 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable Discovery of Time-Series Shapelets
Mar 11, 2015
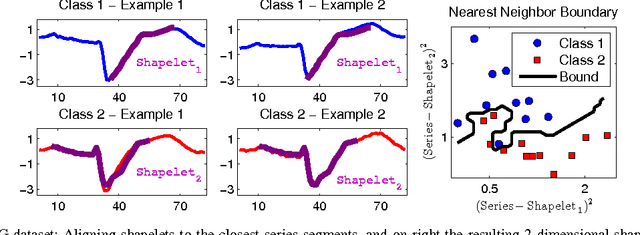
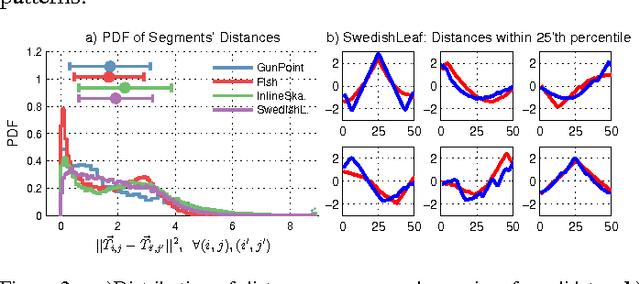
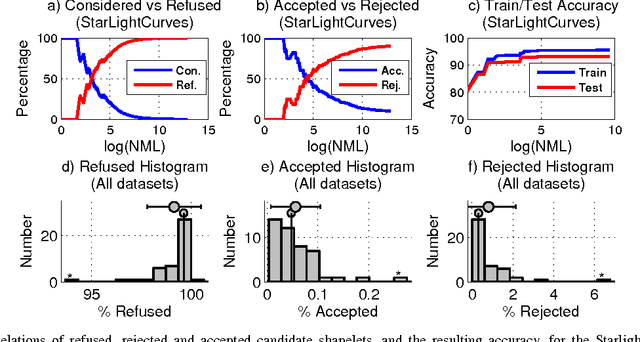
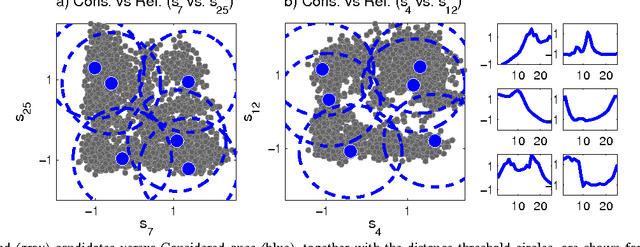
Time-series classification is an important problem for the data mining community due to the wide range of application domains involving time-series data. A recent paradigm, called shapelets, represents patterns that are highly predictive for the target variable. Shapelets are discovered by measuring the prediction accuracy of a set of potential (shapelet) candidates. The candidates typically consist of all the segments of a dataset, therefore, the discovery of shapelets is computationally expensive. This paper proposes a novel method that avoids measuring the prediction accuracy of similar candidates in Euclidean distance space, through an online clustering pruning technique. In addition, our algorithm incorporates a supervised shapelet selection that filters out only those candidates that improve classification accuracy. Empirical evidence on 45 datasets from the UCR collection demonstrate that our method is 3-4 orders of magnitudes faster than the fastest existing shapelet-discovery method, while providing better prediction accuracy.
A Distributed Model-Free Ride-Sharing Approach for Joint Matching, Pricing, and Dispatching using Deep Reinforcement Learning
Oct 05, 2020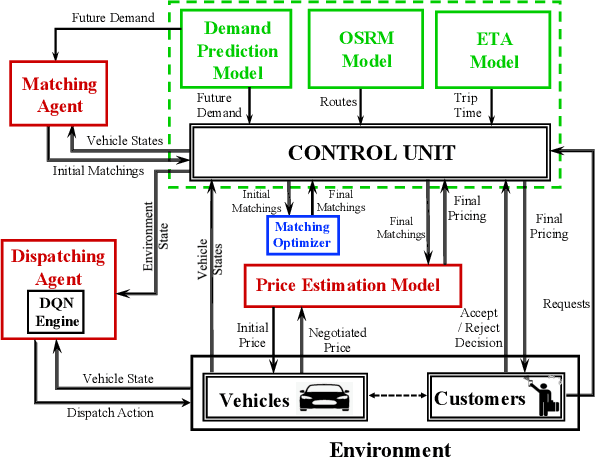
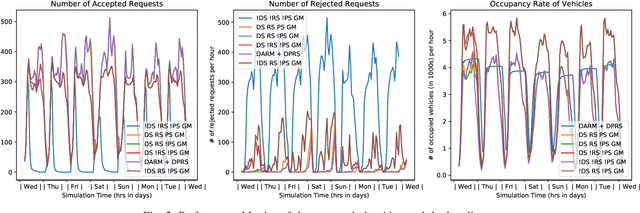
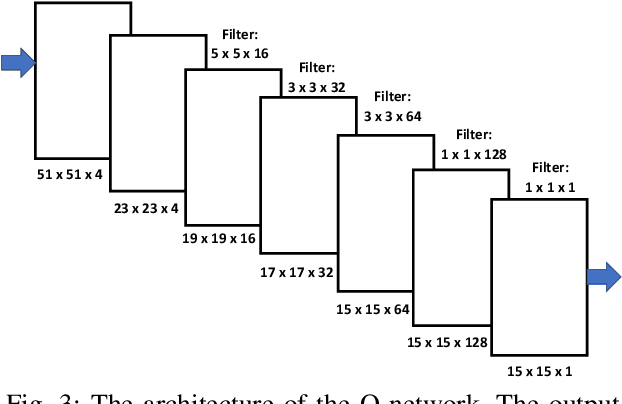
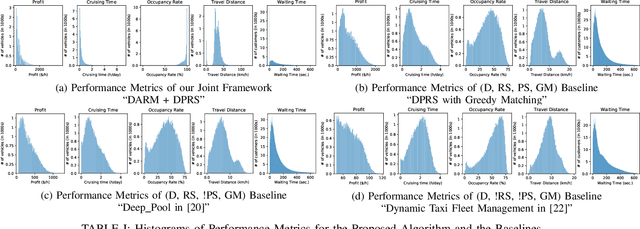
Significant development of ride-sharing services presents a plethora of opportunities to transform urban mobility by providing personalized and convenient transportation while ensuring efficiency of large-scale ride pooling. However, a core problem for such services is route planning for each driver to fulfill the dynamically arriving requests while satisfying given constraints. Current models are mostly limited to static routes with only two rides per vehicle (optimally) or three (with heuristics). In this paper, we present a dynamic, demand aware, and pricing-based vehicle-passenger matching and route planning framework that (1) dynamically generates optimal routes for each vehicle based on online demand, pricing associated with each ride, vehicle capacities and locations. This matching algorithm starts greedily and optimizes over time using an insertion operation, (2) involves drivers in the decision-making process by allowing them to propose a different price based on the expected reward for a particular ride as well as the destination locations for future rides, which is influenced by supply-and demand computed by the Deep Q-network, (3) allows customers to accept or reject rides based on their set of preferences with respect to pricing and delay windows, vehicle type and carpooling preferences, and (4) based on demand prediction, our approach re-balances idle vehicles by dispatching them to the areas of anticipated high demand using deep Reinforcement Learning (RL). Our framework is validated using the New York City Taxi public dataset; however, we consider different vehicle types and designed customer utility functions to validate the setup and study different settings. Experimental results show the effectiveness of our approach in real-time and large scale settings.
Autoregressive Asymmetric Linear Gaussian Hidden Markov Models
Oct 27, 2020
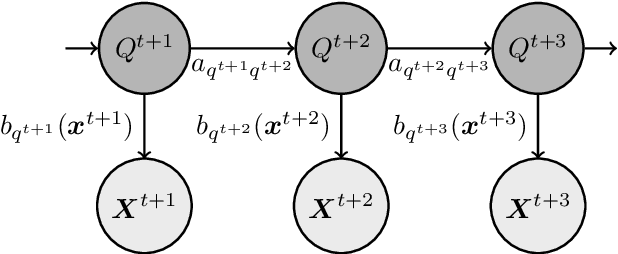

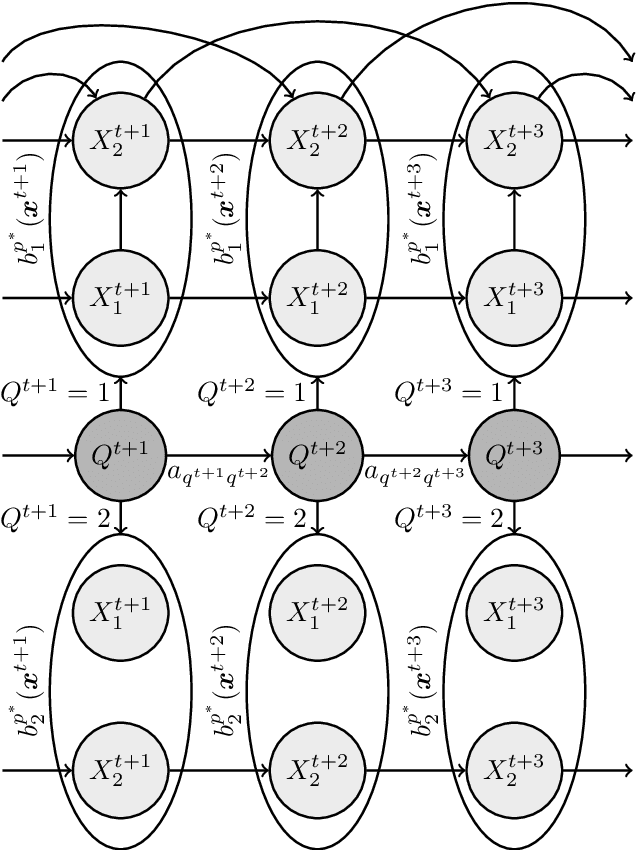
In a real life process evolving over time, the relationship between its relevant variables may change. Therefore, it is advantageous to have different inference models for each state of the process. Asymmetric hidden Markov models fulfil this dynamical requirement and provide a framework where the trend of the process can be expressed as a latent variable. In this paper, we modify these recent asymmetric hidden Markov models to have an asymmetric autoregressive component, allowing the model to choose the order of autoregression that maximizes its penalized likelihood for a given training set. Additionally, we show how inference, hidden states decoding and parameter learning must be adapted to fit the proposed model. Finally, we run experiments with synthetic and real data to show the capabilities of this new model.
Linear Temporal Public Announcement Logic: a new perspective for reasoning the knowledge of multi-classifiers
Sep 09, 2020
Current applied intelligent systems have crucial shortcomings either in reasoning the gathered knowledge, or representation of comprehensive integrated information. To address these limitations, we develop a formal transition system which is applied to the common artificial intelligence (AI) systems, to reason about the findings. The developed model was created by combining the Public Announcement Logic (PAL) and the Linear Temporal Logic (LTL), which will be done to analyze both single-framed data and the following time-series data. To do this, first, the achieved knowledge by an AI-based system (i.e., classifiers) for an individual time-framed data, will be taken, and then, it would be modeled by a PAL. This leads to developing a unified representation of knowledge, and the smoothness in the integration of the gathered and external experiences. Therefore, the model could receive the classifier's predefined -- or any external -- knowledge, to assemble them in a unified manner. Alongside the PAL, all the timed knowledge changes will be modeled, using a temporal logic transition system. Later, following by the translation of natural language questions into the temporal formulas, the satisfaction leads the model to answer that question. This interpretation integrates the information of the recognized input data, rules, and knowledge. Finally, we suggest a mechanism to reduce the investigated paths for the performance improvements, which results in a partial correction for an object-detection system.
Risk-Aware Submodular Optimization for Multi-objective Travelling Salesperson Problem
Nov 02, 2020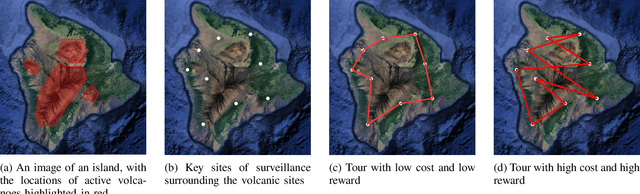
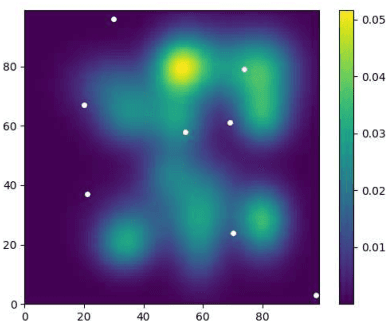
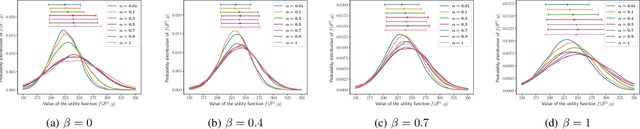
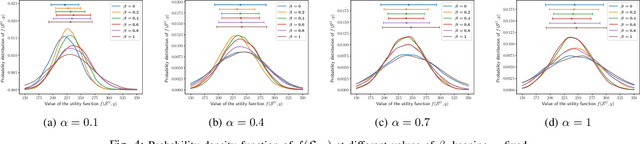
We introduce a risk-aware multi-objective Traveling Salesperson Problem (TSP) variant, where the robot tour cost and tour reward have to be optimized simultaneously. The robot obtains reward along the edges in the graph. We study the case where the rewards and the costs exhibit diminishing marginal gains, i.e., are submodular. Unlike prior work, we focus on the scenario where the costs and the rewards are uncertain and seek to maximize the Conditional-Value-at-Risk (CVaR) metric of the submodular function. We propose a risk-aware greedy algorithm (RAGA) to find a bounded-approximation algorithm. The approximation algorithm runs in polynomial time and is within a constant factor of the optimal and an additive term that depends on the optimal solution. We use the submodular function's curvature to improve approximation results further and verify the algorithm's performance through simulations.
Wireless Power Transfer for Future Networks: Signal Processing, Machine Learning, Computing, and Sensing
Jan 13, 2021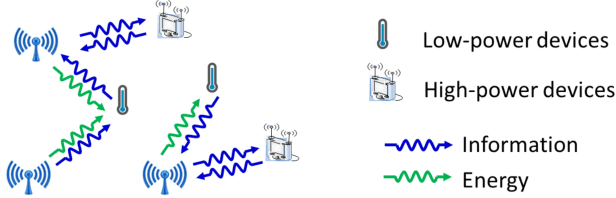
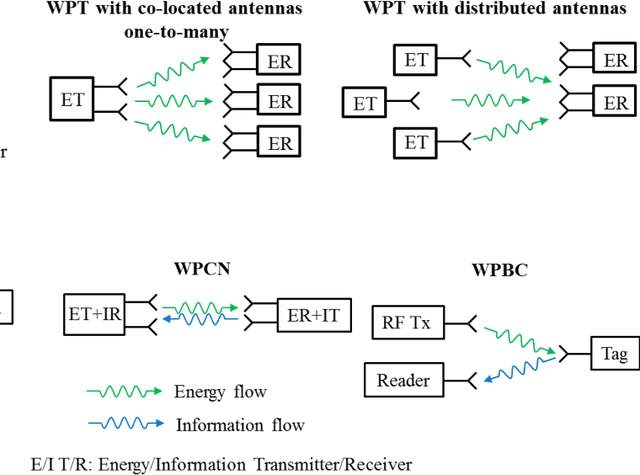

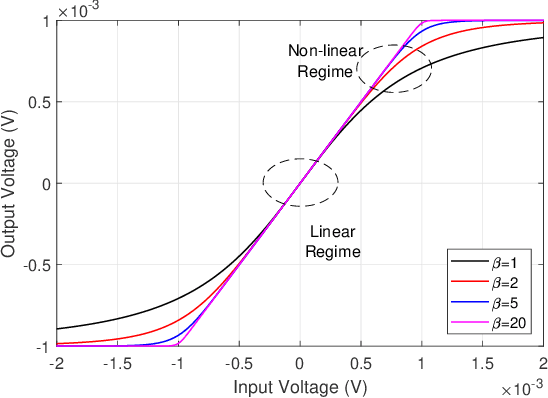
Wireless power transfer (WPT) is an emerging paradigm that will enable using wireless to its full potential in future networks, not only to convey information but also to deliver energy. Such networks will enable trillions of future low-power devices to sense, compute, connect, and energize anywhere, anytime, and on the move. The design of such future networks brings new challenges and opportunities for signal processing, machine learning, sensing, and computing so as to make the best use of the RF radiations, spectrum, and network infrastructure in providing cost-effective and real-time power supplies to wireless devices and enable wireless-powered applications. In this paper, we first review recent signal processing techniques to make WPT and wireless information and power transfer as efficient as possible. Topics include power amplifier and energy harvester nonlinearities, active and passive beamforming, intelligent reflecting surfaces, receive combining with multi-antenna harvester, modulation, coding, waveform, massive MIMO, channel acquisition, transmit diversity, multi-user power region characterization, coordinated multipoint, and distributed antenna systems. Then, we overview two different design methodologies: the model and optimize approach relying on analytical system models, modern convex optimization, and communication theory, and the learning approach based on data-driven end-to-end learning and physics-based learning. We discuss the pros and cons of each approach, especially when accounting for various nonlinearities in wireless-powered networks, and identify interesting emerging opportunities for the approaches to complement each other. Finally, we identify new emerging wireless technologies where WPT may play a key role -- wireless-powered mobile edge computing and wireless-powered sensing -- arguing WPT, communication, computation, and sensing must be jointly designed.
Misinformation has High Perplexity
Jun 08, 2020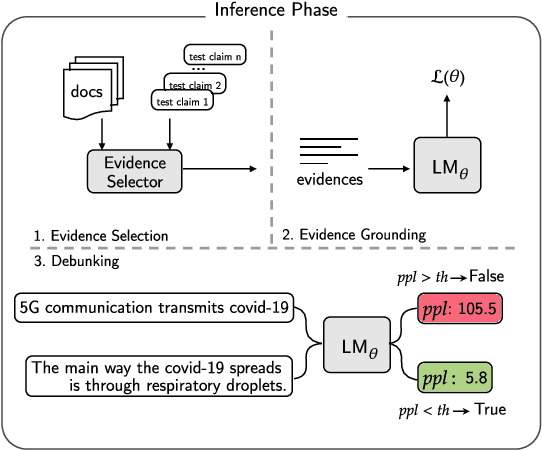


Debunking misinformation is an important and time-critical task as there could be adverse consequences when misinformation is not quashed promptly. However, the usual supervised approach to debunking via misinformation classification requires human-annotated data and is not suited to the fast time-frame of newly emerging events such as the COVID-19 outbreak. In this paper, we postulate that misinformation itself has higher perplexity compared to truthful statements, and propose to leverage the perplexity to debunk false claims in an unsupervised manner. First, we extract reliable evidence from scientific and news sources according to sentence similarity to the claims. Second, we prime a language model with the extracted evidence and finally evaluate the correctness of given claims based on the perplexity scores at debunking time. We construct two new COVID-19-related test sets, one is scientific, and another is political in content, and empirically verify that our system performs favorably compared to existing systems. We are releasing these datasets publicly to encourage more research in debunking misinformation on COVID-19 and other topics.
Leveraging Predictions in Smoothed Online Convex Optimization via Gradient-based Algorithms
Nov 25, 2020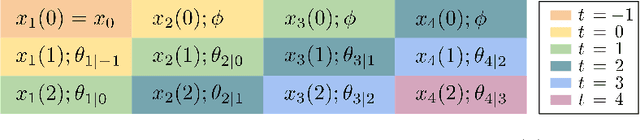
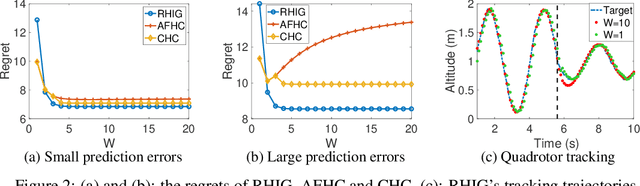
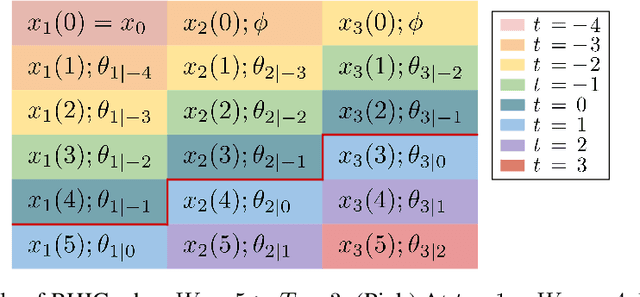
We consider online convex optimization with time-varying stage costs and additional switching costs. Since the switching costs introduce coupling across all stages, multi-step-ahead (long-term) predictions are incorporated to improve the online performance. However, longer-term predictions tend to suffer from lower quality. Thus, a critical question is: how to reduce the impact of long-term prediction errors on the online performance? To address this question, we introduce a gradient-based online algorithm, Receding Horizon Inexact Gradient (RHIG), and analyze its performance by dynamic regrets in terms of the temporal variation of the environment and the prediction errors. RHIG only considers at most $W$-step-ahead predictions to avoid being misled by worse predictions in the longer term. The optimal choice of $W$ suggested by our regret bounds depends on the tradeoff between the variation of the environment and the prediction accuracy. Additionally, we apply RHIG to a well-established stochastic prediction error model and provide expected regret and concentration bounds under correlated prediction errors. Lastly, we numerically test the performance of RHIG on quadrotor tracking problems.
The Univariate Marginal Distribution Algorithm Copes Well With Deception and Epistasis
Jul 16, 2020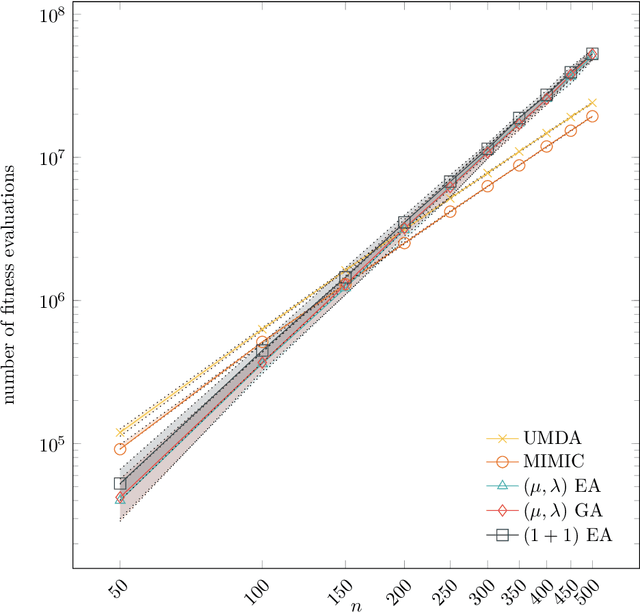
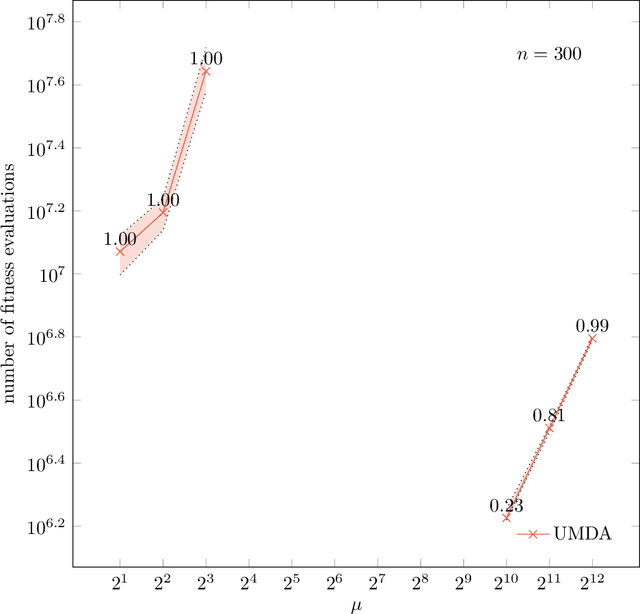
In their recent work, Lehre and Nguyen (FOGA 2019) show that the univariate marginal distribution algorithm (UMDA) needs time exponential in the parent populations size to optimize the DeceptiveLeadingBlocks (DLB) problem. They conclude from this result that univariate EDAs have difficulties with deception and epistasis. In this work, we show that this negative finding is caused by an unfortunate choice of the parameters of the UMDA. When the population sizes are chosen large enough to prevent genetic drift, then the UMDA optimizes the DLB problem with high probability with at most $\lambda(\frac{n}{2} + 2 e \ln n)$ fitness evaluations. Since an offspring population size $\lambda$ of order $n \log n$ can prevent genetic drift, the UMDA can solve the DLB problem with $O(n^2 \log n)$ fitness evaluations. In contrast, for classic evolutionary algorithms no better run time guarantee than $O(n^3)$ is known (which we prove to be tight for the ${(1+1)}$ EA), so our result rather suggests that the UMDA can cope well with deception and epistatis. From a broader perspective, our result shows that the UMDA can cope better with local optima than evolutionary algorithms; such a result was previously known only for the compact genetic algorithm. Together with the result of Lehre and Nguyen, our result for the first time rigorously proves that running EDAs in the regime with genetic drift can lead to drastic performance losses.
3D Point-to-Keypoint Voting Network for 6D Pose Estimation
Dec 22, 2020
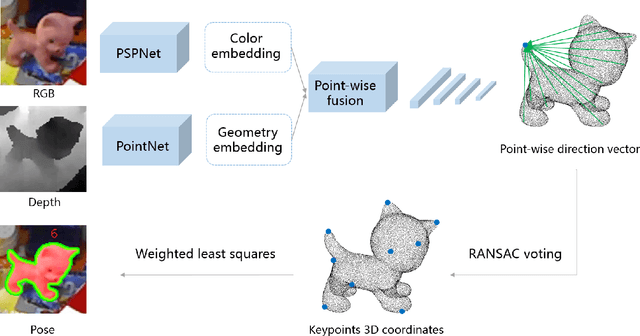


Object 6D pose estimation is an important research topic in the field of computer vision due to its wide application requirements and the challenges brought by complexity and changes in the real-world. We think fully exploring the characteristics of spatial relationship between points will help to improve the pose estimation performance, especially in the scenes of background clutter and partial occlusion. But this information was usually ignored in previous work using RGB image or RGB-D data. In this paper, we propose a framework for 6D pose estimation from RGB-D data based on spatial structure characteristics of 3D keypoints. We adopt point-wise dense feature embedding to vote for 3D keypoints, which makes full use of the structure information of the rigid body. After the direction vectors pointing to the keypoints are predicted by CNN, we use RANSAC voting to calculate the coordinate of the 3D keypoints, then the pose transformation can be easily obtained by the least square method. In addition, a spatial dimension sampling strategy for points is employed, which makes the method achieve excellent performance on small training sets. The proposed method is verified on two benchmark datasets, LINEMOD and OCCLUSION LINEMOD. The experimental results show that our method outperforms the state-of-the-art approaches, achieves ADD(-S) accuracy of 98.7\% on LINEMOD dataset and 52.6\% on OCCLUSION LINEMOD dataset in real-time.