 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can We Automate Scientific Reviewing?
Jan 30, 2021
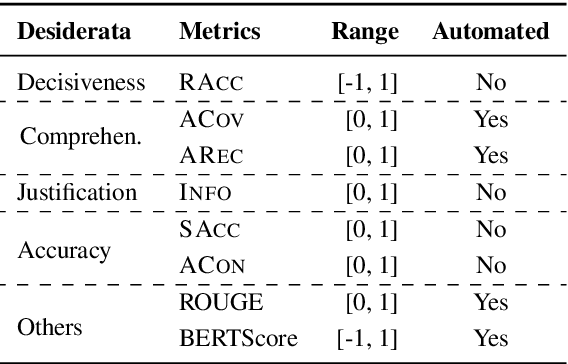
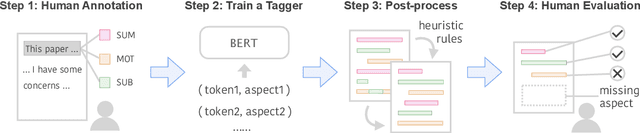
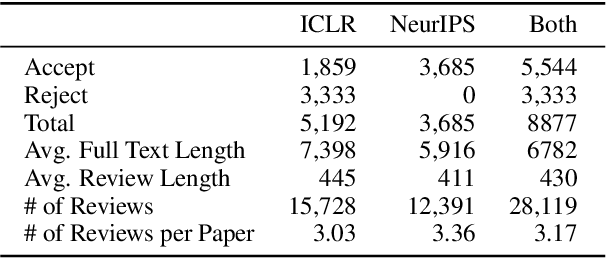
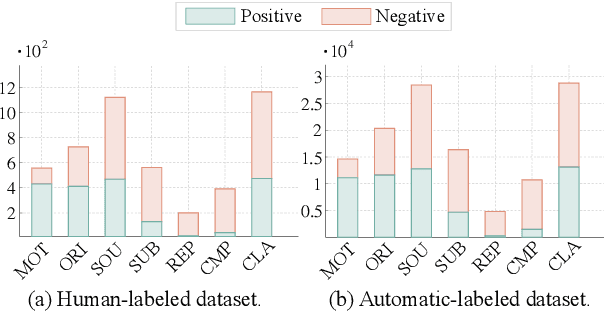
The rapid development of science and technology has been accompanied by an exponential growth in peer-reviewed scientific publications. At the same time, the review of each paper is a laborious process that must be carried out by subject matter experts. Thus, providing high-quality reviews of this growing number of papers is a significant challenge. In this work, we ask the question "can we automate scientific reviewing?", discussing the possibility of using state-of-the-art natural language processing (NLP) models to generate first-pass peer reviews for scientific papers. Arguably the most difficult part of this is defining what a "good" review is in the first place, so we first discuss possible evaluation measures for such reviews. We then collect a dataset of papers in the machine learning domain, annotate them with different aspects of content covered in each review, and train targeted summarization models that take in papers to generate reviews. Comprehensive experimental results show that system-generated reviews tend to touch upon more aspects of the paper than human-written reviews, but the generated text can suffer from lower constructiveness for all aspects except the explanation of the core ideas of the papers, which are largely factually correct. We finally summarize eight challenges in the pursuit of a good review generation system together with potential solutions, which, hopefully, will inspire more future research on this subject. We make all code, and the dataset publicly available: https://github.com/neulab/ReviewAdvisor, as well as a ReviewAdvisor system: http://review.nlpedia.ai/.
Community detection using fast low-cardinality semidefinite programming
Dec 04, 2020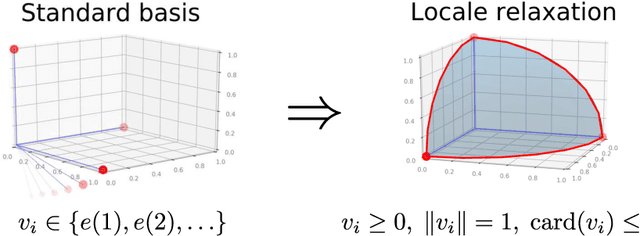
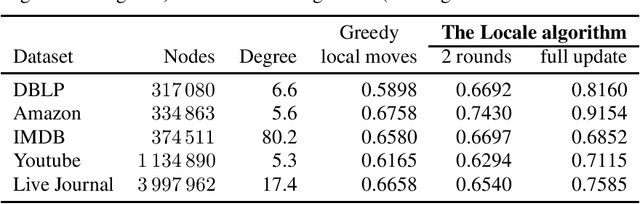

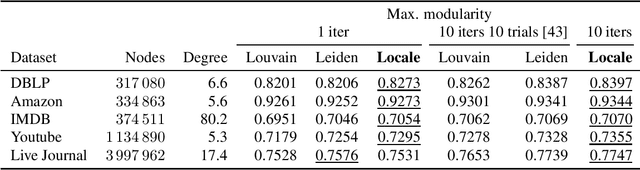
Modularity maximization has been a fundamental tool for understanding the community structure of a network, but the underlying optimization problem is nonconvex and NP-hard to solve. State-of-the-art algorithms like the Louvain or Leiden methods focus on different heuristics to help escape local optima, but they still depend on a greedy step that moves node assignment locally and is prone to getting trapped. In this paper, we propose a new class of low-cardinality algorithm that generalizes the local update to maximize a semidefinite relaxation derived from max-k-cut. This proposed algorithm is scalable, empirically achieves the global semidefinite optimality for small cases, and outperforms the state-of-the-art algorithms in real-world datasets with little additional time cost. From the algorithmic perspective, it also opens a new avenue for scaling-up semidefinite programming when the solutions are sparse instead of low-rank.
Incremental learning with online SVMs on LiDAR sensory data
Dec 30, 2020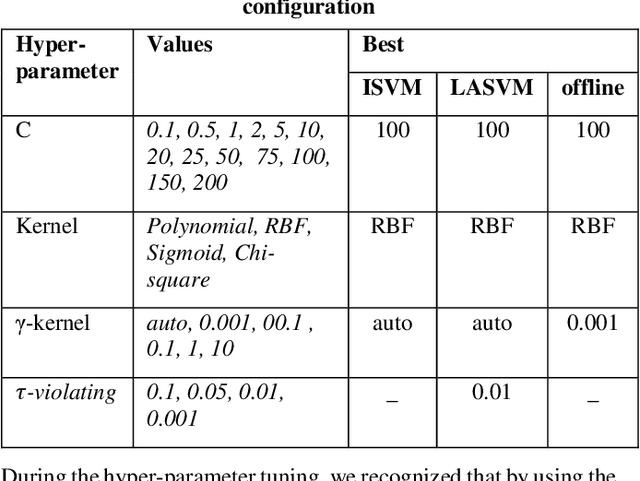
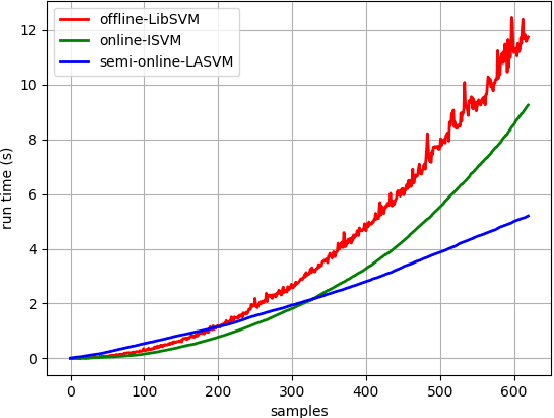
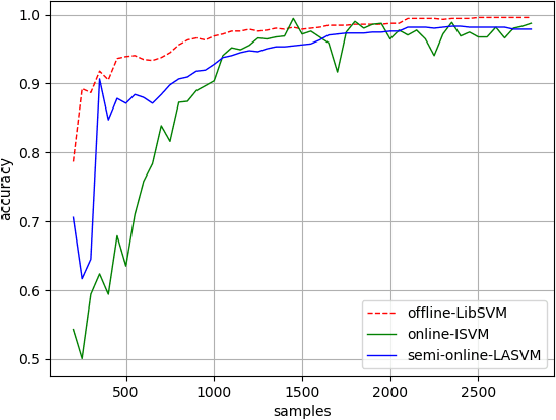
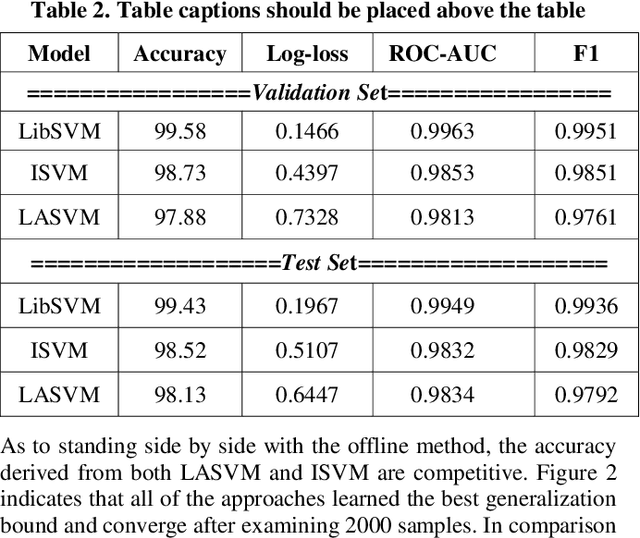
The pipelines transmission system is one of the growing aspects, which has existed for a long time in the energy industry. The cost of in-pipe exploration for maintaining service always draws lots of attention in this industry. Normally exploration methods (e.g. Magnetic flux leakage and eddy current) will establish the sensors stationary for each pipe milestone or carry sensors to travel inside the pipe. It makes the maintenance process very difficult due to the massive amount of sensors. One of the solutions is to implement machine learning techniques for the analysis of sensory data. Although SVMs can resolve this issue with kernel trick, the problem is that computing the kernel depends on the data size too. It is because the process can be exaggerated quickly if the number of support vectors becomes really large. Particularly LiDAR spins with an extremely rapid rate and the flow of input data might eventually lead to massive expansion. In our proposed approach, each sample is learned in an instant way and the supported kernel is computed simultaneously. In this research, incremental learning approach with online support vector machines (SVMs) is presented, which aims to deal with LiDAR sensory data only.
Tell Me Who Your Friends Are: Using Content Sharing Behavior for News Source Veracity Detection
Jan 15, 2021
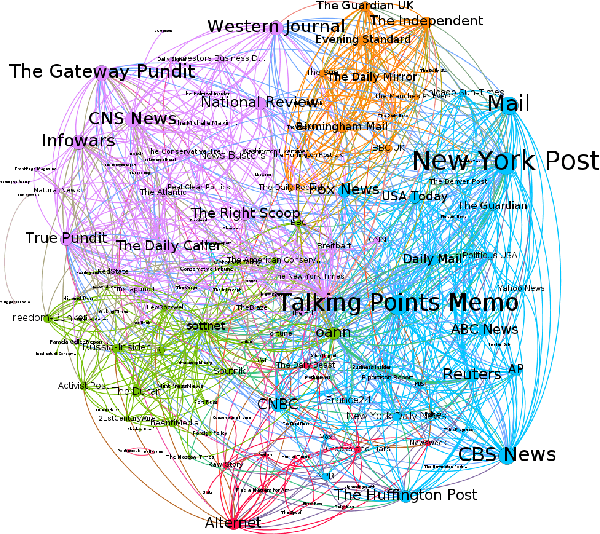
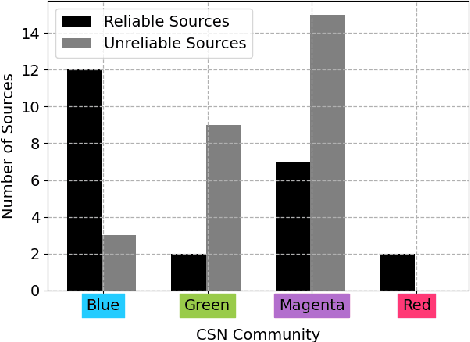
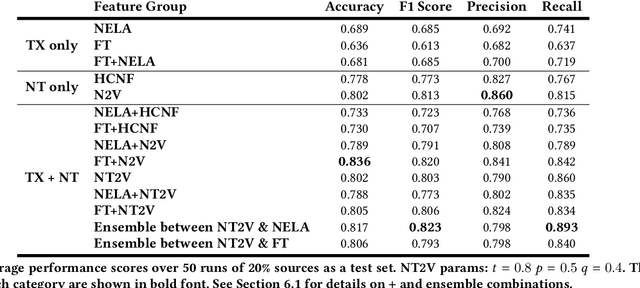
Stopping the malicious spread and production of false and misleading news has become a top priority for researchers. Due to this prevalence, many automated methods for detecting low quality information have been introduced. The majority of these methods have used article-level features, such as their writing style, to detect veracity. While writing style models have been shown to work well in lab-settings, there are concerns of generalizability and robustness. In this paper, we begin to address these concerns by proposing a novel and robust news veracity detection model that uses the content sharing behavior of news sources formulated as a network. We represent these content sharing networks (CSN) using a deep walk based method for embedding graphs that accounts for similarity in both the network space and the article text space. We show that state of the art writing style and CSN features make diverse mistakes when predicting, meaning that they both play different roles in the classification task. Moreover, we show that the addition of CSN features increases the accuracy of writing style models, boosting accuracy as much as 14\% when using Random Forests. Similarly, we show that the combination of hand-crafted article-level features and CSN features is robust to concept drift, performing consistently well over a 10-month time frame.
Probabilistic Tracklet Scoring and Inpainting for Multiple Object Tracking
Dec 10, 2020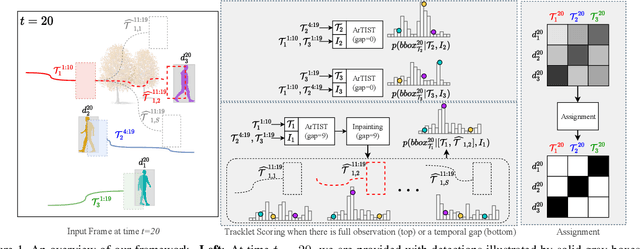
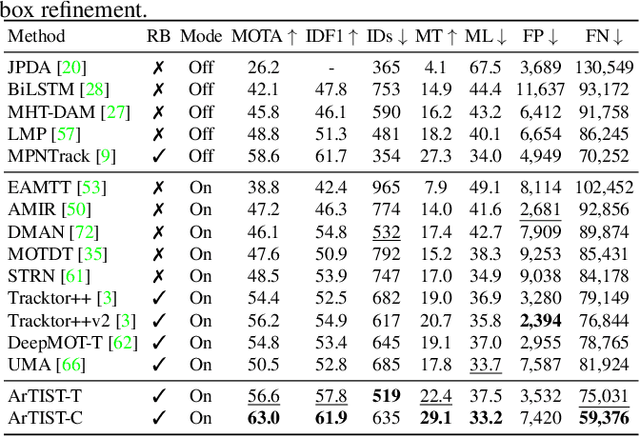
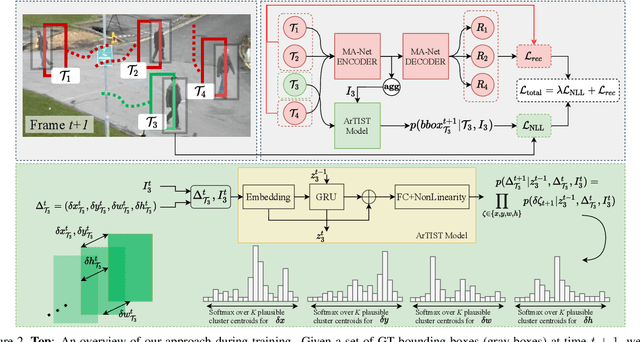
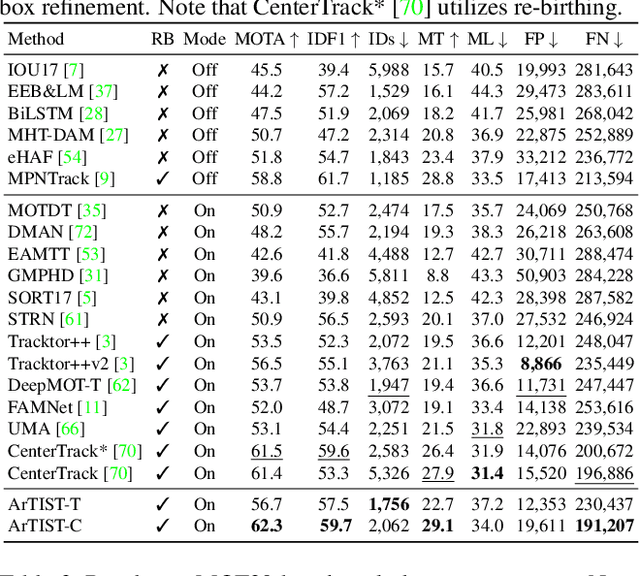
Despite the recent advances in multiple object tracking (MOT), achieved by joint detection and tracking, dealing with long occlusions remains a challenge. This is due to the fact that such techniques tend to ignore the long-term motion information. In this paper, we introduce a probabilistic autoregressive motion model to score tracklet proposals by directly measuring their likelihood. This is achieved by training our model to learn the underlying distribution of natural tracklets. As such, our model allows us not only to assign new detections to existing tracklets, but also to inpaint a tracklet when an object has been lost for a long time, e.g., due to occlusion, by sampling tracklets so as to fill the gap caused by misdetections. Our experiments demonstrate the superiority of our approach at tracking objects in challenging sequences; it outperforms the state of the art in most standard MOT metrics on multiple MOT benchmark datasets, including MOT16, MOT17, and MOT20.
Primal-dual Learning for the Model-free Risk-constrained Linear Quadratic Regulator
Dec 10, 2020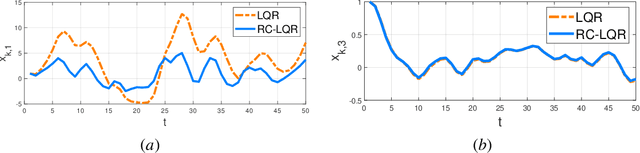
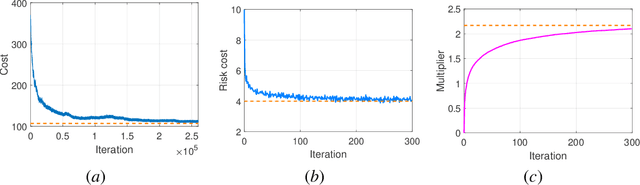
Risk-aware control, though with promise to tackle unexpected events, requires a known exact dynamical model. In this work, we propose a model-free framework to learn a risk-aware controller with a focus on the linear system. We formulate it as a discrete-time infinite-horizon LQR problem with a state predictive variance constraint. To solve it, we parameterize the policy with a feedback gain pair and leverage primal-dual methods to optimize it by solely using data. We first study the optimization landscape of the Lagrangian function and establish the strong duality in spite of its non-convex nature. Alongside, we find that the Lagrangian function enjoys an important local gradient dominance property, which is then exploited to develop a convergent random search algorithm to learn the dual function. Furthermore, we propose a primal-dual algorithm with global convergence to learn the optimal policy-multiplier pair. Finally, we validate our results via simulations.
Importance of Data Loading Pipeline in Training Deep Neural Networks
Apr 21, 2020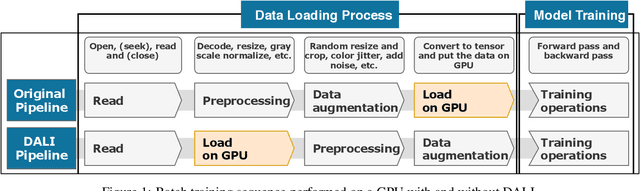
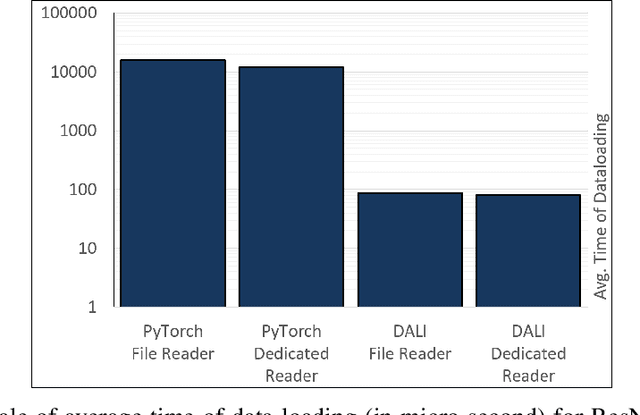
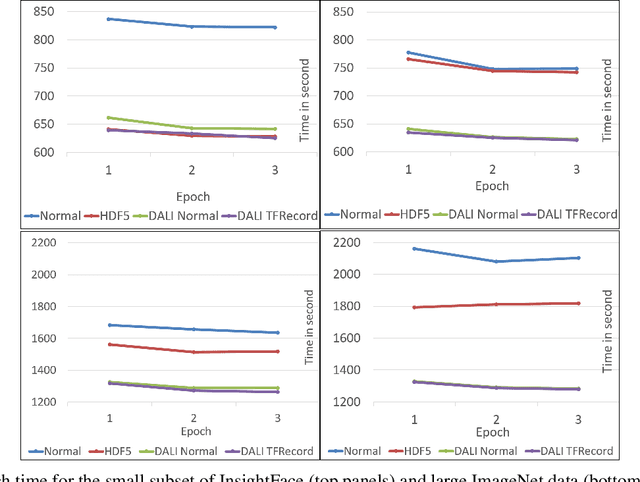
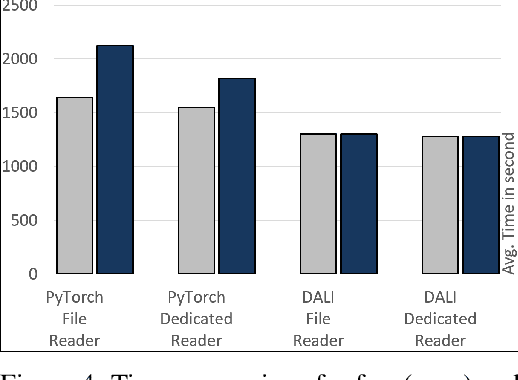
Training large-scale deep neural networks is a long, time-consuming operation, often requiring many GPUs to accelerate. In large models, the time spent loading data takes a significant portion of model training time. As GPU servers are typically expensive, tricks that can save training time are valuable.Slow training is observed especially on real-world applications where exhaustive data augmentation operations are required. Data augmentation techniques include: padding, rotation, adding noise, down sampling, up sampling, etc. These additional operations increase the need to build an efficient data loading pipeline, and to explore existing tools to speed up training time. We focus on the comparison of two main tools designed for this task, namely binary data format to accelerate data reading, and NVIDIA DALI to accelerate data augmentation. Our study shows improvement on the order of 20% to 40% if such dedicated tools are used.
Approaches to Fraud Detection on Credit Card Transactions Using Artificial Intelligence Methods
Jul 29, 2020
Credit card fraud is an ongoing problem for almost all industries in the world, and it raises millions of dollars to the global economy each year. Therefore, there is a number of research either completed or proceeding in order to detect these kinds of frauds in the industry. These researches generally use rule-based or novel artificial intelligence approaches to find eligible solutions. The ultimate goal of this paper is to summarize state-of-the-art approaches to fraud detection using artificial intelligence and machine learning techniques. While summarizing, we will categorize the common problems such as imbalanced dataset, real time working scenarios, and feature engineering challenges that almost all research works encounter, and identify general approaches to solve them. The imbalanced dataset problem occurs because the number of legitimate transactions is much higher than the fraudulent ones whereas applying the right feature engineering is substantial as the features obtained from the industries are limited, and applying feature engineering methods and reforming the dataset is crucial. Also, adapting the detection system to real time scenarios is a challenge since the number of credit card transactions in a limited time period is very high. In addition, we will discuss how evaluation metrics and machine learning methods differentiate among each research.
* 10 pages, 1 table, conference paper
Bridging Cost-sensitive and Neyman-Pearson Paradigms for Asymmetric Binary Classification
Dec 29, 2020
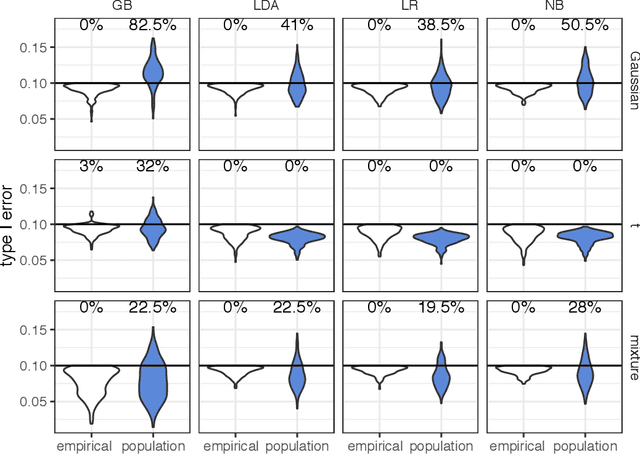
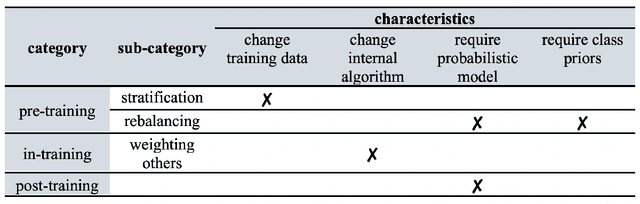
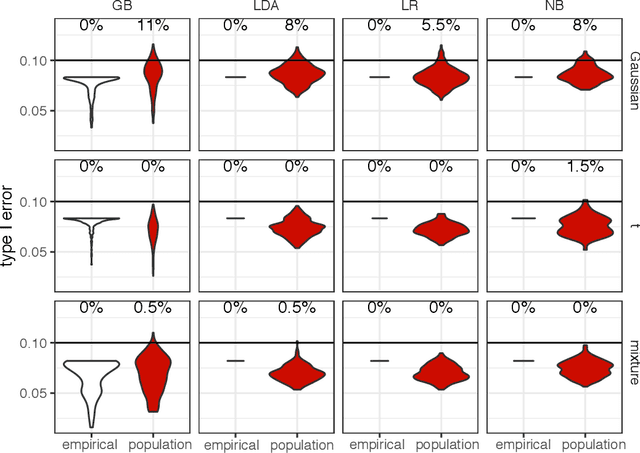
Asymmetric binary classification problems, in which the type I and II errors have unequal severity, are ubiquitous in real-world applications. To handle such asymmetry, researchers have developed the cost-sensitive and Neyman-Pearson paradigms for training classifiers to control the more severe type of classification error, say the type I error. The cost-sensitive paradigm is widely used and has straightforward implementations that do not require sample splitting; however, it demands an explicit specification of the costs of the type I and II errors, and an open question is what specification can guarantee a high-probability control on the population type I error. In contrast, the Neyman-Pearson paradigm can train classifiers to achieve a high-probability control of the population type I error, but it relies on sample splitting that reduces the effective training sample size. Since the two paradigms have complementary strengths, it is reasonable to combine their strengths for classifier construction. In this work, we for the first time study the methodological connections between the two paradigms, and we develop the TUBE-CS algorithm to bridge the two paradigms from the perspective of controlling the population type I error.
Proximal Policy Optimization Smoothed Algorithm
Dec 04, 2020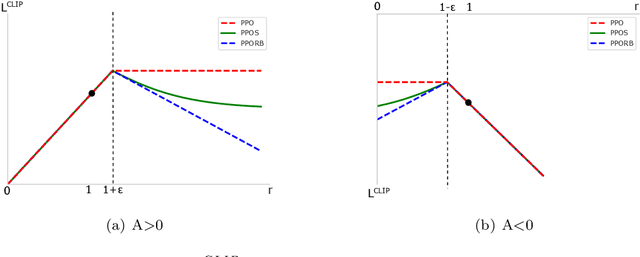


Proximal policy optimization (PPO) has yielded state-of-the-art results in policy search, a subfield of reinforcement learning, with one of its key points being the use of a surrogate objective function to restrict the step size at each policy update. Although such restriction is helpful, the algorithm still suffers from performance instability and optimization inefficiency from the sudden flattening of the curve. To address this issue we present a PPO variant, named Proximal Policy Optimization Smooth Algorithm (PPOS), and its critical improvement is the use of a functional clipping method instead of a flat clipping method. We compare our method with PPO and PPORB, which adopts a rollback clipping method, and prove that our method can conduct more accurate updates at each time step than other PPO methods. Moreover, we show that it outperforms the latest PPO variants on both performance and stability in challenging continuous control tasks.