 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Group Activity Prediction with Sequential Relational Anticipation Model
Aug 06, 2020
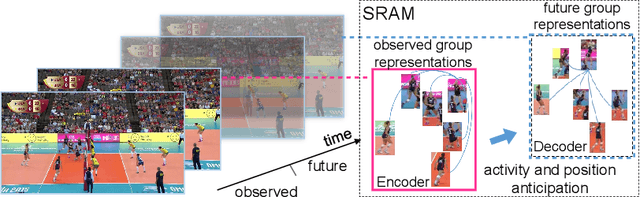
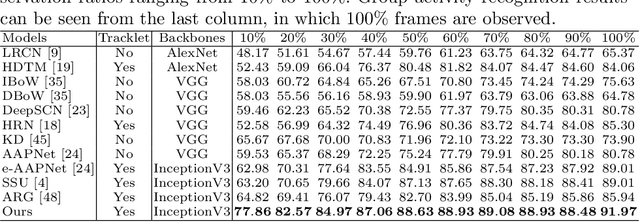

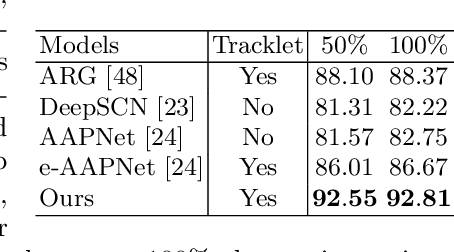
In this paper, we propose a novel approach to predict group activities given the beginning frames with incomplete activity executions. Existing action prediction approaches learn to enhance the representation power of the partial observation. However, for group activity prediction, the relation evolution of people's activity and their positions over time is an important cue for predicting group activity. To this end, we propose a sequential relational anticipation model (SRAM) that summarizes the relational dynamics in the partial observation and progressively anticipates the group representations with rich discriminative information. Our model explicitly anticipates both activity features and positions by two graph auto-encoders, aiming to learn a discriminative group representation for group activity prediction. Experimental results on two popularly used datasets demonstrate that our approach significantly outperforms the state-of-the-art activity prediction methods.
Disentangled Representations for Domain-generalized Cardiac Segmentation
Aug 26, 2020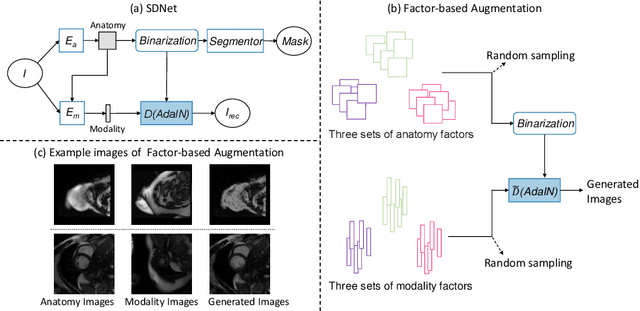
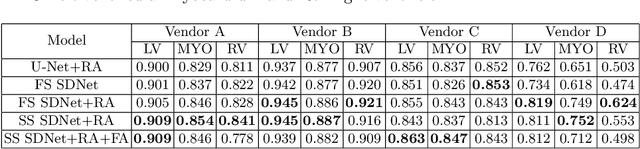
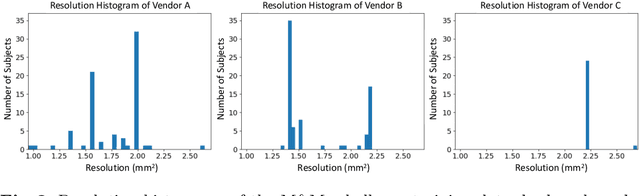
Robust cardiac image segmentation is still an open challenge due to the inability of the existing methods to achieve satisfactory performance on unseen data of different domains. Since the acquisition and annotation of medical data are costly and time-consuming, recent work focuses on domain adaptation and generalization to bridge the gap between data from different populations and scanners. In this paper, we propose two data augmentation methods that focus on improving the domain adaptation and generalization abilities of state-to-the-art cardiac segmentation models. In particular, our "Resolution Augmentation" method generates more diverse data by rescaling images to different resolutions within a range spanning different scanner protocols. Subsequently, our "Factor-based Augmentation" method generates more diverse data by projecting the original samples onto disentangled latent spaces, and combining the learned anatomy and modality factors from different domains. Our extensive experiments demonstrate the importance of efficient adaptation between seen and unseen domains, as well as model generalization ability, to robust cardiac image segmentation.
Foundations of Reasoning with Uncertainty via Real-valued Logics
Aug 06, 2020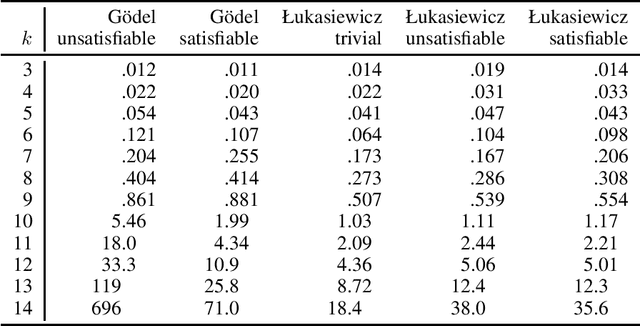
Real-valued logics underlie an increasing number of neuro-symbolic approaches, though typically their logical inference capabilities are characterized only qualitatively. We provide foundations for establishing the correctness and power of such systems. For the first time, we give a sound and complete axiomatization for a broad class containing all the common real-valued logics. This axiomatization allows us to derive exactly what information can be inferred about the combinations of real values of a collection of formulas given information about the combinations of real values of several other collections of formulas. We then extend the axiomatization to deal with weighted subformulas. Finally, we give a decision procedure based on linear programming for deciding, under certain natural assumptions, whether a set of our sentences logically implies another of our sentences.
Detecting and adapting to crisis pattern with context based Deep Reinforcement Learning
Sep 07, 2020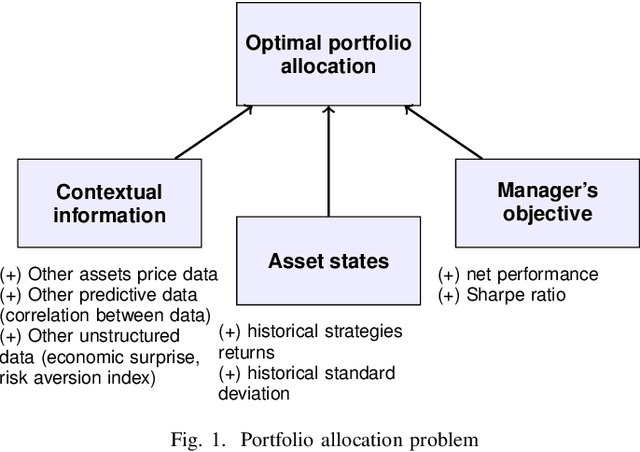

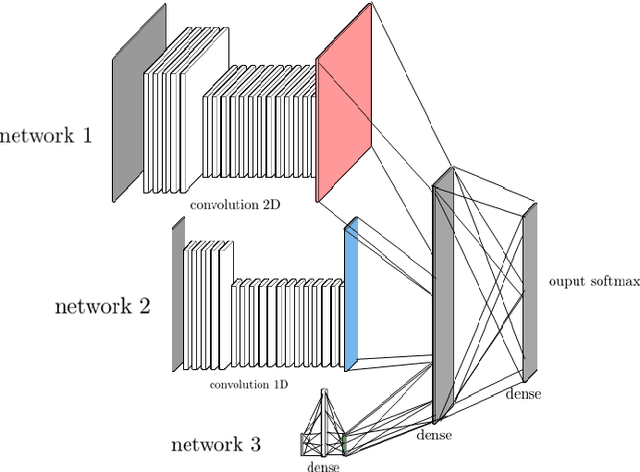
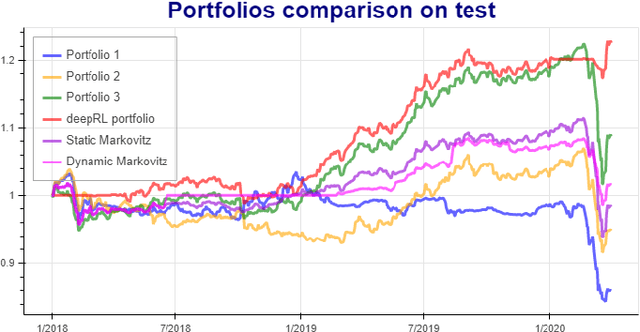
Deep reinforcement learning (DRL) has reached super human levels in complex tasks like game solving (Go and autonomous driving). However, it remains an open question whether DRL can reach human level in applications to financial problems and in particular in detecting pattern crisis and consequently dis-investing. In this paper, we present an innovative DRL framework consisting in two sub-networks fed respectively with portfolio strategies past performances and standard deviations as well as additional contextual features. The second sub network plays an important role as it captures dependencies with common financial indicators features like risk aversion, economic surprise index and correlations between assets that allows taking into account context based information. We compare different network architectures either using layers of convolutions to reduce network's complexity or LSTM block to capture time dependency and whether previous allocations is important in the modeling. We also use adversarial training to make the final model more robust. Results on test set show this approach substantially over-performs traditional portfolio optimization methods like Markowitz and is able to detect and anticipate crisis like the current Covid one.
Time Series Deinterleaving of DNS Traffic
Jul 16, 2018
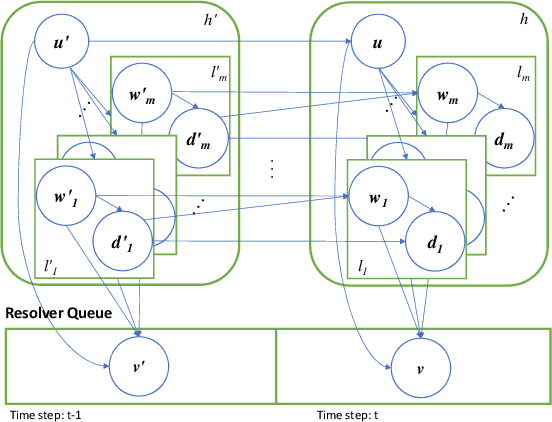
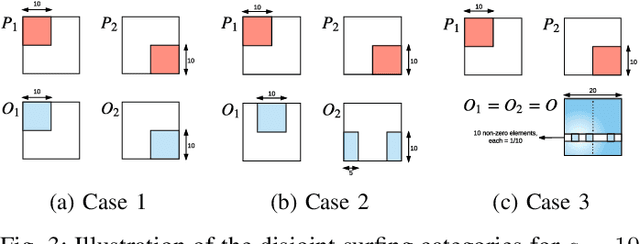

Stream deinterleaving is an important problem with various applications in the cybersecurity domain. In this paper, we consider the specific problem of deinterleaving DNS data streams using machine-learning techniques, with the objective of automating the extraction of malware domain sequences. We first develop a generative model for user request generation and DNS stream interleaving. Based on these we evaluate various inference strategies for deinterleaving including augmented HMMs and LSTMs on synthetic datasets. Our results demonstrate that state-of-the-art LSTMs outperform more traditional augmented HMMs in this application domain.
Moving object detection for visual odometry in a dynamic environment based on occlusion accumulation
Sep 18, 2020



Detection of moving objects is an essential capability in dealing with dynamic environments. Most moving object detection algorithms have been designed for color images without depth. For robotic navigation where real-time RGB-D data is often readily available, utilization of the depth information would be beneficial for obstacle recognition. Here, we propose a simple moving object detection algorithm that uses RGB-D images. The proposed algorithm does not require estimating a background model. Instead, it uses an occlusion model which enables us to estimate the camera pose on a background confused with moving objects that dominate the scene. The proposed algorithm allows to separate the moving object detection and visual odometry (VO) so that an arbitrary robust VO method can be employed in a dynamic situation with a combination of moving object detection, whereas other VO algorithms for a dynamic environment are inseparable. In this paper, we use dense visual odometry (DVO) as a VO method with a bi-square regression weight. Experimental results show the segmentation accuracy and the performance improvement of DVO in the situations. We validate our algorithm in public datasets and our dataset which also publicly accessible.
* 7 pages
Picking Winning Tickets Before Training by Preserving Gradient Flow
Feb 18, 2020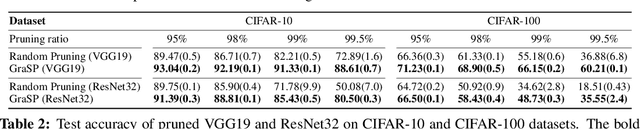
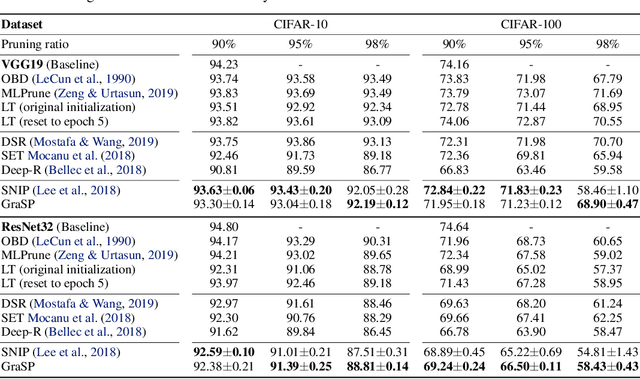
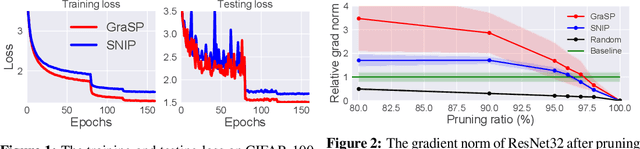
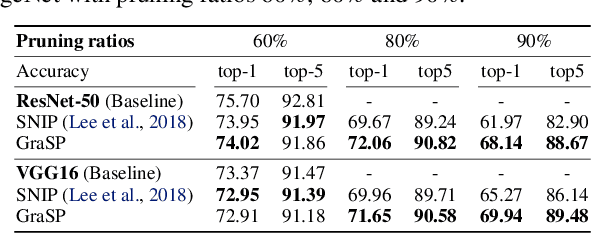
Overparameterization has been shown to benefit both the optimization and generalization of neural networks, but large networks are resource hungry at both training and test time. Network pruning can reduce test-time resource requirements, but is typically applied to trained networks and therefore cannot avoid the expensive training process. We aim to prune networks at initialization, thereby saving resources at training time as well. Specifically, we argue that efficient training requires preserving the gradient flow through the network. This leads to a simple but effective pruning criterion we term Gradient Signal Preservation (GraSP). We empirically investigate the effectiveness of the proposed method with extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet and ImageNet, using VGGNet and ResNet architectures. Our method can prune 80% of the weights of a VGG-16 network on ImageNet at initialization, with only a 1.6% drop in top-1 accuracy. Moreover, our method achieves significantly better performance than the baseline at extreme sparsity levels.
* Accepted at ICLR 2020
Why should we add early exits to neural networks?
Apr 27, 2020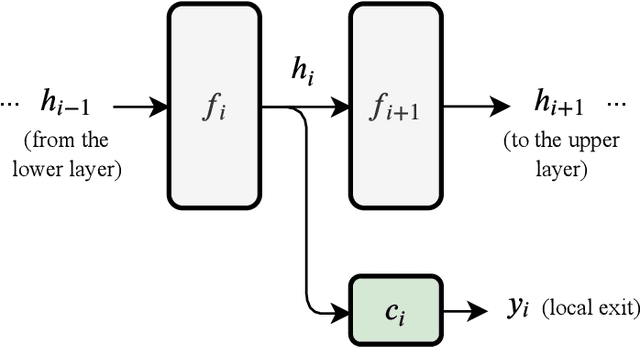
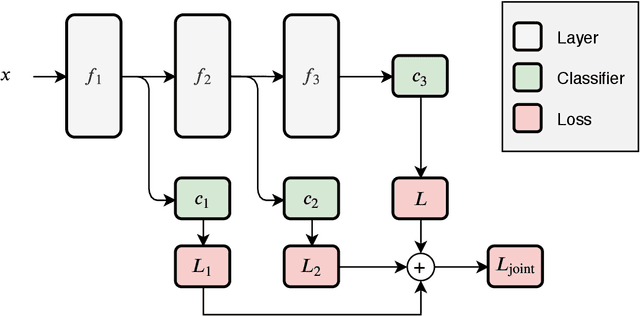
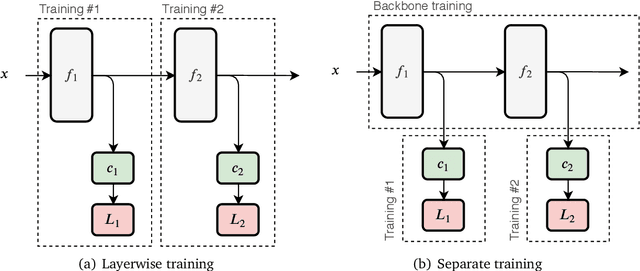
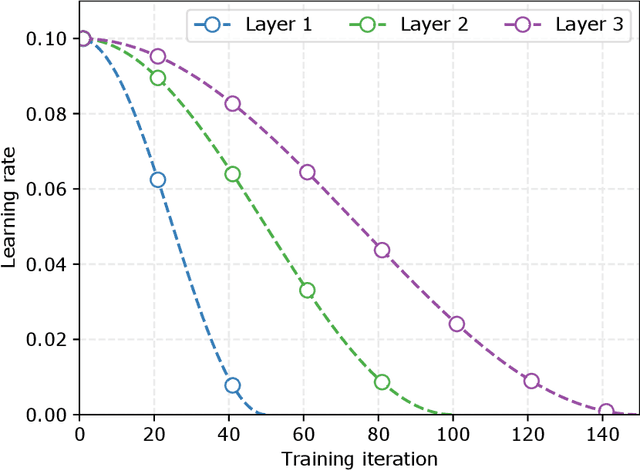
Deep neural networks are generally designed as a stack of differentiable layers, in which a prediction is obtained only after running the full stack. Recently, some contributions have proposed techniques to endow the networks with early exits, allowing to obtain predictions at intermediate points of the stack. These multi-output networks have a number of advantages, including: (i) significant reductions of the inference time, (ii) reduced tendency to overfitting and vanishing gradients, and (iii) capability of being distributed over multi-tier computation platforms. In addition, they connect to the wider themes of biological plausibility and layered cognitive reasoning. In this paper, we provide a comprehensive introduction to this family of neural networks, by describing in a unified fashion the way these architectures can be designed, trained, and actually deployed in time-constrained scenarios. We also describe in-depth their application scenarios in 5G and Fog computing environments, as long as some of the open research questions connected to them.
Universal Lower-Bounds on Classification Error under Adversarial Attacks and Random Corruption
Jun 23, 2020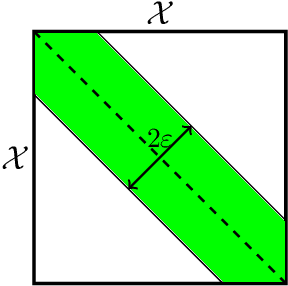
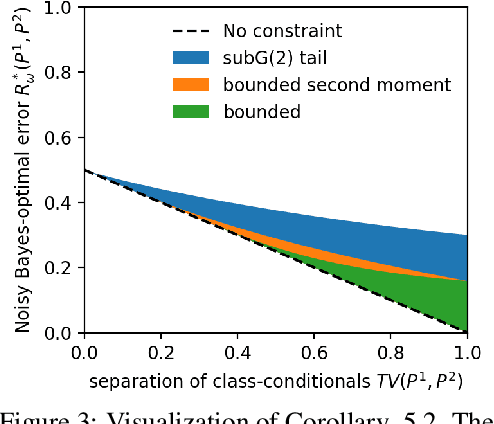
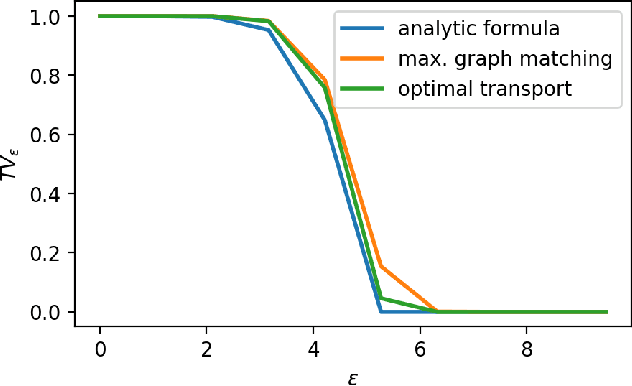
We theoretically analyse the limits of robustness to test-time adversarial and noisy examples in classification. Our work focuses on deriving bounds which uniformly apply to all classifiers (i.e all measurable functions from features to labels) for a given problem. Our contributions are three-fold. (1) In the classical framework of adversarial attacks, we use optimal transport theory to derive variational formulae for the Bayes-optimal error a classifier can make on a given classification problem, subject to adversarial attacks. The optimal adversarial attack is then an optimal transport plan for a certain binary cost-function induced by the specific attack model, and can be computed via a simple algorithm based on maximal matching on bipartite graphs. (2) We derive explicit lower-bounds on the Bayes-optimal error in the case of the popular distance-based attacks. These bounds are universal in the sense that they depend on the geometry of the class-conditional distributions of the data, but not on a particular classifier. Our results are in sharp contrast with the existing literature, wherein adversarial vulnerability of classifiers is derived as a consequence of nonzero ordinary test error. (3) For our third contribution, we study robustness to random noise corruption, wherein the attacker (or nature) is allowed to inject random noise into examples at test time. We establish nonlinear data-processing inequalities induced by such corruptions, and use them to obtain lower-bounds on the Bayes-optimal error for noisy problem.
Approximate Message Passing with Spectral Initialization for Generalized Linear Models
Oct 07, 2020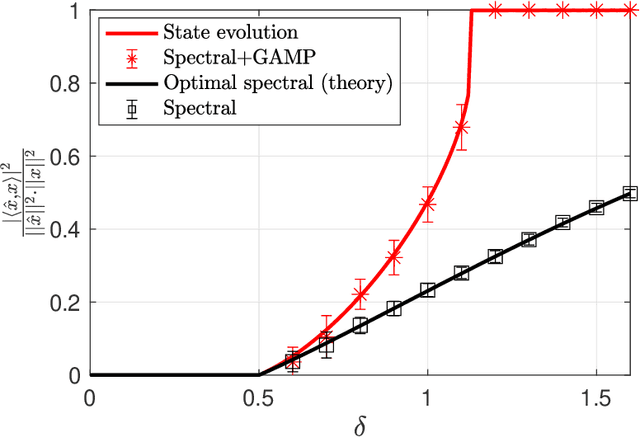
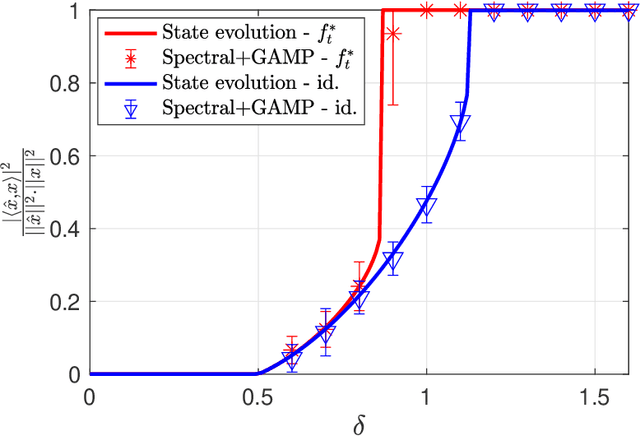

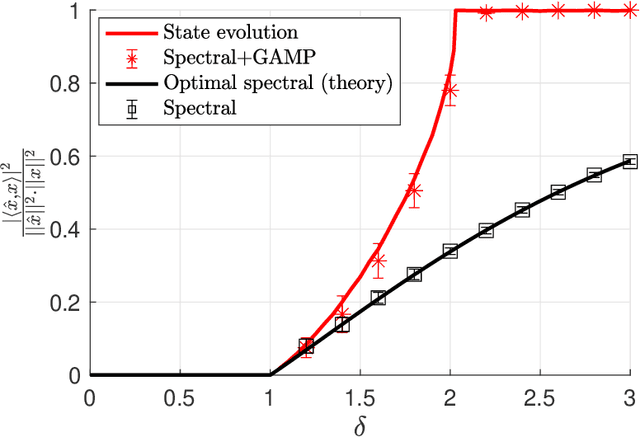
We consider the problem of estimating a signal from measurements obtained via a generalized linear model. We focus on estimators based on approximate message passing (AMP), a family of iterative algorithms with many appealing features: the performance of AMP in the high-dimensional limit can be succinctly characterized under suitable model assumptions; AMP can also be tailored to the empirical distribution of the signal entries, and for a wide class of estimation problems, AMP is conjectured to be optimal among all polynomial-time algorithms. However, a major issue of AMP is that in many models (such as phase retrieval), it requires an initialization correlated with the ground-truth signal and independent from the measurement matrix. Assuming that such an initialization is available is typically not realistic. In this paper, we solve this problem by proposing an AMP algorithm initialized with a spectral estimator. With such an initialization, the standard AMP analysis fails since the spectral estimator depends in a complicated way on the design matrix. Our main technical contribution is the construction and analysis of a two-phase artificial AMP algorithm that first produces the spectral estimator, and then closely approximates the iterates of the true AMP. Our analysis yields a rigorous characterization of the performance of AMP with spectral initialization in the high-dimensional limit. We also provide numerical results that demonstrate the validity of the proposed approach.