 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSFL: A Post-Training Neuro-Symbolic Fuzzy Logic Framework for Boolean Operators in Neural Embeddings
Apr 12, 2026Standard dense retrievers lack a native calculus for multi-atom logical constraints. We introduce Neuro-Symbolic Fuzzy Logic (NSFL), a framework that adapts formal t-norms and t-conorms to neural embedding spaces without requiring retraining. NSFL operates as a first-order hybrid calculus: it anchors logical operations on isolated zero-order similarity scores while actively steering representations using Neuro-Symbolic Deltas (NS-Delta) -- the first-order marginal differences derived from contextual fusion. This preserves pure atomic meaning while capturing domain reliance, preventing the representation collapse and manifold escape endemic to traditional geometric baselines. For scalable real-time retrieval, Spherical Query Optimization (SQO) leverages Riemannian optimization to project these fuzzy formulas into manifold-stable query vectors. Validated across six distinct encoder configurations and two modalities (including zero-shot and SOTA fine-tuned models), NSFL yields mAP improvements up to +81%. Notably, NSFL provides an additive 20% average and up to 47% boost even when applied to encoders explicitly fine-tuned for logical reasoning. By establishing a training-free, order-aware calculus for high-dimensional spaces, this framework lays the foundation for future dynamic scaling and learned manifold logic.
Few Shots Text to Image Retrieval: New Benchmarking Dataset and Optimization Methods
Mar 26, 2026Pre-trained vision-language models (VLMs) excel in multimodal tasks, commonly encoding images as embedding vectors for storage in databases and retrieval via approximate nearest neighbor search (ANNS). However, these models struggle with compositional queries and out-of-distribution (OOD) image-text pairs. Inspired by human cognition's ability to learn from minimal examples, we address this performance gap through few-shot learning approaches specifically designed for image retrieval. We introduce the Few-Shot Text-to-Image Retrieval (FSIR) task and its accompanying benchmark dataset, FSIR-BD - the first to explicitly target image retrieval by text accompanied by reference examples, focusing on the challenging compositional and OOD queries. The compositional part is divided to urban scenes and nature species, both in specific situations or with distinctive features. FSIR-BD contains 38,353 images and 303 queries, with 82% comprising the test corpus (averaging per query 37 positives, ground truth matches, and significant number of hard negatives) and 18% forming the few-shot reference corpus (FSR) of exemplar positive and hard negative images. Additionally, we propose two novel retrieval optimization methods leveraging single shot or few shot reference examples in the FSR to improve performance. Both methods are compatible with any pre-trained image encoder, making them applicable to existing large-scale environments. Our experiments demonstrate that: (1) FSIR-BD provides a challenging benchmark for image retrieval; and (2) our optimization methods outperform existing baselines as measured by mean Average Precision (mAP). Further research into FSIR optimization methods will help narrow the gap between machine and human-level understanding, particularly for compositional reasoning from limited examples.
Rotation Invariant Quantization for Model Compression
Mar 03, 2023



Post-training Neural Network (NN) model compression is an attractive approach for deploying large, memory-consuming models on devices with limited memory resources. In this study, we investigate the rate-distortion tradeoff for NN model compression. First, we suggest a Rotation-Invariant Quantization (RIQ) technique that utilizes a single parameter to quantize the entire NN model, yielding a different rate at each layer, i.e., mixed-precision quantization. Then, we prove that our rotation-invariant approach is optimal in terms of compression. We rigorously evaluate RIQ and demonstrate its capabilities on various models and tasks. For example, RIQ facilitates $\times 19.4$ and $\times 52.9$ compression ratios on pre-trained VGG dense and pruned models, respectively, with $<0.4\%$ accuracy degradation. Code: \url{https://github.com/ehaleva/RIQ}.
Demonstration Informed Specification Search
Dec 20, 2021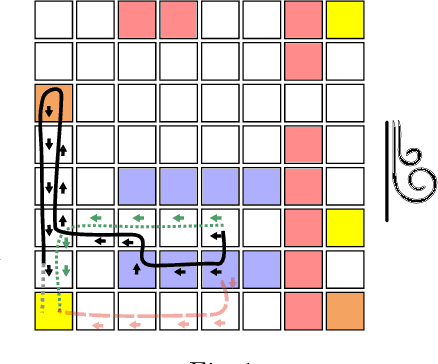
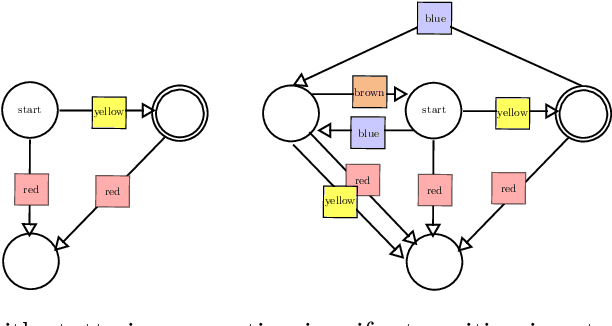
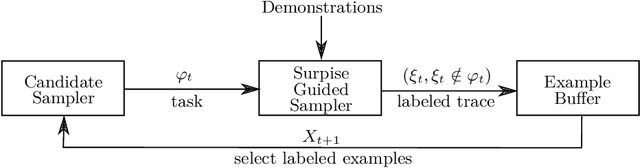
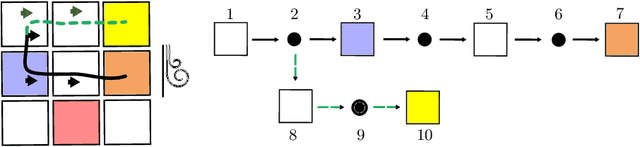
This paper considers the problem of learning history dependent task specifications, e.g. automata and temporal logic, from expert demonstrations. Unfortunately, the (countably infinite) number of tasks under consideration combined with an a-priori ignorance of what historical features are needed to encode the demonstrated task makes existing approaches to learning tasks from demonstrations inapplicable. To address this deficit, we propose Demonstration Informed Specification Search (DISS): a family of algorithms parameterized by black box access to (i) a maximum entropy planner and (ii) an algorithm for identifying concepts, e.g., automata, from labeled examples. DISS works by alternating between (i) conjecturing labeled examples to make the demonstrations less surprising and (ii) sampling concepts consistent with the current labeled examples. In the context of tasks described by deterministic finite automata, we provide a concrete implementation of DISS that efficiently combines partial knowledge of the task and a single expert demonstration to identify the full task specification.
Learning Branching Heuristics for Propositional Model Counting
Jul 07, 2020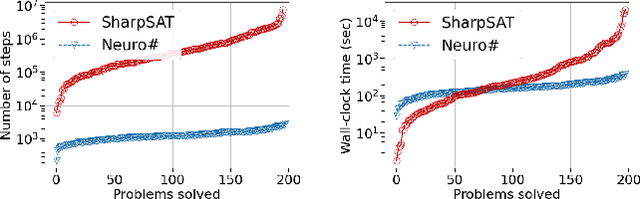
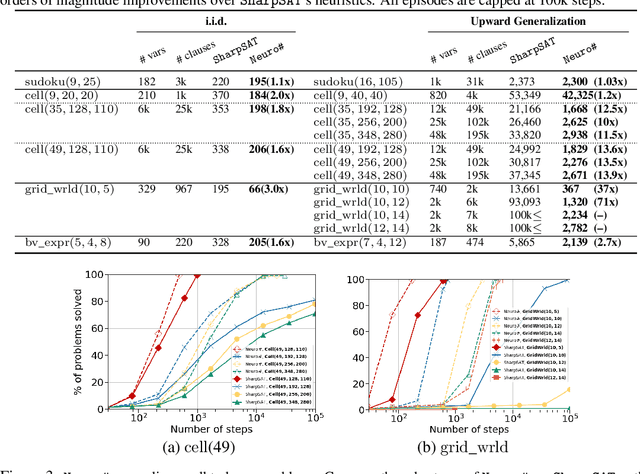
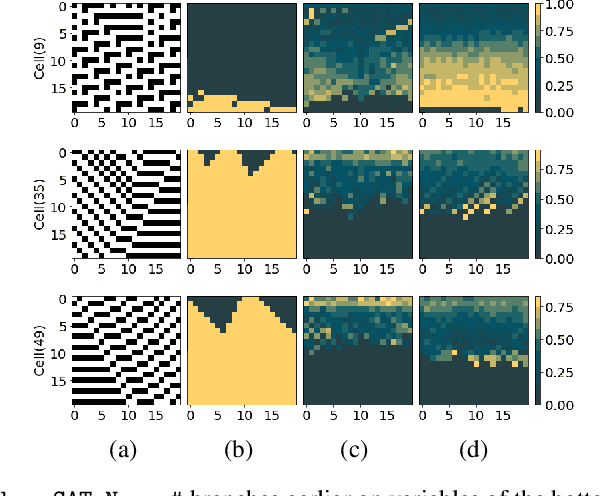
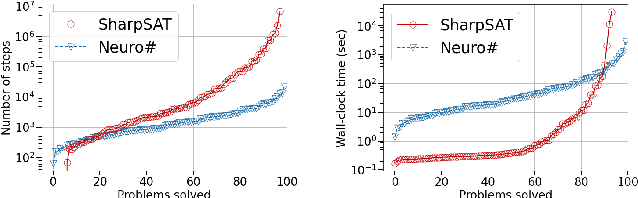
Propositional model counting or #SAT is the problem of computing the number of satisfying assignments of a Boolean formula and many discrete probabilistic inference problems can be translated into a model counting problem to be solved by #SAT solvers. Generic ``exact'' #SAT solvers, however, are often not scalable to industrial-level instances. In this paper, we present Neuro#, an approach for learning branching heuristics for exact #SAT solvers via evolution strategies (ES) to reduce the number of branching steps the solver takes to solve an instance. We experimentally show that our approach not only reduces the step count on similarly distributed held-out instances but it also generalizes to much larger instances from the same problem family. The gap between the learned and the vanilla solver on larger instances is sometimes so wide that the learned solver can even overcome the run time overhead of querying the model and beat the vanilla in wall-clock time by orders of magnitude.
Learning Heuristics for Automated Reasoning through Deep Reinforcement Learning
Jul 20, 2018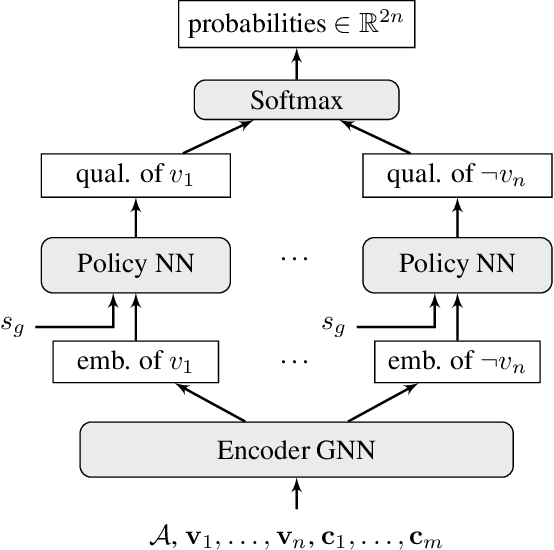
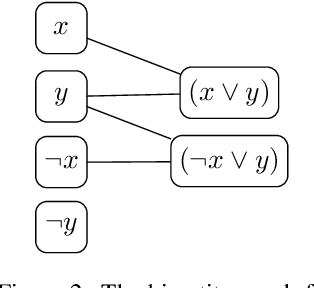
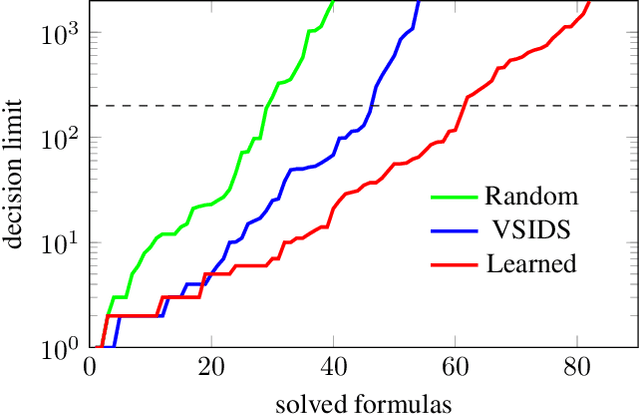
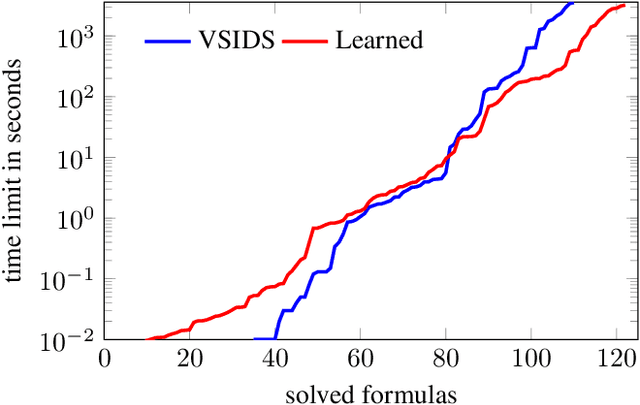
We demonstrate how to learn efficient heuristics for automated reasoning algorithms through deep reinforcement learning. We consider search algorithms for quantified Boolean logics, that already can solve formulas of impressive size - up to 100s of thousands of variables. The main challenge is to find a representation which lends to making predictions in a scalable way. The heuristics learned through our approach significantly improve over the handwritten heuristics for several sets of formulas.