 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-Based Automatic Detection of Poorly Positioned Mammograms to Minimize Patient Return Visits for Repeat Imaging: A Real-World Application
Sep 28, 2020
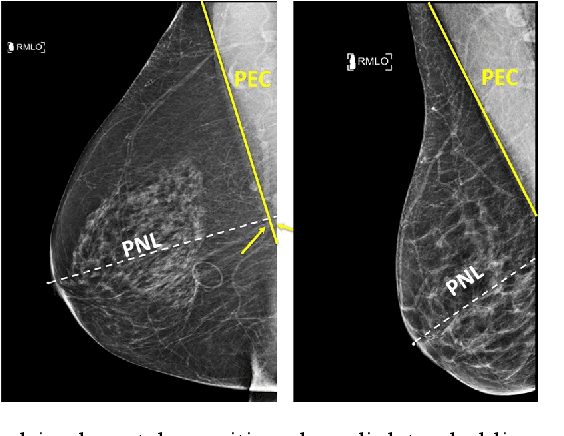
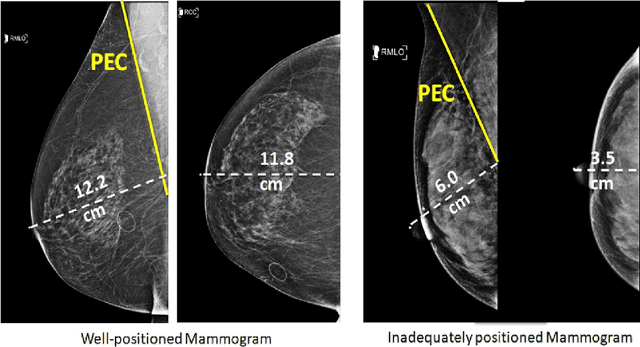
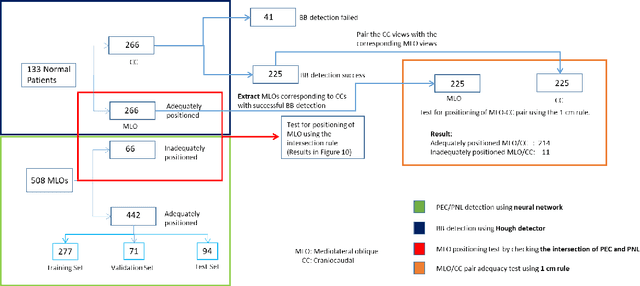

Screening mammograms are a routine imaging exam performed to detect breast cancer in its early stages to reduce morbidity and mortality attributed to this disease. In order to maximize the efficacy of breast cancer screening programs, proper mammographic positioning is paramount. Proper positioning ensures adequate visualization of breast tissue and is necessary for effective breast cancer detection. Therefore, breast-imaging radiologists must assess each mammogram for the adequacy of positioning before providing a final interpretation of the examination; this often necessitates return patient visits for additional imaging. In this paper, we propose a deep learning-algorithm method that mimics and automates this decision-making process to identify poorly positioned mammograms. Our objective for this algorithm is to assist mammography technologists in recognizing inadequately positioned mammograms real-time, improve the quality of mammographic positioning and performance, and ultimately reducing repeat visits for patients with initially inadequate imaging. The proposed model showed a true positive rate for detecting correct positioning of 91.35% in the mediolateral oblique view and 95.11% in the craniocaudal view. In addition to these results, we also present an automatically generated report which can aid the mammography technologist in taking corrective measures during the patient visit.
Psoriasis Severity Assessment with a Similarity-Clustering Machine Learning Approach Reduces Intra- and Inter-observation variation
Sep 28, 2020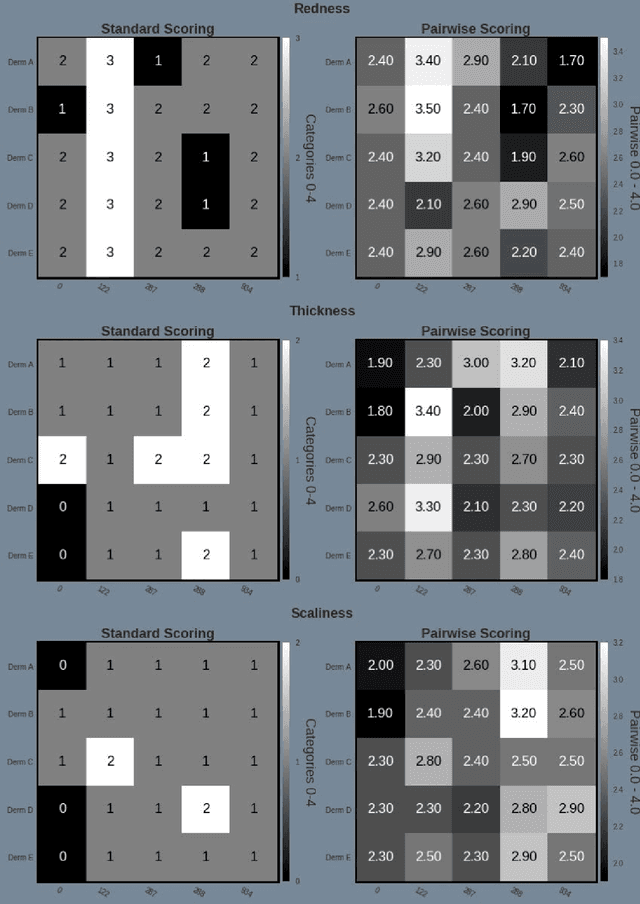
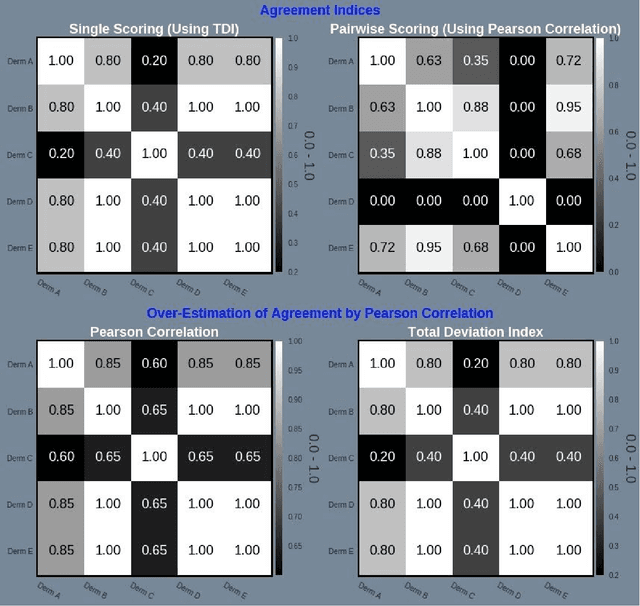
Psoriasis is a complex disease with many variations in genotype and phenotype. General advancements in medicine has further complicated both assessments and treatment for both physicians and dermatologist alike. Even with all of our technological progress we still primarily use the assessment tool Psoriasis Area and Severity Index (PASI) for severity assessments which was developed in the 1970s. In this study we evaluate a method involving digital images, a comparison web application and similarity clustering, developed to improve the assessment tool in terms of intra- and inter-observer variation. Images of patients was collected from a mobile device. Images were captured of the same lesion area taken approximately 1 week apart. Five dermatologists evaluated the severity of psoriasis by modified-PASI, absolute scoring and a relative pairwise PASI scoring using similarity-clustering and conducted using a web-program displaying two images at a time. mPASI scoring of single photos by the same or different dermatologist showed mPASI ratings of 50% to 80%, respectively. Repeated mPASI comparison using similarity clustering showed consistent mPASI ratings > 95%. Pearson correlation between absolute scoring and pairwise scoring progression was 0.72.
Diet deep generative audio models with structured lottery
Jul 31, 2020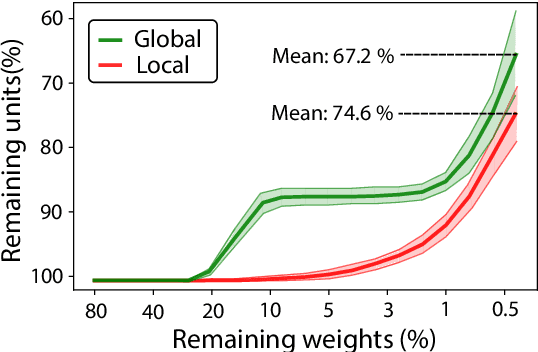
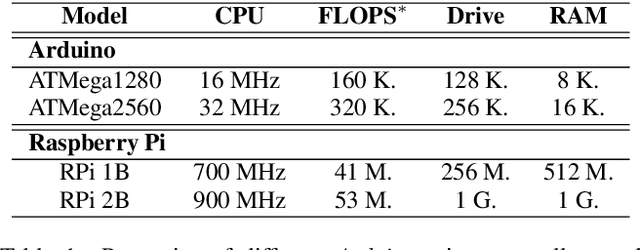
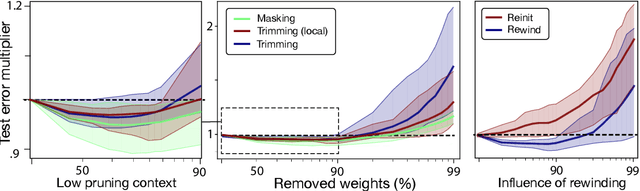
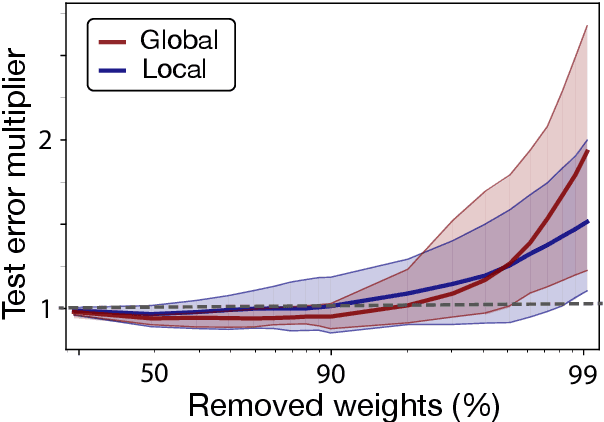
Deep learning models have provided extremely successful solutions in most audio application fields. However, the high accuracy of these models comes at the expense of a tremendous computation cost. This aspect is almost always overlooked in evaluating the quality of proposed models. However, models should not be evaluated without taking into account their complexity. This aspect is especially critical in audio applications, which heavily relies on specialized embedded hardware with real-time constraints. In this paper, we build on recent observations that deep models are highly overparameterized, by studying the lottery ticket hypothesis on deep generative audio models. This hypothesis states that extremely efficient small sub-networks exist in deep models and would provide higher accuracy than larger models if trained in isolation. However, lottery tickets are found by relying on unstructured masking, which means that resulting models do not provide any gain in either disk size or inference time. Instead, we develop here a method aimed at performing structured trimming. We show that this requires to rely on global selection and introduce a specific criterion based on mutual information. First, we confirm the surprising result that smaller models provide higher accuracy than their large counterparts. We further show that we can remove up to 95% of the model weights without significant degradation in accuracy. Hence, we can obtain very light models for generative audio across popular methods such as Wavenet, SING or DDSP, that are up to 100 times smaller with commensurate accuracy. We study the theoretical bounds for embedding these models on Raspberry Pi and Arduino, and show that we can obtain generative models on CPU with equivalent quality as large GPU models. Finally, we discuss the possibility of implementing deep generative audio models on embedded platforms.
Floors are Flat: Leveraging Semantics for Real-Time Surface Normal Prediction
Jun 16, 2019
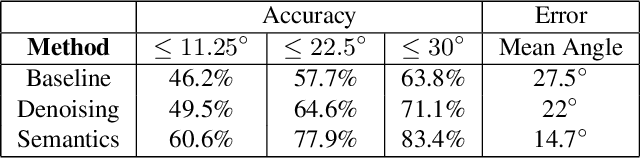

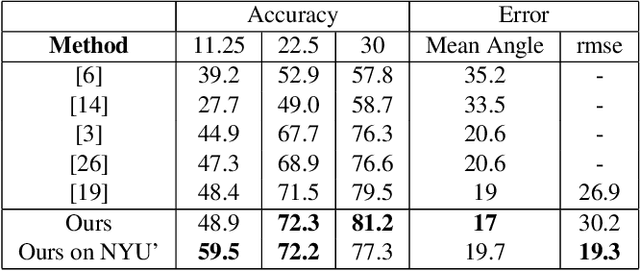
We propose 4 insights that help to significantly improve the performance of deep learning models that predict surface normals and semantic labels from a single RGB image. These insights are: (1) denoise the "ground truth" surface normals in the training set to ensure consistency with the semantic labels; (2) concurrently train on a mix of real and synthetic data, instead of pretraining on synthetic and finetuning on real; (3) jointly predict normals and semantics using a shared model, but only backpropagate errors on pixels that have valid training labels; (4) slim down the model and use grayscale instead of color inputs. Despite the simplicity of these steps, we demonstrate consistently improved results on several datasets, using a model that runs at 12 fps on a standard mobile phone.
Sub-Seasonal Climate Forecasting via Machine Learning: Challenges, Analysis, and Advances
Jun 14, 2020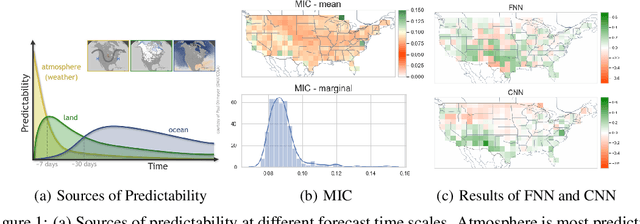
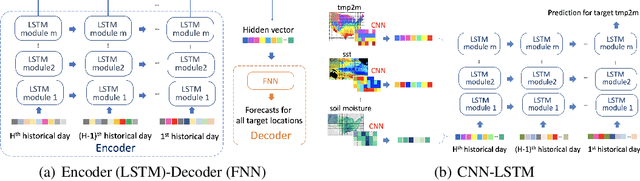
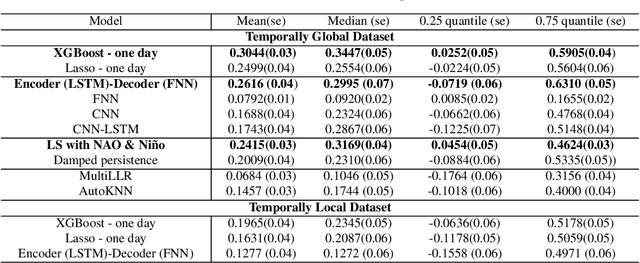
Sub-seasonal climate forecasting (SSF) focuses on predicting key climate variables such as temperature and precipitation in the 2-week to 2-month time scales. Skillful SSF would have immense societal value, in such areas as agricultural productivity, water resource management, transportation and aviation systems, and emergency planning for extreme weather events. However, SSF is considered more challenging than either weather prediction or even seasonal prediction. In this paper, we carefully study a variety of machine learning (ML) approaches for SSF over the US mainland. While atmosphere-land-ocean couplings and the limited amount of good quality data makes it hard to apply black-box ML naively, we show that with carefully constructed feature representations, even linear regression models, e.g., Lasso, can be made to perform well. Among a broad suite of 10 ML approaches considered, gradient boosting performs the best, and deep learning (DL) methods show some promise with careful architecture choices. Overall, ML methods are able to outperform the climatological baseline, i.e., predictions based on the 30 year average at a given location and time. Further, based on studying feature importance, ocean (especially indices based on climatic oscillations such as El Nino) and land (soil moisture) covariates are found to be predictive, whereas atmospheric covariates are not considered helpful.
Hierarchical Multi-Grained Generative Model for Expressive Speech Synthesis
Sep 17, 2020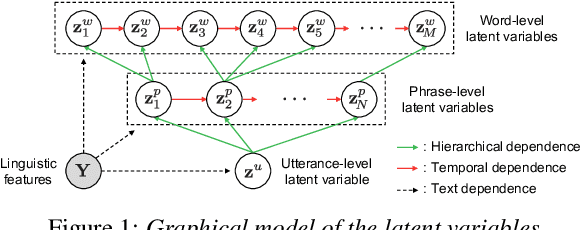
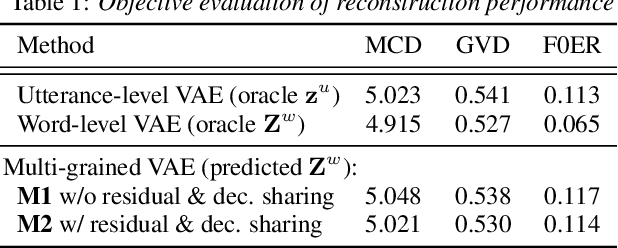
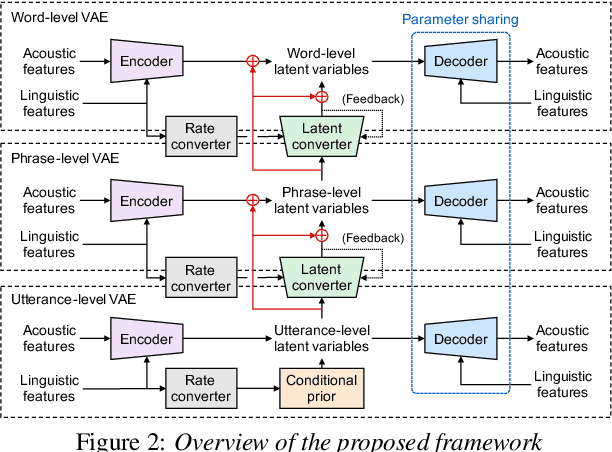
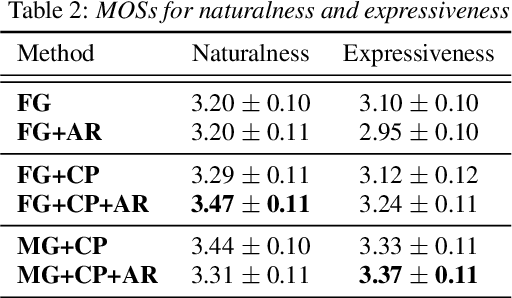
This paper proposes a hierarchical generative model with a multi-grained latent variable to synthesize expressive speech. In recent years, fine-grained latent variables are introduced into the text-to-speech synthesis that enable the fine control of the prosody and speaking styles of synthesized speech. However, the naturalness of speech degrades when these latent variables are obtained by sampling from the standard Gaussian prior. To solve this problem, we propose a novel framework for modeling the fine-grained latent variables, considering the dependence on an input text, a hierarchical linguistic structure, and a temporal structure of latent variables. This framework consists of a multi-grained variational autoencoder, a conditional prior, and a multi-level auto-regressive latent converter to obtain the different time-resolution latent variables and sample the finer-level latent variables from the coarser-level ones by taking into account the input text. Experimental results indicate an appropriate method of sampling fine-grained latent variables without the reference signal at the synthesis stage. Our proposed framework also provides the controllability of speaking style in an entire utterance.
Radar-Camera Sensor Fusion for Joint Object Detection and Distance Estimation in Autonomous Vehicles
Sep 17, 2020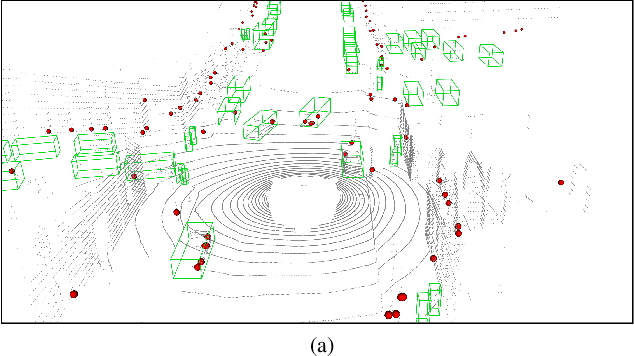
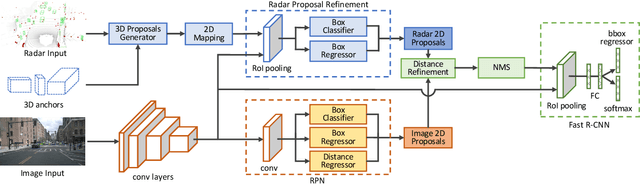


In this paper we present a novel radar-camera sensor fusion framework for accurate object detection and distance estimation in autonomous driving scenarios. The proposed architecture uses a middle-fusion approach to fuse the radar point clouds and RGB images. Our radar object proposal network uses radar point clouds to generate 3D proposals from a set of 3D prior boxes. These proposals are mapped to the image and fed into a Radar Proposal Refinement (RPR) network for objectness score prediction and box refinement. The RPR network utilizes both radar information and image feature maps to generate accurate object proposals and distance estimations. The radar-based proposals are combined with image-based proposals generated by a modified Region Proposal Network (RPN). The RPN has a distance regression layer for estimating distance for every generated proposal. The radar-based and image-based proposals are merged and used in the next stage for object classification. Experiments on the challenging nuScenes dataset show our method outperforms other existing radar-camera fusion methods in the 2D object detection task while at the same time accurately estimates objects' distances.
Combining Label Propagation and Simple Models Out-performs Graph Neural Networks
Nov 02, 2020



Graph Neural Networks (GNNs) are the predominant technique for learning over graphs. However, there is relatively little understanding of why GNNs are successful in practice and whether they are necessary for good performance. Here, we show that for many standard transductive node classification benchmarks, we can exceed or match the performance of state-of-the-art GNNs by combining shallow models that ignore the graph structure with two simple post-processing steps that exploit correlation in the label structure: (i) an "error correlation" that spreads residual errors in training data to correct errors in test data and (ii) a "prediction correlation" that smooths the predictions on the test data. We call this overall procedure Correct and Smooth (C&S), and the post-processing steps are implemented via simple modifications to standard label propagation techniques from early graph-based semi-supervised learning methods. Our approach exceeds or nearly matches the performance of state-of-the-art GNNs on a wide variety of benchmarks, with just a small fraction of the parameters and orders of magnitude faster runtime. For instance, we exceed the best known GNN performance on the OGB-Products dataset with 137 times fewer parameters and greater than 100 times less training time. The performance of our methods highlights how directly incorporating label information into the learning algorithm (as was done in traditional techniques) yields easy and substantial performance gains. We can also incorporate our techniques into big GNN models, providing modest gains. Our code for the OGB results is at https://github.com/Chillee/CorrectAndSmooth.
Semi-supervised Pathology Segmentation with Disentangled Representations
Sep 05, 2020



Automated pathology segmentation remains a valuable diagnostic tool in clinical practice. However, collecting training data is challenging. Semi-supervised approaches by combining labelled and unlabelled data can offer a solution to data scarcity. An approach to semi-supervised learning relies on reconstruction objectives (as self-supervision objectives) that learns in a joint fashion suitable representations for the task. Here, we propose Anatomy-Pathology Disentanglement Network (APD-Net), a pathology segmentation model that attempts to learn jointly for the first time: disentanglement of anatomy, modality, and pathology. The model is trained in a semi-supervised fashion with new reconstruction losses directly aiming to improve pathology segmentation with limited annotations. In addition, a joint optimization strategy is proposed to fully take advantage of the available annotations. We evaluate our methods with two private cardiac infarction segmentation datasets with LGE-MRI scans. APD-Net can perform pathology segmentation with few annotations, maintain performance with different amounts of supervision, and outperform related deep learning methods.
* 12 Pages, 4 figures
Learnable Strategies for Bilateral Agent Negotiation over Multiple Issues
Sep 17, 2020
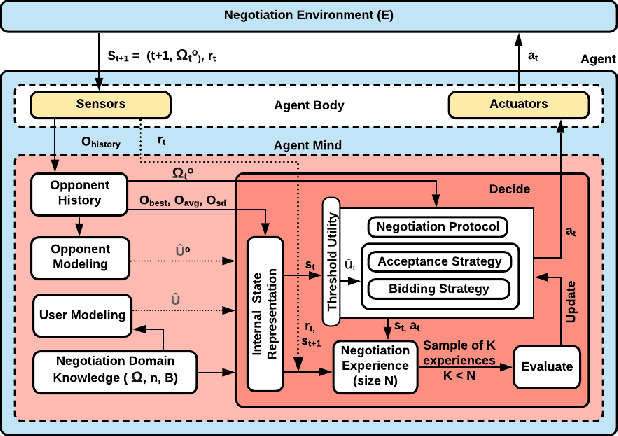
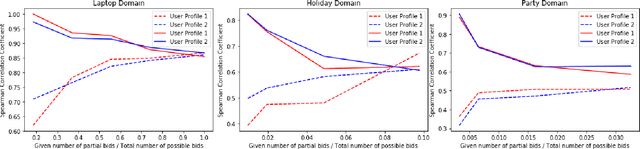
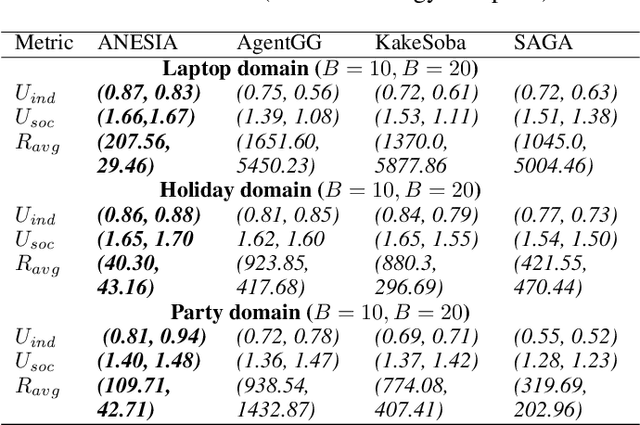
We present a novel bilateral negotiation model that allows a self-interested agent to learn how to negotiate over multiple issues in the presence of user preference uncertainty. The model relies upon interpretable strategy templates representing the tactics the agent should employ during the negotiation and learns template parameters to maximize the average utility received over multiple negotiations, thus resulting in optimal bid acceptance and generation. Our model also uses deep reinforcement learning to evaluate threshold utility values, for those tactics that require them, thereby deriving optimal utilities for every environment state. To handle user preference uncertainty, the model relies on a stochastic search to find user model that best agrees with a given partial preference profile. Multi-objective optimization and multi-criteria decision-making methods are applied at negotiation time to generate Pareto-optimal outcomes thereby increasing the number of successful (win-win) negotiations. Rigorous experimental evaluations show that the agent employing our model outperforms the winning agents of the 10th Automated Negotiating Agents Competition (ANAC'19) in terms of individual as well as social-welfare utilities.