 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAST3D: Animal behavioral analysis and neural encoding from multi-view video via Gaussian splatting
Jun 01, 2026Multi-view video recordings are increasingly used to capture the 3D movements of animals in experimental settings, yet extracting rich 3D representations from these recordings remains challenging. Supervised pose estimation requires extensive manual annotation, while general-purpose 3D reconstruction models trained on generic scene datasets fail on the specialized imagery and sparse-view setting of laboratory experiments. We address these limitations with BEAST3D, a self-supervised pretraining framework that learns 3D visual representations from unlabeled, calibrated multi-view video. BEAST3D uses a vision transformer to predict 3D Gaussian splats that reconstruct held-out views through differentiable rendering, while simultaneously segmenting the animal from the background. BEAST3D reconstructs 3D structure with as few as four views by conditioning directly on known camera parameters--unlike general-purpose models, which must estimate camera geometry from dense overlapping viewpoints that are seldom available in lab settings. Through comprehensive evaluation across four species, we demonstrate that BEAST3D produces rich, viewpoint-invariant features that transfer effectively to three downstream tasks: novel view synthesis, which validates the quality of the learned 3D representations; multi-view pose estimation, which provides the sparse keypoint trajectories widely used in behavioral analysis; and neural encoding, which relates 3D behavioral features to simultaneously recorded neural activity. BEAST3D thus establishes a versatile framework for behavioral analysis that leverages 3D structure in modern multi-view laboratory recordings.
Proximal Policy Optimization Smoothed Algorithm
Dec 04, 2020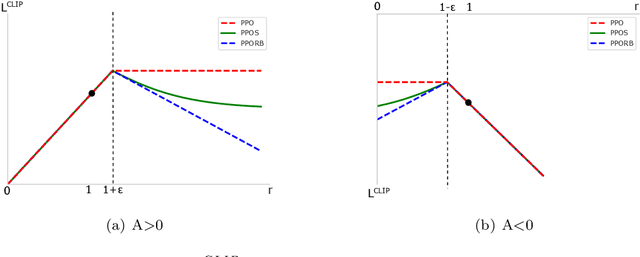


Proximal policy optimization (PPO) has yielded state-of-the-art results in policy search, a subfield of reinforcement learning, with one of its key points being the use of a surrogate objective function to restrict the step size at each policy update. Although such restriction is helpful, the algorithm still suffers from performance instability and optimization inefficiency from the sudden flattening of the curve. To address this issue we present a PPO variant, named Proximal Policy Optimization Smooth Algorithm (PPOS), and its critical improvement is the use of a functional clipping method instead of a flat clipping method. We compare our method with PPO and PPORB, which adopts a rollback clipping method, and prove that our method can conduct more accurate updates at each time step than other PPO methods. Moreover, we show that it outperforms the latest PPO variants on both performance and stability in challenging continuous control tasks.