 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic detection of abnormal EEG signals using wavelet feature extraction and gradient boosting decision tree
Dec 18, 2020


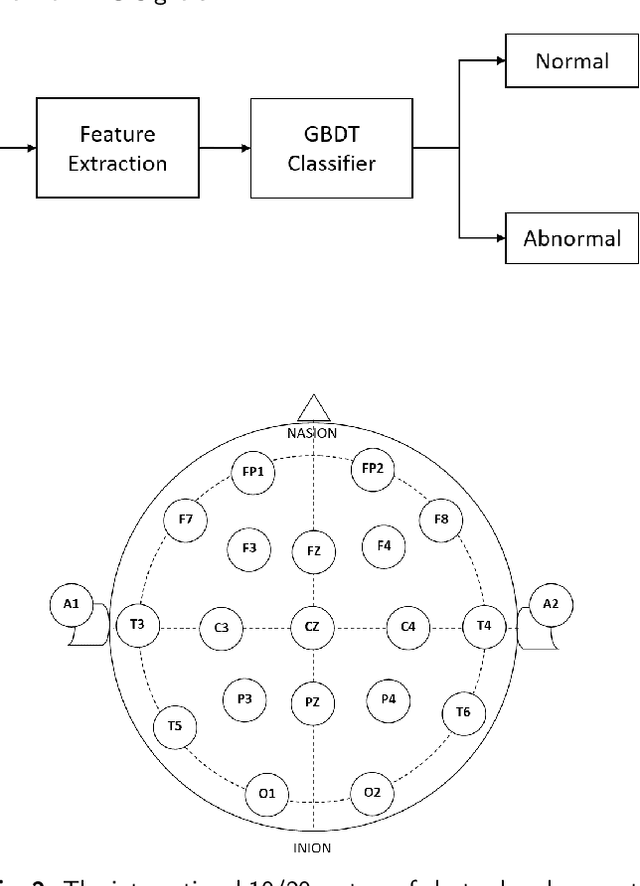
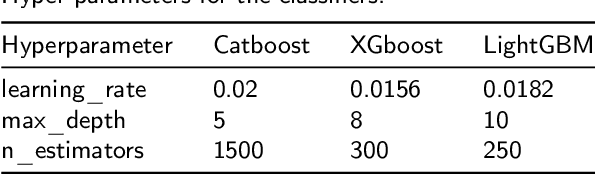
Electroencephalography is frequently used for diagnostic evaluation of various brain-related disorders due to its excellent resolution, non-invasive nature and low cost. However, manual analysis of EEG signals could be strenuous and a time-consuming process for experts. It requires long training time for physicians to develop expertise in it and additionally experts have low inter-rater agreement (IRA) among themselves. Therefore, many Computer Aided Diagnostic (CAD) based studies have considered the automation of interpreting EEG signals to alleviate the workload and support the final diagnosis. In this paper, we present an automatic binary classification framework for brain signals in multichannel EEG recordings. We propose to use Wavelet Packet Decomposition (WPD) techniques to decompose the EEG signals into frequency sub-bands and extract a set of statistical features from each of the selected coefficients. Moreover, we propose a novel method to reduce the dimension of the feature space without compromising the quality of the extracted features. The extracted features are classified using different Gradient Boosting Decision Tree (GBDT) based classification frameworks, which are CatBoost, XGBoost and LightGBM. We used Temple University Hospital EEG Abnormal Corpus V2.0.0 to test our proposed technique. We found that CatBoost classifier achieves the binary classification accuracy of 87.68%, and outperforms state-of-the-art techniques on the same dataset by more than 1% in accuracy and more than 3% in sensitivity. The obtained results in this research provide important insights into the usefulness of WPD feature extraction and GBDT classifiers for EEG classification.
NuCLS: A scalable crowdsourcing, deep learning approach and dataset for nucleus classification, localization and segmentation
Feb 18, 2021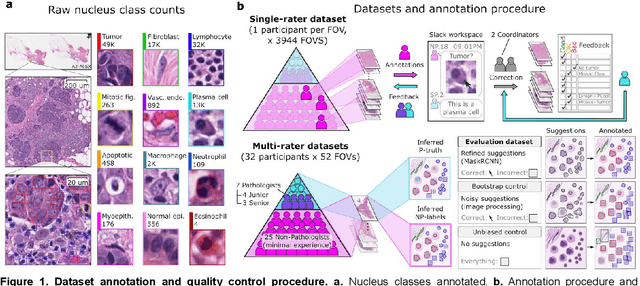
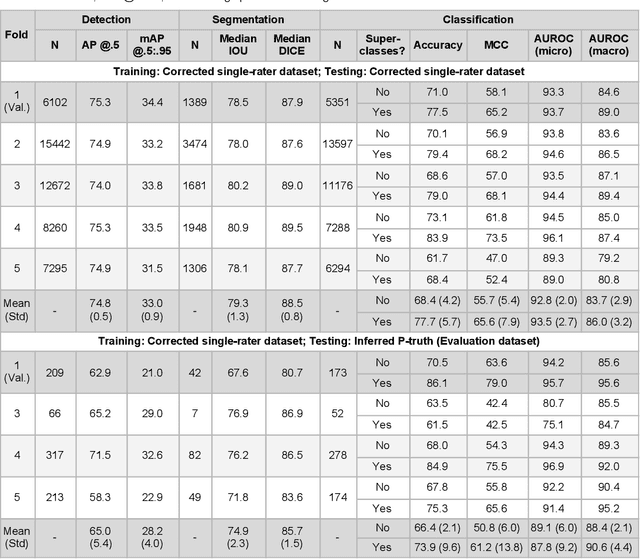
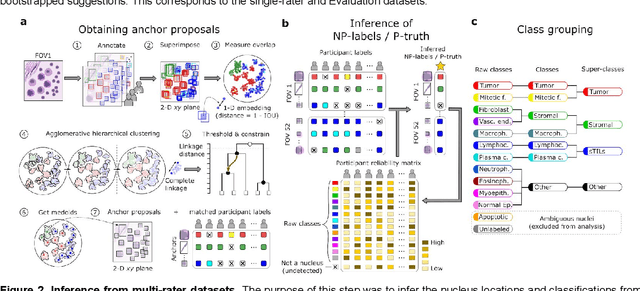
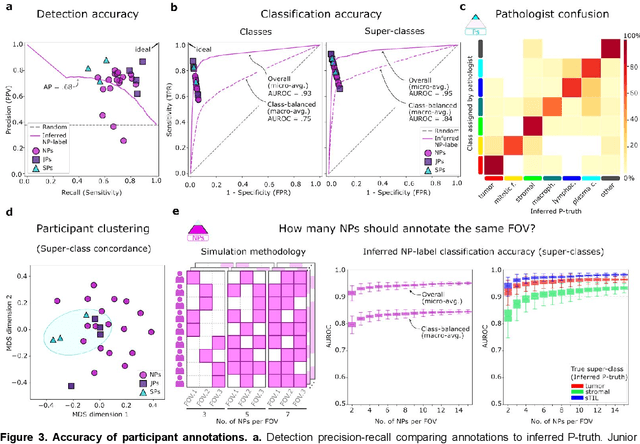
High-resolution mapping of cells and tissue structures provides a foundation for developing interpretable machine-learning models for computational pathology. Deep learning algorithms can provide accurate mappings given large numbers of labeled instances for training and validation. Generating adequate volume of quality labels has emerged as a critical barrier in computational pathology given the time and effort required from pathologists. In this paper we describe an approach for engaging crowds of medical students and pathologists that was used to produce a dataset of over 220,000 annotations of cell nuclei in breast cancers. We show how suggested annotations generated by a weak algorithm can improve the accuracy of annotations generated by non-experts and can yield useful data for training segmentation algorithms without laborious manual tracing. We systematically examine interrater agreement and describe modifications to the MaskRCNN model to improve cell mapping. We also describe a technique we call Decision Tree Approximation of Learned Embeddings (DTALE) that leverages nucleus segmentations and morphologic features to improve the transparency of nucleus classification models. The annotation data produced in this study are freely available for algorithm development and benchmarking at: https://sites.google.com/view/nucls.
Personalized TV Recommendation: Fusing User Behavior and Preferences
Aug 30, 2020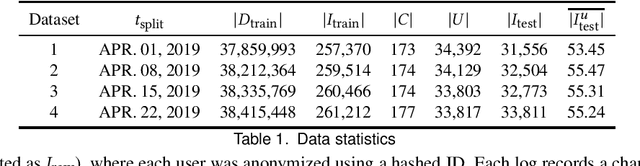
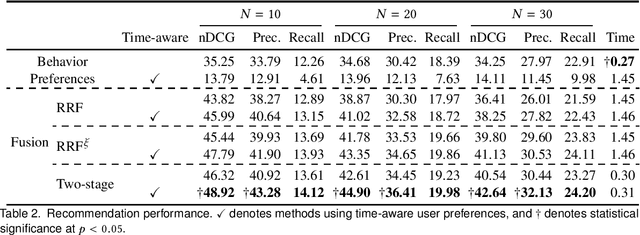
In this paper, we propose a two-stage ranking approach for recommending linear TV programs. The proposed approach first leverages user viewing patterns regarding time and TV channels to identify potential candidates for recommendation and then further leverages user preferences to rank these candidates given textual information about programs. To evaluate the method, we conduct empirical studies on a real-world TV dataset, the results of which demonstrate the superior performance of our model in terms of both recommendation accuracy and time efficiency.
A textual transform of multivariate time-series for prognostics
Sep 19, 2017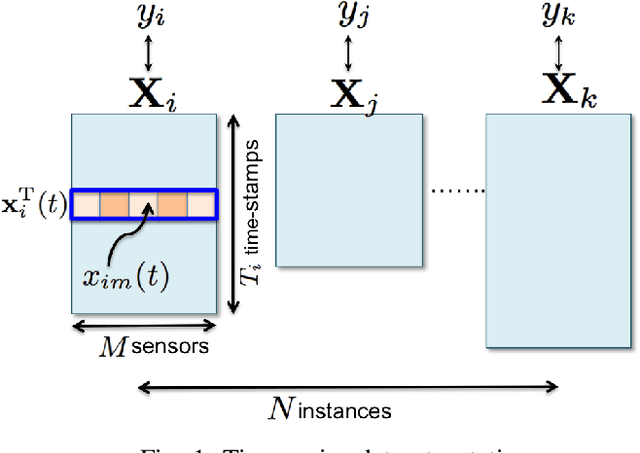
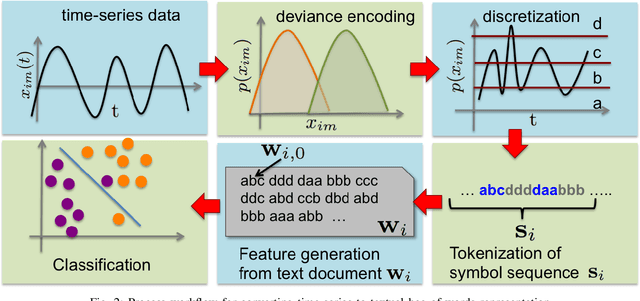
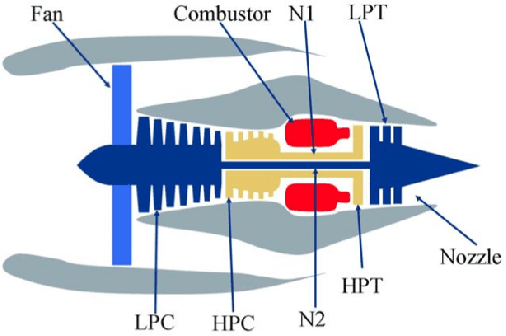
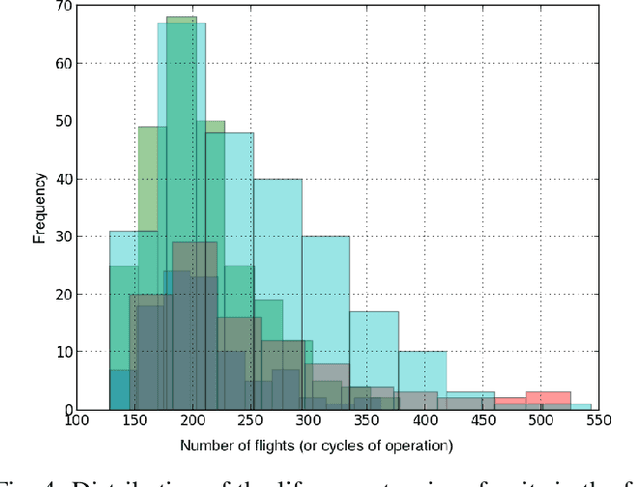
Prognostics or early detection of incipient faults is an important industrial challenge for condition-based and preventive maintenance. Physics-based approaches to modeling fault progression are infeasible due to multiple interacting components, uncontrolled environmental factors and observability constraints. Moreover, such approaches to prognostics do not generalize to new domains. Consequently, domain-agnostic data-driven machine learning approaches to prognostics are desirable. Damage progression is a path-dependent process and explicitly modeling the temporal patterns is critical for accurate estimation of both the current damage state and its progression leading to total failure. In this paper, we present a novel data-driven approach to prognostics that employs a novel textual representation of multivariate temporal sensor observations for predicting the future health state of the monitored equipment early in its life. This representation enables us to utilize well-understood concepts from text-mining for modeling, prediction and understanding distress patterns in a domain agnostic way. The approach has been deployed and successfully tested on large scale multivariate time-series data from commercial aircraft engines. We report experiments on well-known publicly available benchmark datasets and simulation datasets. The proposed approach is shown to be superior in terms of prediction accuracy, lead time to prediction and interpretability.
Variational Dynamic Mixtures
Oct 20, 2020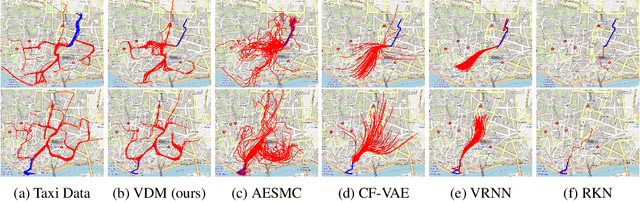
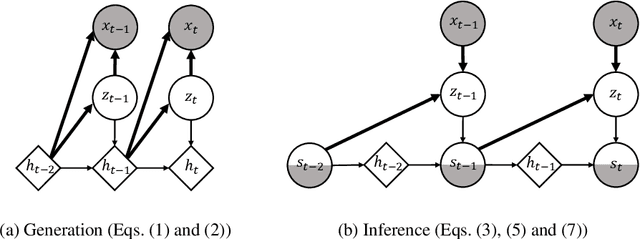


Deep probabilistic time series forecasting models have become an integral part of machine learning. While several powerful generative models have been proposed, we provide evidence that their associated inference models are oftentimes too limited and cause the generative model to predict mode-averaged dynamics. Modeaveraging is problematic since many real-world sequences are highly multi-modal, and their averaged dynamics are unphysical (e.g., predicted taxi trajectories might run through buildings on the street map). To better capture multi-modality, we develop variational dynamic mixtures (VDM): a new variational family to infer sequential latent variables. The VDM approximate posterior at each time step is a mixture density network, whose parameters come from propagating multiple samples through a recurrent architecture. This results in an expressive multi-modal posterior approximation. In an empirical study, we show that VDM outperforms competing approaches on highly multi-modal datasets from different domains.
Blending MPC & Value Function Approximation for Efficient Reinforcement Learning
Dec 10, 2020
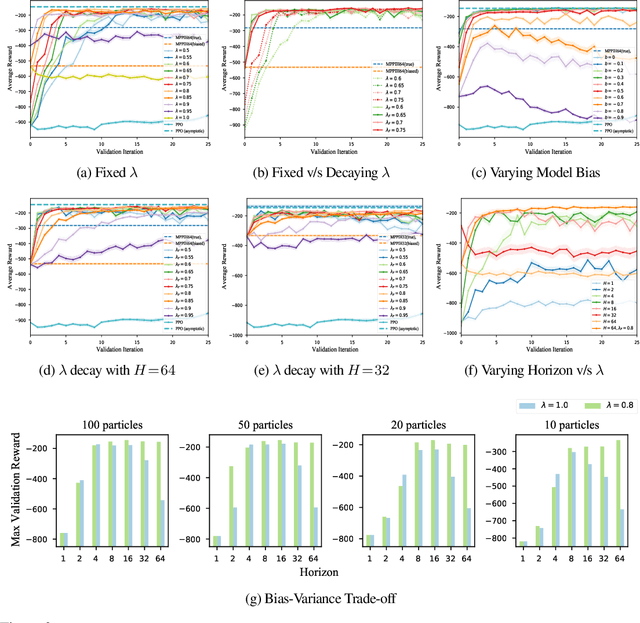
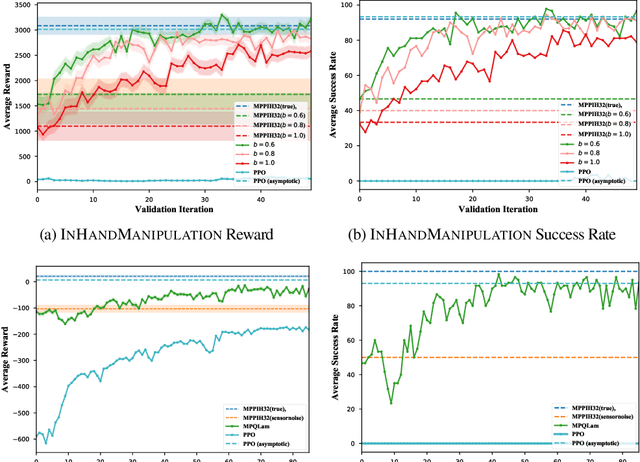
Model-Predictive Control (MPC) is a powerful tool for controlling complex, real-world systems that uses a model to make predictions about future behavior. For each state encountered, MPC solves an online optimization problem to choose a control action that will minimize future cost. This is a surprisingly effective strategy, but real-time performance requirements warrant the use of simple models. If the model is not sufficiently accurate, then the resulting controller can be biased, limiting performance. We present a framework for improving on MPC with model-free reinforcement learning (RL). The key insight is to view MPC as constructing a series of local Q-function approximations. We show that by using a parameter $\lambda$, similar to the trace decay parameter in TD($\lambda$), we can systematically trade-off learned value estimates against the local Q-function approximations. We present a theoretical analysis that shows how error from inaccurate models in MPC and value function estimation in RL can be balanced. We further propose an algorithm that changes $\lambda$ over time to reduce the dependence on MPC as our estimates of the value function improve, and test the efficacy our approach on challenging high-dimensional manipulation tasks with biased models in simulation. We demonstrate that our approach can obtain performance comparable with MPC with access to true dynamics even under severe model bias and is more sample efficient as compared to model-free RL.
The Unsupervised Method of Vessel Movement Trajectory Prediction
Jul 28, 2020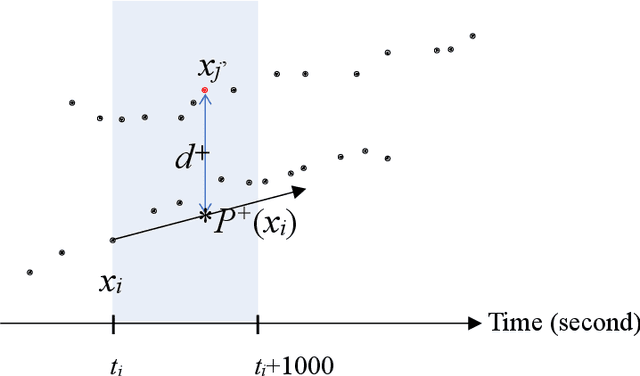

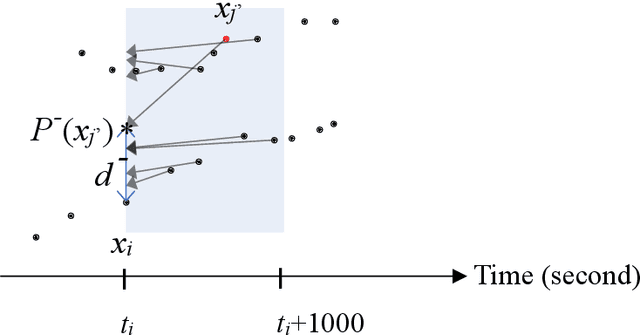

In real-world application scenarios, it is crucial for marine navigators and security analysts to predict vessel movement trajectories at sea based on the Automated Identification System (AIS) data in a given time span. This article presents an unsupervised method of ship movement trajectory prediction which represents the data in a three-dimensional space which consists of time difference between points, the scaled error distance between the tested and its predicted forward and backward locations, and the space-time angle. The representation feature space reduces the search scope for the next point to a collection of candidates which fit the local path prediction well, and therefore improve the accuracy. Unlike most statistical learning or deep learning methods, the proposed clustering-based trajectory reconstruction method does not require computationally expensive model training. This makes real-time reliable and accurate prediction feasible without using a training set. Our results show that the most prediction trajectories accurately consist of the true vessel paths.
BW-EDA-EEND: Streaming End-to-End Neural Speaker Diarization for a Variable Number of Speakers
Nov 05, 2020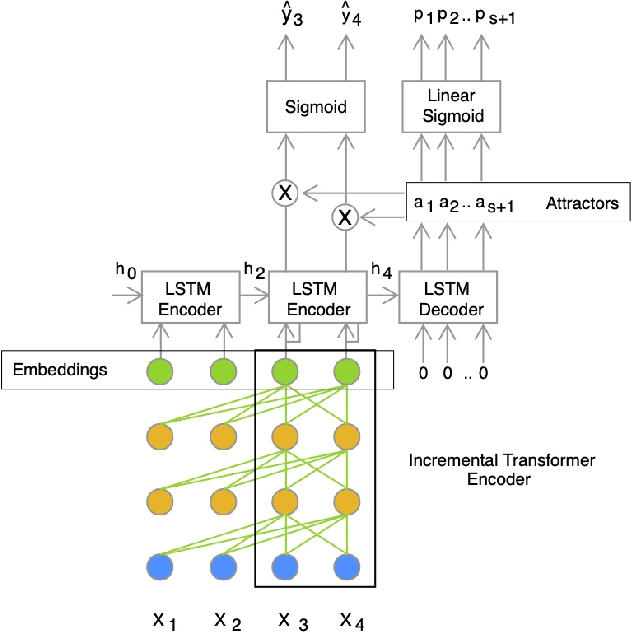
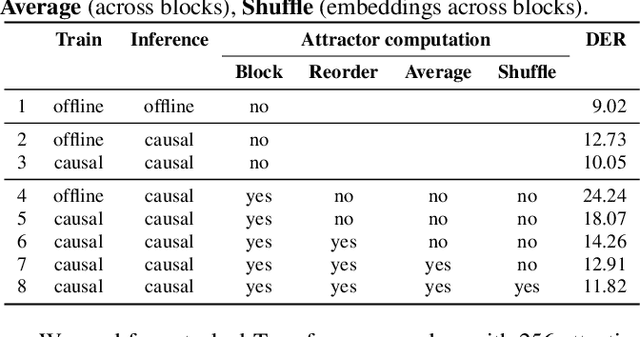
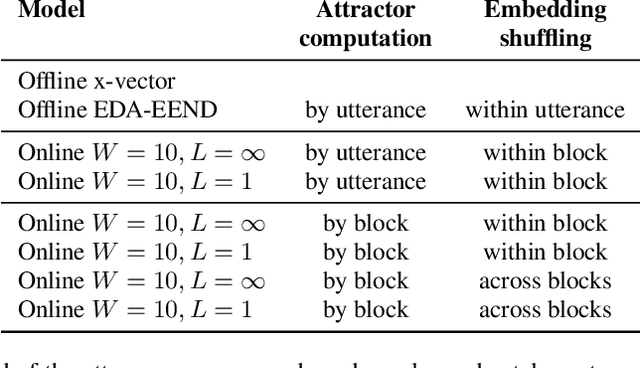
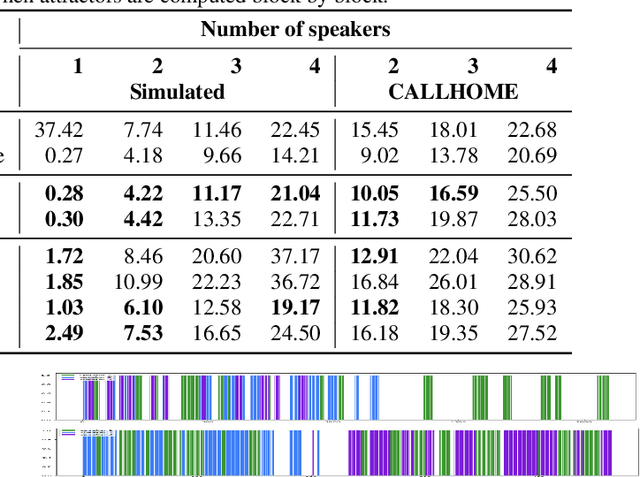
We present a novel online end-to-end neural diarization system, BW-EDA-EEND, that processes data incrementally for a variable number of speakers. The system is based on the EDA architecture of Horiguchi et al., but utilizes the incremental Transformer encoder, attending only to its left contexts and using block-level recurrence in the hidden states to carry information from block to block, making the algorithm complexity linear in time. We propose two variants of it. For unlimited-latency BW-EDA-EEND, which processes inputs in linear time, we show only moderate degradation for up to two speakers using a context size of 10 seconds compared to offline EDA-EEND. With more than two speakers, the accuracy gap between online and offline grows, but it still outperforms a baseline offline clustering diarization system for one to four speakers with unlimited context size, and shows comparable accuracy with context size of 10 seconds. For limited-latency BW-EDA-EEND, which produces diarization outputs block-by-block as audio arrives, we show accuracy comparable to the offline clustering-based system.
SpecTr: Spectral Transformer for Hyperspectral Pathology Image Segmentation
Mar 05, 2021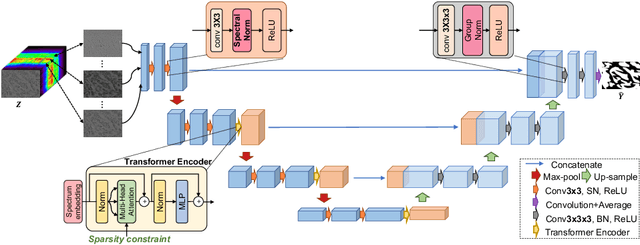
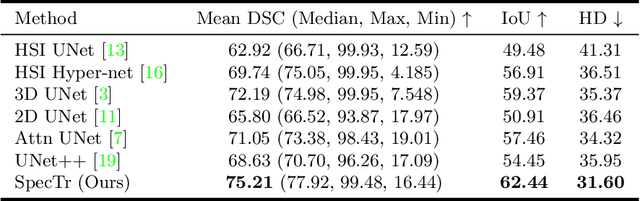
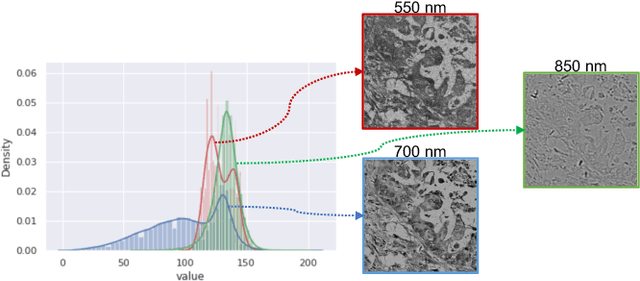
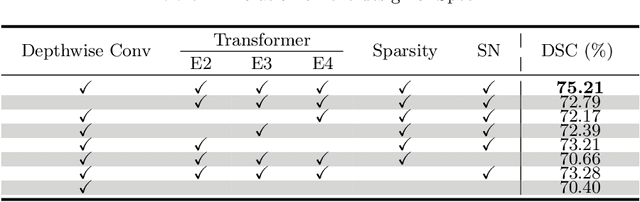
Hyperspectral imaging (HSI) unlocks the huge potential to a wide variety of applications relied on high-precision pathology image segmentation, such as computational pathology and precision medicine. Since hyperspectral pathology images benefit from the rich and detailed spectral information even beyond the visible spectrum, the key to achieve high-precision hyperspectral pathology image segmentation is to felicitously model the context along high-dimensional spectral bands. Inspired by the strong context modeling ability of transformers, we hereby, for the first time, formulate the contextual feature learning across spectral bands for hyperspectral pathology image segmentation as a sequence-to-sequence prediction procedure by transformers. To assist spectral context learning procedure, we introduce two important strategies: (1) a sparsity scheme enforces the learned contextual relationship to be sparse, so as to eliminates the distraction from the redundant bands; (2) a spectral normalization, a separate group normalization for each spectral band, mitigates the nuisance caused by heterogeneous underlying distributions of bands. We name our method Spectral Transformer (SpecTr), which enjoys two benefits: (1) it has a strong ability to model long-range dependency among spectral bands, and (2) it jointly explores the spatial-spectral features of HSI. Experiments show that SpecTr outperforms other competing methods in a hyperspectral pathology image segmentation benchmark without the need of pre-training. Code is available at https://github.com/hfut-xc-yun/SpecTr.
A Hybrid Dynamical Modeling Framework for Shape Memory Alloy Wire Actuated Structures
Mar 05, 2021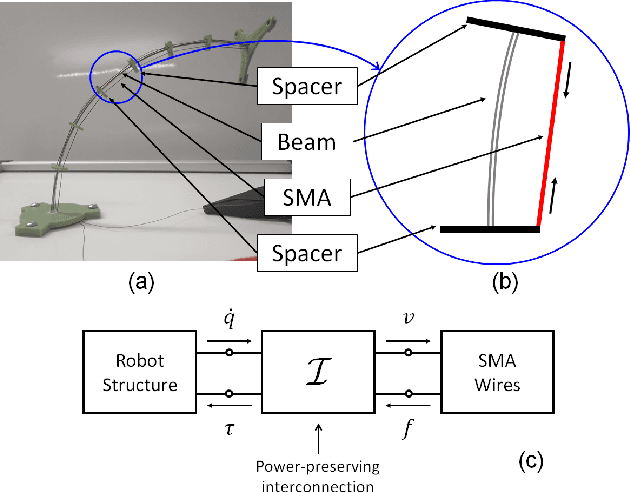
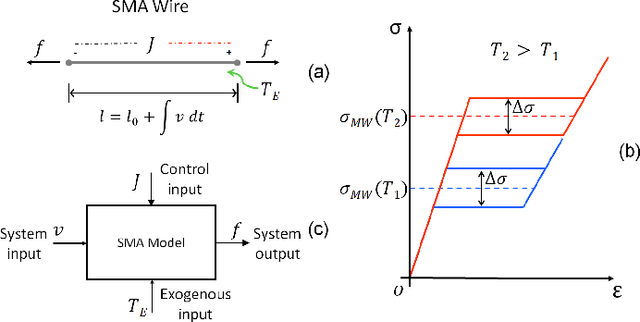
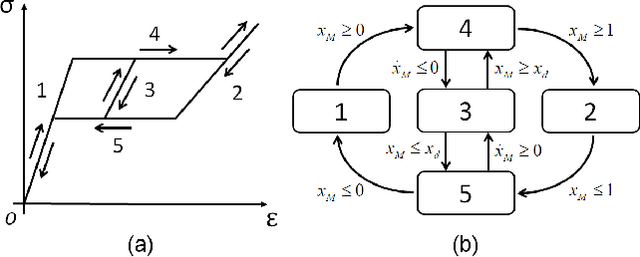
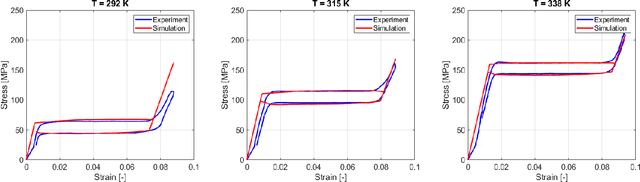
In this paper, a hybrid model for single-crystal Shape Memory Alloy (SMA) wire actuators is presented. The result is based on a mathematical reformulation of the M\"uller-Achenbach-Seelecke (MAS) model, which provides an accurate and interconnection-oriented description of the SMA hysteretic response. The strong nonlinearity and high numerical stiffness of the MAS model, however, hinder its practical use for simulation and control of complex SMA-driven systems. The main idea behind the hybrid reformulation is based on dividing the mechanical hysteresis of the SMA into five operating modes, each one representing a different physical state of the material. By properly deriving the switching conditions among those modes in a physically-consistent way, the MAS model is effectively reformulated within a hybrid dynamical setting. The main advantage of the hybrid reformulation is the possibility of describing the material dynamics with a simplified set of state equations while maintaining all benefits of the physics-based description offered by the MAS model After describing the novel approach, simulation studies are conducted on a flexible robotic module actuated by protagonist-antagonist SMA wires. Through comparative numerical analysis, it is shown how the hybrid model provides the same accuracy as the MAS model while saving up to 80% of the simulation time. Moreover, the new modeling framework opens up the possibility of addressing SMA control from a hybrid systems perspective.