 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating Agents without Rewards
Dec 21, 2020
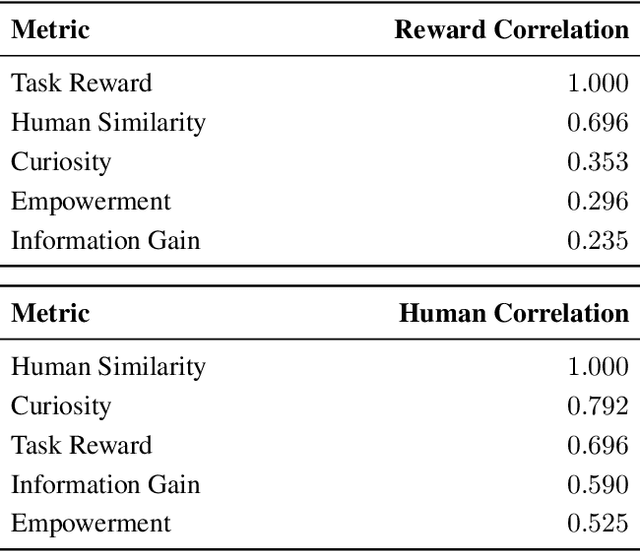
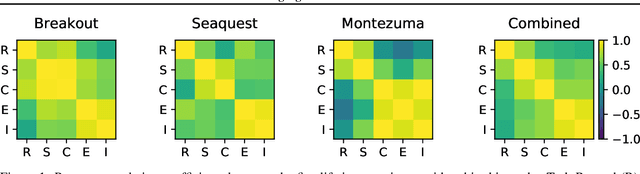
Reinforcement learning has enabled agents to solve challenging tasks in unknown environments. However, manually crafting reward functions can be time consuming, expensive, and error prone to human error. Competing objectives have been proposed for agents to learn without external supervision, but it has been unclear how well they reflect task rewards or human behavior. To accelerate the development of intrinsic objectives, we retrospectively compute potential objectives on pre-collected datasets of agent behavior, rather than optimizing them online, and compare them by analyzing their correlations. We study input entropy, information gain, and empowerment across seven agents, three Atari games, and the 3D game Minecraft. We find that all three intrinsic objectives correlate more strongly with a human behavior similarity metric than with task reward. Moreover, input entropy and information gain correlate more strongly with human similarity than task reward does, suggesting the use of intrinsic objectives for designing agents that behave similarly to human players.
Property Inference From Poisoning
Jan 26, 2021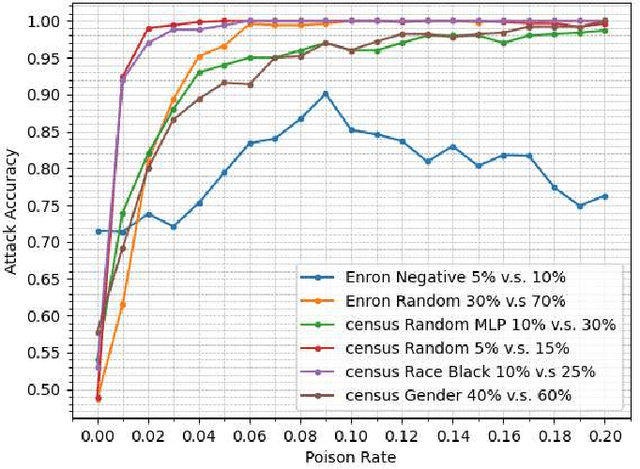
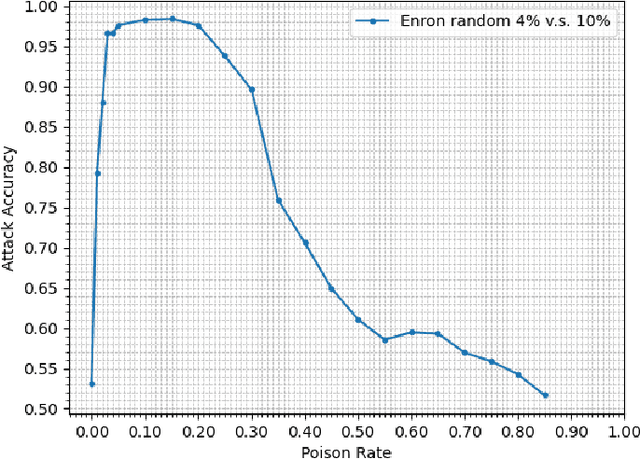
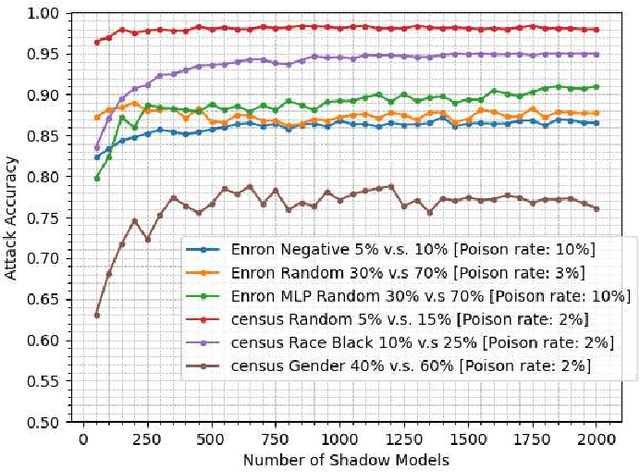
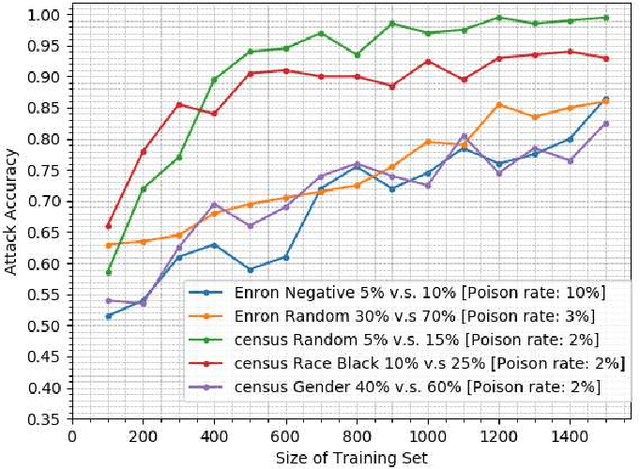
Property inference attacks consider an adversary who has access to the trained model and tries to extract some global statistics of the training data. In this work, we study property inference in scenarios where the adversary can maliciously control part of the training data (poisoning data) with the goal of increasing the leakage. Previous work on poisoning attacks focused on trying to decrease the accuracy of models either on the whole population or on specific sub-populations or instances. Here, for the first time, we study poisoning attacks where the goal of the adversary is to increase the information leakage of the model. Our findings suggest that poisoning attacks can boost the information leakage significantly and should be considered as a stronger threat model in sensitive applications where some of the data sources may be malicious. We describe our \emph{property inference poisoning attack} that allows the adversary to learn the prevalence in the training data of any property it chooses. We theoretically prove that our attack can always succeed as long as the learning algorithm used has good generalization properties. We then verify the effectiveness of our attack by experimentally evaluating it on two datasets: a Census dataset and the Enron email dataset. We were able to achieve above $90\%$ attack accuracy with $9-10\%$ poisoning in all of our experiments.
Deep Latent Variable Model for Longitudinal Group Factor Analysis
May 11, 2020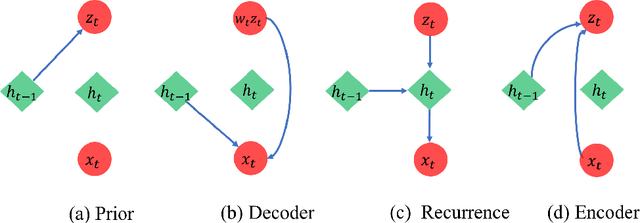
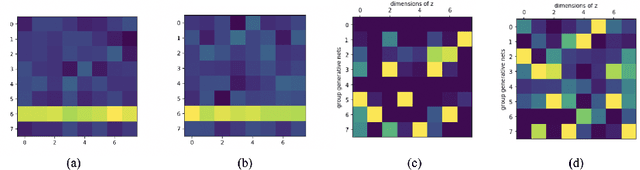

In many scientific problems such as video surveillance, modern genomic analysis, and clinical studies, data are often collected from diverse domains across time that exhibit time-dependent heterogeneous properties. It is important to not only integrate data from multiple sources (called multiview data), but also to incorporate time dependency for deep understanding of the underlying system. Latent factor models are popular tools for exploring multi-view data. However, it is frequently observed that these models do not perform well for complex systems and they are not applicable to time-series data. Therefore, we propose a generative model based on variational autoencoder and recurrent neural network to infer the latent dynamic factors for multivariate timeseries data. This approach allows us to identify the disentangled latent embeddings across multiple modalities while accounting for the time factor. We invoke our proposed model for analyzing three datasets on which we demonstrate the effectiveness and the interpretability of the model.
Sum-Rate Maximization for UAV-assisted Visible Light Communications using NOMA: Swarm Intelligence meets Machine Learning
Jan 10, 2021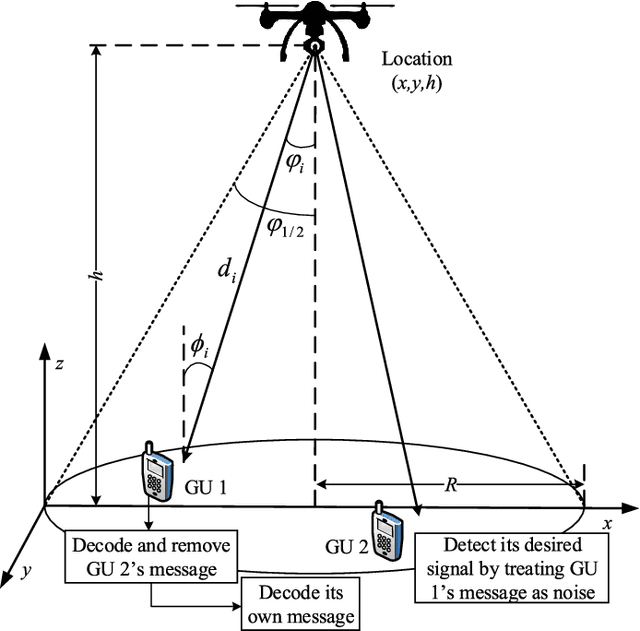
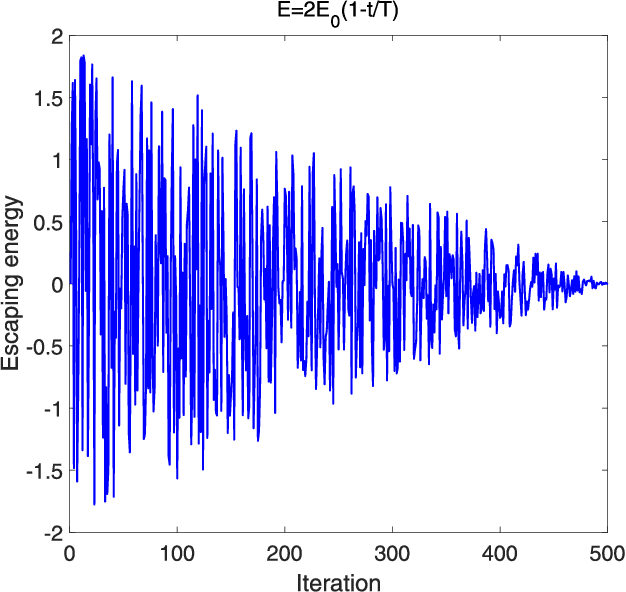
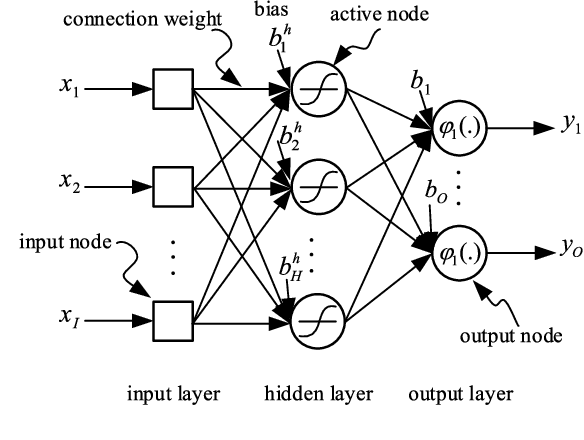

As the integration of unmanned aerial vehicles (UAVs) into visible light communications (VLC) can offer many benefits for massive-connectivity applications and services in 5G and beyond, this work considers a UAV-assisted VLC using non-orthogonal multiple-access. More specifically, we formulate a joint problem of power allocation and UAV's placement to maximize the sum rate of all users, subject to constraints on power allocation, quality of service of users, and UAV's position. Since the problem is non-convex and NP-hard in general, it is difficult to be solved optimally. Moreover, the problem is not easy to be solved by conventional approaches, e.g., coordinate descent algorithms, due to channel modeling in VLC. Therefore, we propose using harris hawks optimization (HHO) algorithm to solve the formulated problem and obtain an efficient solution. We then use the HHO algorithm together with artificial neural networks to propose a design which can be used in real-time applications and avoid falling into the "local minima" trap in conventional trainers. Numerical results are provided to verify the effectiveness of the proposed algorithm and further demonstrate that the proposed algorithm/HHO trainer is superior to several alternative schemes and existing metaheuristic algorithms.
A Direct-Indirect Hybridization Approach to Control-Limited DDP
Oct 01, 2020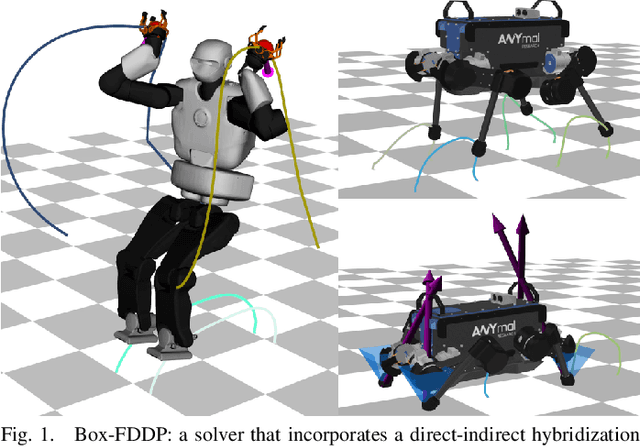

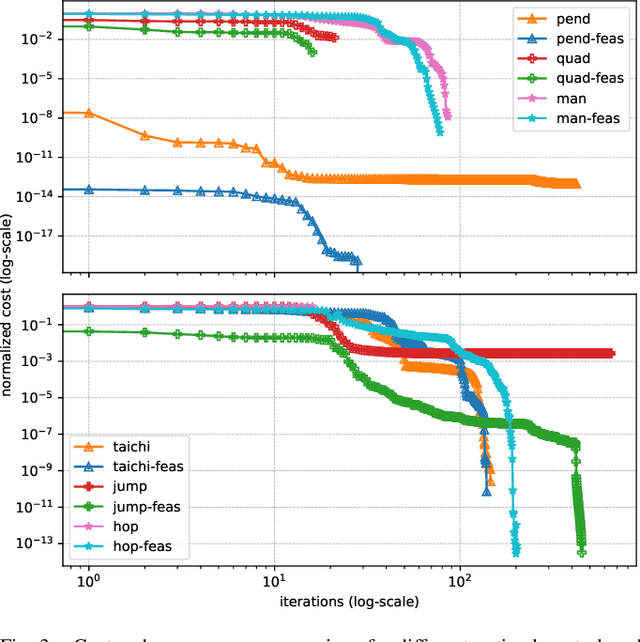
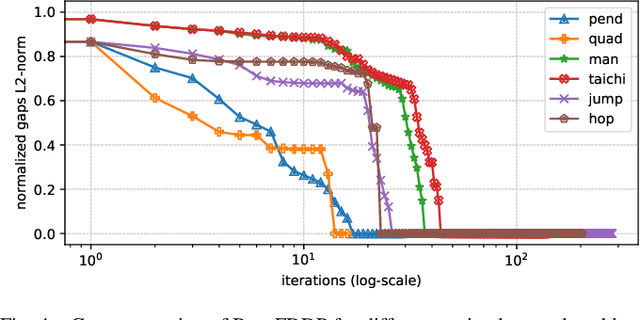
Optimal control is a widely used tool for synthesizing motions and controls for user-defined tasks under physical constraints. A common approach is to formulate it using direct multiple-shooting and then to use off-the-shelf nonlinear programming solvers that can easily handle arbitrary constraints on the controls and states. However, these methods are not fast enough for many robotics applications such as real-time humanoid motor control. Exploiting the sparse structure of optimal control problem, such as in Differential DynamicProgramming (DDP), has proven to significantly boost the computational efficiency, and recent works have been focused on handling arbitrary constraints. Despite that, DDP has been associated with poor numerical convergence, particularly when considering long time horizons. One of the main reasons is due to system instabilities and poor warm-starting (only controls). This paper presents control-limited Feasibility-driven DDP (Box-FDDP), a solver that incorporates a direct-indirect hybridization of the control-limited DDP algorithm. Concretely, the forward and backward passes handle feasibility and control limits. We showcase the impact and importance of our method on a set of challenging optimal control problems against the Box-DDP and squashing-function approach.
Cross-Correlation Based Discriminant Criterion for Channel Selection in Motor Imagery BCI Systems
Dec 10, 2020Many electroencephalogram (EEG)-based brain-computer interface (BCI) systems use a large amount of channels for higher performance, which is time-consuming to set up and inconvenient for practical applications. Finding an optimal subset of channels without compromising the performance is a necessary and challenging task. In this article, we proposed a cross-correlation based discriminant criterion (XCDC) which assesses the importance of a channel for discriminating the mental states of different motor imagery (MI) tasks. The performance of XCDC is evaluated on two motor imagery EEG datasets. In both datasets, XCDC significantly reduces the amount of channels without compromising classification accuracy compared to the all-channel setups. Under the same constraint of accuracy, the proposed method requires fewer channels than existing channel selection methods based on Pearson's correlation coefficient and common spatial pattern. Visualization of XCDC shows consistent results with neurophysiological principles.
FastPET: Near Real-Time PET Reconstruction from Histo-Images Using a Neural Network
Feb 11, 2020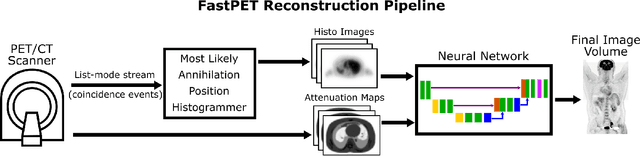
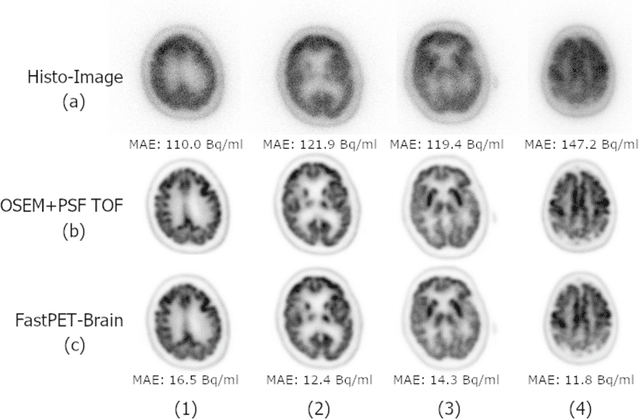

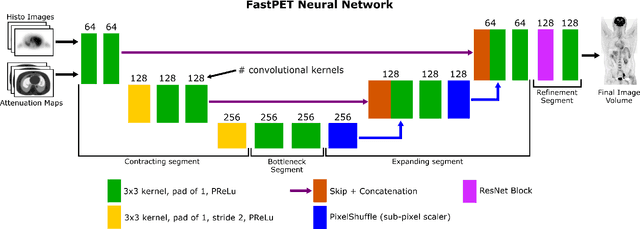
Direct reconstruction of positron emission tomography (PET) data using deep neural networks is a growing field of research. Initial results are promising, but often the networks are complex, memory utilization inefficient, produce relatively small image sizes (e.g. 128x128), and low count rate reconstructions are of varying quality. This paper proposes FastPET, a novel direct reconstruction convolutional neural network that is architecturally simple, memory space efficient, produces larger images (e.g. 440x440) and is capable of processing a wide range of count densities. FastPET operates on noisy and blurred histo-images reconstructing clinical-quality multi-slice image volumes 800x faster than ordered subsets expectation maximization (OSEM). Patient data studies show a higher contrast recovery value than for OSEM with equivalent variance and a higher overall signal-to-noise ratio with both cases due to FastPET's lower noise images. This work also explored the application to low dose PET imaging and found FastPET able to produce images comparable to normal dose with only 50% and 25% counts. We additionally explored the effect of reducing the anatomical region by training specific FastPET variants on brain and chest images and found narrowing the data distribution led to increased performance.
Fair and Useful Cohort Selection
Sep 04, 2020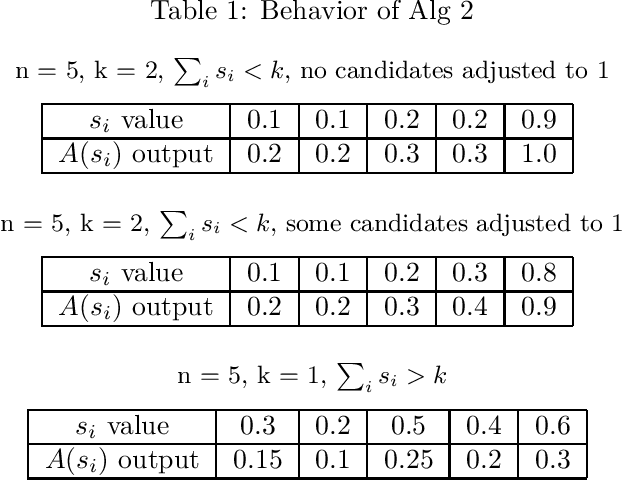

As important decisions about the distribution of society's resources become increasingly automated, it is essential to consider the measurement and enforcement of fairness in these decisions. In this work we build on the results of Dwork and Ilvento ITCS'19, which laid the foundations for the study of fair algorithms under composition. In particular, we study the cohort selection problem, where we wish to use a fair classifier to select $k$ candidates from an arbitrarily ordered set of size $n>k$, while preserving individual fairness and maximizing utility. We define a linear utility function to measure performance relative to the behavior of the original classifier. We develop a fair, utility-optimal $O(n)$-time cohort selection algorithm for the offline setting, and our primary result, a solution to the problem in the streaming setting that keeps no more than $O(k)$ pending candidates at all time.
Full-Time Supervision based Bidirectional RNN for Factoid Question Answering
Jun 21, 2016
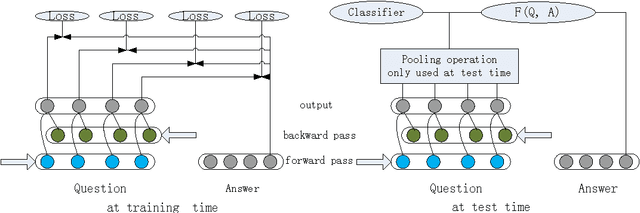
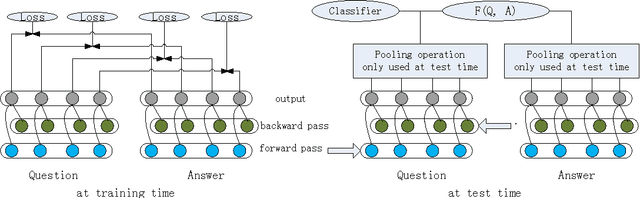

Recently, bidirectional recurrent neural network (BRNN) has been widely used for question answering (QA) tasks with promising performance. However, most existing BRNN models extract the information of questions and answers by directly using a pooling operation to generate the representation for loss or similarity calculation. Hence, these existing models don't put supervision (loss or similarity calculation) at every time step, which will lose some useful information. In this paper, we propose a novel BRNN model called full-time supervision based BRNN (FTS-BRNN), which can put supervision at every time step. Experiments on the factoid QA task show that our FTS-BRNN can outperform other baselines to achieve the state-of-the-art accuracy.
Predicting respondent difficulty in web surveys: A machine-learning approach based on mouse movement features
Nov 05, 2020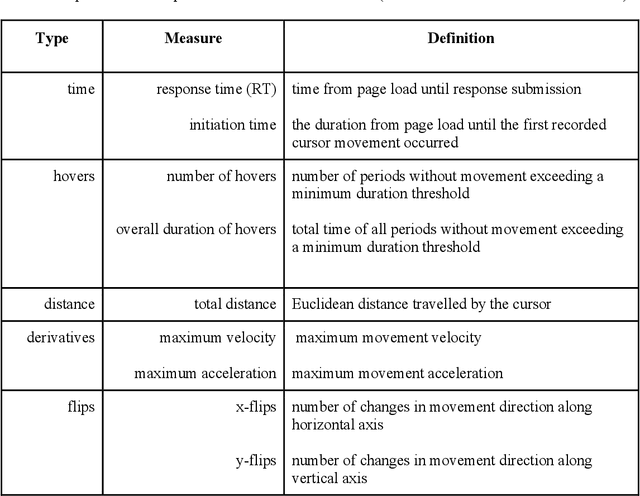
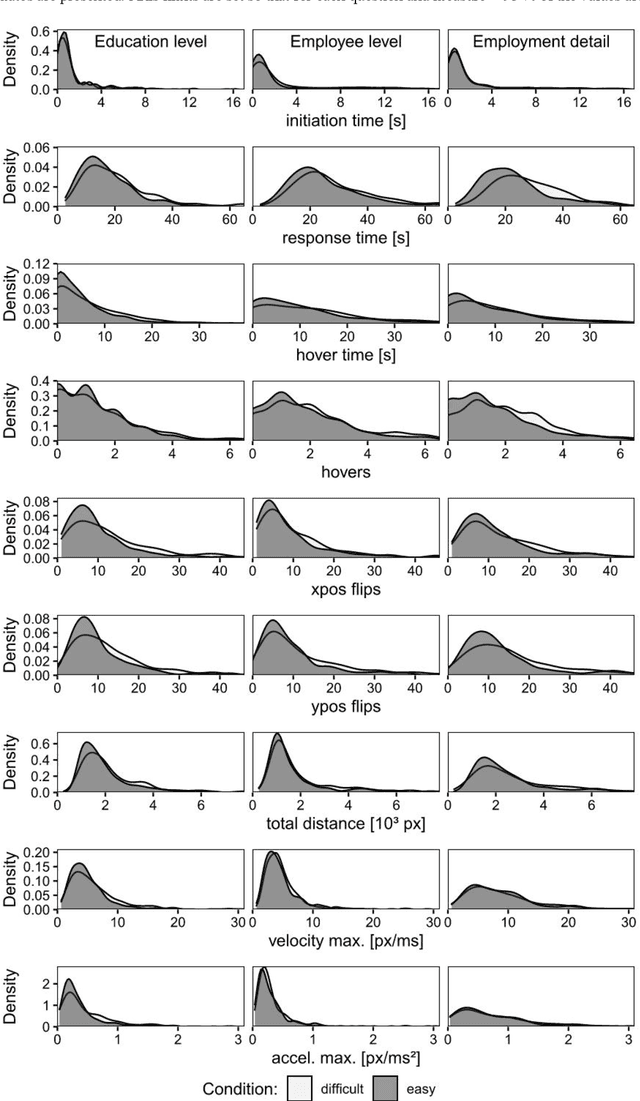
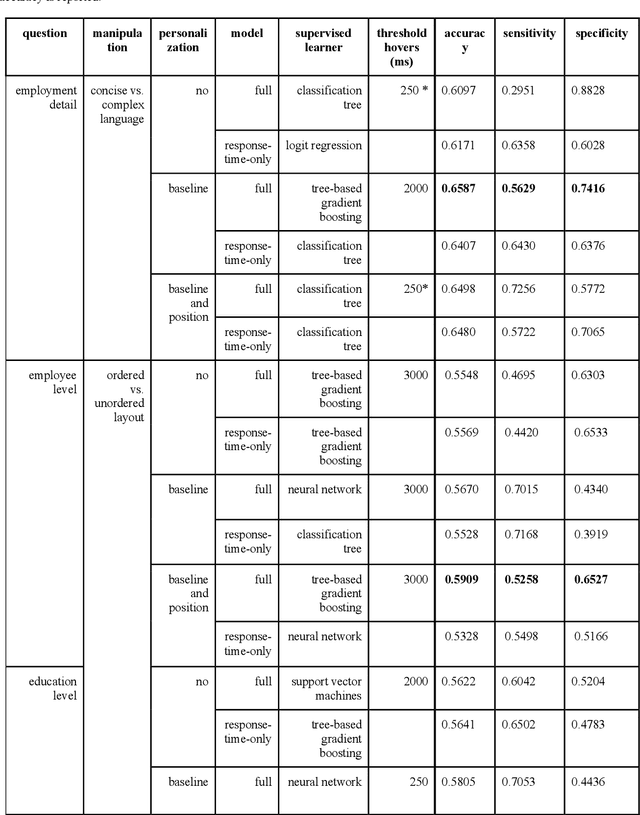
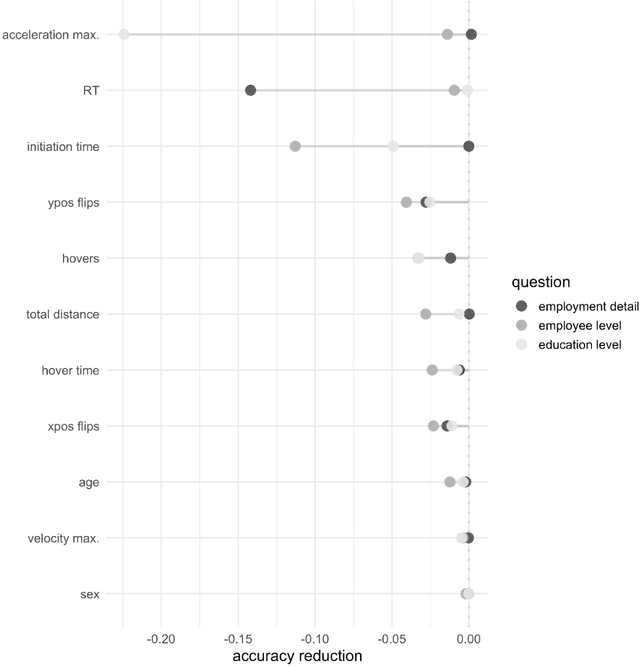
A central goal of survey research is to collect robust and reliable data from respondents. However, despite researchers' best efforts in designing questionnaires, respondents may experience difficulty understanding questions' intent and therefore may struggle to respond appropriately. If it were possible to detect such difficulty, this knowledge could be used to inform real-time interventions through responsive questionnaire design, or to indicate and correct measurement error after the fact. Previous research in the context of web surveys has used paradata, specifically response times, to detect difficulties and to help improve user experience and data quality. However, richer data sources are now available, in the form of the movements respondents make with the mouse, as an additional and far more detailed indicator for the respondent-survey interaction. This paper uses machine learning techniques to explore the predictive value of mouse-tracking data with regard to respondents' difficulty. We use data from a survey on respondents' employment history and demographic information, in which we experimentally manipulate the difficulty of several questions. Using features derived from the cursor movements, we predict whether respondents answered the easy or difficult version of a question, using and comparing several state-of-the-art supervised learning methods. In addition, we develop a personalization method that adjusts for respondents' baseline mouse behavior and evaluate its performance. For all three manipulated survey questions, we find that including the full set of mouse movement features improved prediction performance over response-time-only models in nested cross-validation. Accounting for individual differences in mouse movements led to further improvements.