 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Gamified and Self-Adaptive Applications for the Common Good: Research Challenges Ahead
Mar 22, 2021
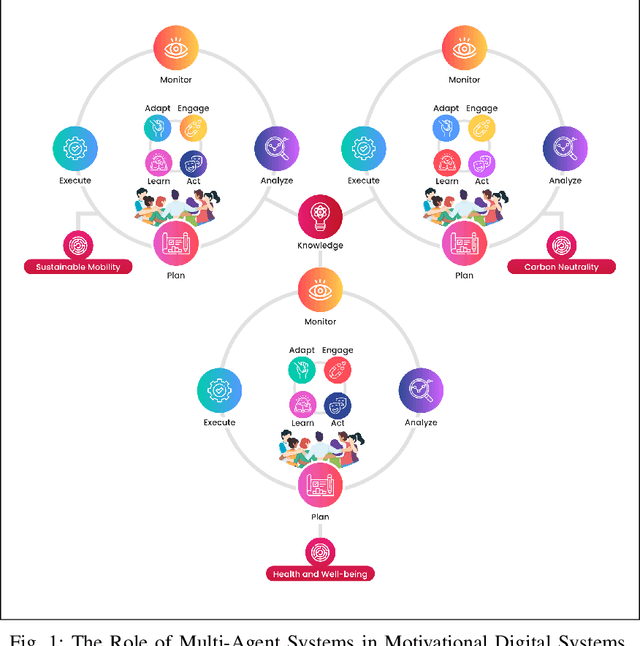
Motivational digital systems offer capabilities to engage and motivate end-users to foster behavioral changes towards a common goal. In general these systems use gamification principles in non-games contexts. Over the years, gamification has gained consensus among researchers and practitioners as a tool to motivate people to perform activities with the ultimate goal of promoting behavioural change, or engaging the users to perform activities that can offer relevant benefits but which can be seen as unrewarding and even tedious. There exists a plethora of heterogeneous application scenarios towards reaching the common good that can benefit from gamification. However, an open problem is how to effectively combine multiple motivational campaigns to maximise the degree of participation without exposing the system to counterproductive behaviours. We conceive motivational digital systems as multi-agent systems: self-adaptation is a feature of the overall system, while individual agents may self-adapt in order to leverage other agents' resources, functionalities and capabilities to perform tasks more efficiently and effectively. Consequently, multiple campaigns can be run and adapted to reach common good. At the same time, agents are grouped into micro-communities in which agents contribute with their own social capital and leverage others' capabilities to balance their weaknesses. In this paper we propose our vision on how the principles at the base of the autonomous and multi-agent systems can be exploited to design multi-challenge motivational systems to engage smart communities towards common goals. We present an initial version of a general framework based on the MAPE-K loop and a set of research challenges that characterise our research roadmap for the implementation of our vision.
Efficient Learning with Arbitrary Covariate Shift
Feb 15, 2021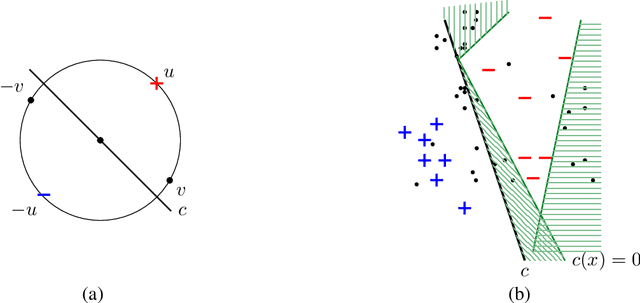
We give an efficient algorithm for learning a binary function in a given class C of bounded VC dimension, with training data distributed according to P and test data according to Q, where P and Q may be arbitrary distributions over X. This is the generic form of what is called covariate shift, which is impossible in general as arbitrary P and Q may not even overlap. However, recently guarantees were given in a model called PQ-learning (Goldwasser et al., 2020) where the learner has: (a) access to unlabeled test examples from Q (in addition to labeled samples from P, i.e., semi-supervised learning); and (b) the option to reject any example and abstain from classifying it (i.e., selective classification). The algorithm of Goldwasser et al. (2020) requires an (agnostic) noise tolerant learner for C. The present work gives a polynomial-time PQ-learning algorithm that uses an oracle to a "reliable" learner for C, where reliable learning (Kalai et al., 2012) is a model of learning with one-sided noise. Furthermore, our reduction is optimal in the sense that we show the equivalence of reliable and PQ learning.
Enhancement Of Coded Speech Using a Mask-Based Post-Filter
Oct 12, 2020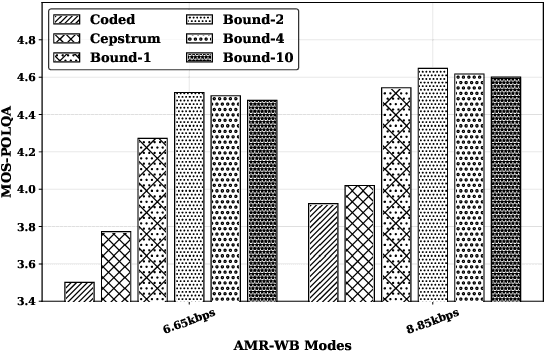
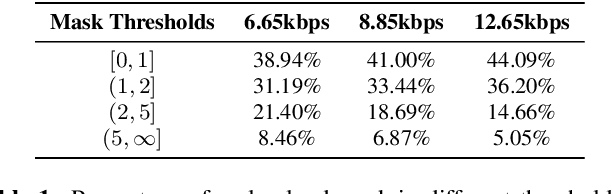

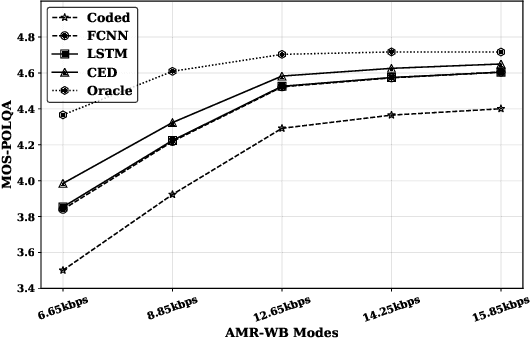
The quality of speech codecs deteriorates at low bitrates due to high quantization noise. A post-filter is generally employed to enhance the quality of the coded speech. In this paper, a data-driven post-filter relying on masking in the time-frequency domain is proposed. A fully connected neural network (FCNN), a convolutional encoder-decoder (CED) network and a long short-term memory (LSTM) network are implemeted to estimate a real-valued mask per time-frequency bin. The proposed models were tested on the five lowest operating modes (6.65 kbps-15.85 kbps) of the Adaptive Multi-Rate Wideband codec (AMR-WB). Both objective and subjective evaluations confirm the enhancement of the coded speech and also show the superiority of the mask-based neural network system over a conventional heuristic post-filter used in the standard like ITU-T G.718.
Augmenting Proposals by the Detector Itself
Jan 28, 2021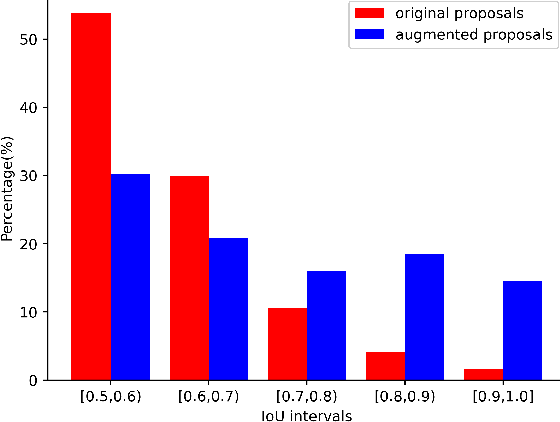
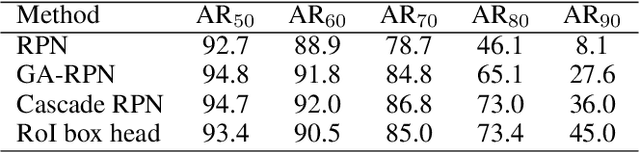
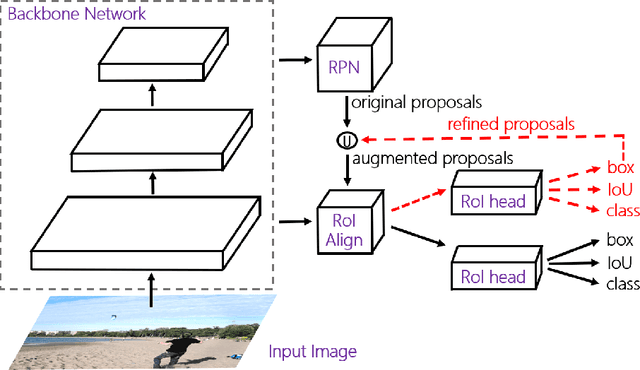
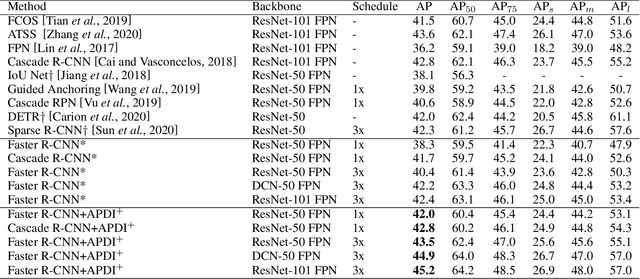
Lacking enough high quality proposals for RoI box head has impeded two-stage and multi-stage object detectors for a long time, and many previous works try to solve it via improving RPN's performance or manually generating proposals from ground truth. However, these methods either need huge training and inference costs or bring little improvements. In this paper, we design a novel training method named APDI, which means augmenting proposals by the detector itself and can generate proposals with higher quality. Furthermore, APDI makes it possible to integrate IoU head into RoI box head. And it does not add any hyperparameter, which is beneficial for future research and downstream tasks. Extensive experiments on COCO dataset show that our method brings at least 2.7 AP improvements on Faster R-CNN with various backbones, and APDI can cooperate with advanced RPNs, such as GA-RPN and Cascade RPN, to obtain extra gains. Furthermore, it brings significant improvements on Cascade R-CNN.
MotionRNN: A Flexible Model for Video Prediction with Spacetime-Varying Motions
Mar 03, 2021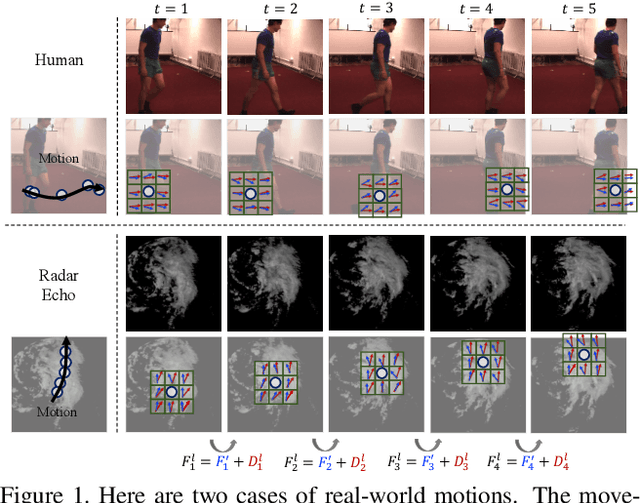
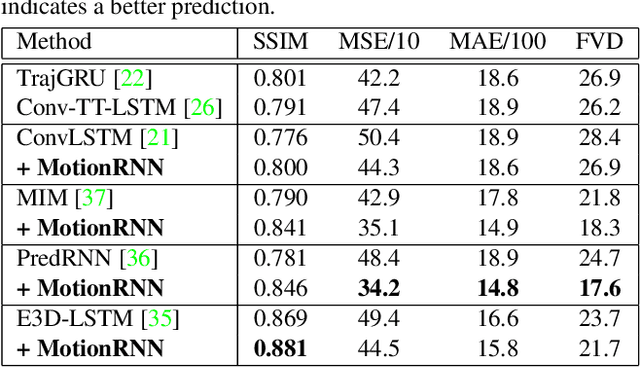
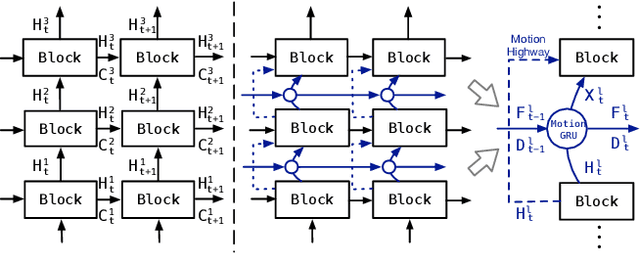
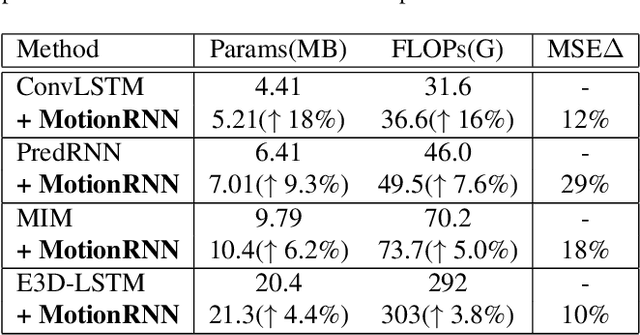
This paper tackles video prediction from a new dimension of predicting spacetime-varying motions that are incessantly changing across both space and time. Prior methods mainly capture the temporal state transitions but overlook the complex spatiotemporal variations of the motion itself, making them difficult to adapt to ever-changing motions. We observe that physical world motions can be decomposed into transient variation and motion trend, while the latter can be regarded as the accumulation of previous motions. Thus, simultaneously capturing the transient variation and the motion trend is the key to make spacetime-varying motions more predictable. Based on these observations, we propose the MotionRNN framework, which can capture the complex variations within motions and adapt to spacetime-varying scenarios. MotionRNN has two main contributions. The first is that we design the MotionGRU unit, which can model the transient variation and motion trend in a unified way. The second is that we apply the MotionGRU to RNN-based predictive models and indicate a new flexible video prediction architecture with a Motion Highway that can significantly improve the ability to predict changeable motions and avoid motion vanishing for stacked multiple-layer predictive models. With high flexibility, this framework can adapt to a series of models for deterministic spatiotemporal prediction. Our MotionRNN can yield significant improvements on three challenging benchmarks for video prediction with spacetime-varying motions.
EmoWrite: A Sentiment Analysis-Based Thought to Text Conversion
Mar 03, 2021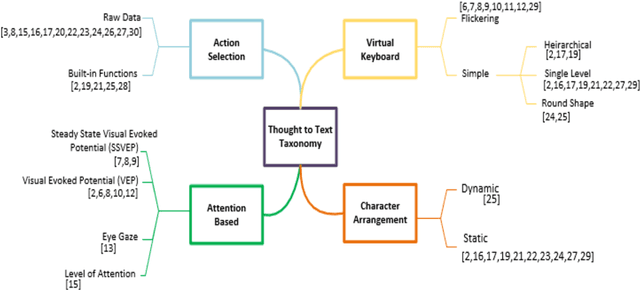
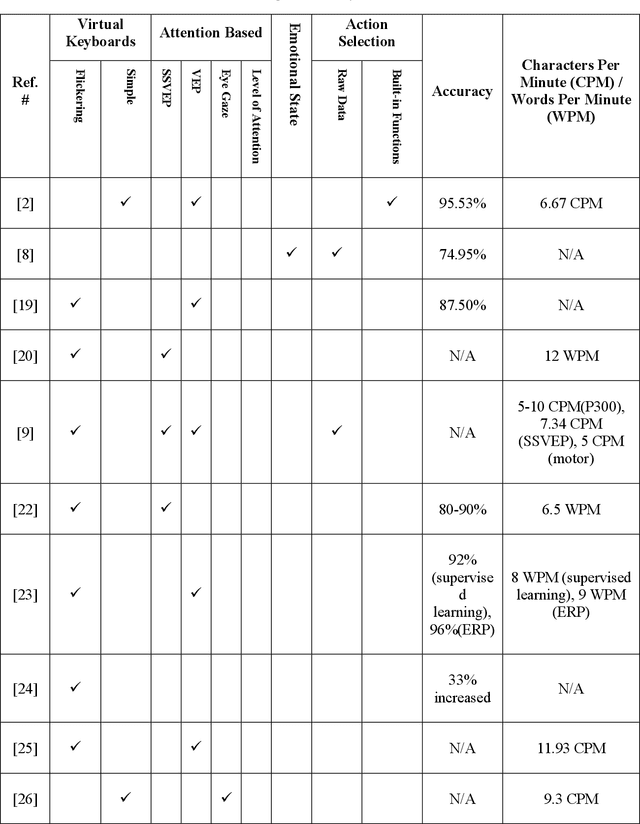
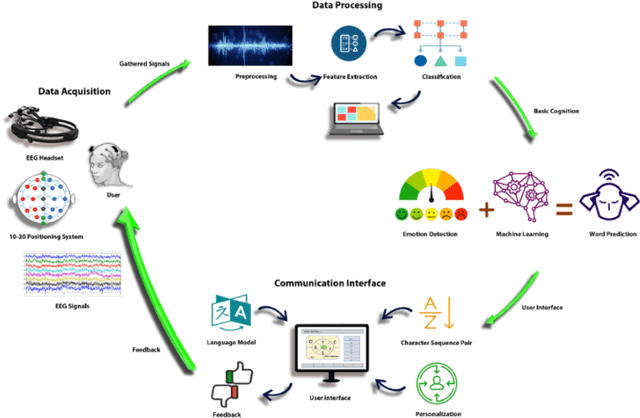

Brain Computer Interface (BCI) helps in processing and extraction of useful information from the acquired brain signals having applications in diverse fields such as military, medicine, neuroscience, and rehabilitation. BCI has been used to support paralytic patients having speech impediments with severe disabilities. To help paralytic patients communicate with ease, BCI based systems convert silent speech (thoughts) to text. However, these systems have an inconvenient graphical user interface, high latency, limited typing speed, and low accuracy rate. Apart from these limitations, the existing systems do not incorporate the inevitable factor of a patient's emotional states and sentiment analysis. The proposed system EmoWrite implements a dynamic keyboard with contextualized appearance of characters reducing the traversal time and improving the utilization of the screen space. The proposed system has been evaluated and compared with the existing systems for accuracy, convenience, sentimental analysis, and typing speed. This system results in 6.58 Words Per Minute (WPM) and 31.92 Characters Per Minute (CPM) with an accuracy of 90.36 percent. EmoWrite also gives remarkable results when it comes to the integration of emotional states. Its Information Transfer Rate (ITR) is also high as compared to other systems i.e., 87.55 bits per min with commands and 72.52 bits per min for letters. Furthermore, it provides easy to use interface with a latency of 2.685 sec.
SDVTracker: Real-Time Multi-Sensor Association and Tracking for Self-Driving Vehicles
Mar 09, 2020
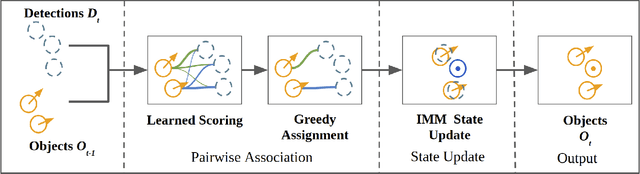
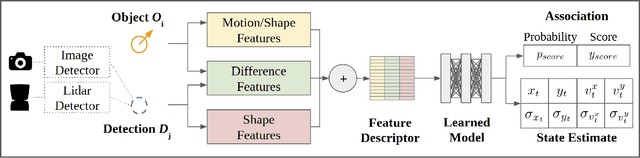
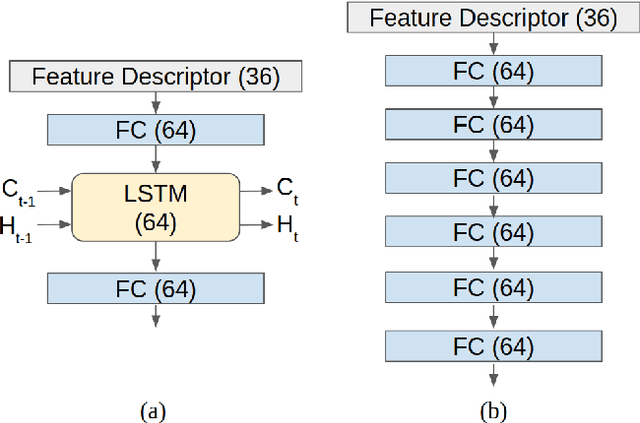
Accurate motion state estimation of Vulnerable Road Users (VRUs), is a critical requirement for autonomous vehicles that navigate in urban environments. Due to their computational efficiency, many traditional autonomy systems perform multi-object tracking using Kalman Filters which frequently rely on hand-engineered association. However, such methods fail to generalize to crowded scenes and multi-sensor modalities, often resulting in poor state estimates which cascade to inaccurate predictions. We present a practical and lightweight tracking system, SDVTracker, that uses a deep learned model for association and state estimation in conjunction with an Interacting Multiple Model (IMM) filter. The proposed tracking method is fast, robust and generalizes across multiple sensor modalities and different VRU classes. In this paper, we detail a model that jointly optimizes both association and state estimation with a novel loss, an algorithm for determining ground-truth supervision, and a training procedure. We show this system significantly outperforms hand-engineered methods on a real-world urban driving dataset while running in less than 2.5 ms on CPU for a scene with 100 actors, making it suitable for self-driving applications where low latency and high accuracy is critical.
Computation harvesting in road traffic dynamics
Nov 21, 2020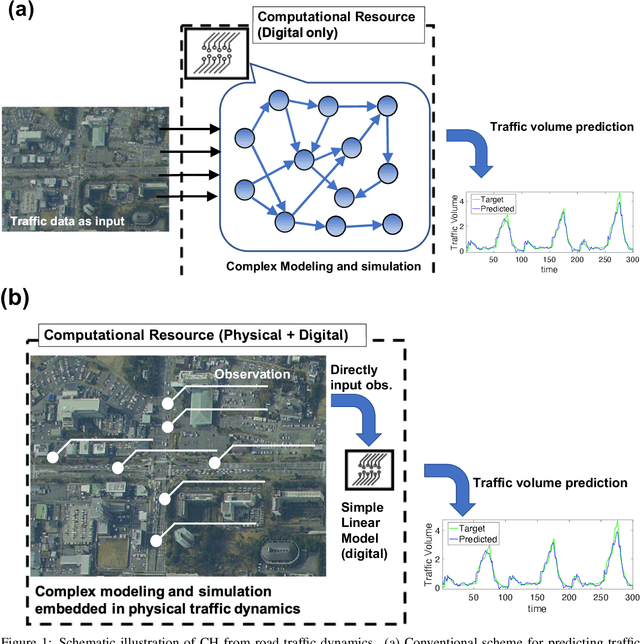

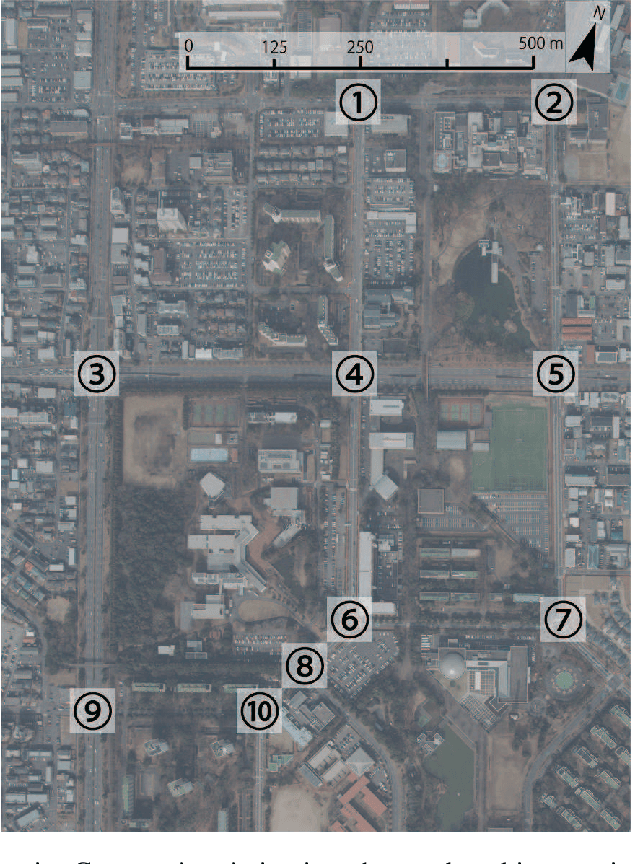
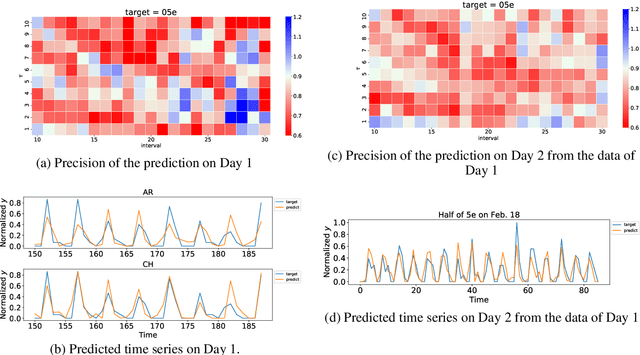
Owing to recent advances in artificial intelligence and internet of things (IoT) technologies, collected big data facilitates high computational performance, while its computational resources and energy cost are large. Moreover, data are often collected but not used. To solve these problems, we propose a framework for a computational model that follows a natural computational system, such as the human brain, and does not rely heavily on electronic computers. In particular, we propose a methodology based on the concept of `computation harvesting', which uses IoT data collected from rich sensors and leaves most of the computational processes to real-world phenomena as collected data. This aspect assumes that large-scale computations can be fast and resilient. Herein, we perform prediction tasks using real-world road traffic data to show the feasibility of computation harvesting. First, we show that the substantial computation in traffic flow is resilient against sensor failure and real-time traffic changes due to several combinations of harvesting from spatiotemporal dynamics to synthesize specific patterns. Next, we show the practicality of this method as a real-time prediction because of its low computational cost. Finally, we show that, compared to conventional methods, our method requires lower resources while providing a comparable performance.
Treewidth-Aware Complexity in ASP: Not all Positive Cycles are Equally Hard
Jul 09, 2020
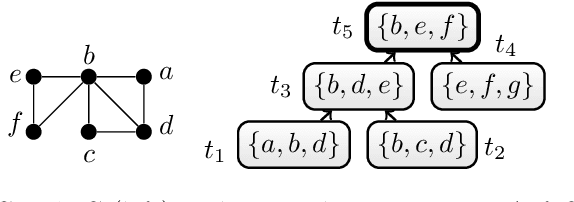
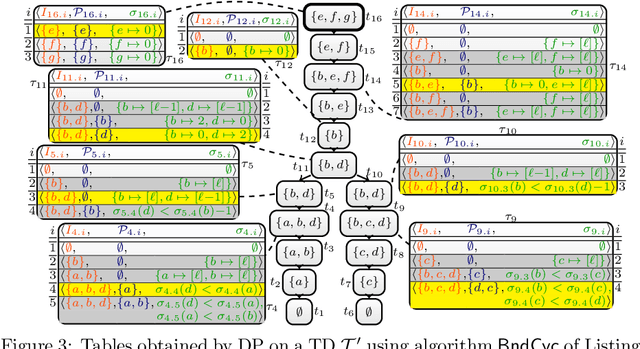
It is well-know that deciding consistency for normal answer set programs (ASP) is NP-complete, thus, as hard as the satisfaction problem for classical propositional logic (SAT). The best algorithms to solve these problems take exponential time in the worst case. The exponential time hypothesis (ETH) implies that this result is tight for SAT, that is, SAT cannot be solved in subexponential time. This immediately establishes that the result is also tight for the consistency problem for ASP. However, accounting for the treewidth of the problem, the consistency problem for ASP is slightly harder than SAT: while SAT can be solved by an algorithm that runs in exponential time in the treewidth k, it was recently shown that ASP requires exponential time in k \cdot log(k). This extra cost is due checking that there are no self-supported true atoms due to positive cycles in the program. In this paper, we refine the above result and show that the consistency problem for ASP can be solved in exponential time in k \cdot log({\lambda}) where {\lambda} is the minimum between the treewidth and the size of the largest strongly-connected component in the positive dependency graph of the program. We provide a dynamic programming algorithm that solves the problem and a treewidth-aware reduction from ASP to SAT that adhere to the above limit.
A 3D Non-stationary MmWave Channel Model for Vacuum Tube Ultra-High-Speed Train Channels
Jan 17, 2021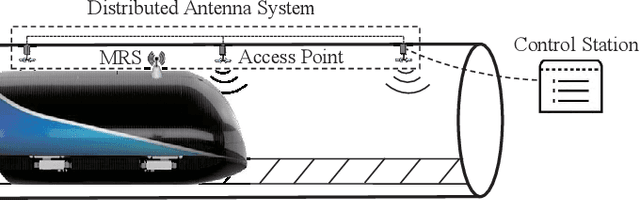
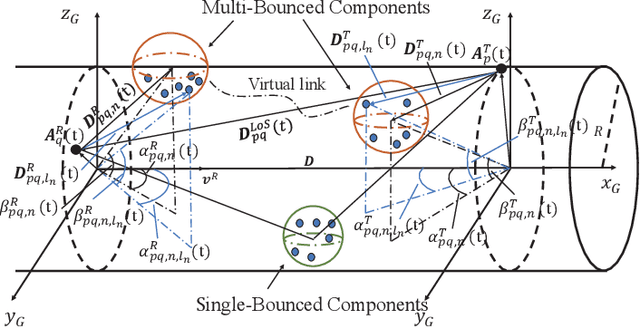
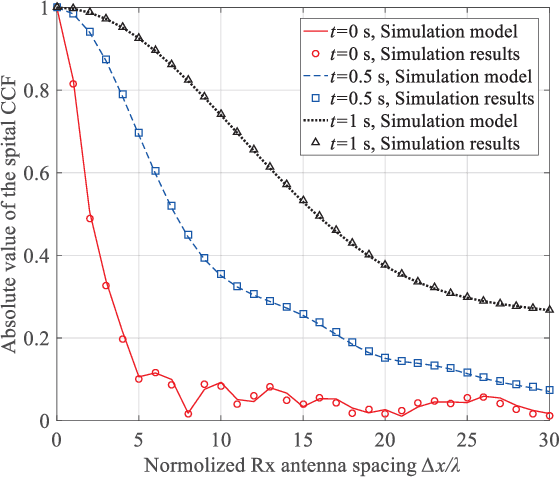
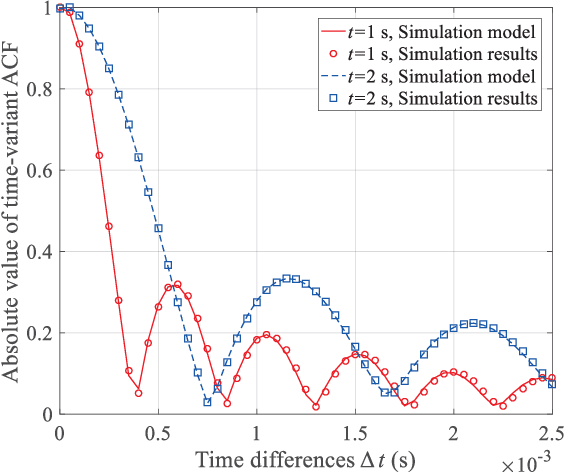
As a potential development direction of future transportation, the vacuum tube ultra-high-speed train (UHST) wireless communication systems have newly different channel characteristics from existing high-speed train (HST) scenarios. In this paper, a three-dimensional non-stationary millimeter wave (mmWave) geometry-based stochastic model (GBSM) is proposed to investigate the channel characteristics of UHST channels in vacuum tube scenarios, taking into account the waveguide effect and the impact of tube wall roughness on channel. Then, based on the proposed model, some important time-variant channel statistical properties are studied and compared with those in existing HST and tunnel channels. The results obtained show that the multipath effect in vacuum tube scenarios will be more obvious than tunnel scenarios but less than existing HST scenarios, which will provide some insights for future research on vacuum tube UHST wireless communications.