 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Data-Driven Analytical Framework of Estimating Multimodal Travel Demand Patterns using Mobile Device Location Data
Dec 08, 2020
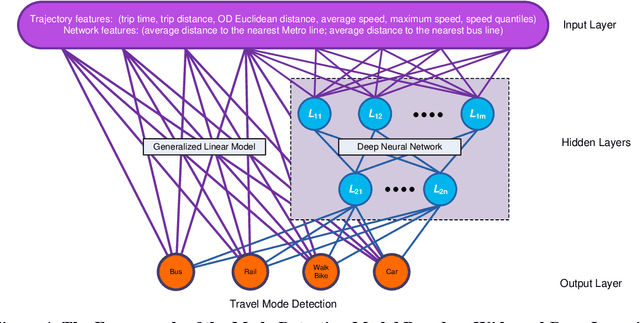

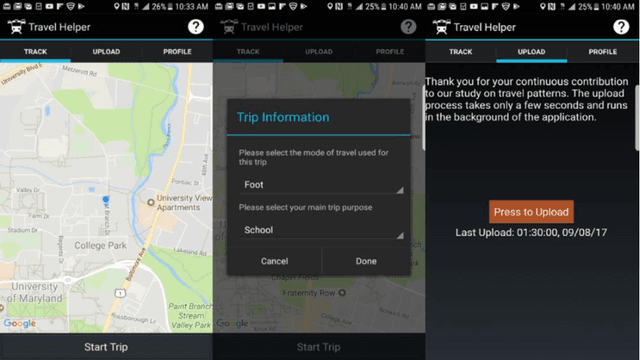
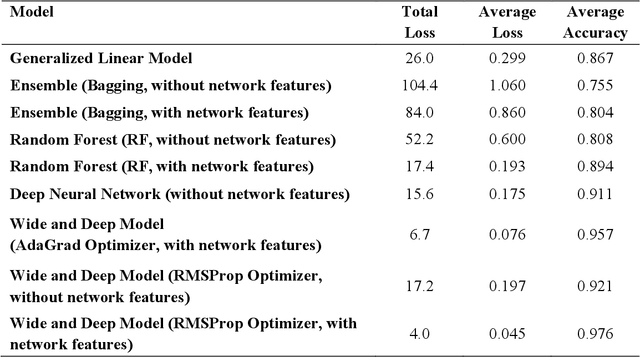
While benefiting people's daily life in so many ways, smartphones and their location-based services are generating massive mobile device location data that has great potential to help us understand travel demand patterns and make transportation planning for the future. While recent studies have analyzed human travel behavior using such new data sources, limited research has been done to extract multimodal travel demand patterns out of them. This paper presents a data-driven analytical framework to bridge the gap. To be able to successfully detect travel modes using the passively collected location information, we conduct a smartphone-based GPS survey to collect ground truth observations. Then a jointly trained single-layer model and deep neural network for travel mode imputation is developed. Being "wide" and "deep" at the same time, this model combines the advantages of both types of models. The framework also incorporates the multimodal transportation network in order to evaluate the closeness of trip routes to the nearby rail, metro, highway and bus lines and therefore enhance the imputation accuracy. To showcase the applications of the introduced framework in answering real-world planning needs, a separate mobile device location data is processed through trip end identification and attribute generation, in a way that the travel mode imputation can be directly applied. The estimated multimodal travel demand patterns are then validated against typical household travel surveys in the same Washington D.C. and Baltimore Metropolitan Regions.
A deep learning approach to real-time parking occupancy prediction in spatio-termporal networks incorporating multiple spatio-temporal data sources
Jan 21, 2019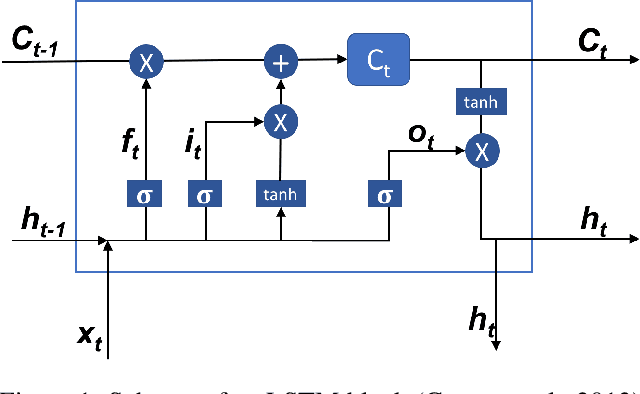
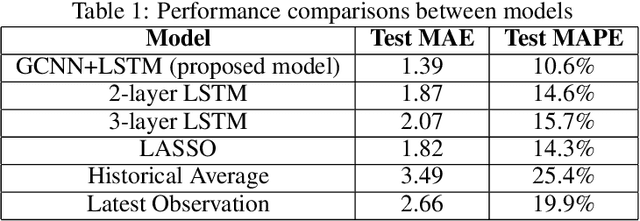
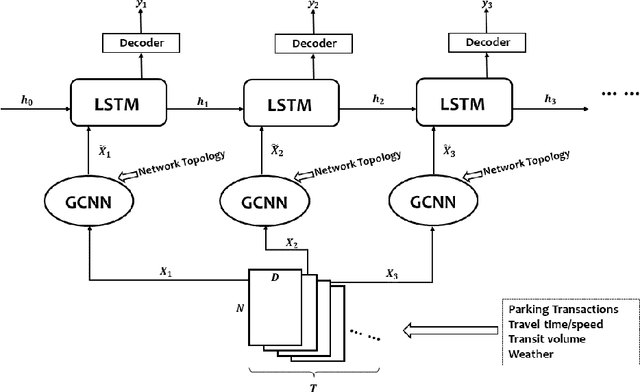
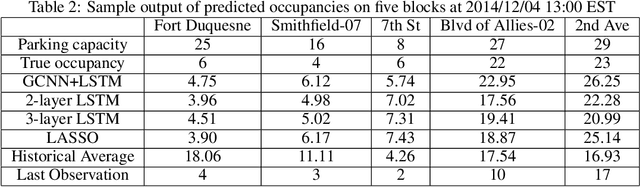
A deep learning model is proposed for predicting block-level parking occupancy in real time. The model leverages Graph-Convolutional Neural Networks (GCNN) to extract the spatial relations of traffic flow in large-scale networks, and utilizes Recurrent Neural Networks (RNN) with Long-Short Term Memory (LSTM) to capture the temporal features. In addition, the model is capable of taking multiple heterogeneously structured traffic data sources as input, such as parking meter transactions, traffic speed, and weather conditions. The model performance is evaluated through a case study in Pittsburgh downtown area. The proposed model outperforms other baseline methods including multi-layer LSTM and Lasso with an average testing MAPE of 12.0\% when predicting block-level parking occupancies 30 minutes in advance. The case study also shows that, in generally, the prediction model works better for business areas than for recreational locations. We found that incorporating traffic speed and weather information can significantly improve the prediction performance. Weather data is particularly useful for improving predicting accuracy in recreational areas.
Transcription Is All You Need: Learning to Separate Musical Mixtures with Score as Supervision
Oct 22, 2020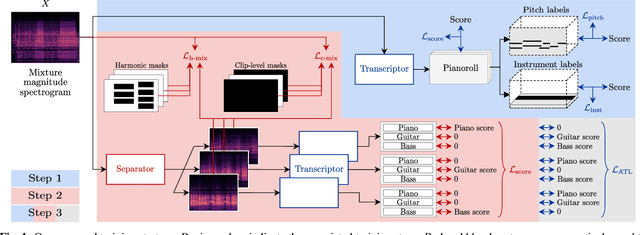
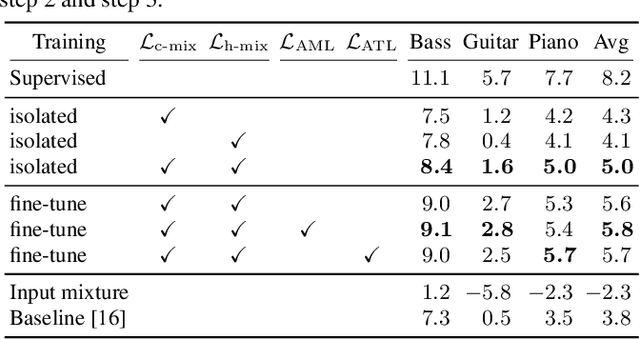
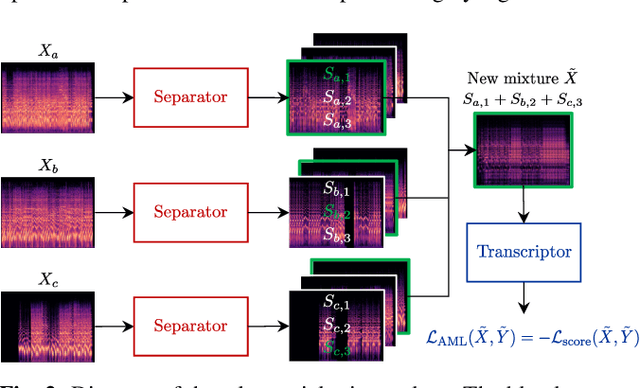
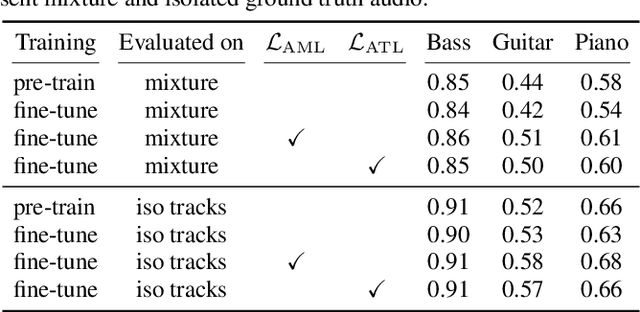
Most music source separation systems require large collections of isolated sources for training, which can be difficult to obtain. In this work, we use musical scores, which are comparatively easy to obtain, as a weak label for training a source separation system. In contrast with previous score-informed separation approaches, our system does not require isolated sources, and score is used only as a training target, not required for inference. Our model consists of a separator that outputs a time-frequency mask for each instrument, and a transcriptor that acts as a critic, providing both temporal and frequency supervision to guide the learning of the separator. A harmonic mask constraint is introduced as another way of leveraging score information during training, and we propose two novel adversarial losses for additional fine-tuning of both the transcriptor and the separator. Results demonstrate that using score information outperforms temporal weak-labels, and adversarial structures lead to further improvements in both separation and transcription performance.
G-Net: A Deep Learning Approach to G-computation for Counterfactual Outcome Prediction Under Dynamic Treatment Regimes
Mar 23, 2020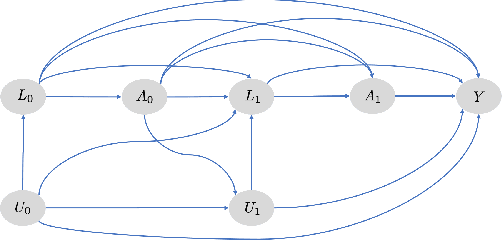

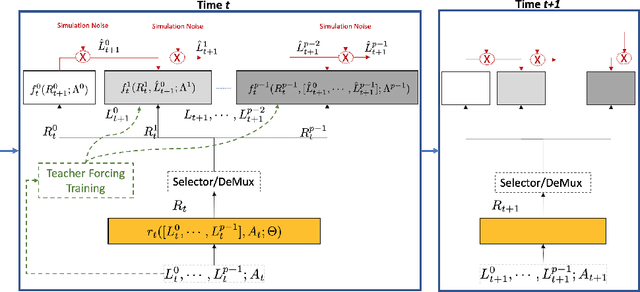
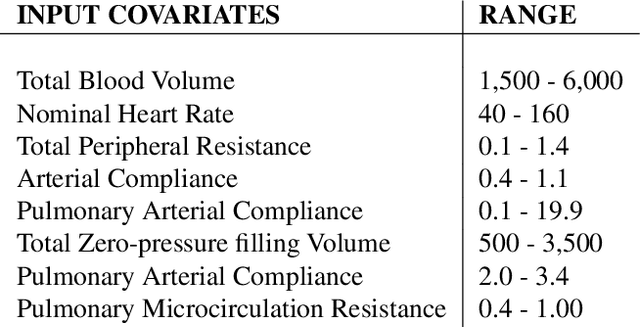
Counterfactual prediction is a fundamental task in decision-making. G-computation is a method for estimating expected counterfactual outcomes under dynamic time-varying treatment strategies. Existing G-computation implementations have mostly employed classical regression models with limited capacity to capture complex temporal and nonlinear dependence structures. This paper introduces G-Net, a novel sequential deep learning framework for G-computation that can handle complex time series data while imposing minimal modeling assumptions and provide estimates of individual or population-level time varying treatment effects. We evaluate alternative G-Net implementations using realistically complex temporal simulated data obtained from CVSim, a mechanistic model of the cardiovascular system.
Dependent Matérn Processes for Multivariate Time Series
Feb 11, 2015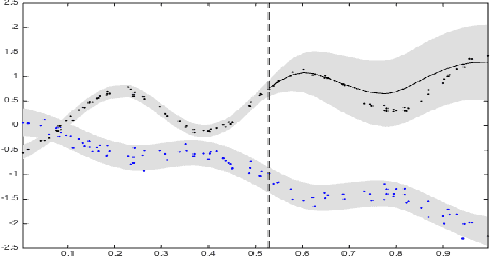
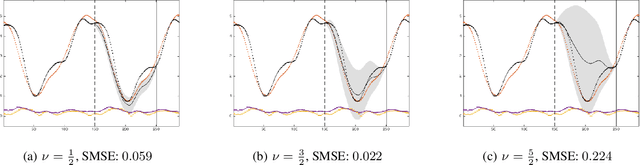
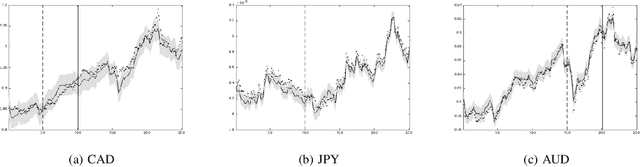
For the challenging task of modeling multivariate time series, we propose a new class of models that use dependent Mat\'ern processes to capture the underlying structure of data, explain their interdependencies, and predict their unknown values. Although similar models have been proposed in the econometric, statistics, and machine learning literature, our approach has several advantages that distinguish it from existing methods: 1) it is flexible to provide high prediction accuracy, yet its complexity is controlled to avoid overfitting; 2) its interpretability separates it from black-box methods; 3) finally, its computational efficiency makes it scalable for high-dimensional time series. In this paper, we use several simulated and real data sets to illustrate these advantages. We will also briefly discuss some extensions of our model.
Not all parameters are born equal: Attention is mostly what you need
Oct 22, 2020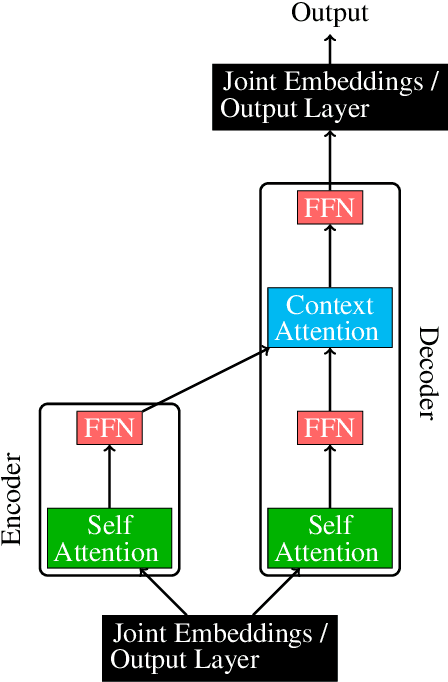
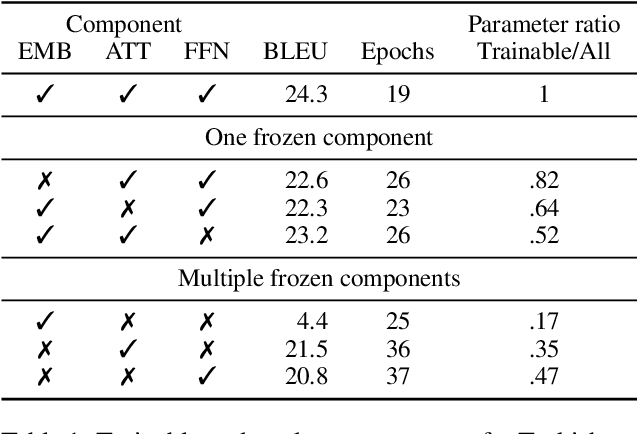
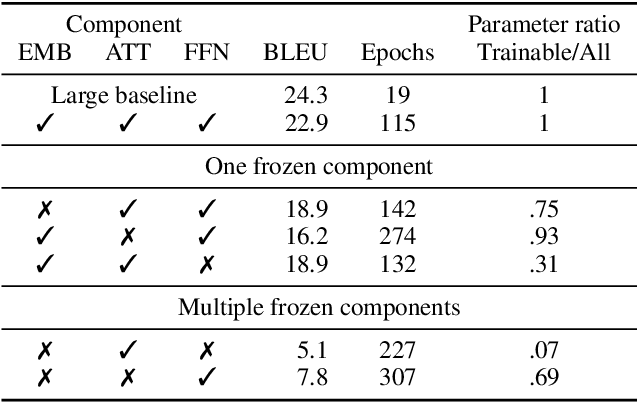
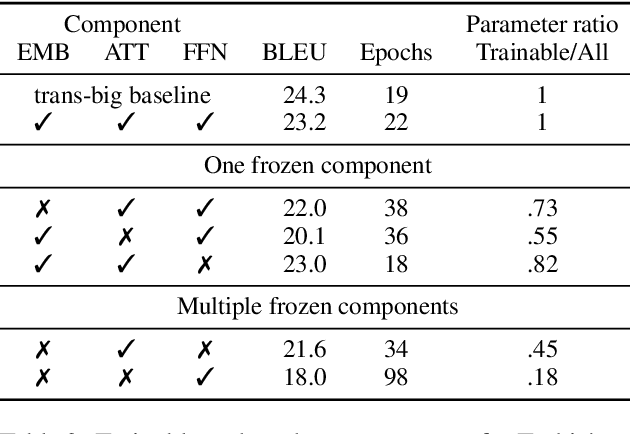
Transformers are widely used in state-of-the-art machine translation, but the key to their success is still unknown. To gain insight into this, we consider three groups of parameters: embeddings, attention, and feed forward neural network (FFN) layers. We examine the relative importance of each by performing an ablation study where we initialise them at random and freeze them, so that their weights do not change over the course of the training. Through this, we show that the attention and FFN are equally important and fulfil the same functionality in a model. We show that the decision about whether a component is frozen or allowed to train is at least as important for the final model performance as its number of parameters. At the same time, the number of parameters alone is not indicative of a component's importance. Finally, while the embedding layer is the least essential for machine translation tasks, it is the most important component for language modelling tasks.
Castle in the Sky: Dynamic Sky Replacement and Harmonization in Videos
Oct 22, 2020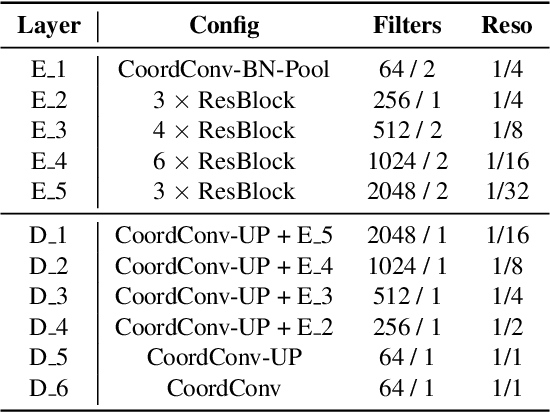
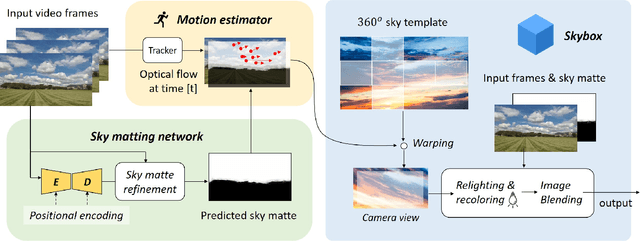
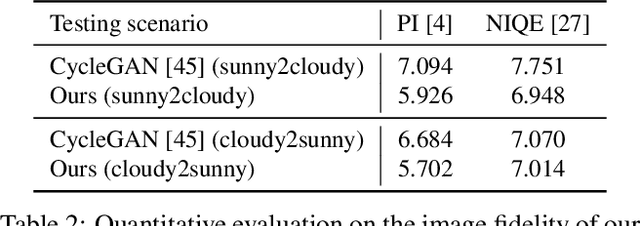

This paper proposes a vision-based method for video sky replacement and harmonization, which can automatically generate realistic and dramatic sky backgrounds in videos with controllable styles. Different from previous sky editing methods that either focus on static photos or require inertial measurement units integrated in smartphones on shooting videos, our method is purely vision-based, without any requirements on the capturing devices, and can be well applied to either online or offline processing scenarios. Our method runs in real-time and is free of user interactions. We decompose this artistic creation process into a couple of proxy tasks including sky matting, motion estimation, and image blending. Experiments are conducted on videos diversely captured in the wild by handheld smartphones and dash cameras, and show high fidelity and good generalization of our method in both visual quality and lighting/motion dynamics. Our code and animated results are available at \url{https://jiupinjia.github.io/skyar/}.
Time-Critical Dynamic Decision Making
Jan 23, 2013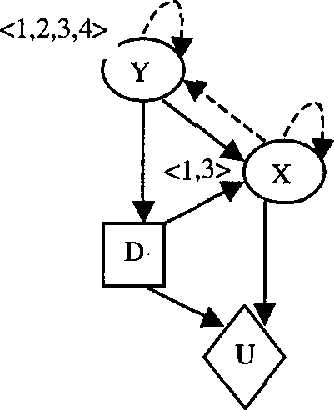
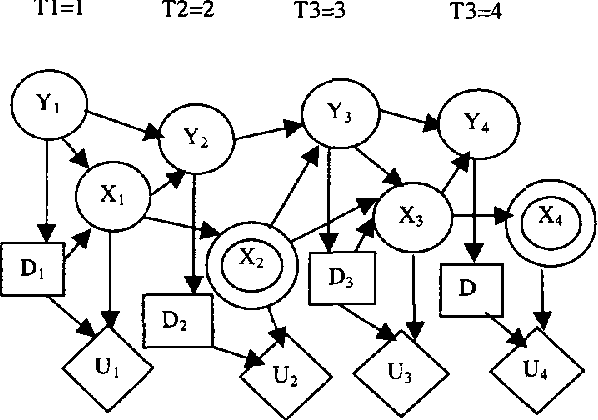
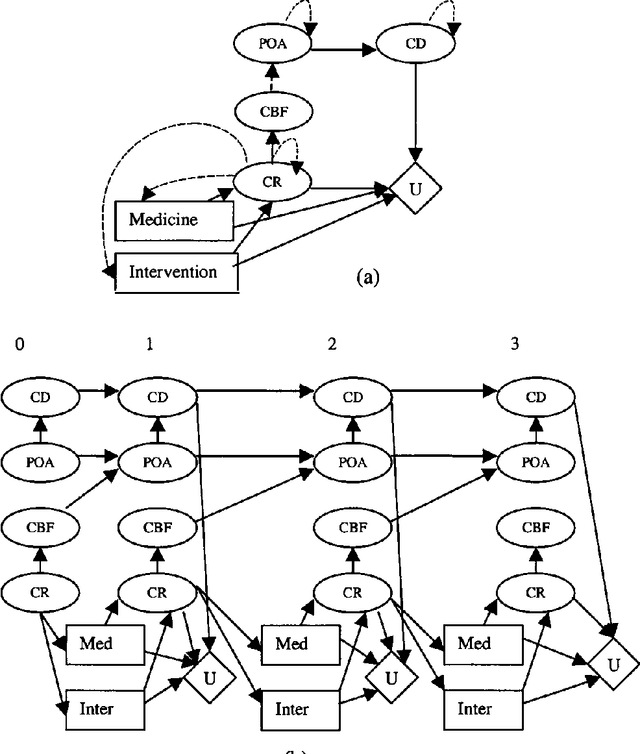
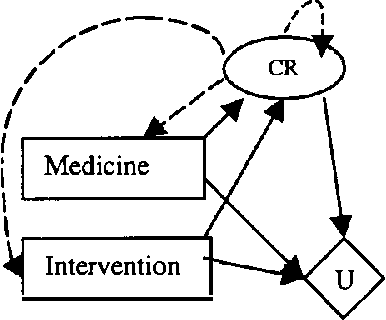
Recent interests in dynamic decision modeling have led to the development of several representation and inference methods. These methods however, have limited application under time critical conditions where a trade-off between model quality and computational tractability is essential. This paper presents an approach to time-critical dynamic decision modeling. A knowledge representation and modeling method called the time-critical dynamic influence diagram is proposed. The formalism has two forms. The condensed form is used for modeling and model abstraction, while the deployed form which can be converted from the condensed form is used for inference purposes. The proposed approach has the ability to represent space-temporal abstraction within the model. A knowledge-based meta-reasoning approach is proposed for the purpose of selecting the best abstracted model that provide the optimal trade-off between model quality and model tractability. An outline of the knowledge-based model construction algorithm is also provided.
SIMDive: Approximate SIMD Soft Multiplier-Divider for FPGAs with Tunable Accuracy
Nov 02, 2020

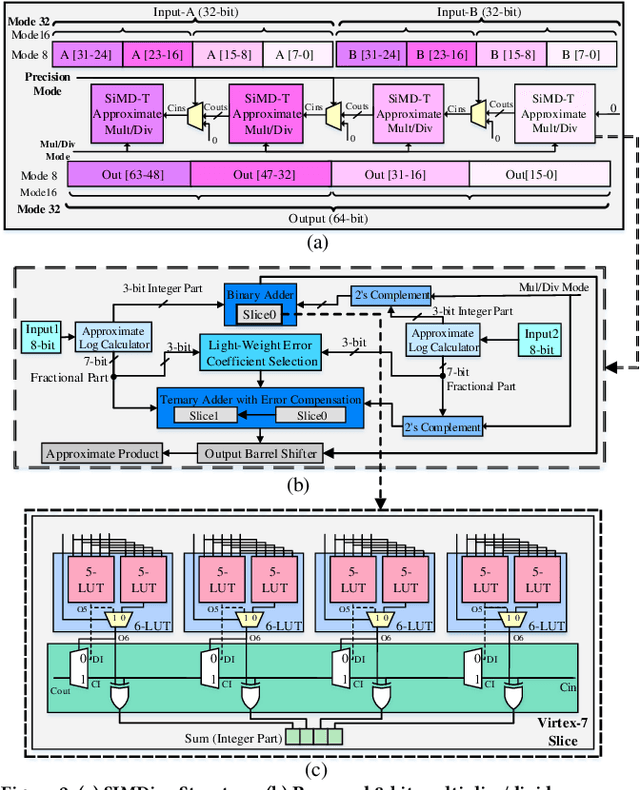
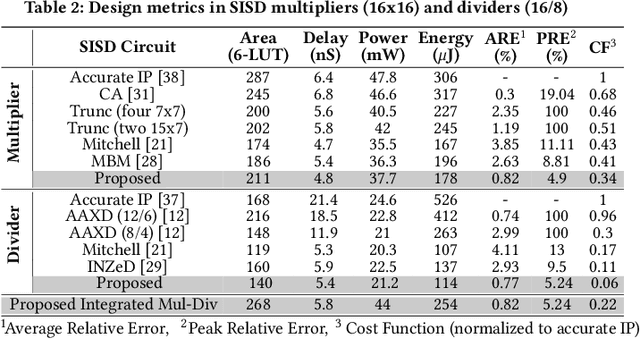
The ever-increasing quest for data-level parallelism and variable precision in ubiquitous multimedia and Deep Neural Network (DNN) applications has motivated the use of Single Instruction, Multiple Data (SIMD) architectures. To alleviate energy as their main resource constraint, approximate computing has re-emerged,albeit mainly specialized for their Application-Specific Integrated Circuit (ASIC) implementations. This paper, presents for the first time, an SIMD architecture based on novel multiplier and divider with tunable accuracy, targeted for Field-Programmable Gate Arrays (FPGAs). The proposed hybrid architecture implements Mitchell's algorithms and supports precision variability from 8 to 32 bits. Experimental results obtained from Vivado, multimedia and DNN applications indicate superiority of proposed architecture (both SISD and SIMD) over accurate and state-of-the-art approximate counterparts. In particular, the proposed SISD divider outperforms the accurate Intellectual Property (IP) divider provided by Xilinx with 4x higher speed and 4.6x less energy and tolerating only < 0.8% error. Moreover, the proposed SIMD multiplier-divider supersede accurate SIMD multiplier by achieving up to 26%, 45%, 36%, and 56% improvement in area, throughput, power, and energy, respectively.
SLAM in the Field: An Evaluation of Monocular Mapping and Localization on Challenging Dynamic Agricultural Environment
Nov 02, 2020
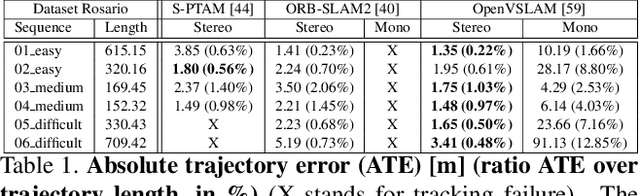
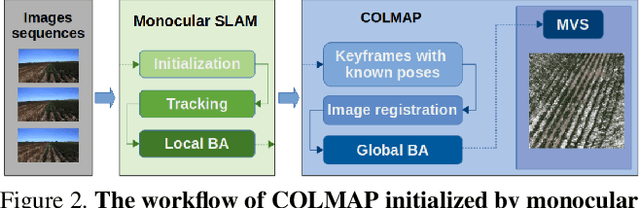
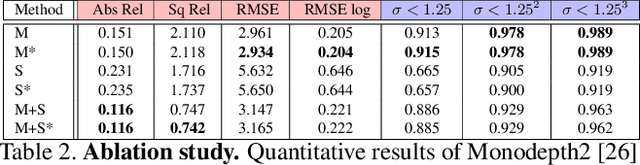
This paper demonstrates a system capable of combining a sparse, indirect, monocular visual SLAM, with both offline and real-time Multi-View Stereo (MVS) reconstruction algorithms. This combination overcomes many obstacles encountered by autonomous vehicles or robots employed in agricultural environments, such as overly repetitive patterns, need for very detailed reconstructions, and abrupt movements caused by uneven roads. Furthermore, the use of a monocular SLAM makes our system much easier to integrate with an existing device, as we do not rely on a LiDAR (which is expensive and power consuming), or stereo camera (whose calibration is sensitive to external perturbation e.g. camera being displaced). To the best of our knowledge, this paper presents the first evaluation results for monocular SLAM, and our work further explores unsupervised depth estimation on this specific application scenario by simulating RGB-D SLAM to tackle the scale ambiguity, and shows our approach produces reconstructions that are helpful to various agricultural tasks. Moreover, we highlight that our experiments provide meaningful insight to improve monocular SLAM systems under agricultural settings.