 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-navigated 3D diffusion MRI using an optimized CAIPI sampling and structured low-rank reconstruction
Jan 11, 2024
3D multi-slab acquisitions are an appealing approach for diffusion MRI because they are compatible with the imaging regime delivering optimal SNR efficiency. In conventional 3D multi-slab imaging, shot-to-shot phase variations caused by motion pose challenges due to the use of multi-shot k-space acquisition. Navigator acquisition after each imaging echo is typically employed to correct phase variations, which prolongs scan time and increases the specific absorption rate (SAR). The aim of this study is to develop a highly efficient, self-navigated method to correct for phase variations in 3D multi-slab diffusion MRI without explicitly acquiring navigators. The sampling of each shot is carefully designed to intersect with the central kz plane of each slab, and the multi-shot sampling is optimized for self-navigation performance while retaining decent reconstruction quality. The central kz intersections from all shots are jointly used to reconstruct a 2D phase map for each shot using a structured low-rank constrained reconstruction that leverages the redundancy in shot and coil dimensions. The phase maps are used to eliminate the shot-to-shot phase inconsistency in the final 3D multi-shot reconstruction. We demonstrate the method's efficacy using retrospective simulations and prospectively acquired in-vivo experiments at 1.22 mm and 1.09 mm isotropic resolutions. Compared to conventional navigated 3D multi-slab imaging, the proposed self-navigated method achieves comparable image quality while shortening the scan time by 31.7% and improving the SNR efficiency by 15.5%. The proposed method produces comparable quality of DTI and white matter tractography to conventional navigated 3D multi-slab acquisition with a much shorter scan time.
Classification of Volatile Organic Compounds by Differential Mobility Spectrometry Based on Continuity of Alpha Curves
Jan 13, 2024Background: Classification of volatile organic compounds (VOCs) is of interest in many fields. Examples include but are not limited to medicine, detection of explosives, and food quality control. Measurements collected with electronic noses can be used for classification and analysis of VOCs. One type of electronic noses that has seen considerable development in recent years is Differential Mobility Spectrometry (DMS). DMS yields measurements that are visualized as dispersion plots that contain traces, also known as alpha curves. Current methods used for analyzing DMS dispersion plots do not usually utilize the information stored in the continuity of these traces, which suggests that alternative approaches should be investigated. Results: In this work, for the first time, dispersion plots were interpreted as a series of measurements evolving sequentially. Thus, it was hypothesized that time-series classification algorithms can be effective for classification and analysis of dispersion plots. An extensive dataset of 900 dispersion plots for five chemicals measured at five flow rates and two concentrations was collected. The data was used to analyze the classification performance of six algorithms. According to our hypothesis, the highest classification accuracy of 88\% was achieved by a Long-Short Term Memory neural network, which supports our hypothesis. Significance: A new concept for approaching classification tasks of dispersion plots is presented and compared with other well-known classification algorithms. This creates a new angle of view for analysis and classification of the dispersion plots. In addition, a new dataset of dispersion plots is openly shared to public.
Ordering-Flexible Multi-Robot Coordination for MovingTarget Convoying Using Long-TermTask Execution
Jan 12, 2024In this paper, we propose a cooperative long-term task execution (LTTE) algorithm for protecting a moving target into the interior of an ordering-flexible convex hull by a team of robots resiliently in the changing environments. Particularly, by designing target-approaching and sensing-neighbor collision-free subtasks, and incorporating these subtasks into the constraints rather than the traditional cost function in an online constraint-based optimization framework, the proposed LTTE can systematically guarantee long-term target convoying under changing environments in the n-dimensional Euclidean space. Then, the introduction of slack variables allow for the constraint violation of different subtasks; i.e., the attraction from target-approaching constraints and the repulsion from time-varying collision-avoidance constraints, which results in the desired formation with arbitrary spatial ordering sequences. Rigorous analysis is provided to guarantee asymptotical convergence with challenging nonlinear couplings induced by time-varying collision-free constraints. Finally, 2D experiments using three autonomous mobile robots (AMRs) are conducted to validate the effectiveness of the proposed algorithm, and 3D simulations tackling changing environmental elements, such as different initial positions, some robots suddenly breakdown and static obstacles are presented to demonstrate the multi-dimensional adaptability, robustness and the ability of obstacle avoidance of the proposed method.
A Reproducibility Study of Goldilocks: Just-Right Tuning of BERT for TAR
Jan 16, 2024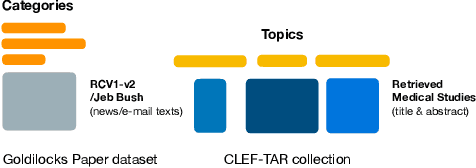
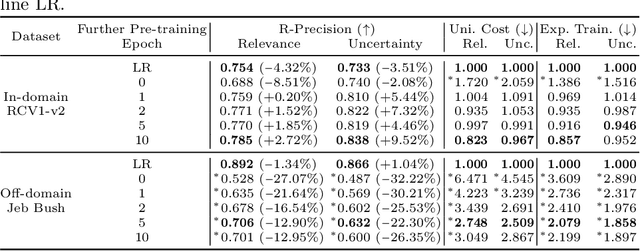
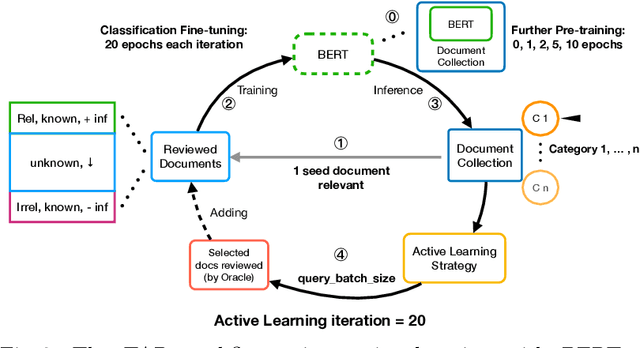
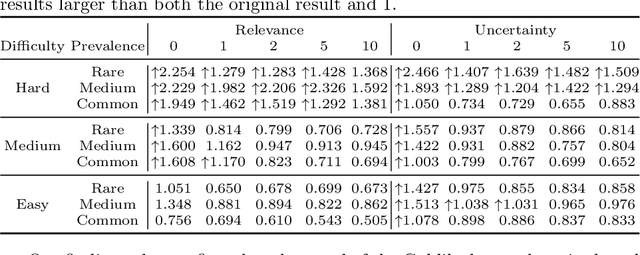
Screening documents is a tedious and time-consuming aspect of high-recall retrieval tasks, such as compiling a systematic literature review, where the goal is to identify all relevant documents for a topic. To help streamline this process, many Technology-Assisted Review (TAR) methods leverage active learning techniques to reduce the number of documents requiring review. BERT-based models have shown high effectiveness in text classification, leading to interest in their potential use in TAR workflows. In this paper, we investigate recent work that examined the impact of further pre-training epochs on the effectiveness and efficiency of a BERT-based active learning pipeline. We first report that we could replicate the original experiments on two specific TAR datasets, confirming some of the findings: importantly, that further pre-training is critical to high effectiveness, but requires attention in terms of selecting the correct training epoch. We then investigate the generalisability of the pipeline on a different TAR task, that of medical systematic reviews. In this context, we show that there is no need for further pre-training if a domain-specific BERT backbone is used within the active learning pipeline. This finding provides practical implications for using the studied active learning pipeline within domain-specific TAR tasks.
Mobile Contactless Palmprint Recognition: Use of Multiscale, Multimodel Embeddings
Jan 16, 2024Contactless palmprints are comprised of both global and local discriminative features. Most prior work focuses on extracting global features or local features alone for palmprint matching, whereas this research introduces a novel framework that combines global and local features for enhanced palmprint matching accuracy. Leveraging recent advancements in deep learning, this study integrates a vision transformer (ViT) and a convolutional neural network (CNN) to extract complementary local and global features. Next, a mobile-based, end-to-end palmprint recognition system is developed, referred to as Palm-ID. On top of the ViT and CNN features, Palm-ID incorporates a palmprint enhancement module and efficient dimensionality reduction (for faster matching). Palm-ID balances the trade-off between accuracy and latency, requiring just 18ms to extract a template of size 516 bytes, which can be efficiently searched against a 10,000 palmprint gallery in 0.33ms on an AMD EPYC 7543 32-Core CPU utilizing 128-threads. Cross-database matching protocols and evaluations on large-scale operational datasets demonstrate the robustness of the proposed method, achieving a TAR of 98.06% at FAR=0.01% on a newly collected, time-separated dataset. To show a practical deployment of the end-to-end system, the entire recognition pipeline is embedded within a mobile device for enhanced user privacy and security.
Adversarial Supervision Makes Layout-to-Image Diffusion Models Thrive
Jan 16, 2024Despite the recent advances in large-scale diffusion models, little progress has been made on the layout-to-image (L2I) synthesis task. Current L2I models either suffer from poor editability via text or weak alignment between the generated image and the input layout. This limits their usability in practice. To mitigate this, we propose to integrate adversarial supervision into the conventional training pipeline of L2I diffusion models (ALDM). Specifically, we employ a segmentation-based discriminator which provides explicit feedback to the diffusion generator on the pixel-level alignment between the denoised image and the input layout. To encourage consistent adherence to the input layout over the sampling steps, we further introduce the multistep unrolling strategy. Instead of looking at a single timestep, we unroll a few steps recursively to imitate the inference process, and ask the discriminator to assess the alignment of denoised images with the layout over a certain time window. Our experiments show that ALDM enables layout faithfulness of the generated images, while allowing broad editability via text prompts. Moreover, we showcase its usefulness for practical applications: by synthesizing target distribution samples via text control, we improve domain generalization of semantic segmentation models by a large margin (~12 mIoU points).
Series2Vec: Similarity-based Self-supervised Representation Learning for Time Series Classification
Dec 12, 2023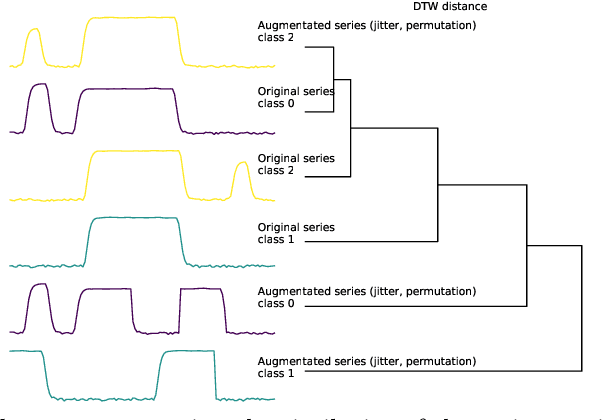
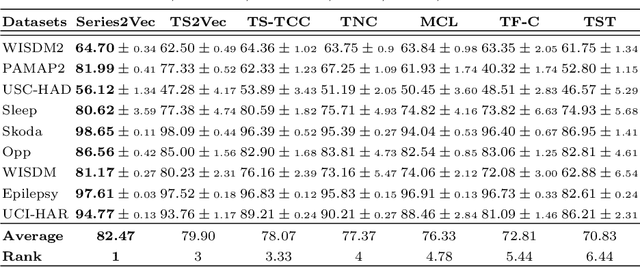
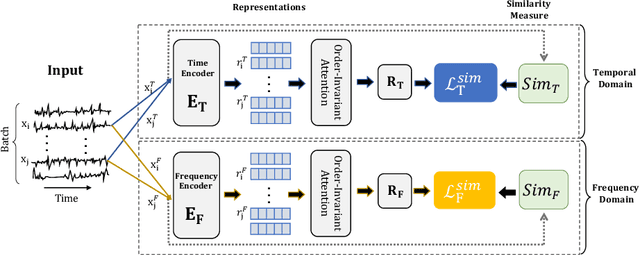

We argue that time series analysis is fundamentally different in nature to either vision or natural language processing with respect to the forms of meaningful self-supervised learning tasks that can be defined. Motivated by this insight, we introduce a novel approach called \textit{Series2Vec} for self-supervised representation learning. Unlike other self-supervised methods in time series, which carry the risk of positive sample variants being less similar to the anchor sample than series in the negative set, Series2Vec is trained to predict the similarity between two series in both temporal and spectral domains through a self-supervised task. Series2Vec relies primarily on the consistency of the unsupervised similarity step, rather than the intrinsic quality of the similarity measurement, without the need for hand-crafted data augmentation. To further enforce the network to learn similar representations for similar time series, we propose a novel approach that applies order-invariant attention to each representation within the batch during training. Our evaluation of Series2Vec on nine large real-world datasets, along with the UCR/UEA archive, shows enhanced performance compared to current state-of-the-art self-supervised techniques for time series. Additionally, our extensive experiments show that Series2Vec performs comparably with fully supervised training and offers high efficiency in datasets with limited-labeled data. Finally, we show that the fusion of Series2Vec with other representation learning models leads to enhanced performance for time series classification. Code and models are open-source at \url{https://github.com/Navidfoumani/Series2Vec.}
Multi-perspective Feedback-attention Coupling Model for Continuous-time Dynamic Graphs
Dec 13, 2023Recently, representation learning over graph networks has gained popularity, with various models showing promising results. Despite this, several challenges persist: 1) most methods are designed for static or discrete-time dynamic graphs; 2) existing continuous-time dynamic graph algorithms focus on a single evolving perspective; and 3) many continuous-time dynamic graph approaches necessitate numerous temporal neighbors to capture long-term dependencies. In response, this paper introduces the Multi-Perspective Feedback-Attention Coupling (MPFA) model. MPFA incorporates information from both evolving and raw perspectives, efficiently learning the interleaved dynamics of observed processes. The evolving perspective employs temporal self-attention to distinguish continuously evolving temporal neighbors for information aggregation. Through dynamic updates, this perspective can capture long-term dependencies using a small number of temporal neighbors. Meanwhile, the raw perspective utilizes a feedback attention module with growth characteristic coefficients to aggregate raw neighborhood information. Experimental results on a self-organizing dataset and seven public datasets validate the efficacy and competitiveness of our proposed model.
AutoXPCR: Automated Multi-Objective Model Selection for Time Series Forecasting
Dec 20, 2023Automated machine learning (AutoML) streamlines the creation of ML models. While most methods select the "best" model based on predictive quality, it's crucial to acknowledge other aspects, such as interpretability and resource consumption. This holds particular importance in the context of deep neural networks (DNNs), as these models are often perceived as computationally intensive black boxes. In the challenging domain of time series forecasting, DNNs achieve stunning results, but specialized approaches for automatically selecting models are scarce. In this paper, we propose AutoXPCR - a novel method for automated and explainable multi-objective model selection. Our approach leverages meta-learning to estimate any model's performance along PCR criteria, which encompass (P)redictive error, (C)omplexity, and (R)esource demand. Explainability is addressed on multiple levels, as our interactive framework can prioritize less complex models and provide by-product explanations of recommendations. We demonstrate practical feasibility by deploying AutoXPCR on over 1000 configurations across 114 data sets from various domains. Our method clearly outperforms other model selection approaches - on average, it only requires 20% of computation costs for recommending models with 90% of the best-possible quality.
Stable generative modeling using diffusion maps
Jan 09, 2024We consider the problem of sampling from an unknown distribution for which only a sufficiently large number of training samples are available. Such settings have recently drawn considerable interest in the context of generative modelling. In this paper, we propose a generative model combining diffusion maps and Langevin dynamics. Diffusion maps are used to approximate the drift term from the available training samples, which is then implemented in a discrete-time Langevin sampler to generate new samples. By setting the kernel bandwidth to match the time step size used in the unadjusted Langevin algorithm, our method effectively circumvents any stability issues typically associated with time-stepping stiff stochastic differential equations. More precisely, we introduce a novel split-step scheme, ensuring that the generated samples remain within the convex hull of the training samples. Our framework can be naturally extended to generate conditional samples. We demonstrate the performance of our proposed scheme through experiments on synthetic datasets with increasing dimensions and on a stochastic subgrid-scale parametrization conditional sampling problem.