 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Automate Scientific Reviewing?
Paper and Code
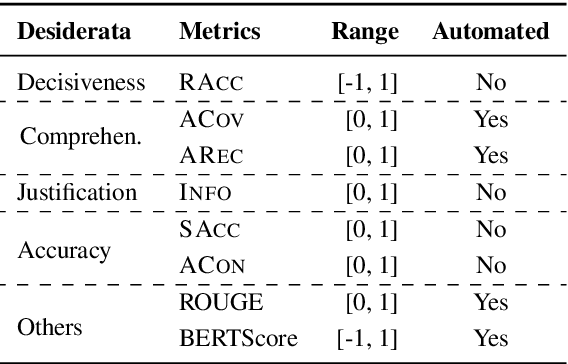
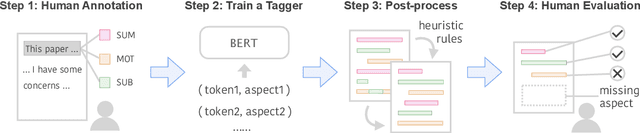
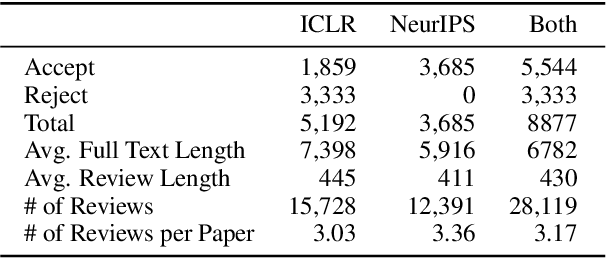
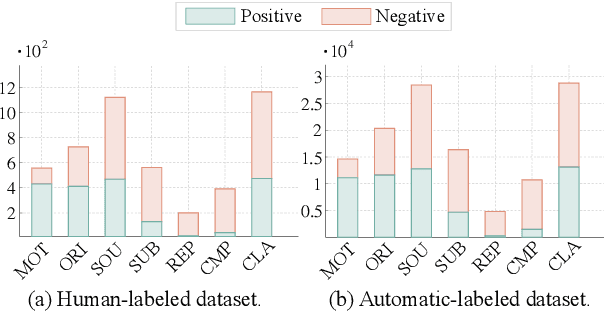
The rapid development of science and technology has been accompanied by an exponential growth in peer-reviewed scientific publications. At the same time, the review of each paper is a laborious process that must be carried out by subject matter experts. Thus, providing high-quality reviews of this growing number of papers is a significant challenge. In this work, we ask the question "can we automate scientific reviewing?", discussing the possibility of using state-of-the-art natural language processing (NLP) models to generate first-pass peer reviews for scientific papers. Arguably the most difficult part of this is defining what a "good" review is in the first place, so we first discuss possible evaluation measures for such reviews. We then collect a dataset of papers in the machine learning domain, annotate them with different aspects of content covered in each review, and train targeted summarization models that take in papers to generate reviews. Comprehensive experimental results show that system-generated reviews tend to touch upon more aspects of the paper than human-written reviews, but the generated text can suffer from lower constructiveness for all aspects except the explanation of the core ideas of the papers, which are largely factually correct. We finally summarize eight challenges in the pursuit of a good review generation system together with potential solutions, which, hopefully, will inspire more future research on this subject. We make all code, and the dataset publicly available: https://github.com/neulab/ReviewAdvisor, as well as a ReviewAdvisor system: http://review.nlpedia.ai/.