 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A short note on the decision tree based neural turing machine
Oct 27, 2020
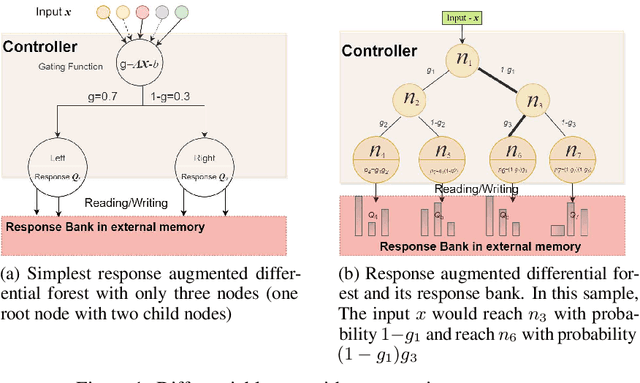
Turing machine and decision tree have developed independently for a long time. With the recent development of differentiable models, there is an intersection between them. Neural turing machine(NTM) opens door for the memory network. It use differentiable attention mechanism to read/write external memory bank. Differentiable forest brings differentiable properties to classical decision tree. In this short note, we show the deep connection between these two models. That is: differentiable forest is a special case of NTM. Differentiable forest is actually decision tree based neural turing machine. Based on this deep connection, we propose a response augmented differential forest (RaDF). The controller of RaDF is differentiable forest, the external memory of RaDF are response vectors which would be read/write by leaf nodes.
Knowledge Distillation Methods for Efficient Unsupervised Adaptation Across Multiple Domains
Jan 18, 2021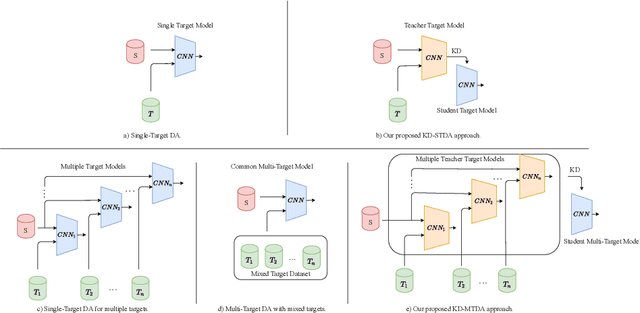
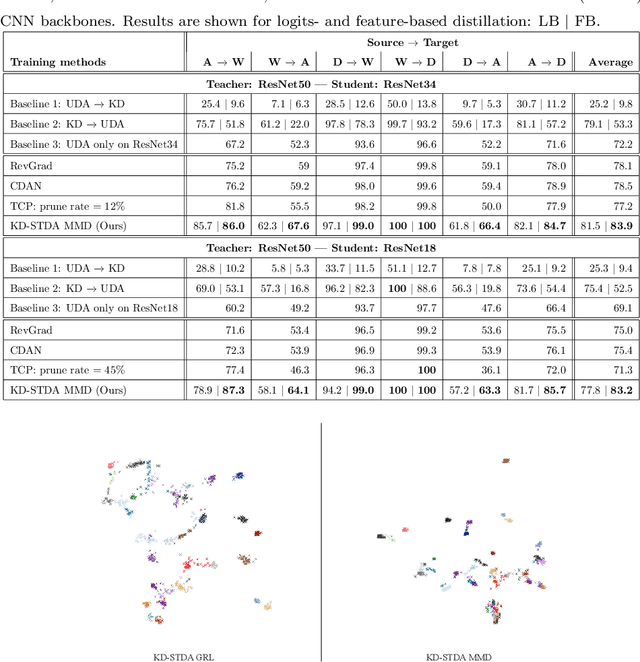
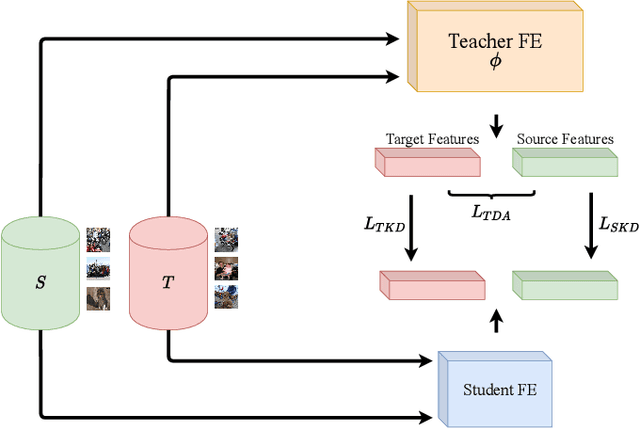
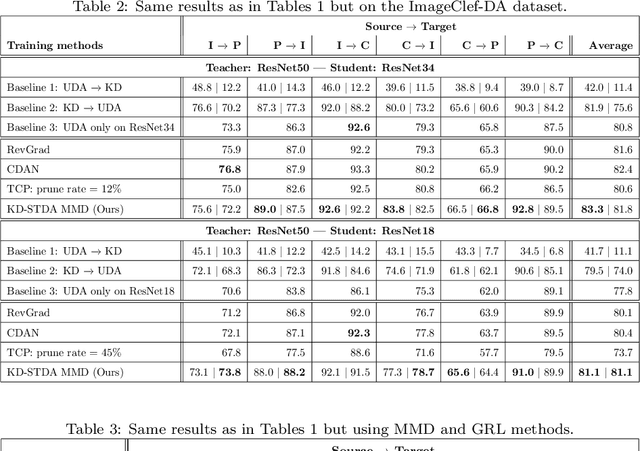
Beyond the complexity of CNNs that require training on large annotated datasets, the domain shift between design and operational data has limited the adoption of CNNs in many real-world applications. For instance, in person re-identification, videos are captured over a distributed set of cameras with non-overlapping viewpoints. The shift between the source (e.g. lab setting) and target (e.g. cameras) domains may lead to a significant decline in recognition accuracy. Additionally, state-of-the-art CNNs may not be suitable for such real-time applications given their computational requirements. Although several techniques have recently been proposed to address domain shift problems through unsupervised domain adaptation (UDA), or to accelerate/compress CNNs through knowledge distillation (KD), we seek to simultaneously adapt and compress CNNs to generalize well across multiple target domains. In this paper, we propose a progressive KD approach for unsupervised single-target DA (STDA) and multi-target DA (MTDA) of CNNs. Our method for KD-STDA adapts a CNN to a single target domain by distilling from a larger teacher CNN, trained on both target and source domain data in order to maintain its consistency with a common representation. Our proposed approach is compared against state-of-the-art methods for compression and STDA of CNNs on the Office31 and ImageClef-DA image classification datasets. It is also compared against state-of-the-art methods for MTDA on Digits, Office31, and OfficeHome. In both settings -- KD-STDA and KD-MTDA -- results indicate that our approach can achieve the highest level of accuracy across target domains, while requiring a comparable or lower CNN complexity.
A Robotic System for Implant Modification in Single-stage Cranioplasty
Jan 12, 2021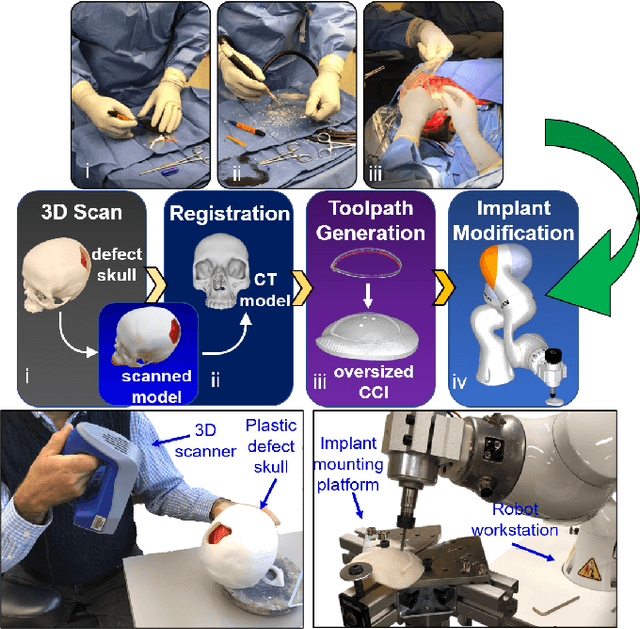
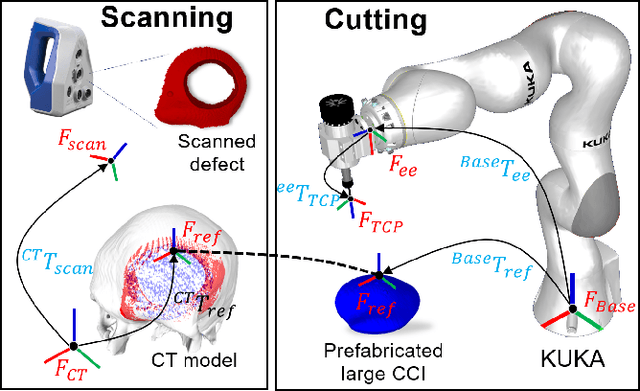
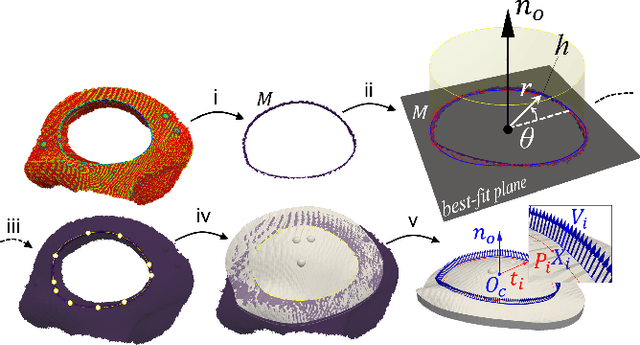
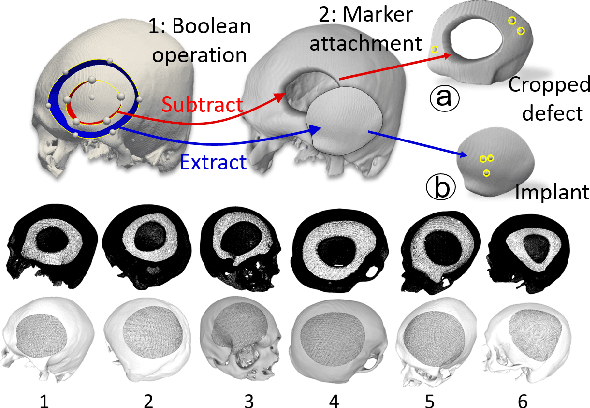
Craniomaxillofacial reconstruction with patient-specific customized craniofacial implants (CCIs) is most commonly performed for large-sized skeletal defects. Because the exact size of skull resection may not be known prior to the surgery, in the single-stage cranioplasty, a large CCI is prefabricated and resized intraoperatively with a manual-cutting process provided by a surgeon. The manual resizing, however, may be inaccurate and significantly add to the operating time. This paper introduces a fast and non-contact approach for intraoperatively determining the exact contour of the skull resection and automatically resizing the implant to fit the resection area. Our approach includes four steps: First, a patient's defect information is acquired by a 3D scanner. Second, the scanned defect is aligned to the CCI by registering the scanned defect to the reconstructed CT model. Third, a cutting toolpath is generated from the contour of the scanned defect. Lastly, the large CCI is resized by a cutting robot to fit the resection area according to the given toolpath. To evaluate the resizing performance of our method, six different resection shapes were used in the cutting experiments. We compared the performance of our method to the performances of surgeon's manual resizing and an existing technique which collects the defect contour with an optical tracking system and projects the contour on the CCI to guide the manual modification. The results show that our proposed method improves the resizing accuracy by 56% compared to the surgeon's manual modification and 42% compared to the projection method.
Task-Aware Neural Architecture Search
Oct 27, 2020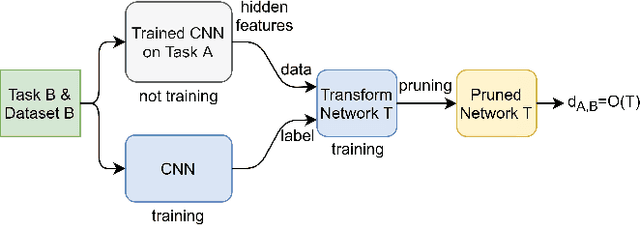
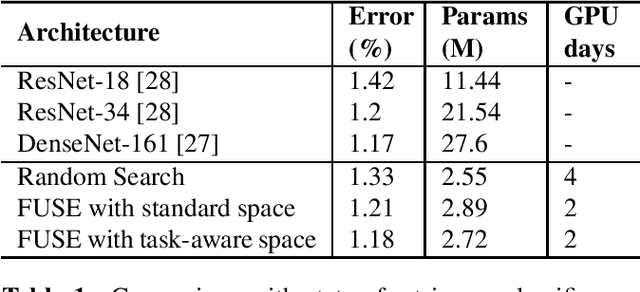
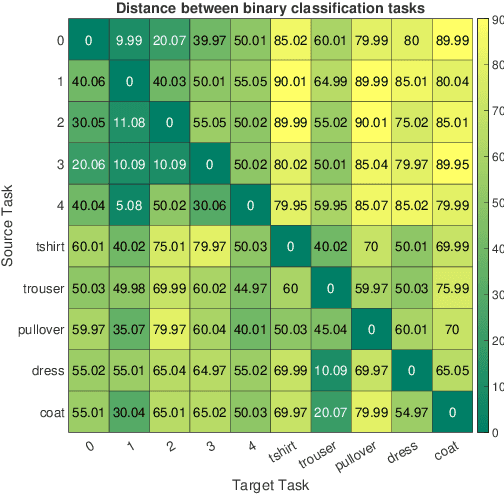
The design of handcrafted neural networks requires a lot of time and resources. Recent techniques in Neural Architecture Search (NAS) have proven to be competitive or better than traditional handcrafted design, although they require domain knowledge and have generally used limited search spaces. In this paper, we propose a novel framework for neural architecture search, utilizing a dictionary of models of base tasks and the similarity between the target task and the atoms of the dictionary; hence, generating an adaptive search space based on the base models of the dictionary. By introducing a gradient-based search algorithm, we can evaluate and discover the best architecture in the search space without fully training the networks. The experimental results show the efficacy of our proposed task-aware approach.
Robust & Asymptotically Locally Optimal UAV-Trajectory Generation Based on Spline Subdivision
Oct 19, 2020


Generating locally optimal UAV-trajectories is challenging due to the non-convex constraints of collision avoidance and actuation limits. We present the first local, optimization-based UAV-trajectory generator that simultaneously guarantees validity and asymptotic optimality. \textit{Validity:} Given a feasible initial guess, our algorithm guarantees the satisfaction of all constraints throughout the process of optimization. \textit{Asymptotic Optimality:} We use a conservative piecewise approximation of the trajectory with automatically adjustable resolution of its discretization. The trajectory converges under refinement to the first-order stationary point of the exact non-convex programming problem. Our method has additional practical advantages including joint optimality in terms of trajectory and time-allocation, and robustness to challenging environments as demonstrated in our experiments.
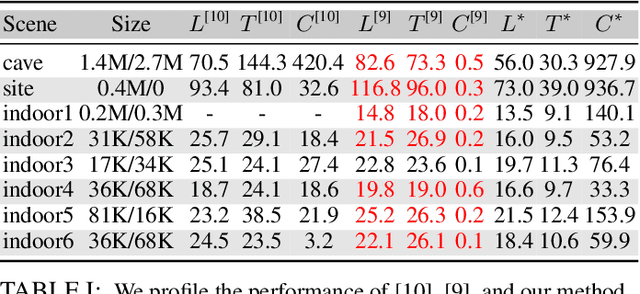
3D-ANAS: 3D Asymmetric Neural Architecture Search for Fast Hyperspectral Image Classification
Jan 12, 2021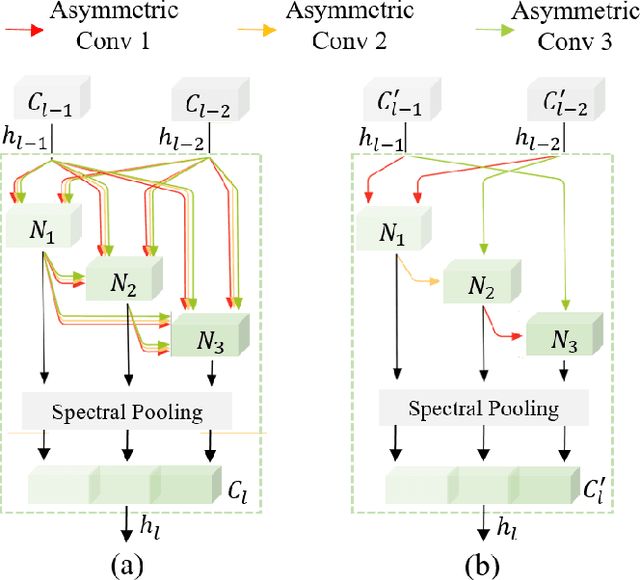
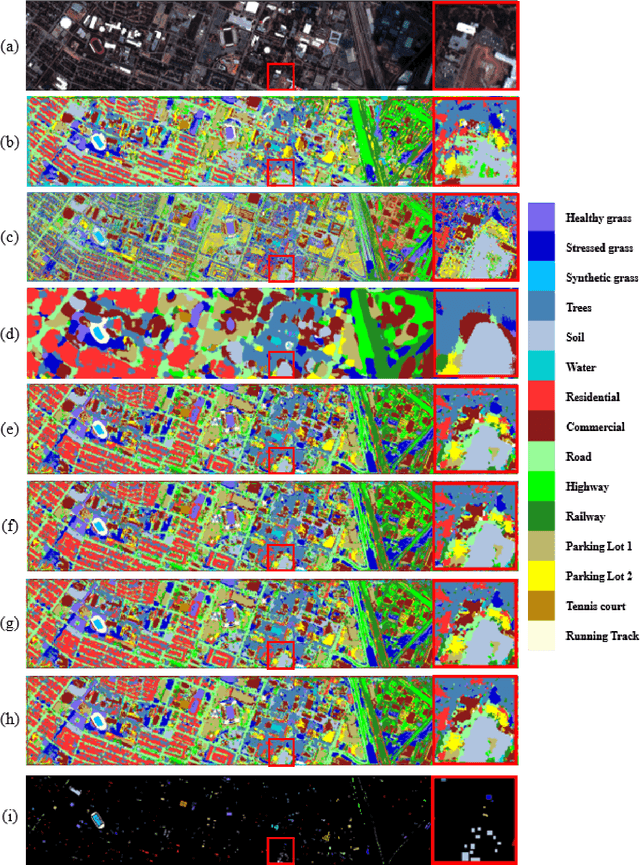
Hyperspectral images involve abundant spectral and spatial information, playing an irreplaceable role in land-cover classification. Recently, based on deep learning technologies, an increasing number of HSI classification approaches have been proposed, which demonstrate promising performance. However, previous studies suffer from two major drawbacks: 1) the architecture of most deep learning models is manually designed, relies on specialized knowledge, and is relatively tedious. Moreover, in HSI classifications, datasets captured by different sensors have different physical properties. Correspondingly, different models need to be designed for different datasets, which further increases the workload of designing architectures; 2) the mainstream framework is a patch-to-pixel framework. The overlap regions of patches of adjacent pixels are calculated repeatedly, which increases computational cost and time cost. Besides, the classification accuracy is sensitive to the patch size, which is artificially set based on extensive investigation experiments. To overcome the issues mentioned above, we firstly propose a 3D asymmetric neural network search algorithm and leverage it to automatically search for efficient architectures for HSI classifications. By analysing the characteristics of HSIs, we specifically build a 3D asymmetric decomposition search space, where spectral and spatial information are processed with different decomposition convolutions. Furthermore, we propose a new fast classification framework, i,e., pixel-to-pixel classification framework, which has no repetitive operations and reduces the overall cost. Experiments on three public HSI datasets captured by different sensors demonstrate the networks designed by our 3D-ANAS achieve competitive performance compared to several state-of-the-art methods, while having a much faster inference speed.
Times series averaging from a probabilistic interpretation of time-elastic kernel
Jun 09, 2015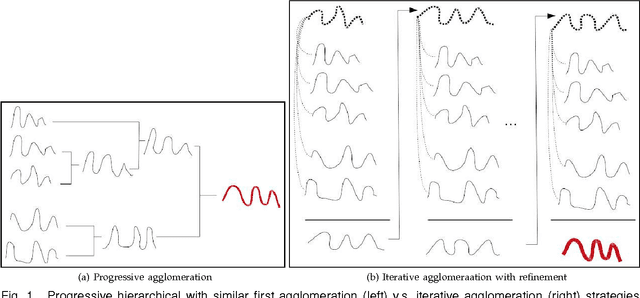
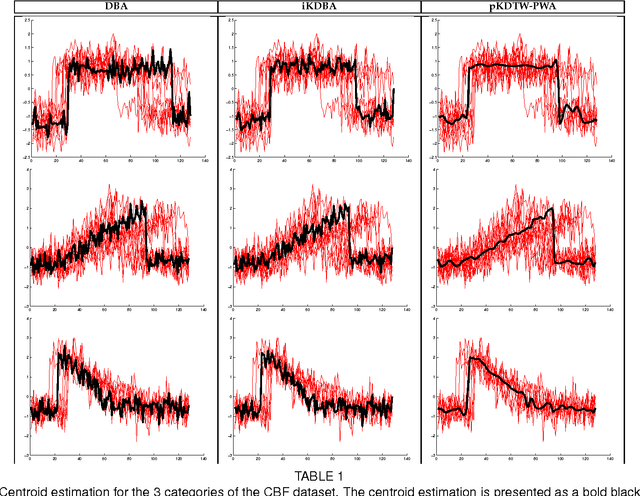
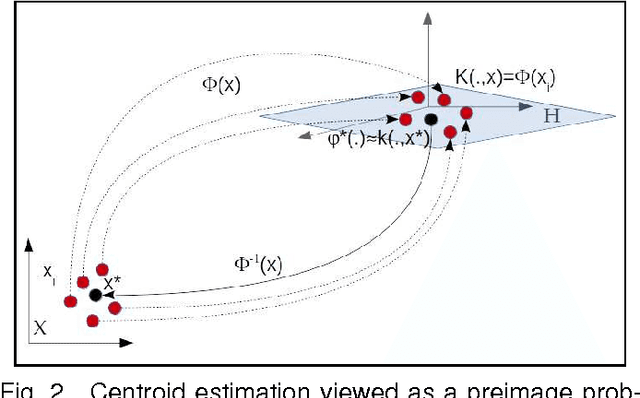
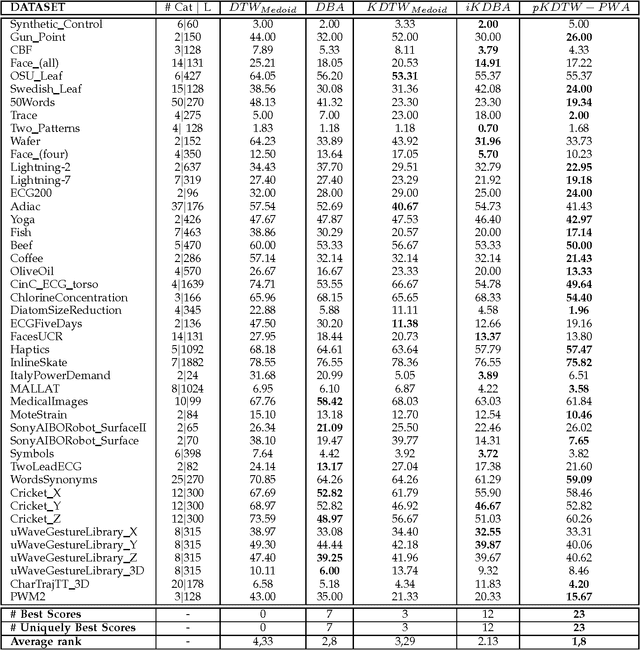
At the light of regularized dynamic time warping kernels, this paper reconsider the concept of time elastic centroid (TEC) for a set of time series. From this perspective, we show first how TEC can easily be addressed as a preimage problem. Unfortunately this preimage problem is ill-posed, may suffer from over-fitting especially for long time series and getting a sub-optimal solution involves heavy computational costs. We then derive two new algorithms based on a probabilistic interpretation of kernel alignment matrices that expresses in terms of probabilistic distributions over sets of alignment paths. The first algorithm is an iterative agglomerative heuristics inspired from the state of the art DTW barycenter averaging (DBA) algorithm proposed specifically for the Dynamic Time Warping measure. The second proposed algorithm achieves a classical averaging of the aligned samples but also implements an averaging of the time of occurrences of the aligned samples. It exploits a straightforward progressive agglomerative heuristics. An experimentation that compares for 45 time series datasets classification error rates obtained by first near neighbors classifiers exploiting a single medoid or centroid estimate to represent each categories show that: i) centroids based approaches significantly outperform medoids based approaches, ii) on the considered experience, the two proposed algorithms outperform the state of the art DBA algorithm, and iii) the second proposed algorithm that implements an averaging jointly in the sample space and along the time axes emerges as the most significantly robust time elastic averaging heuristic with an interesting noise reduction capability. Index Terms-Time series averaging Time elastic kernel Dynamic Time Warping Time series clustering and classification.
Double machine learning for (weighted) dynamic treatment effects
Dec 01, 2020

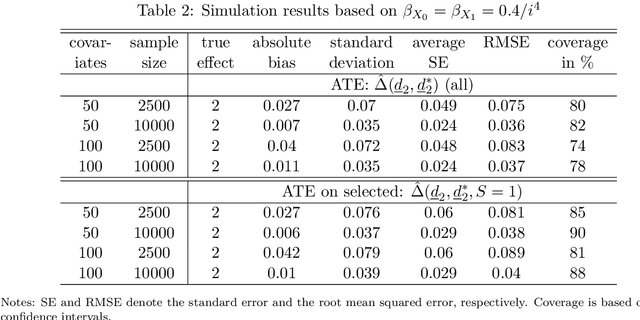

We consider evaluating the causal effects of dynamic treatments, i.e. of multiple treatment sequences in various periods, based on double machine learning to control for observed, time-varying covariates in a data-driven way under a selection-on-observables assumption. To this end, we make use of so-called Neyman-orthogonal score functions, which imply the robustness of treatment effect estimation to moderate (local) misspecifications of the dynamic outcome and treatment models. This robustness property permits approximating outcome and treatment models by double machine learning even under high dimensional covariates and is combined with data splitting to prevent overfitting. In addition to effect estimation for the total population, we consider weighted estimation that permits assessing dynamic treatment effects in specific subgroups, e.g. among those treated in the first treatment period. We demonstrate that the estimators are asymptotically normal and $\sqrt{n}$-consistent under specific regularity conditions and investigate their finite sample properties in a simulation study. Finally, we apply the methods to the Job Corps study in order to assess different sequences of training programs under a large set of covariates.
Quantum Mathematics in Artificial Intelligence
Jan 12, 2021
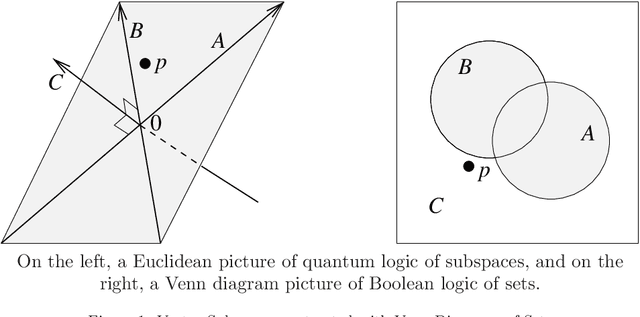
In the decade since 2010, successes in artificial intelligence have been at the forefront of computer science and technology, and vector space models have solidified a position at the forefront of artificial intelligence. At the same time, quantum computers have become much more powerful, and announcements of major advances are frequently in the news. The mathematical techniques underlying both these areas have more in common than is sometimes realized. Vector spaces took a position at the axiomatic heart of quantum mechanics in the 1930s, and this adoption was a key motivation for the derivation of logic and probability from the linear geometry of vector spaces. Quantum interactions between particles are modelled using the tensor product, which is also used to express objects and operations in artificial neural networks. This paper describes some of these common mathematical areas, including examples of how they are used in artificial intelligence (AI), particularly in automated reasoning and natural language processing (NLP). Techniques discussed include vector spaces, scalar products, subspaces and implication, orthogonal projection and negation, dual vectors, density matrices, positive operators, and tensor products. Application areas include information retrieval, categorization and implication, modelling word-senses and disambiguation, inference in knowledge bases, and semantic composition. Some of these approaches can potentially be implemented on quantum hardware. Many of the practical steps in this implementation are in early stages, and some are already realized. Explaining some of the common mathematical tools can help researchers in both AI and quantum computing further exploit these overlaps, recognizing and exploring new directions along the way.
The FaceChannelS: Strike of the Sequences for the AffWild 2 Challenge
Oct 04, 2020

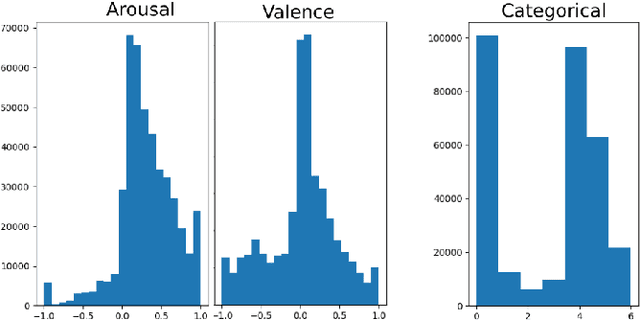
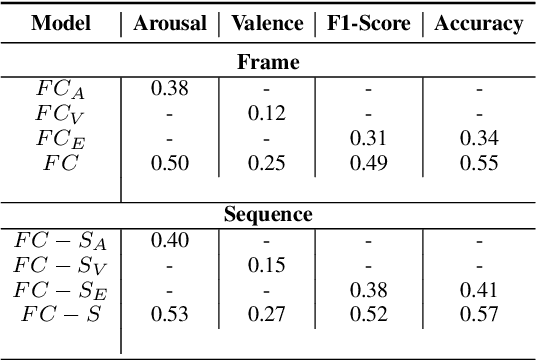
Predicting affective information from human faces became a popular task for most of the machine learning community in the past years. The development of immense and dense deep neural networks was backed by the availability of numerous labeled datasets. These models, most of the time, present state-of-the-art results in such benchmarks, but are very difficult to adapt to other scenarios. In this paper, we present one more chapter of benchmarking different versions of the FaceChannel neural network: we demonstrate how our little model can predict affective information from the facial expression on the novel AffWild2 dataset.