 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Enhanced Adversarial Network with Combined Latent Features for Spatio-Temporal Facial Affect Estimation in the Wild
Feb 18, 2021
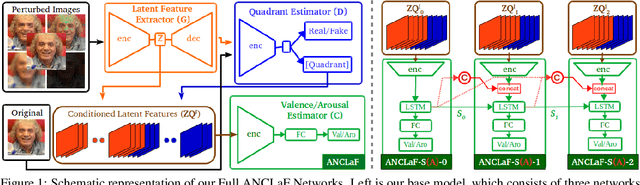
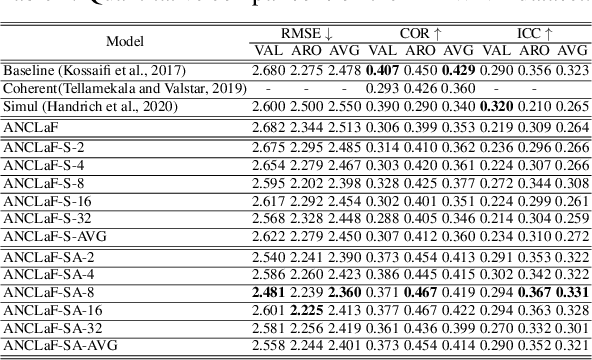
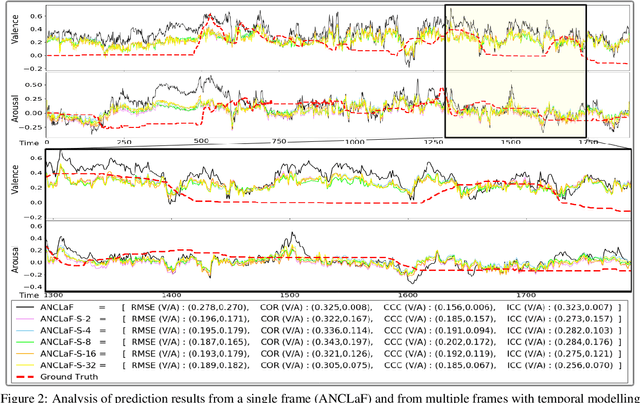
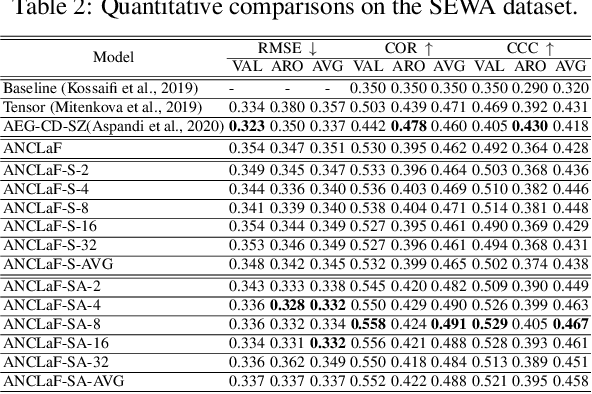
Affective Computing has recently attracted the attention of the research community, due to its numerous applications in diverse areas. In this context, the emergence of video-based data allows to enrich the widely used spatial features with the inclusion of temporal information. However, such spatio-temporal modelling often results in very high-dimensional feature spaces and large volumes of data, making training difficult and time consuming. This paper addresses these shortcomings by proposing a novel model that efficiently extracts both spatial and temporal features of the data by means of its enhanced temporal modelling based on latent features. Our proposed model consists of three major networks, coined Generator, Discriminator, and Combiner, which are trained in an adversarial setting combined with curriculum learning to enable our adaptive attention modules. In our experiments, we show the effectiveness of our approach by reporting our competitive results on both the AFEW-VA and SEWA datasets, suggesting that temporal modelling improves the affect estimates both in qualitative and quantitative terms. Furthermore, we find that the inclusion of attention mechanisms leads to the highest accuracy improvements, as its weights seem to correlate well with the appearance of facial movements, both in terms of temporal localisation and intensity. Finally, we observe the sequence length of around 160\,ms to be the optimum one for temporal modelling, which is consistent with other relevant findings utilising similar lengths.
Neural 3D Video Synthesis
Mar 03, 2021
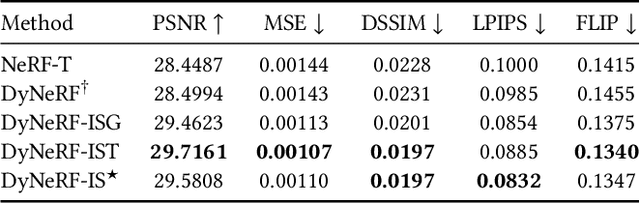
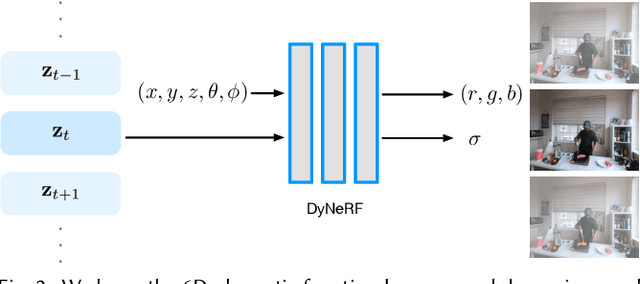

We propose a novel approach for 3D video synthesis that is able to represent multi-view video recordings of a dynamic real-world scene in a compact, yet expressive representation that enables high-quality view synthesis and motion interpolation. Our approach takes the high quality and compactness of static neural radiance fields in a new direction: to a model-free, dynamic setting. At the core of our approach is a novel time-conditioned neural radiance fields that represents scene dynamics using a set of compact latent codes. To exploit the fact that changes between adjacent frames of a video are typically small and locally consistent, we propose two novel strategies for efficient training of our neural network: 1) An efficient hierarchical training scheme, and 2) an importance sampling strategy that selects the next rays for training based on the temporal variation of the input videos. In combination, these two strategies significantly boost the training speed, lead to fast convergence of the training process, and enable high quality results. Our learned representation is highly compact and able to represent a 10 second 30 FPS multi-view video recording by 18 cameras with a model size of just 28MB. We demonstrate that our method can render high-fidelity wide-angle novel views at over 1K resolution, even for highly complex and dynamic scenes. We perform an extensive qualitative and quantitative evaluation that shows that our approach outperforms the current state of the art. We include additional video and information at: https://neural-3d-video.github.io/
Feature Analyses and Modelling of Lithium-ion Batteries Manufacturing based on Random Forest Classification
Feb 10, 2021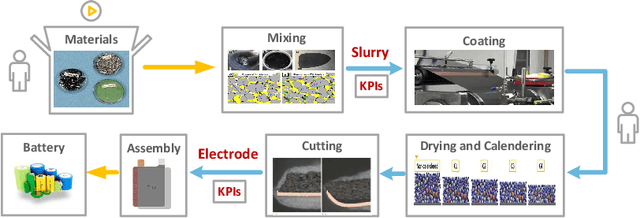
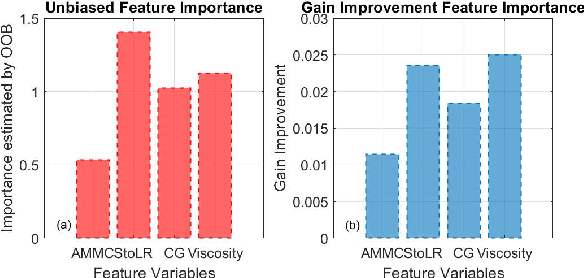
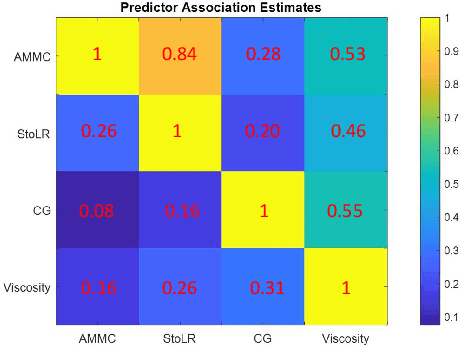
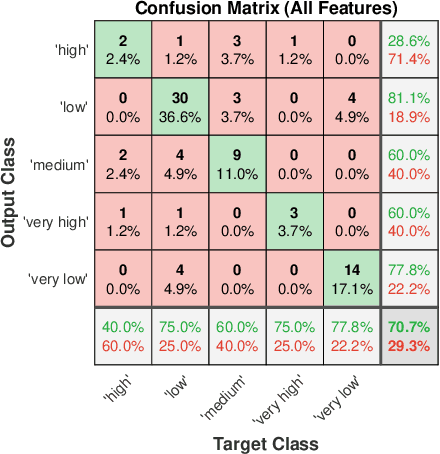
Lithium-ion battery manufacturing is a highly complicated process with strongly coupled feature interdependencies, a feasible solution that can analyse feature variables within manufacturing chain and achieve reliable classification is thus urgently needed. This article proposes a random forest (RF)-based classification framework, through using the out of bag (OOB) predictions, Gini changes as well as predictive measure of association (PMOA), for effectively quantifying the importance and correlations of battery manufacturing features and their effects on the classification of electrode properties. Battery manufacturing data containing three intermediate product features from the mixing stage and one product parameter from the coating stage are analysed by the designed RF framework to investigate their effects on both the battery electrode active material mass load and porosity. Illustrative results demonstrate that the proposed RF framework not only achieves the reliable classification of electrode properties but also leads to the effective quantification of both manufacturing feature importance and correlations. This is the first time to design a systematic RF framework for simultaneously quantifying battery production feature importance and correlations by three various quantitative indicators including the unbiased feature importance (FI), gain improvement FI and PMOA, paving a promising solution to reduce model dimension and conduct efficient sensitivity analysis of battery manufacturing.
Aggregating Dependent Gaussian Experts in Local Approximation
Oct 17, 2020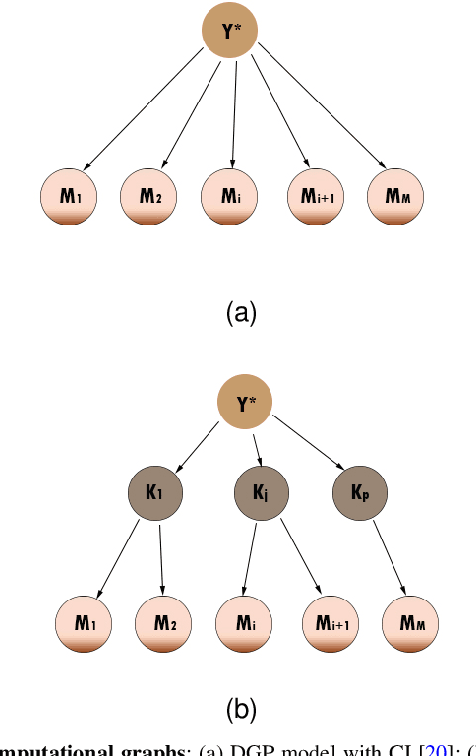
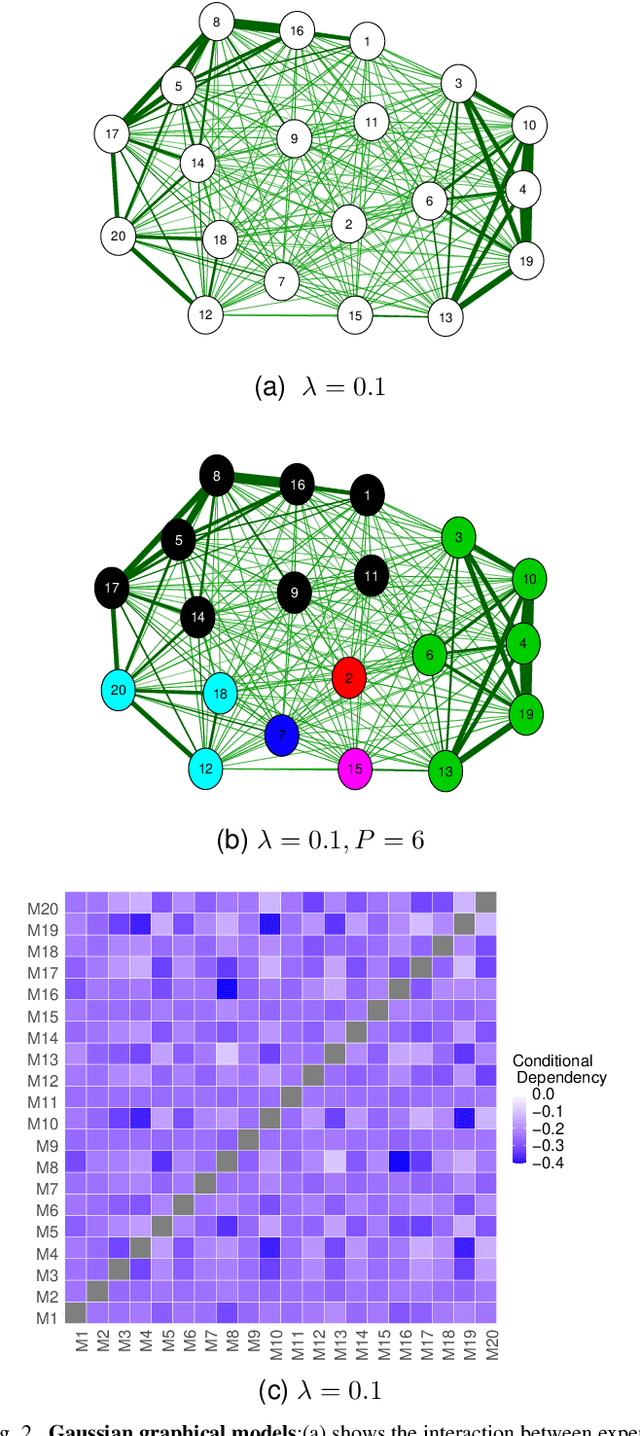
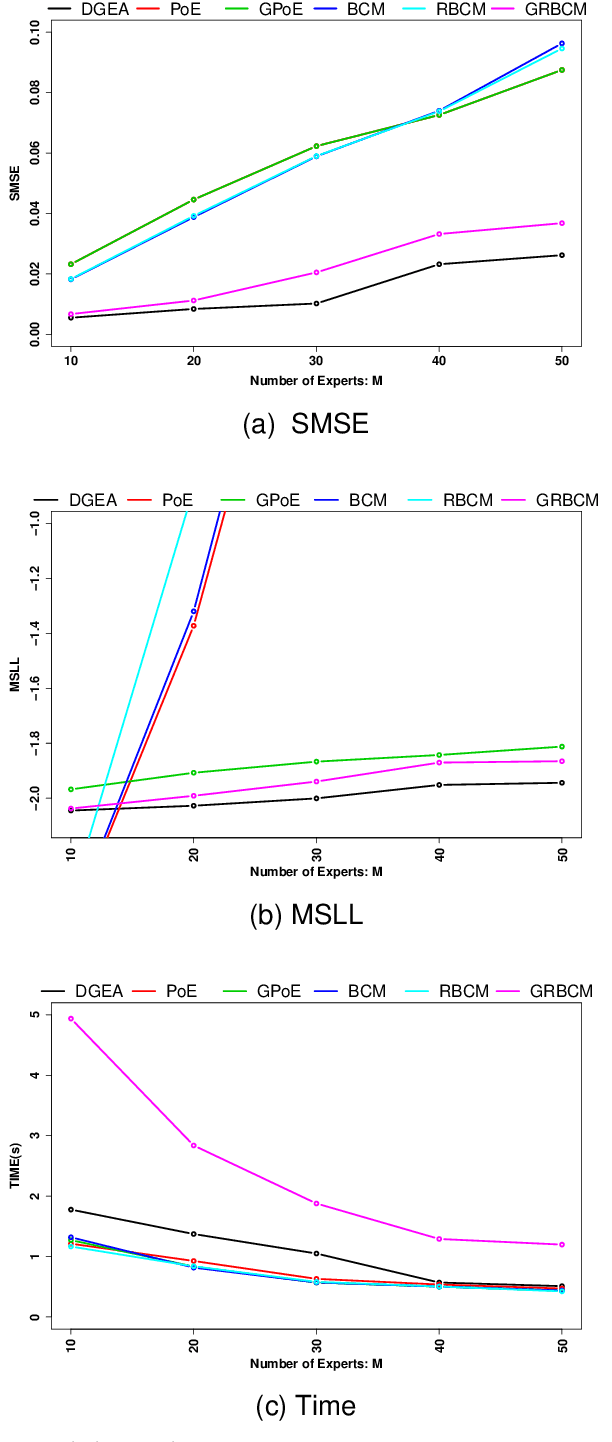
Distributed Gaussian processes (DGPs) are prominent local approximation methods to scale Gaussian processes (GPs) to large datasets. Instead of a global estimation, they train local experts by dividing the training set into subsets, thus reducing the time complexity. This strategy is based on the conditional independence assumption, which basically means that there is a perfect diversity between the local experts. In practice, however, this assumption is often violated, and the aggregation of experts leads to sub-optimal and inconsistent solutions. In this paper, we propose a novel approach for aggregating the Gaussian experts by detecting strong violations of conditional independence. The dependency between experts is determined by using a Gaussian graphical model, which yields the precision matrix. The precision matrix encodes conditional dependencies between experts and is used to detect strongly dependent experts and construct an improved aggregation. Using both synthetic and real datasets, our experimental evaluations illustrate that our new method outperforms other state-of-the-art (SOTA) DGP approaches while being substantially more time-efficient than SOTA approaches, which build on independent experts.
SE(3)-Equivariant Graph Neural Networks for Data-Efficient and Accurate Interatomic Potentials
Jan 08, 2021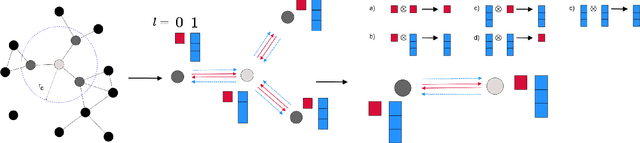
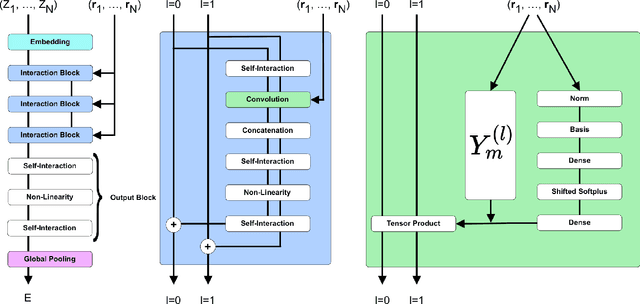
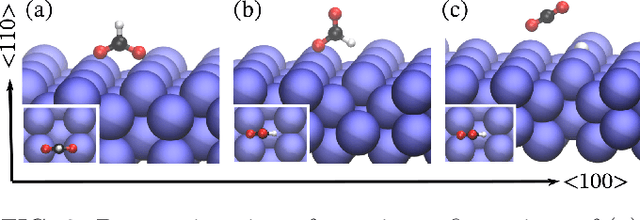
This work presents Neural Equivariant Interatomic Potentials (NequIP), a SE(3)-equivariant neural network approach for learning interatomic potentials from ab-initio calculations for molecular dynamics simulations. While most contemporary symmetry-aware models use invariant convolutions and only act on scalars, NequIP employs SE(3)-equivariant convolutions for interactions of geometric tensors, resulting in a more information-rich and faithful representation of atomic environments. The method achieves state-of-the-art accuracy on a challenging set of diverse molecules and materials while exhibiting remarkable data efficiency. NequIP outperforms existing models with up to three orders of magnitude fewer training data, challenging the widely held belief that deep neural networks require massive training sets. The high data efficiency of the method allows for the construction of accurate potentials using high-order quantum chemical level of theory as reference and enables high-fidelity molecular dynamics simulations over long time scales.
PDFFlow: hardware accelerating parton density access
Dec 15, 2020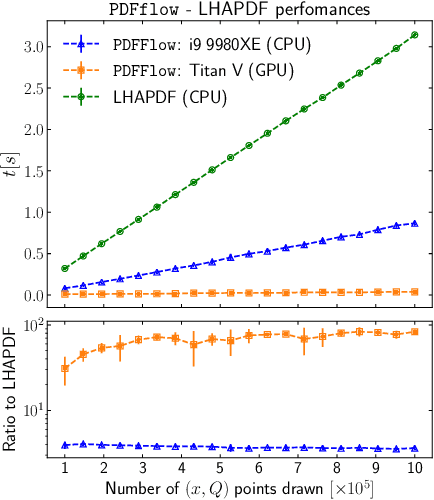
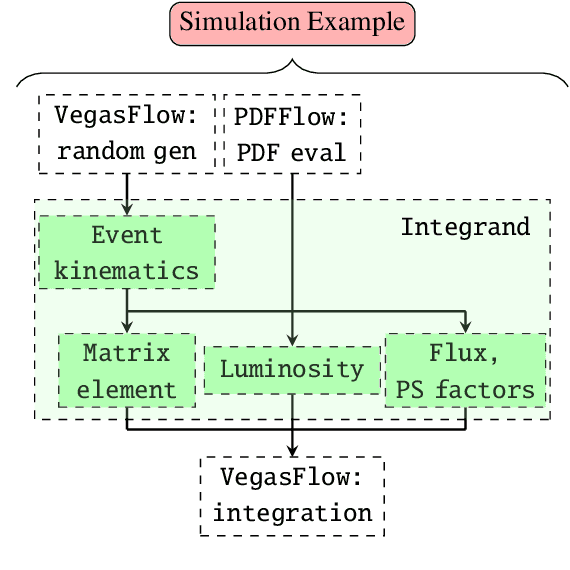

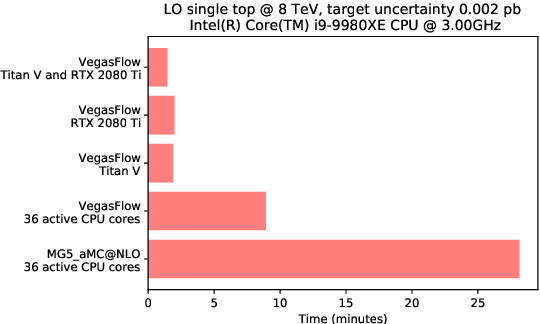
We present PDFFlow, a new software for fast evaluation of parton distribution functions (PDFs) designed for platforms with hardware accelerators. PDFs are essential for the calculation of particle physics observables through Monte Carlo simulation techniques. The evaluation of a generic set of PDFs for quarks and gluons at a given momentum fraction and energy scale requires the implementation of interpolation algorithms as introduced for the first time by the LHAPDF project. PDFFlow extends and implements these interpolation algorithms using Google's TensorFlow library providing the possibility to perform PDF evaluations taking fully advantage of multi-threading CPU and GPU setups. We benchmark the performance of this library on multiple scenarios relevant for the particle physics community.
Automatic Cell Counting in Flourescent Microscopy Using Deep Learning
Feb 24, 2021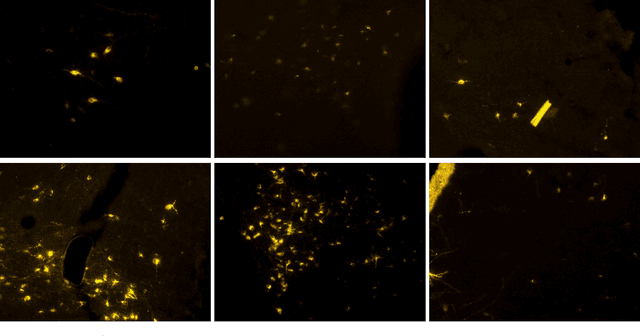
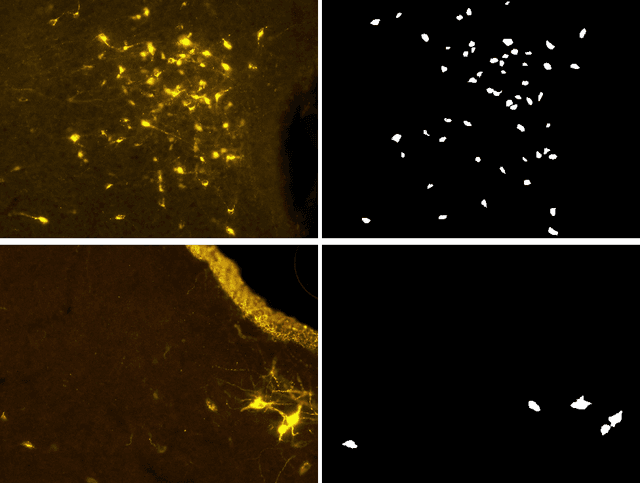
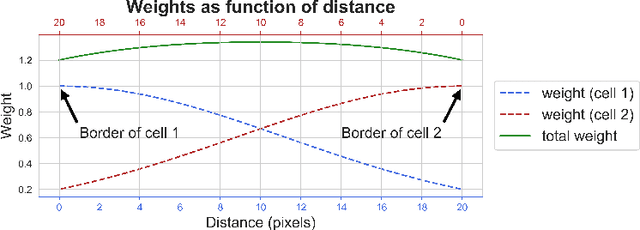
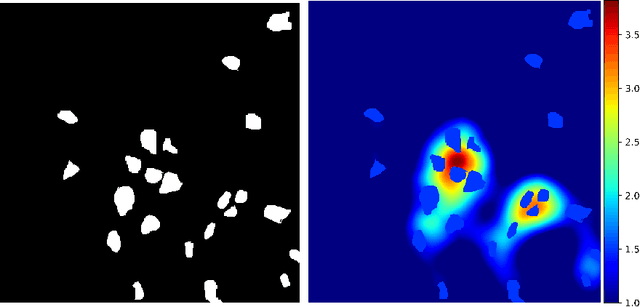
Counting cells in fluorescent microscopy is a tedious, time-consuming task that researchers have to accomplish to assess the effects of different experimental conditions on biological structures of interest. Although such objects are generally easy to identify, the process of manually annotating cells is sometimes subject to arbitrariness due to the operator's interpretation of the borderline cases. We propose a Machine Learning approach that exploits a fully-convolutional network in a binary segmentation fashion to localize the objects of interest. Counts are then retrieved as the number of detected items. Specifically, we adopt a UNet-like architecture leveraging residual units and an extended bottleneck for enlarging the field-of-view. In addition, we make use of weighted maps that penalize the errors on cells boundaries increasingly with overcrowding. These changes provide more context and force the model to focus on relevant features during pixel-wise classification. As a result, the model performance is enhanced, especially in presence of clumping cells, artifacts and confounding biological structures. Posterior assessment of the results with domain experts confirms that the model detects cells of interest correctly. The model demonstrates a human-level ability inasmuch even erroneous predictions seem to fall within the limits of operator interpretation. This qualitative assessment is also corroborated by quantitative metrics as an ${F_1}$ score of 0.87. Despite some difficulties in interpretation, results are also satisfactory with respect to the counting task, as testified by mean and median absolute error of, respectively, 0.8 and 1.
An Empirical Study on Model-agnostic Debiasing Strategies for Robust Natural Language Inference
Oct 17, 2020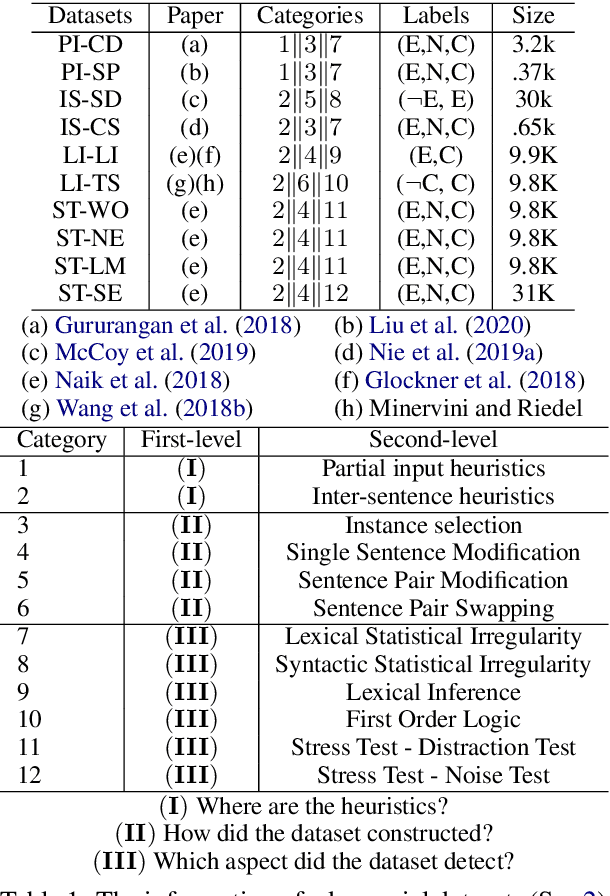
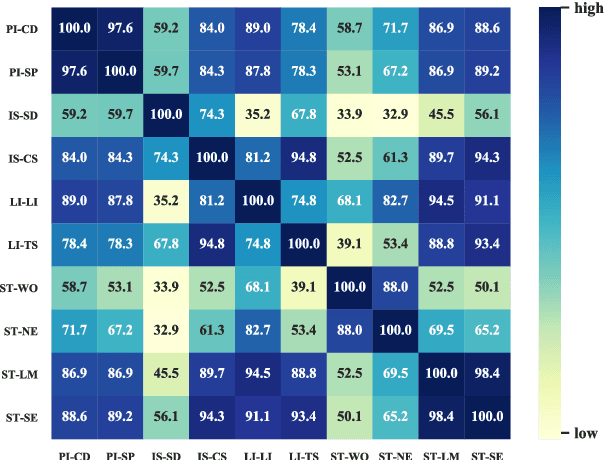
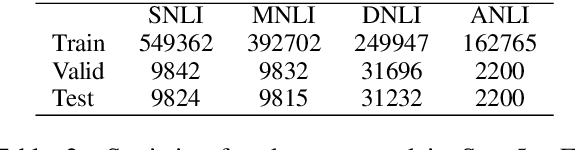
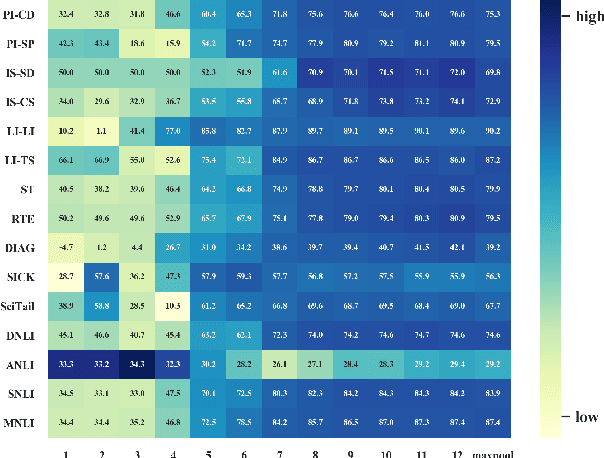
The prior work on natural language inference (NLI) debiasing mainly targets at one or few known biases while not necessarily making the models more robust. In this paper, we focus on the model-agnostic debiasing strategies and explore how to (or is it possible to) make the NLI models robust to multiple distinct adversarial attacks while keeping or even strengthening the models' generalization power. We firstly benchmark prevailing neural NLI models including pretrained ones on various adversarial datasets. We then try to combat distinct known biases by modifying a mixture of experts (MoE) ensemble method and show that it's nontrivial to mitigate multiple NLI biases at the same time, and that model-level ensemble method outperforms MoE ensemble method. We also perform data augmentation including text swap, word substitution and paraphrase and prove its efficiency in combating various (though not all) adversarial attacks at the same time. Finally, we investigate several methods to merge heterogeneous training data (1.35M) and perform model ensembling, which are straightforward but effective to strengthen NLI models.
Are Adaptive Face Recognition Systems still Necessary? Experiments on the APE Dataset
Oct 17, 2020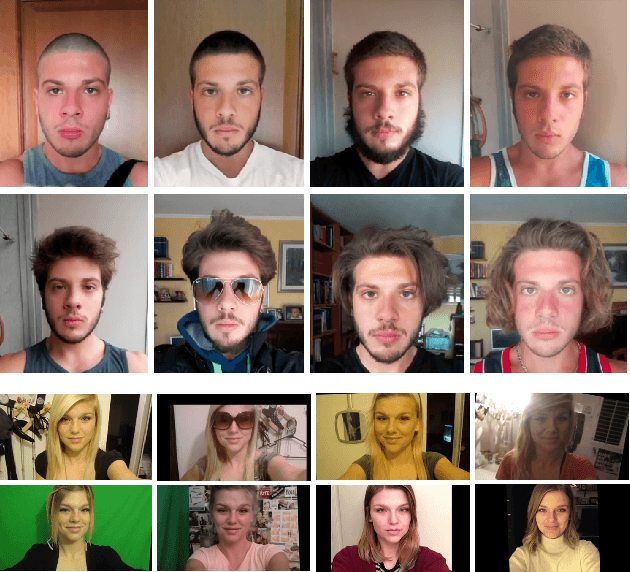

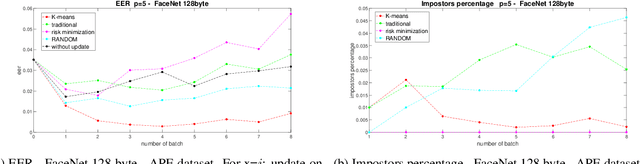
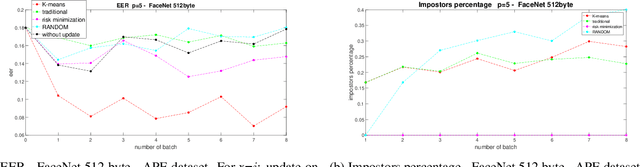
In the last five years, deep learning methods, in particular CNN, have attracted considerable attention in the field of face-based recognition, achieving impressive results. Despite this progress, it is not yet clear precisely to what extent deep features are able to follow all the intra-class variations that the face can present over time. In this paper we investigate the performance the performance improvement of face recognition systems by adopting self updating strategies of the face templates. For that purpose, we evaluate the performance of a well-known deep-learning face representation, namely, FaceNet, on a dataset that we generated explicitly conceived to embed intra-class variations of users on a large time span of captures: the APhotoEveryday (APE) dataset. Moreover, we compare these deep features with handcrafted features extracted using the BSIF algorithm. In both cases, we evaluate various template update strategies, in order to detect the most useful for such kind of features. Experimental results show the effectiveness of "optimized" self-update methods with respect to systems without update or random selection of templates.
CycleGAN without checkerboard artifacts for counter-forensics of fake-image detection
Dec 01, 2020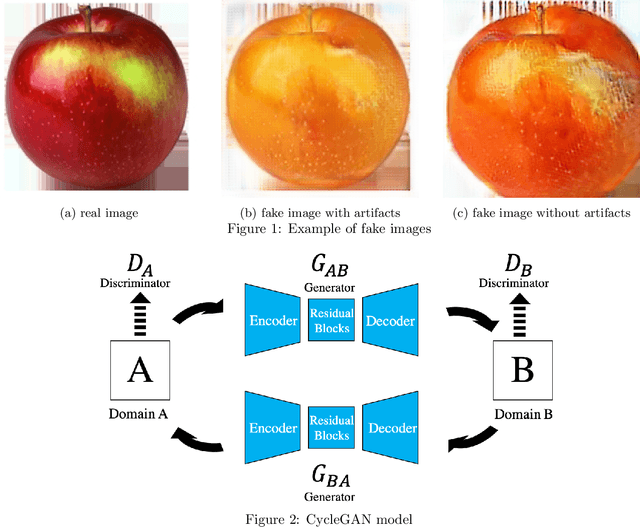

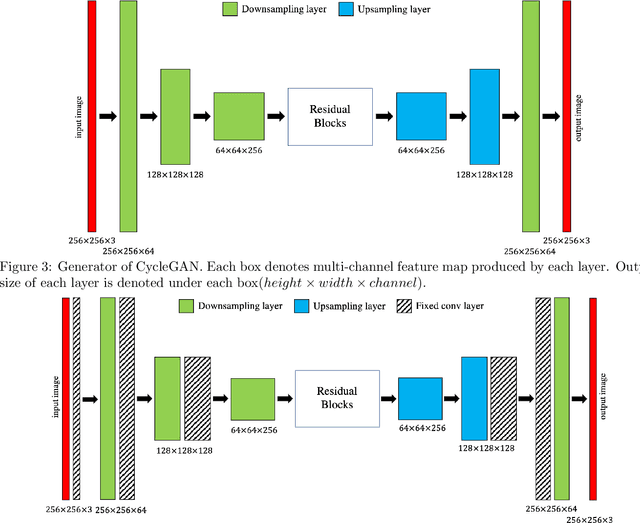
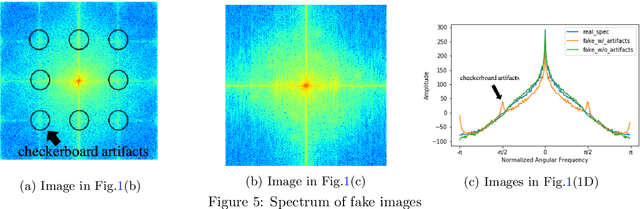
In this paper, we propose a novel CycleGAN without checkerboard artifacts for counter-forensics of fake-image detection. Recent rapid advances in image manipulation tools and deep image synthesis techniques, such as Generative Adversarial Networks (GANs) have easily generated fake images, so detecting manipulated images has become an urgent issue. Most state-of-the-art forgery detection methods assume that images include checkerboard artifacts which are generated by using DNNs. Accordingly, we propose a novel CycleGAN without any checkerboard artifacts for counter-forensics of fake-mage detection methods for the first time, as an example of GANs without checkerboard artifacts.