 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Efficient Newton Method for Extreme Similarity Learning with Nonlinear Embeddings
Oct 26, 2020
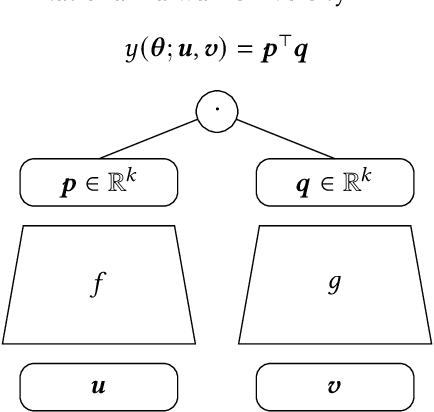

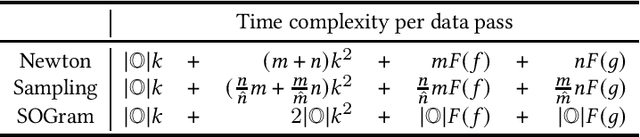
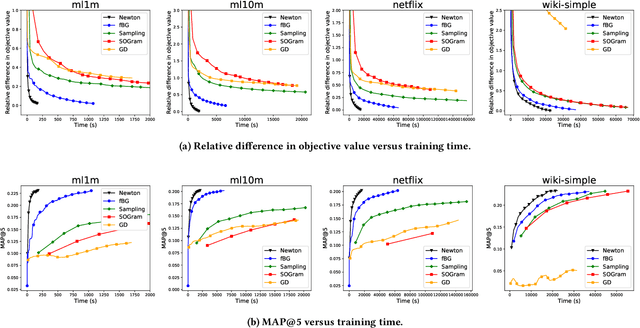
We study the problem of learning similarity by using nonlinear embedding models (e.g., neural networks) from all possible pairs. This problem is well-known for its difficulty of training with the extreme number of pairs. Existing optimization methods extended from stochastic gradient methods suffer from slow convergence and high complexity per pass of all possible pairs. Inspired by some recent works reporting that Newton methods are competitive for training certain types of neural networks, in this work, we novelly apply the Newton method for this problem. A prohibitive cost depending on the extreme number of pairs occurs if the Newton method is directly applied. We propose an efficient algorithm which successfully eliminates the cost. Our proposed algorithm can take advantage of second-order information and lower time complexity per pass of all possible pairs. Experiments conducted on large-scale data sets demonstrate that the proposed algorithm is more efficient than existing algorithms.
Human-Paraphrased References Improve Neural Machine Translation
Oct 20, 2020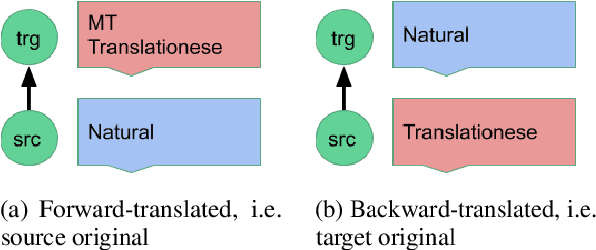
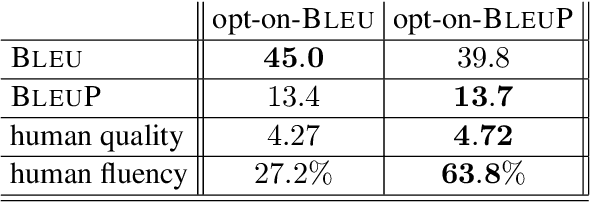
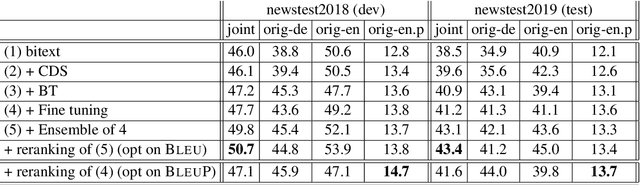
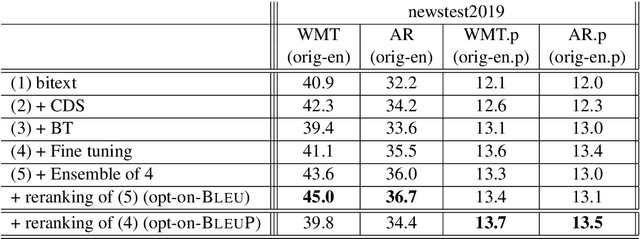
Automatic evaluation comparing candidate translations to human-generated paraphrases of reference translations has recently been proposed by Freitag et al. When used in place of original references, the paraphrased versions produce metric scores that correlate better with human judgment. This effect holds for a variety of different automatic metrics, and tends to favor natural formulations over more literal (translationese) ones. In this paper we compare the results of performing end-to-end system development using standard and paraphrased references. With state-of-the-art English-German NMT components, we show that tuning to paraphrased references produces a system that is significantly better according to human judgment, but 5 BLEU points worse when tested on standard references. Our work confirms the finding that paraphrased references yield metric scores that correlate better with human judgment, and demonstrates for the first time that using these scores for system development can lead to significant improvements.
Intrusion Detection using Continuous Time Bayesian Networks
Jan 16, 2014
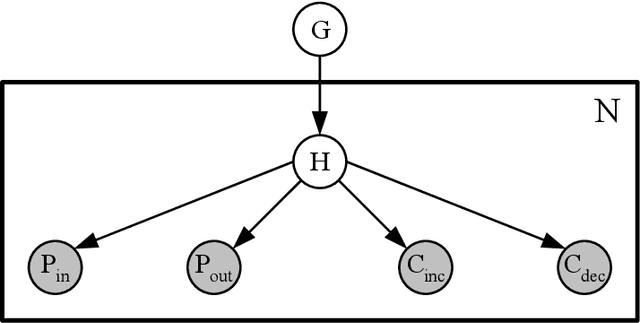


Intrusion detection systems (IDSs) fall into two high-level categories: network-based systems (NIDS) that monitor network behaviors, and host-based systems (HIDS) that monitor system calls. In this work, we present a general technique for both systems. We use anomaly detection, which identifies patterns not conforming to a historic norm. In both types of systems, the rates of change vary dramatically over time (due to burstiness) and over components (due to service difference). To efficiently model such systems, we use continuous time Bayesian networks (CTBNs) and avoid specifying a fixed update interval common to discrete-time models. We build generative models from the normal training data, and abnormal behaviors are flagged based on their likelihood under this norm. For NIDS, we construct a hierarchical CTBN model for the network packet traces and use Rao-Blackwellized particle filtering to learn the parameters. We illustrate the power of our method through experiments on detecting real worms and identifying hosts on two publicly available network traces, the MAWI dataset and the LBNL dataset. For HIDS, we develop a novel learning method to deal with the finite resolution of system log file time stamps, without losing the benefits of our continuous time model. We demonstrate the method by detecting intrusions in the DARPA 1998 BSM dataset.
Gentlemen on the Road: Effect of Yielding Behavior of Autonomous Vehicle on Pedestrian Head Orientation
May 16, 2020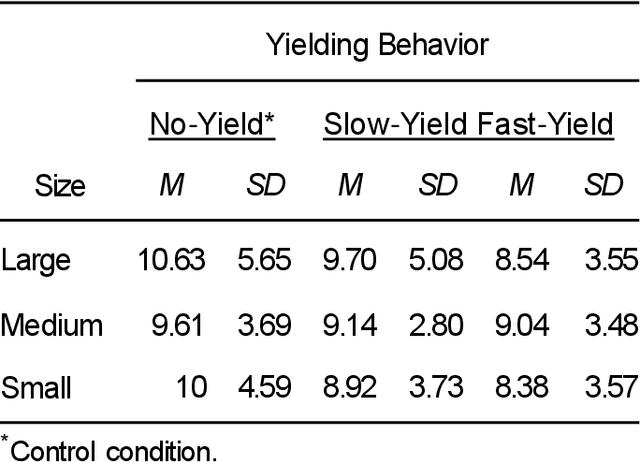

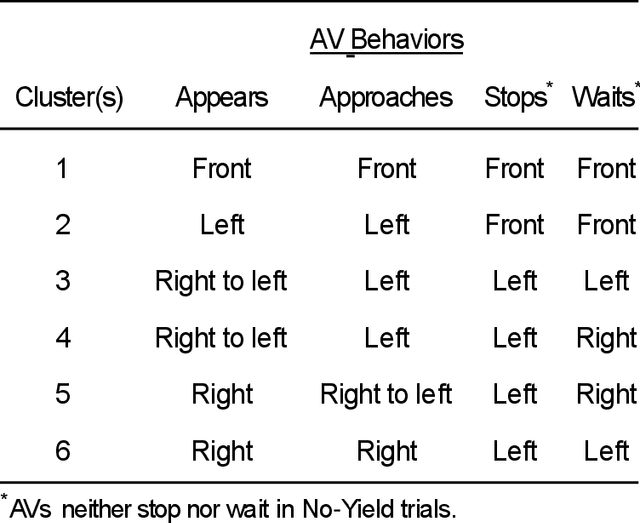
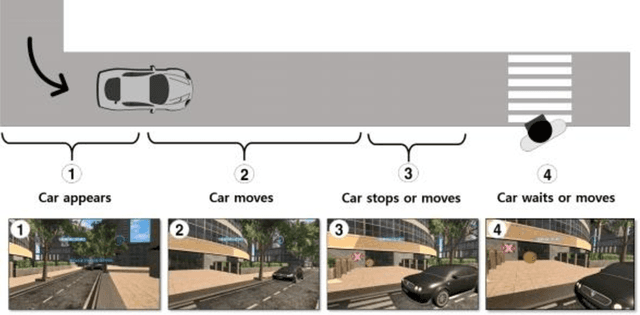
Autonomous vehicles can improve pedestrian safety by learning human-like social behaviors (e.g., yielding). We conducted a virtual reality experiment with 39 participants and measured crossing times (seconds) and head orientation (yaw degrees). We manipulated AV yielding behavior (no-yield, slow-yield, and fast-yield) and the AV size (small, medium, and large). Using Dynamic time warping and K-means clustering, we classified the head orientation change of pedestrians by time into 6 clusters of patterns. Results indicate that head orientation change of pedestrians was influenced by AV yielding behavior as well as the size of the AV. Participants fixated on the front most of the time even when the car approached near. Participants changed head orientation most frequently when a large size AV did not yield (no-yield). In post-experiment interviews, participants reported that yielding behavior and size affected their decision to cross and perceived safety. For autonomous vehicles to be perceived as more safe and trustful, vehicle-specific factors such as size and yielding behavior should be considered in the designing process.
Point-of-Interest Type Inference from Social Media Text
Sep 30, 2020
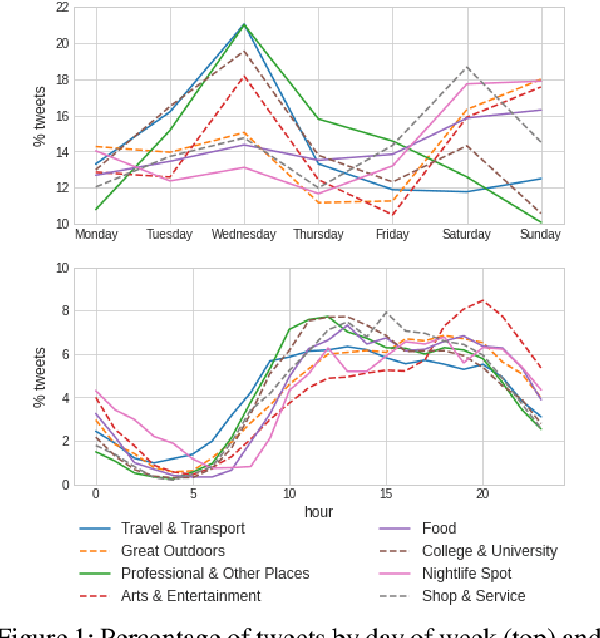
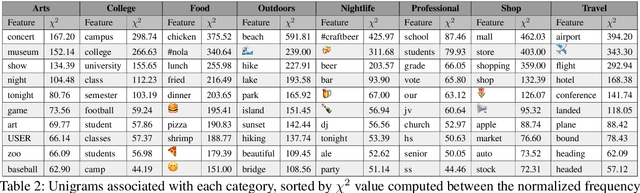
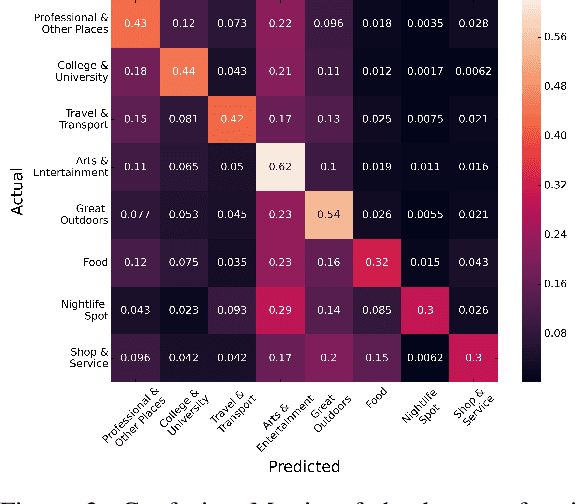
Physical places help shape how we perceive the experiences we have there. For the first time, we study the relationship between social media text and the type of the place from where it was posted, whether a park, restaurant, or someplace else. To facilitate this, we introduce a novel data set of $\sim$200,000 English tweets published from 2,761 different points-of-interest in the U.S., enriched with place type information. We train classifiers to predict the type of the location a tweet was sent from that reach a macro F1 of 43.67 across eight classes and uncover the linguistic markers associated with each type of place. The ability to predict semantic place information from a tweet has applications in recommendation systems, personalization services and cultural geography.
Single Shot MC Dropout Approximation
Jul 07, 2020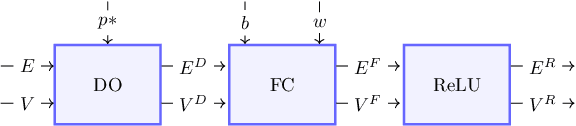
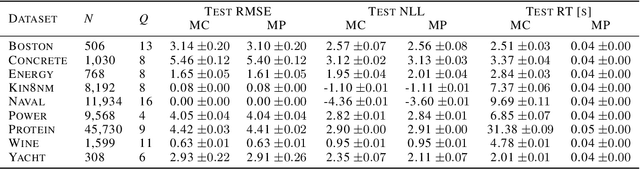
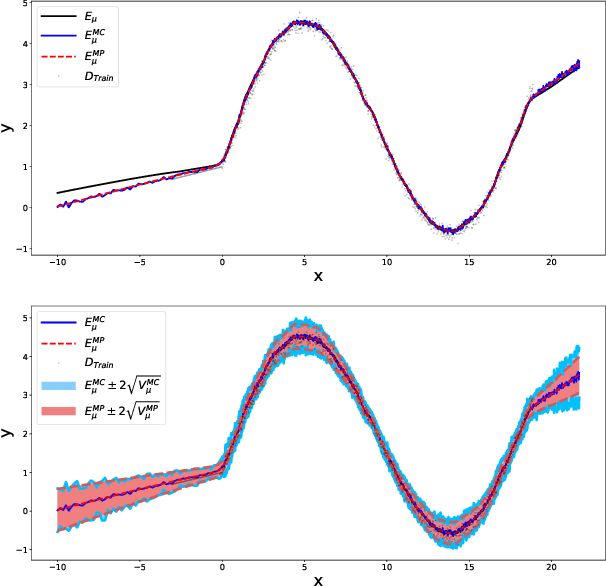
Deep neural networks (DNNs) are known for their high prediction performance, especially in perceptual tasks such as object recognition or autonomous driving. Still, DNNs are prone to yield unreliable predictions when encountering completely new situations without indicating their uncertainty. Bayesian variants of DNNs (BDNNs), such as MC dropout BDNNs, do provide uncertainty measures. However, BDNNs are slow during test time because they rely on a sampling approach. Here we present a single shot MC dropout approximation that preserves the advantages of BDNNs without being slower than a DNN. Our approach is to analytically approximate for each layer in a fully connected network the expected value and the variance of the MC dropout signal. We evaluate our approach on different benchmark datasets and a simulated toy example. We demonstrate that our single shot MC dropout approximation resembles the point estimate and the uncertainty estimate of the predictive distribution that is achieved with an MC approach, while being fast enough for real-time deployments of BDNNs.
Critical Business Decision Making for Technology Startups -- A PerceptIn Case Study
Sep 07, 2020
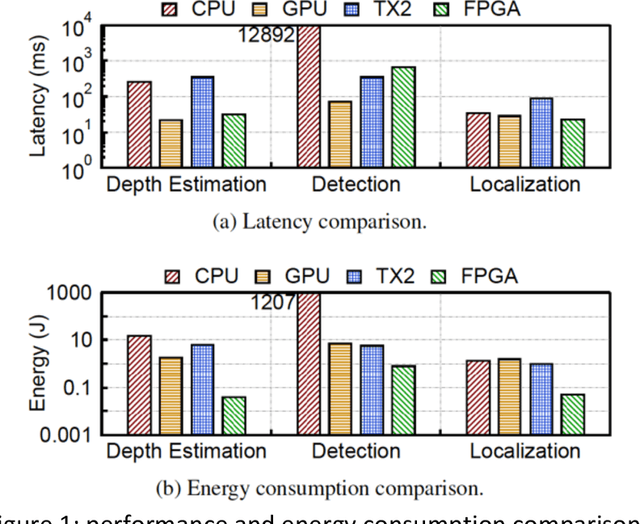
Most business decisions are made with analysis, but some are judgment calls not susceptible to analysis due to time or information constraints. In this article, we present a real-life case study of critical business decision making of PerceptIn, an autonomous driving technology startup. In early years of PerceptIn, PerceptIn had to make a decision on the design of computing systems for its autonomous vehicle products. By providing details on PerceptIn's decision process and the results of the decision, we hope to provide some insights that can be beneficial to entrepreneurs and engineering managers in technology startups.
STT-CBS: A Conflict-Based Search Algorithm for Multi-Agent Path Finding with Stochastic Travel Times
Apr 17, 2020
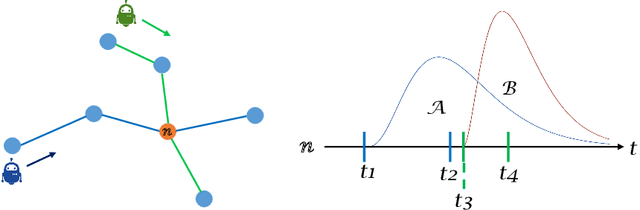
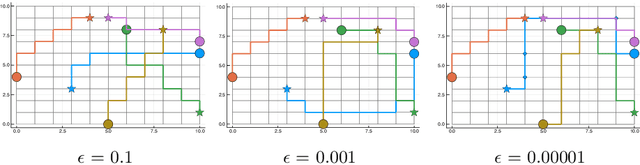
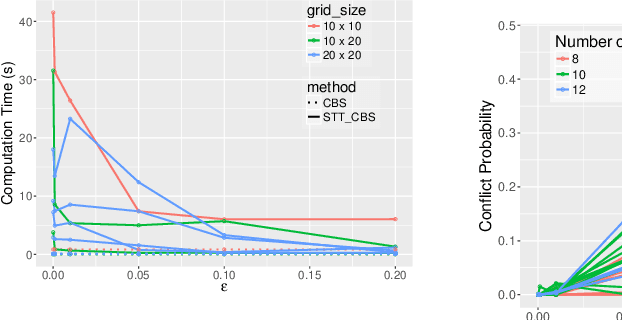
We address the Multi-Agent Path Finding problem on a graph for agents assigned to goals in a known environment and under uncertainty. Our algorithm, called STT-CBS, uses Conflict-Based Search (CBS) with a stochastic travel time (STT) model for the agents. We model robot travel time along each edge of the graph by independent gamma-distributed random variables and propose probabilistic conflict identification and constraint creation methods to robustly handle travel time uncertainty. We show that under reasonable assumptions our algorithm is complete and optimal in terms of expected sum of travel times, while ensuring an upper bound on each pairwise conflict probability. Simulations and hardware experiments show that STT-CBS is able to significantly decrease conflict probability over CBS, while remaining within the same complexity class.
Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping
Oct 26, 2020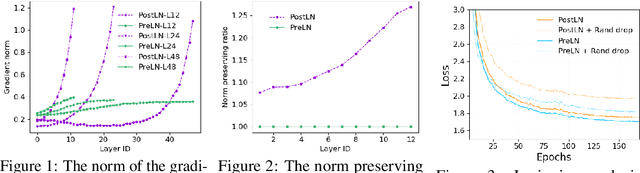
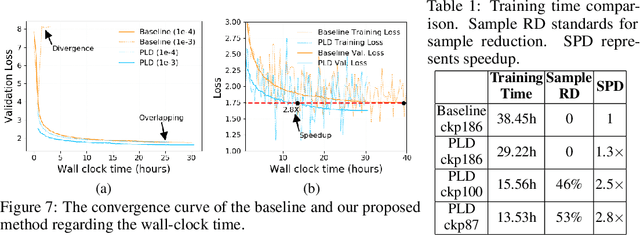
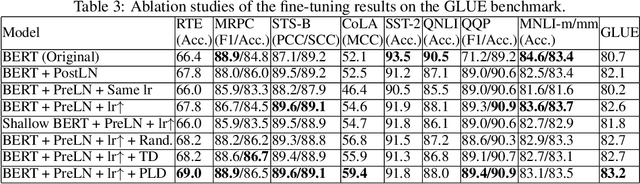
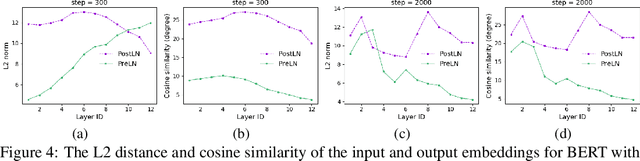
Recently, Transformer-based language models have demonstrated remarkable performance across many NLP domains. However, the unsupervised pre-training step of these models suffers from unbearable overall computational expenses. Current methods for accelerating the pre-training either rely on massive parallelism with advanced hardware or are not applicable to language modeling. In this work, we propose a method based on progressive layer dropping that speeds the training of Transformer-based language models, not at the cost of excessive hardware resources but from model architecture change and training technique boosted efficiency. Extensive experiments on BERT show that the proposed method achieves a 24% time reduction on average per sample and allows the pre-training to be 2.5 times faster than the baseline to get a similar accuracy on downstream tasks. While being faster, our pre-trained models are equipped with strong knowledge transferability, achieving comparable and sometimes higher GLUE score than the baseline when pre-trained with the same number of samples.
Learning Branching Heuristics for Propositional Model Counting
Jul 07, 2020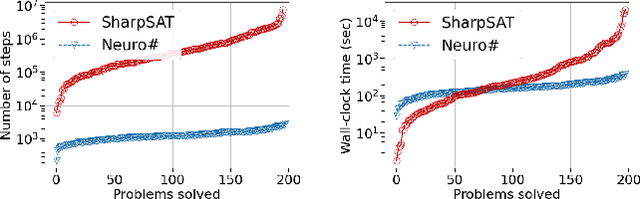
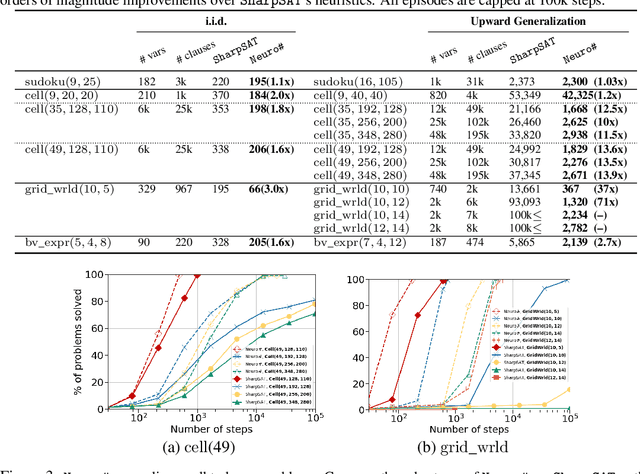
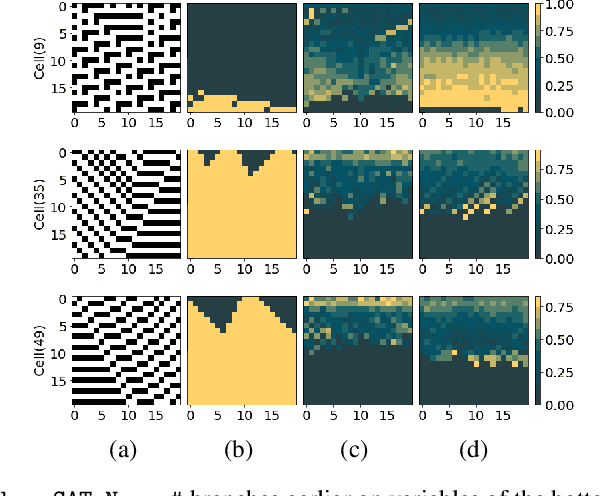
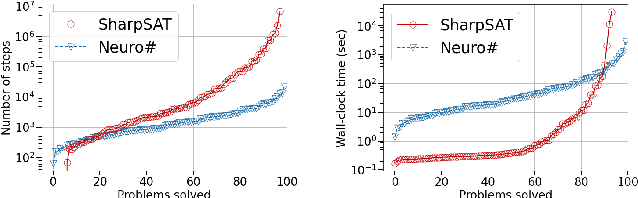
Propositional model counting or #SAT is the problem of computing the number of satisfying assignments of a Boolean formula and many discrete probabilistic inference problems can be translated into a model counting problem to be solved by #SAT solvers. Generic ``exact'' #SAT solvers, however, are often not scalable to industrial-level instances. In this paper, we present Neuro#, an approach for learning branching heuristics for exact #SAT solvers via evolution strategies (ES) to reduce the number of branching steps the solver takes to solve an instance. We experimentally show that our approach not only reduces the step count on similarly distributed held-out instances but it also generalizes to much larger instances from the same problem family. The gap between the learned and the vanilla solver on larger instances is sometimes so wide that the learned solver can even overcome the run time overhead of querying the model and beat the vanilla in wall-clock time by orders of magnitude.