 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Disentanglement Then Reconstruction: Learning Compact Features for Unsupervised Domain Adaptation
May 28, 2020
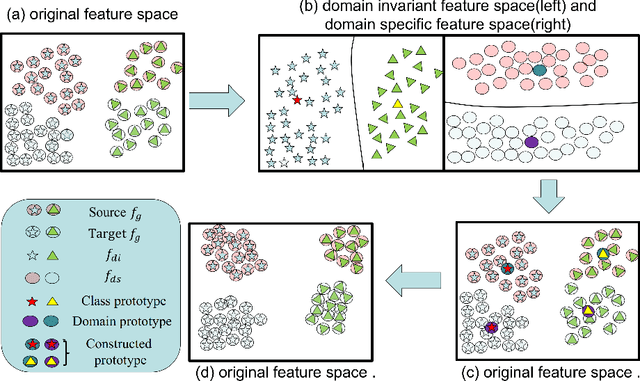
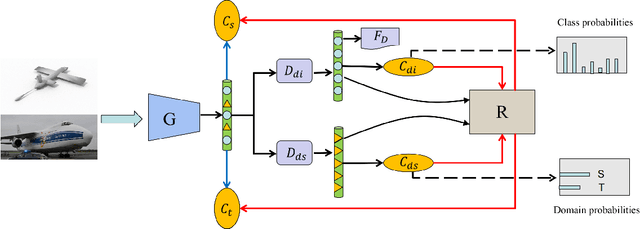
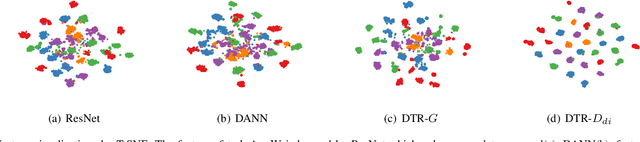
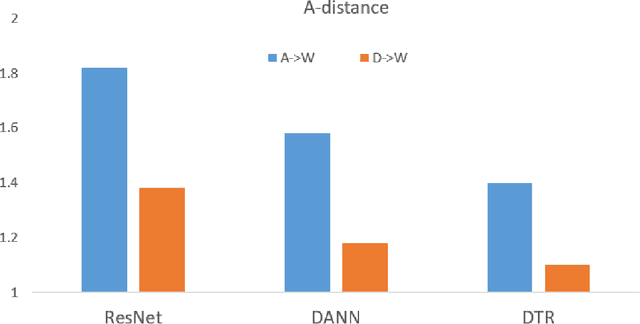
Recent works in domain adaptation always learn domain invariant features to mitigate the gap between the source and target domains by adversarial methods. The category information are not sufficiently used which causes the learned domain invariant features are not enough discriminative. We propose a new domain adaptation method based on prototype construction which likes capturing data cluster centers. Specifically, it consists of two parts: disentanglement and reconstruction. First, the domain specific features and domain invariant features are disentangled from the original features. At the same time, the domain prototypes and class prototypes of both domains are estimated. Then, a reconstructor is trained by reconstructing the original features from the disentangled domain invariant features and domain specific features. By this reconstructor, we can construct prototypes for the original features using class prototypes and domain prototypes correspondingly. In the end, the feature extraction network is forced to extract features close to these prototypes. Our contribution lies in the technical use of the reconstructor to obtain the original feature prototypes which helps to learn compact and discriminant features. As far as we know, this idea is proposed for the first time. Experiment results on several public datasets confirm the state-of-the-art performance of our method.
Performance characterization of a novel deep learning-based MR image reconstruction pipeline
Aug 14, 2020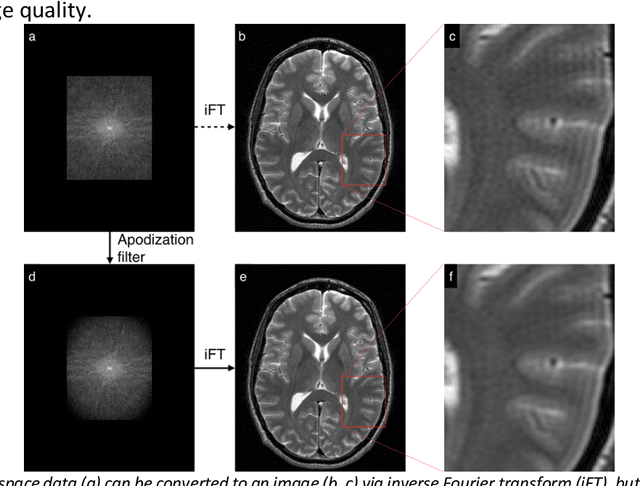
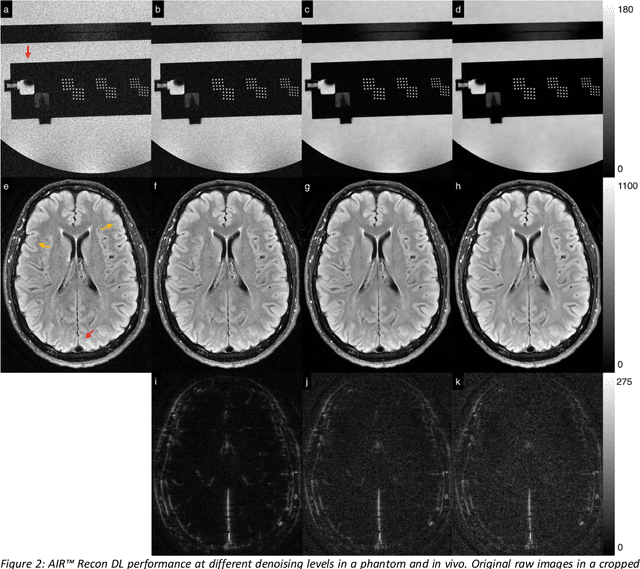
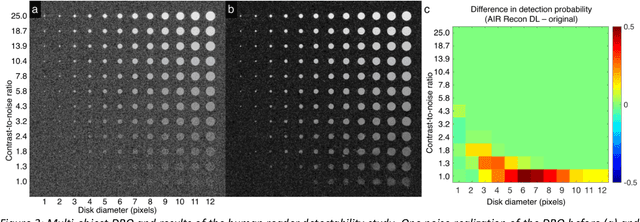
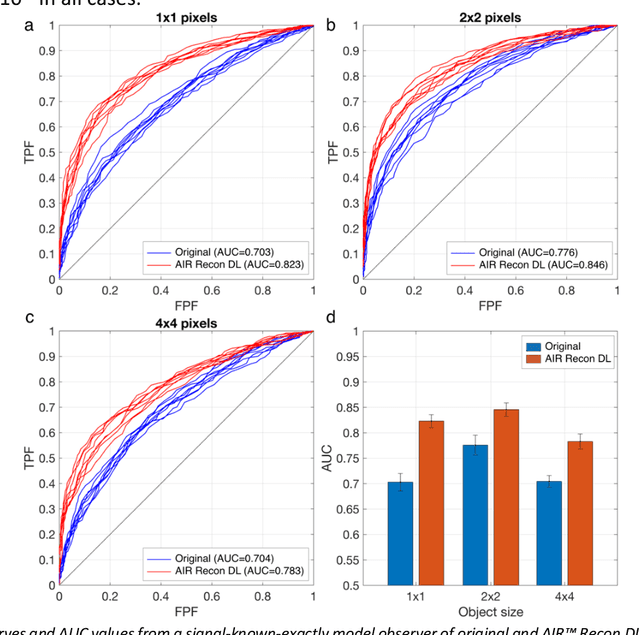
A novel deep learning-based magnetic resonance imaging reconstruction pipeline was designed to address fundamental image quality limitations of conventional reconstruction to provide high-resolution, low-noise MR images. This pipeline's unique aims were to convert truncation artifact into improved image sharpness while jointly denoising images to improve image quality. This new approach, now commercially available at AIR Recon DL (GE Healthcare, Waukesha, WI), includes a deep convolutional neural network (CNN) to aid in the reconstruction of raw data, ultimately producing clean, sharp images. Here we describe key features of this pipeline and its CNN, characterize its performance in digital reference objects, phantoms, and in-vivo, and present sample images and protocol optimization strategies that leverage image quality improvement for reduced scan time. This new deep learning-based reconstruction pipeline represents a powerful new tool to increase the diagnostic and operational performance of an MRI scanner.
Mining Persistent Activity in Continually Evolving Networks
Jun 27, 2020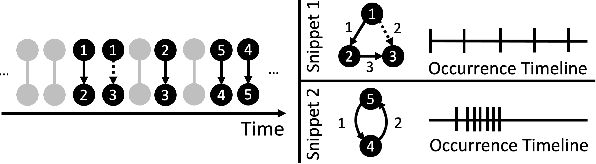

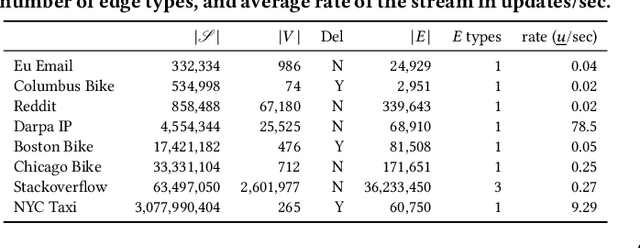
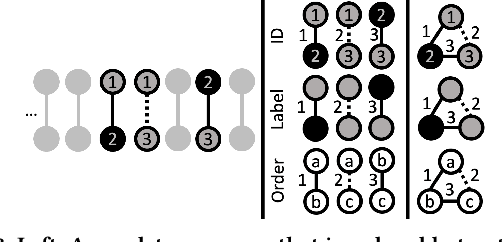
Frequent pattern mining is a key area of study that gives insights into the structure and dynamics of evolving networks, such as social or road networks. However, not only does a network evolve, but often the way that it evolves, itself evolves. Thus, knowing, in addition to patterns' frequencies, for how long and how regularly they have occurred---i.e., their persistence---can add to our understanding of evolving networks. In this work, we propose the problem of mining activity that persists through time in continually evolving networks---i.e., activity that repeatedly and consistently occurs. We extend the notion of temporal motifs to capture activity among specific nodes, in what we call activity snippets, which are small sequences of edge-updates that reoccur. We propose axioms and properties that a measure of persistence should satisfy, and develop such a persistence measure. We also propose PENminer, an efficient framework for mining activity snippets' Persistence in Evolving Networks, and design both offline and streaming algorithms. We apply PENminer to numerous real, large-scale evolving networks and edge streams, and find activity that is surprisingly regular over a long period of time, but too infrequent to be discovered by aggregate count alone, and bursts of activity exposed by their lack of persistence. Our findings with PENminer include neighborhoods in NYC where taxi traffic persisted through Hurricane Sandy, the opening of new bike-stations, characteristics of social network users, and more. Moreover, we use PENminer towards identifying anomalies in multiple networks, outperforming baselines at identifying subtle anomalies by 9.8-48% in AUC.
Bayesian Neural Architecture Search using A Training-Free Performance Metric
Jan 29, 2020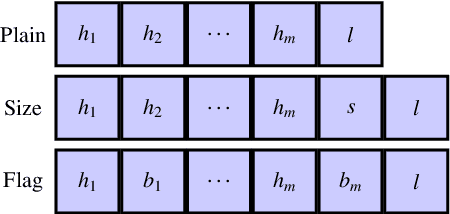


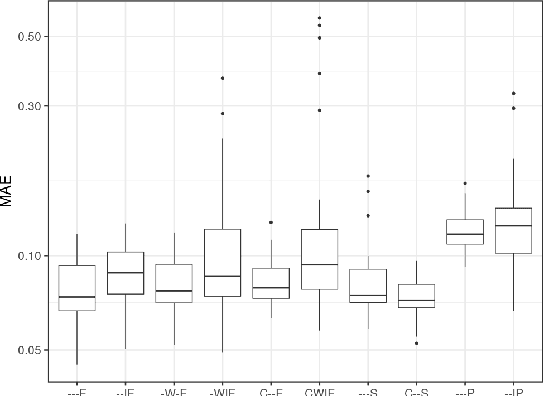
Recurrent neural networks (RNNs) are a powerful approach for time series prediction. However, their performance is strongly affected by their architecture and hyperparameter settings. The architecture optimization of RNNs is a time-consuming task, where the search space is typically a mixture of real, integer and categorical values. To allow for shrinking and expanding the size of the network, the representation of architectures often has a variable length. In this paper, we propose to tackle the architecture optimization problem with a variant of the Bayesian Optimization (BO) algorithm. To reduce the evaluation time of candidate architectures the Mean Absolute Error Random Sampling (MRS), a training-free method to estimate the network performance, is adopted as the objective function for BO. Also, we propose three fixed-length encoding schemes to cope with the variable-length architecture representation. The result is a new perspective on accurate and efficient design of RNNs, that we validate on three problems. Our findings show that 1) the BO algorithm can explore different network architectures using the proposed encoding schemes and successfully designs well-performing architectures, and 2) the optimization time is significantly reduced by using MRS, without compromising the performance as compared to the architectures obtained from the actual training procedure.
An Experimental Evaluation of Robustness and Precision for Long-term LiDAR-based Localization in Highly Changing Environments
Mar 17, 2020


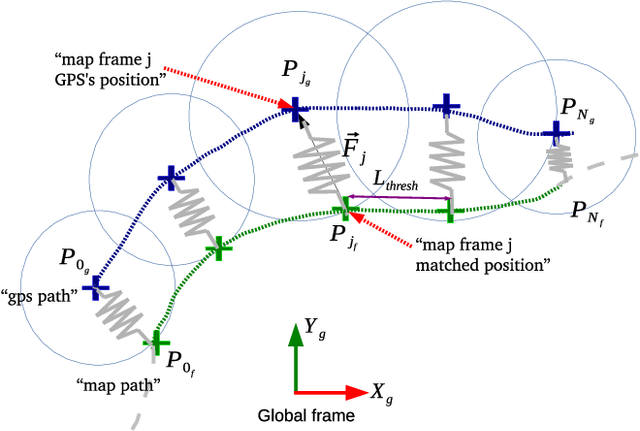
One of the hardest challenges to face in the development of a non GPS-based localization system for autonomous vehicles is the changes of the environment. LiDAR-based systems typically try to match the last measurements obtained with a previously recorded map of the area. If the existing map is not updated along time, there is a good chance that the measures will not match the environment well enough, causing the vehicle to lose track of its location. In this paper, we present and analyze experimental results regarding the robustness and precision of a map-matching based localization system over a certain period of time in the following three cases: (1) without any update of the initial map, (2) updating the map as the vehicle moves and (3) with map updates that take into account surrounding structures labeled as "fixed" which are treated differently. The environment of the tests is a busy parking area, which ensures drastic changes from one day to the next. The precision is obtained by comparing the positions computed using the map with the ones provided by a Real-Time Kinematic GPS system. The experimental results reveal a positioning error of about 6cm which remains stable even after 23 days when using fixed structures on the working area.
SHREC 2020 track: 6D Object Pose Estimation
Oct 19, 2020
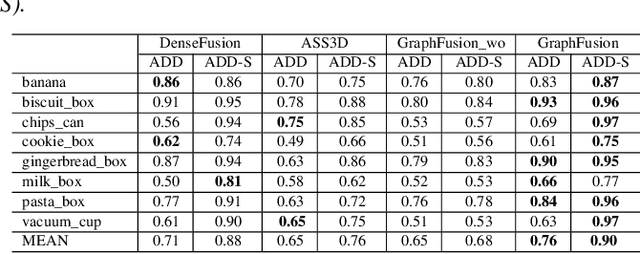
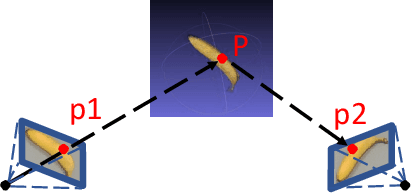
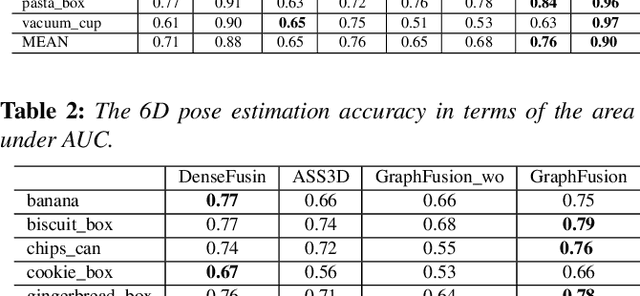
6D pose estimation is crucial for augmented reality, virtual reality, robotic manipulation and visual navigation. However, the problem is challenging due to the variety of objects in the real world. They have varying 3D shape and their appearances in captured images are affected by sensor noise, changing lighting conditions and occlusions between objects. Different pose estimation methods have different strengths and weaknesses, depending on feature representations and scene contents. At the same time, existing 3D datasets that are used for data-driven methods to estimate 6D poses have limited view angles and low resolution. To address these issues, we organize the Shape Retrieval Challenge benchmark on 6D pose estimation and create a physically accurate simulator that is able to generate photo-realistic color-and-depth image pairs with corresponding ground truth 6D poses. From captured color and depth images, we use this simulator to generate a 3D dataset which has 400 photo-realistic synthesized color-and-depth image pairs with various view angles for training, and another 100 captured and synthetic images for testing. Five research groups register in this track and two of them submitted their results. Data-driven methods are the current trend in 6D object pose estimation and our evaluation results show that approaches which fully exploit the color and geometric features are more robust for 6D pose estimation of reflective and texture-less objects and occlusion. This benchmark and comparative evaluation results have the potential to further enrich and boost the research of 6D object pose estimation and its applications.
More Effective Randomized Search Heuristics for Graph Coloring Through Dynamic Optimization
May 28, 2020
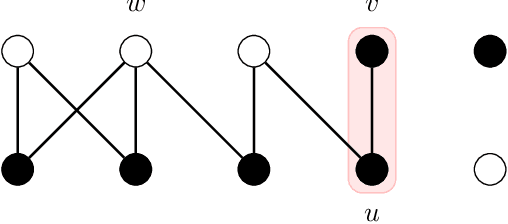
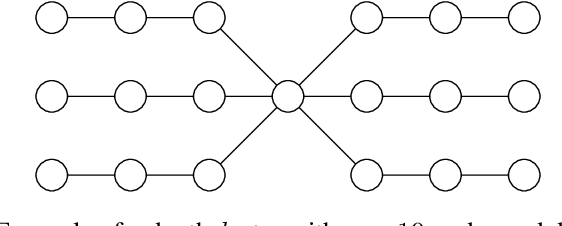

Dynamic optimization problems have gained significant attention in evolutionary computation as evolutionary algorithms (EAs) can easily adapt to changing environments. We show that EAs can solve the graph coloring problem for bipartite graphs more efficiently by using dynamic optimization. In our approach the graph instance is given incrementally such that the EA can reoptimize its coloring when a new edge introduces a conflict. We show that, when edges are inserted in a way that preserves graph connectivity, Randomized Local Search (RLS) efficiently finds a proper 2-coloring for all bipartite graphs. This includes graphs for which RLS and other EAs need exponential expected time in a static optimization scenario. We investigate different ways of building up the graph by popular graph traversals such as breadth-first-search and depth-first-search and analyse the resulting runtime behavior. We further show that offspring populations (e. g. a (1+$\lambda$) RLS) lead to an exponential speedup in $\lambda$. Finally, an island model using 3 islands succeeds in an optimal time of $\Theta(m)$ on every $m$-edge bipartite graph, outperforming offspring populations. This is the first example where an island model guarantees a speedup that is not bounded in the number of islands.
Large Population Sizes and Crossover Help in Dynamic Environments
Apr 21, 2020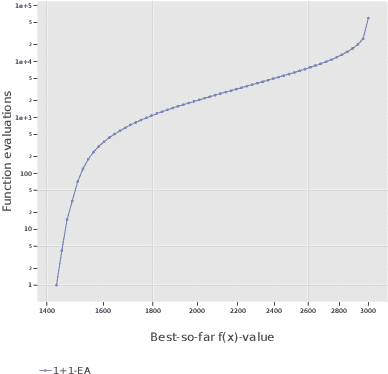
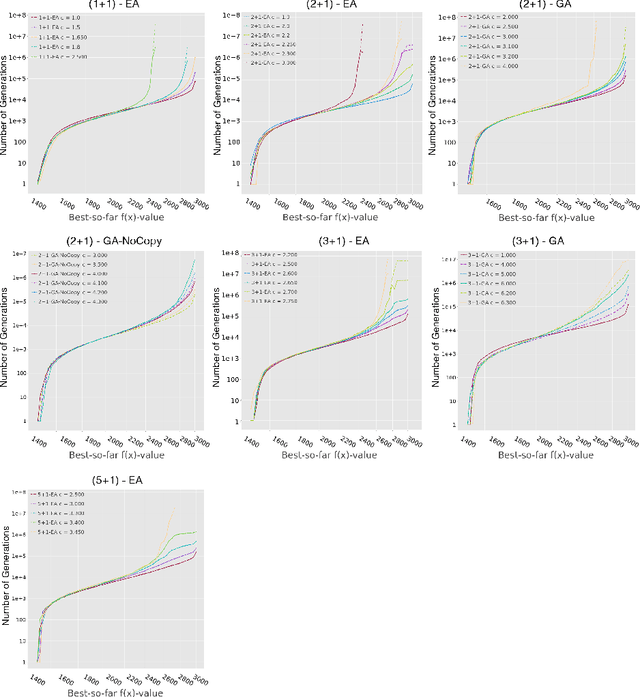
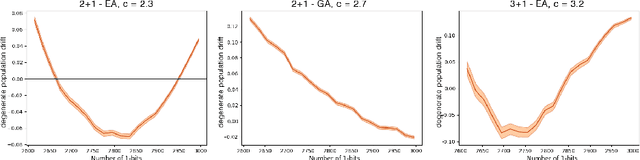
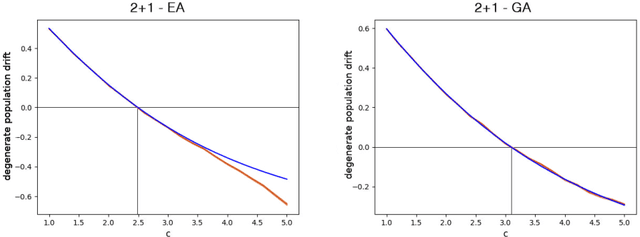
Dynamic linear functions on the hypercube are functions which assign to each bit a positive weight, but the weights change over time. Throughout optimization, these functions maintain the same global optimum, and never have defecting local optima. Nevertheless, it was recently shown [Lengler, Schaller, FOCI 2019] that the $(1+1)$-Evolutionary Algorithm needs exponential time to find or approximate the optimum for some algorithm configurations. In this paper, we study the effect of larger population sizes for Dynamic BinVal, the extremal form of dynamic linear functions. We find that moderately increased population sizes extend the range of efficient algorithm configurations, and that crossover boosts this positive effect substantially. Remarkably, similar to the static setting of monotone functions in [Lengler, Zou, FOGA 2019], the hardest region of optimization for $(\mu+1)$-EA is not close the optimum, but far away from it. In contrast, for the $(\mu+1)$-GA, the region around the optimum is the hardest region in all studied cases.
Benchmarking in Optimization: Best Practice and Open Issues
Jul 07, 2020
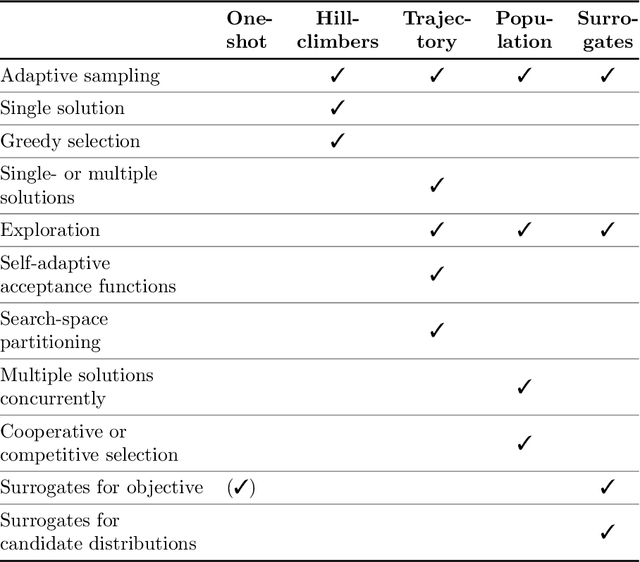
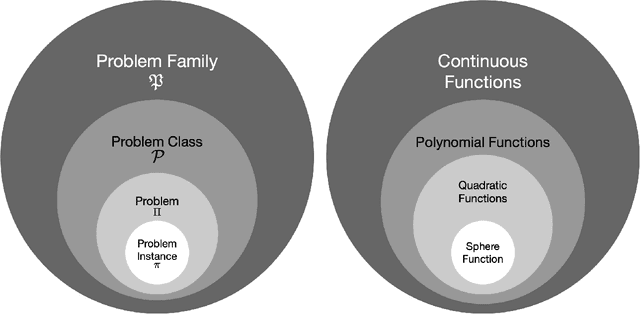

This survey compiles ideas and recommendations from more than a dozen researchers with different backgrounds and from different institutes around the world. Promoting best practice in benchmarking is its main goal. The article discusses eight essential topics in benchmarking: clearly stated goals, well-specified problems, suitable algorithms, adequate performance measures, thoughtful analysis, effective and efficient designs, comprehensible presentations, and guaranteed reproducibility. The final goal is to provide well-accepted guidelines (rules) that might be useful for authors and reviewers. As benchmarking in optimization is an active and evolving field of research this manuscript is meant to co-evolve over time by means of periodic updates.
Defending Regression Learners Against Poisoning Attacks
Aug 21, 2020
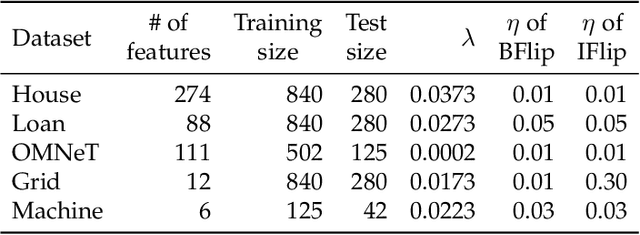

Regression models, which are widely used from engineering applications to financial forecasting, are vulnerable to targeted malicious attacks such as training data poisoning, through which adversaries can manipulate their predictions. Previous works that attempt to address this problem rely on assumptions about the nature of the attack/attacker or overestimate the knowledge of the learner, making them impractical. We introduce a novel Local Intrinsic Dimensionality (LID) based measure called N-LID that measures the local deviation of a given data point's LID with respect to its neighbors. We then show that N-LID can distinguish poisoned samples from normal samples and propose an N-LID based defense approach that makes no assumptions of the attacker. Through extensive numerical experiments with benchmark datasets, we show that the proposed defense mechanism outperforms the state of the art defenses in terms of prediction accuracy (up to 76% lower MSE compared to an undefended ridge model) and running time.