ones and preserve the normal tissue at the same time. Qualitative and quantitative experimental results on public datasets BraTS and LiTS demonstrate that the proposed method outperforms state-of-the-art methods by preserving style and removing the artifacts. Our implementation is publicly available at https://github.com/Au3C2/Generator-Versus-Segmentor
Hard Class Rectification for Domain Adaptation
Aug 08, 2020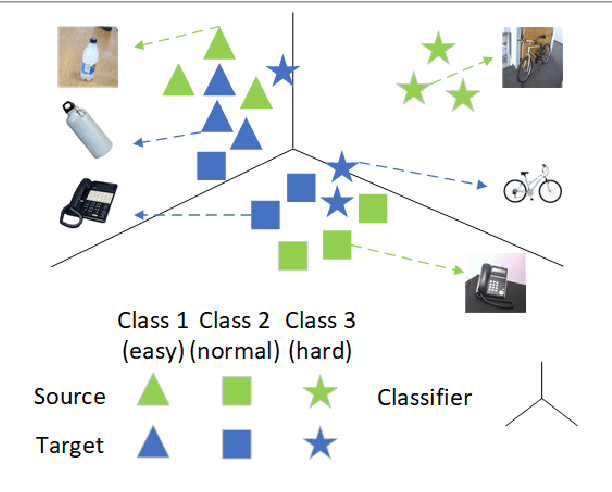
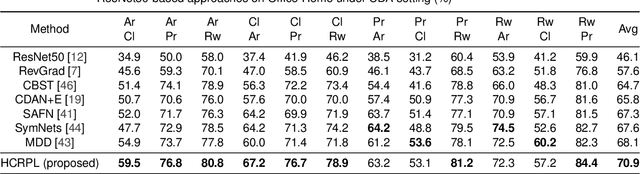
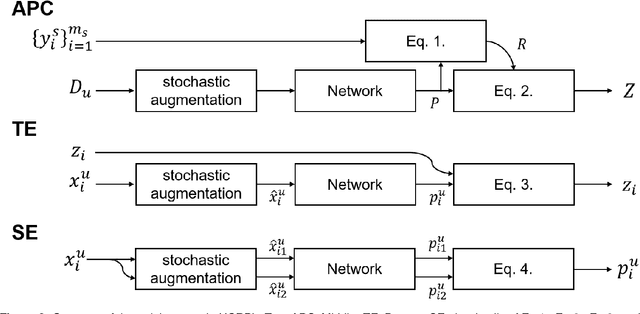
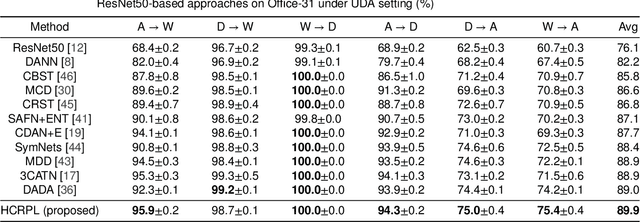
Domain adaptation (DA) aims to transfer knowledge from a label-rich and related domain (source domain) to a label-scare domain (target domain). Pseudo-labeling has recently been widely explored and used in DA. However, this line of research is still confined to the inaccuracy of pseudo-labels. In this paper, we reveal an interesting observation that the target samples belonging to the classes with larger domain shift are easier to be misclassified compared with the other classes. These classes are called hard class, which deteriorates the performance of DA and restricts the applications of DA. We propose a novel framework, called Hard Class Rectification Pseudo-labeling (HCRPL), to alleviate the hard class problem from two aspects. First, as is difficult to identify the target samples as hard class, we propose a simple yet effective scheme, named Adaptive Prediction Calibration (APC), to calibrate the predictions of the target samples according to the difficulty degree for each class. Second, we further consider that the predictions of target samples belonging to the hard class are vulnerable to perturbations. To prevent these samples to be misclassified easily, we introduce Temporal-Ensembling (TE) and Self-Ensembling (SE) to obtain consistent predictions. The proposed method is evaluated in both unsupervised domain adaptation (UDA) and semi-supervised domain adaptation (SSDA). The experimental results on several real-world cross-domain benchmarks, including ImageCLEF, Office-31 and Office-Home, substantiates the superiority of the proposed method.