 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient One-Pass End-to-End Entity Linking for Questions
Oct 06, 2020
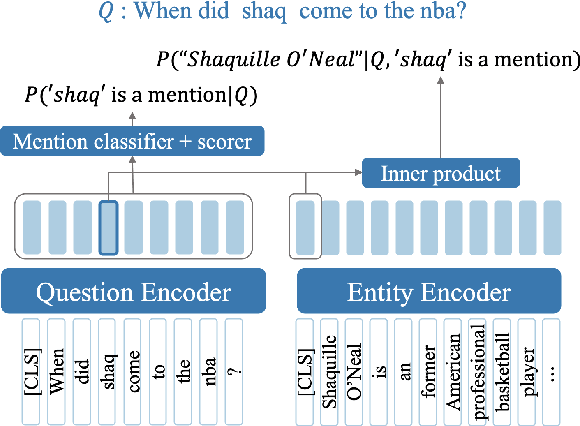
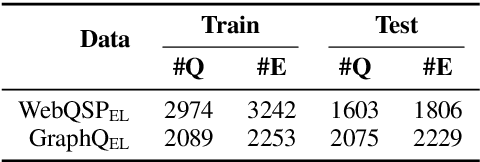
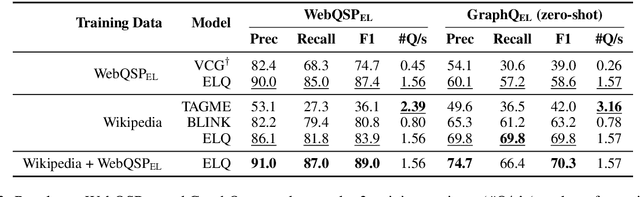
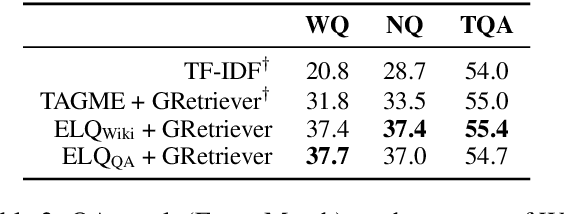
We present ELQ, a fast end-to-end entity linking model for questions, which uses a biencoder to jointly perform mention detection and linking in one pass. Evaluated on WebQSP and GraphQuestions with extended annotations that cover multiple entities per question, ELQ outperforms the previous state of the art by a large margin of +12.7% and +19.6% F1, respectively. With a very fast inference time (1.57 examples/s on a single CPU), ELQ can be useful for downstream question answering systems. In a proof-of-concept experiment, we demonstrate that using ELQ significantly improves the downstream QA performance of GraphRetriever (arXiv:1911.03868). Code and data available at https://github.com/facebookresearch/BLINK/tree/master/elq
Addressing machine learning concept drift reveals declining vaccine sentiment during the COVID-19 pandemic
Dec 07, 2020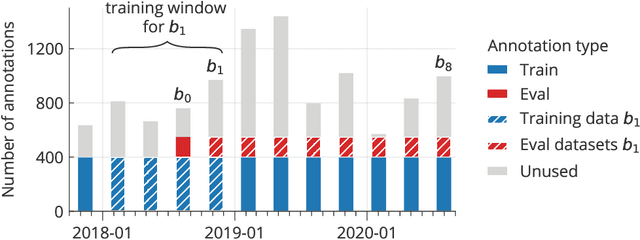
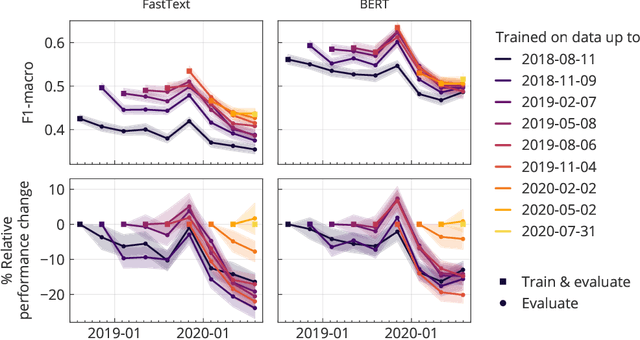
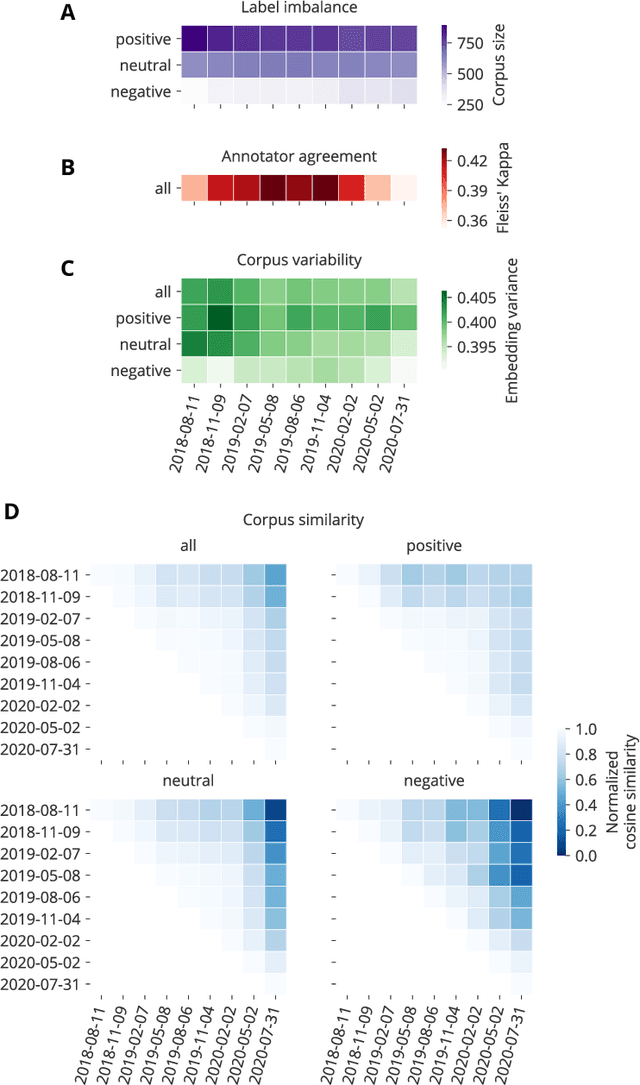
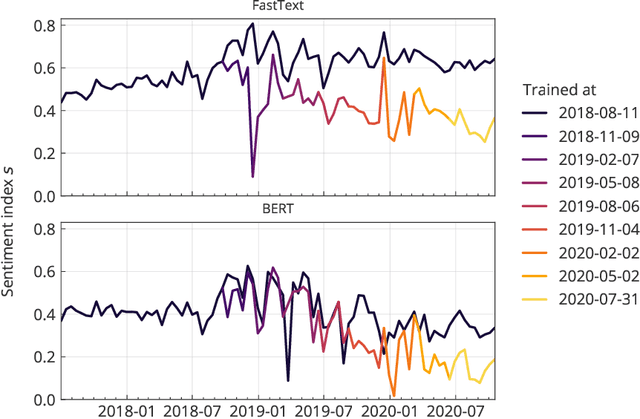
Social media analysis has become a common approach to assess public opinion on various topics, including those about health, in near real-time. The growing volume of social media posts has led to an increased usage of modern machine learning methods in natural language processing. While the rapid dynamics of social media can capture underlying trends quickly, it also poses a technical problem: algorithms trained on annotated data in the past may underperform when applied to contemporary data. This phenomenon, known as concept drift, can be particularly problematic when rapid shifts occur either in the topic of interest itself, or in the way the topic is discussed. Here, we explore the effect of machine learning concept drift by focussing on vaccine sentiments expressed on Twitter, a topic of central importance especially during the COVID-19 pandemic. We show that while vaccine sentiment has declined considerably during the COVID-19 pandemic in 2020, algorithms trained on pre-pandemic data would have largely missed this decline due to concept drift. Our results suggest that social media analysis systems must address concept drift in a continuous fashion in order to avoid the risk of systematic misclassification of data, which is particularly likely during a crisis when the underlying data can change suddenly and rapidly.
Privileged Knowledge Distillation for Online Action Detection
Nov 18, 2020

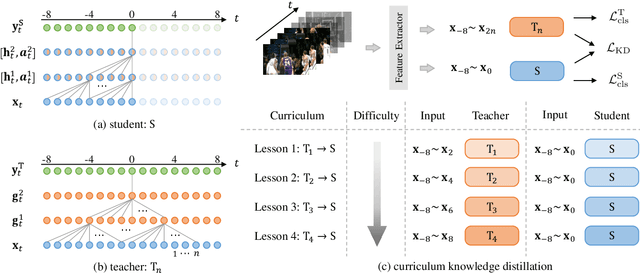
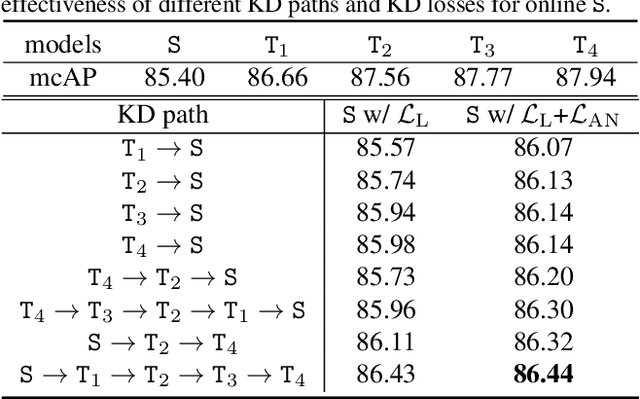
Online Action Detection (OAD) in videos is proposed as a per-frame labeling task to address the real-time prediction tasks that can only obtain the previous and current video frames. This paper presents a novel learning-with-privileged based framework for online action detection where the future frames only observable at the training stages are considered as a form of privileged information. Knowledge distillation is employed to transfer the privileged information from the offline teacher to the online student. We note that this setting is different from conventional KD because the difference between the teacher and student models mostly lies in input data rather than the network architecture. We propose Privileged Knowledge Distillation (PKD) which (i) schedules a curriculum learning procedure and (ii) inserts auxiliary nodes to the student model, both for shrinking the information gap and improving learning performance. Compared to other OAD methods that explicitly predict future frames, our approach avoids learning unpredictable unnecessary yet inconsistent visual contents and achieves state-of-the-art accuracy on two popular OAD benchmarks, TVSeries and THUMOS14.
Anytime MiniBatch: Exploiting Stragglers in Online Distributed Optimization
Jun 10, 2020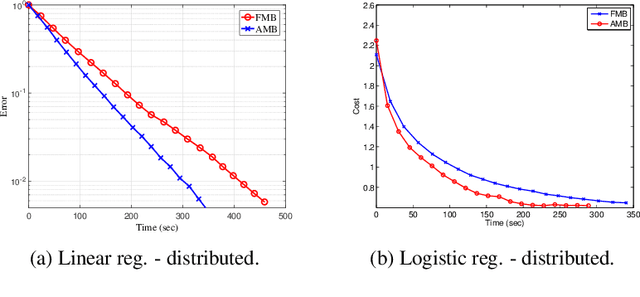
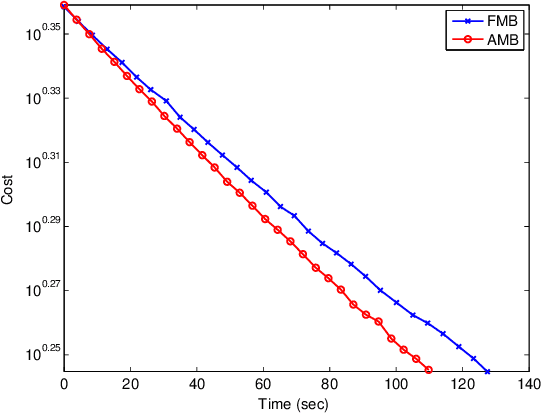
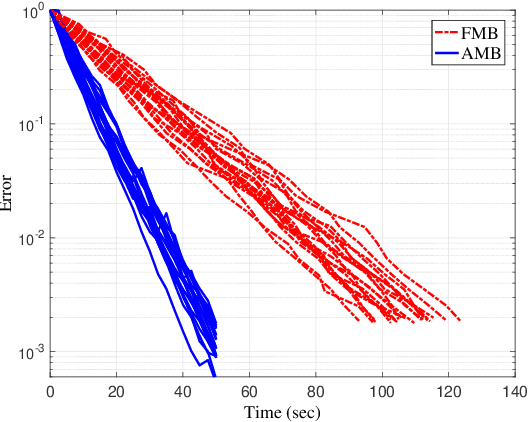
Distributed optimization is vital in solving large-scale machine learning problems. A widely-shared feature of distributed optimization techniques is the requirement that all nodes complete their assigned tasks in each computational epoch before the system can proceed to the next epoch. In such settings, slow nodes, called stragglers, can greatly slow progress. To mitigate the impact of stragglers, we propose an online distributed optimization method called Anytime Minibatch. In this approach, all nodes are given a fixed time to compute the gradients of as many data samples as possible. The result is a variable per-node minibatch size. Workers then get a fixed communication time to average their minibatch gradients via several rounds of consensus, which are then used to update primal variables via dual averaging. Anytime Minibatch prevents stragglers from holding up the system without wasting the work that stragglers can complete. We present a convergence analysis and analyze the wall time performance. Our numerical results show that our approach is up to 1.5 times faster in Amazon EC2 and it is up to five times faster when there is greater variability in compute node performance.
* International Conference on Learning Representations (ICLR), May 2019, New Orleans, LA, USA
A thermodynamically consistent chemical spiking neuron capable of autonomous Hebbian learning
Sep 28, 2020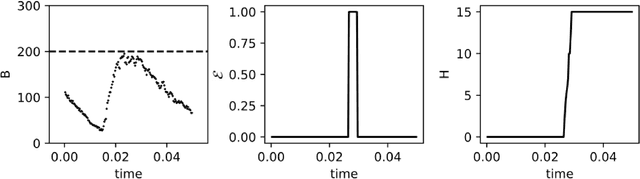
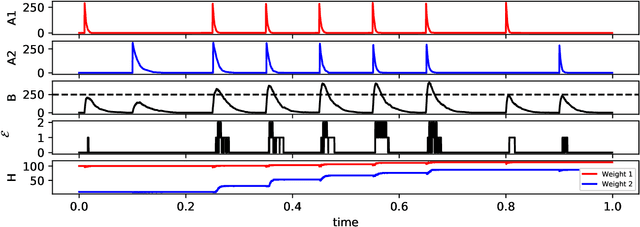
We propose a fully autonomous, thermodynamically consistent set of chemical reactions that implements a spiking neuron. This chemical neuron is able to learn input patterns in a Hebbian fashion. The system is scalable to arbitrarily many input channels. We demonstrate its performance in learning frequency biases in the input as well as correlations between different input channels. Efficient computation of time-correlations requires a highly non-linear activation function. The resource requirements of a non-linear activation function are discussed. In addition to the thermodynamically consistent model of the CN, we also propose a biologically plausible version that could be engineered in a synthetic biology context.
Bayesian Optimization for Selecting Efficient Machine Learning Models
Aug 02, 2020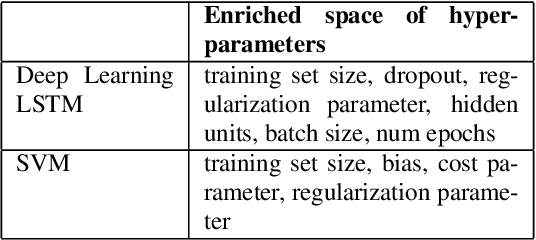



The performance of many machine learning models depends on their hyper-parameter settings. Bayesian Optimization has become a successful tool for hyper-parameter optimization of machine learning algorithms, which aims to identify optimal hyper-parameters during an iterative sequential process. However, most of the Bayesian Optimization algorithms are designed to select models for effectiveness only and ignore the important issue of model training efficiency. Given that both model effectiveness and training time are important for real-world applications, models selected for effectiveness may not meet the strict training time requirements necessary to deploy in a production environment. In this work, we present a unified Bayesian Optimization framework for jointly optimizing models for both prediction effectiveness and training efficiency. We propose an objective that captures the tradeoff between these two metrics and demonstrate how we can jointly optimize them in a principled Bayesian Optimization framework. Experiments on model selection for recommendation tasks indicate models selected this way significantly improves model training efficiency while maintaining strong effectiveness as compared to state-of-the-art Bayesian Optimization algorithms.
Optimal Decision Lists using SAT
Oct 19, 2020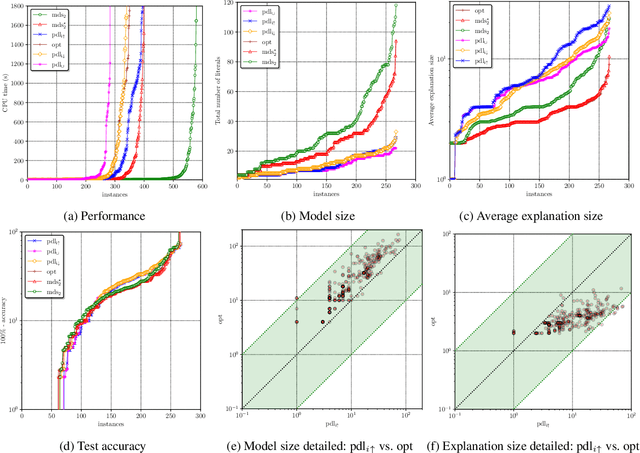
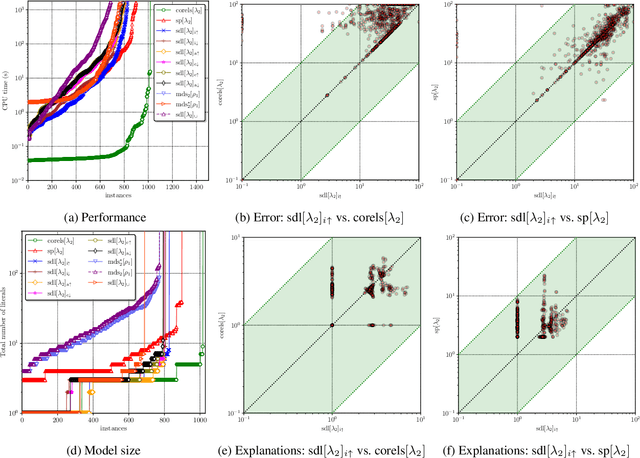
Decision lists are one of the most easily explainable machine learning models. Given the renewed emphasis on explainable machine learning decisions, this machine learning model is increasingly attractive, combining small size and clear explainability. In this paper, we show for the first time how to construct optimal "perfect" decision lists which are perfectly accurate on the training data, and minimal in size, making use of modern SAT solving technology. We also give a new method for determining optimal sparse decision lists, which trade off size and accuracy. We contrast the size and test accuracy of optimal decisions lists versus optimal decision sets, as well as other state-of-the-art methods for determining optimal decision lists. We also examine the size of average explanations generated by decision sets and decision lists.
RSINet: Rotation-Scale Invariant Network for Online Visual Tracking
Nov 18, 2020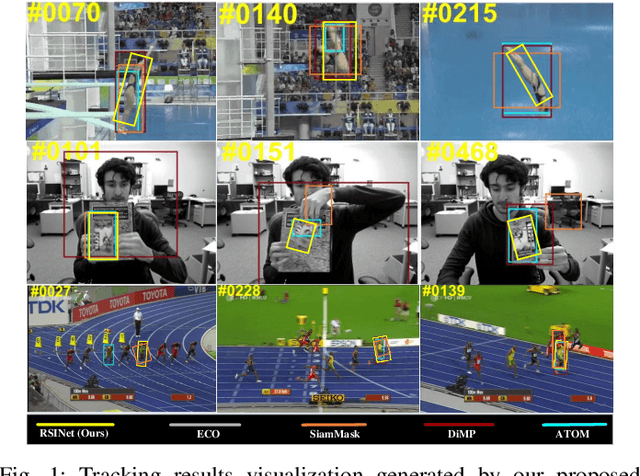
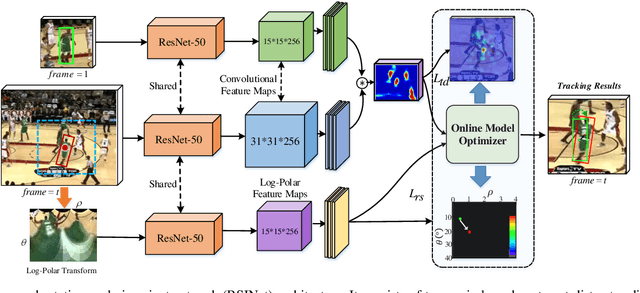
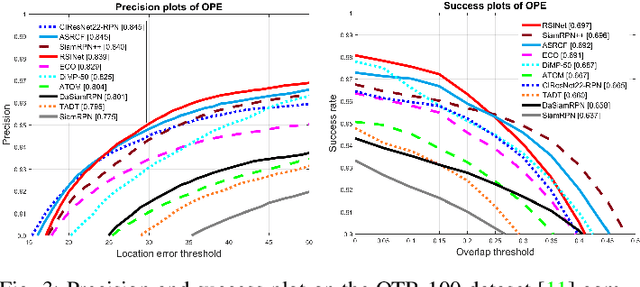
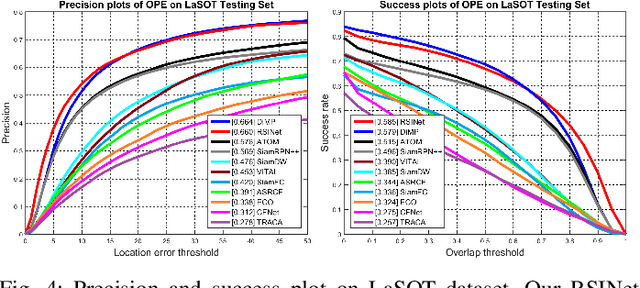
Most Siamese network-based trackers perform the tracking process without model update, and cannot learn targetspecific variation adaptively. Moreover, Siamese-based trackers infer the new state of tracked objects by generating axis-aligned bounding boxes, which contain extra background noise, and are unable to accurately estimate the rotation and scale transformation of moving objects, thus potentially reducing tracking performance. In this paper, we propose a novel Rotation-Scale Invariant Network (RSINet) to address the above problem. Our RSINet tracker consists of a target-distractor discrimination branch and a rotation-scale estimation branch, the rotation and scale knowledge can be explicitly learned by a multi-task learning method in an end-to-end manner. In addtion, the tracking model is adaptively optimized and updated under spatio-temporal energy control, which ensures model stability and reliability, as well as high tracking efficiency. Comprehensive experiments on OTB-100, VOT2018, and LaSOT benchmarks demonstrate that our proposed RSINet tracker yields new state-of-the-art performance compared with recent trackers, while running at real-time speed about 45 FPS.
BundleFusion: Real-time Globally Consistent 3D Reconstruction using On-the-fly Surface Re-integration
Feb 07, 2017
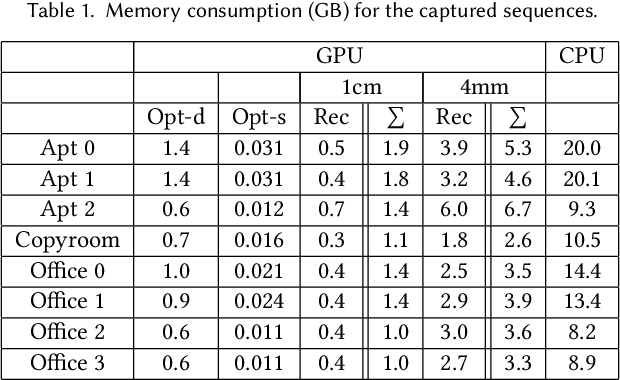
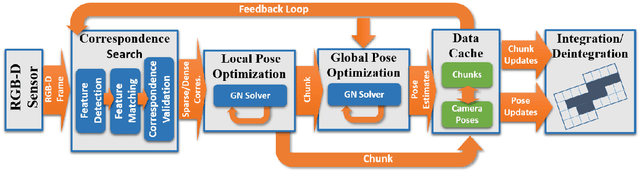
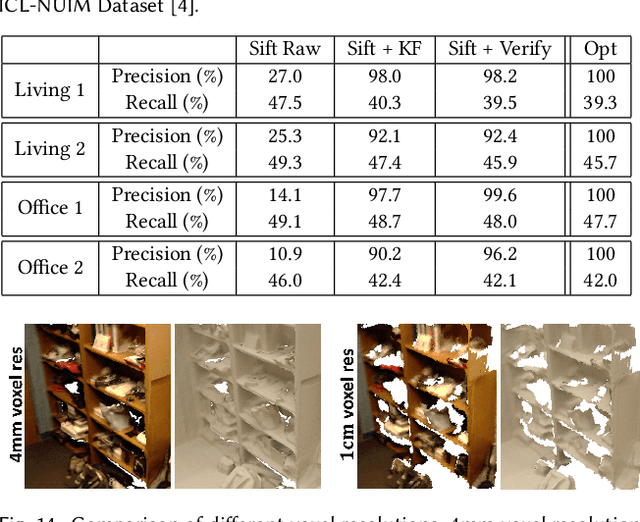
Real-time, high-quality, 3D scanning of large-scale scenes is key to mixed reality and robotic applications. However, scalability brings challenges of drift in pose estimation, introducing significant errors in the accumulated model. Approaches often require hours of offline processing to globally correct model errors. Recent online methods demonstrate compelling results, but suffer from: (1) needing minutes to perform online correction preventing true real-time use; (2) brittle frame-to-frame (or frame-to-model) pose estimation resulting in many tracking failures; or (3) supporting only unstructured point-based representations, which limit scan quality and applicability. We systematically address these issues with a novel, real-time, end-to-end reconstruction framework. At its core is a robust pose estimation strategy, optimizing per frame for a global set of camera poses by considering the complete history of RGB-D input with an efficient hierarchical approach. We remove the heavy reliance on temporal tracking, and continually localize to the globally optimized frames instead. We contribute a parallelizable optimization framework, which employs correspondences based on sparse features and dense geometric and photometric matching. Our approach estimates globally optimized (i.e., bundle adjusted) poses in real-time, supports robust tracking with recovery from gross tracking failures (i.e., relocalization), and re-estimates the 3D model in real-time to ensure global consistency; all within a single framework. Our approach outperforms state-of-the-art online systems with quality on par to offline methods, but with unprecedented speed and scan completeness. Our framework leads to a comprehensive online scanning solution for large indoor environments, enabling ease of use and high-quality results.
Failure Prediction by Confidence Estimation of Uncertainty-Aware Dirichlet Networks
Oct 19, 2020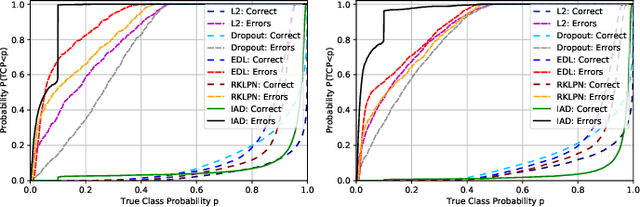
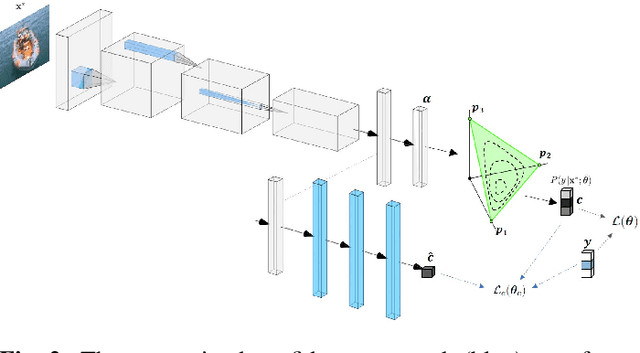
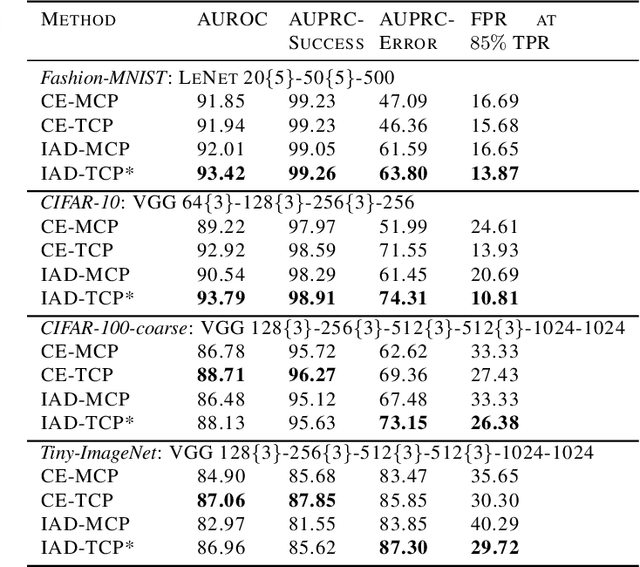
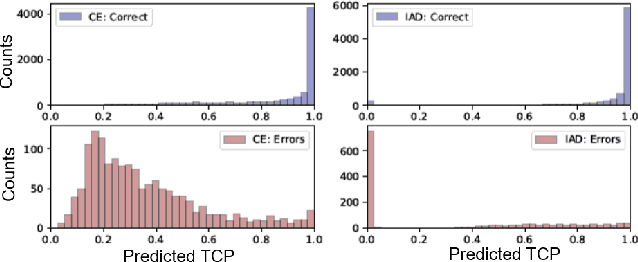
Reliably assessing model confidence in deep learning and predicting errors likely to be made are key elements in providing safety for model deployment, in particular for applications with dire consequences. In this paper, it is first shown that uncertainty-aware deep Dirichlet neural networks provide an improved separation between the confidence of correct and incorrect predictions in the true class probability (TCP) metric. Second, as the true class is unknown at test time, a new criterion is proposed for learning the true class probability by matching prediction confidence scores while taking imbalance and TCP constraints into account for correct predictions and failures. Experimental results show our method improves upon the maximum class probability (MCP) baseline and predicted TCP for standard networks on several image classification tasks with various network architectures.