 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Image Reconstruction via Variational Network for Real-Time Hand-Held Sound-Speed Imaging
Jul 19, 2018
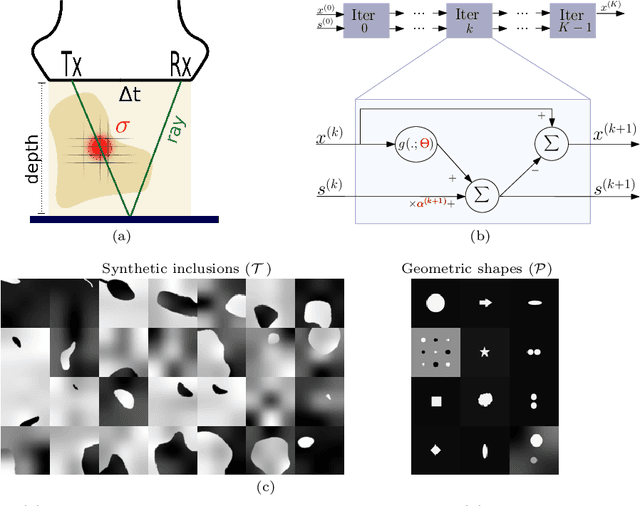

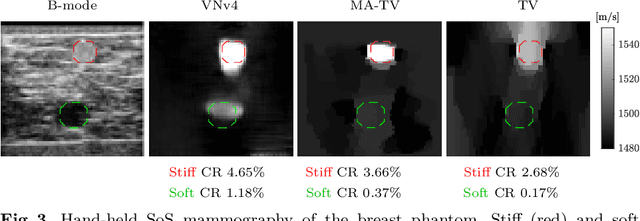
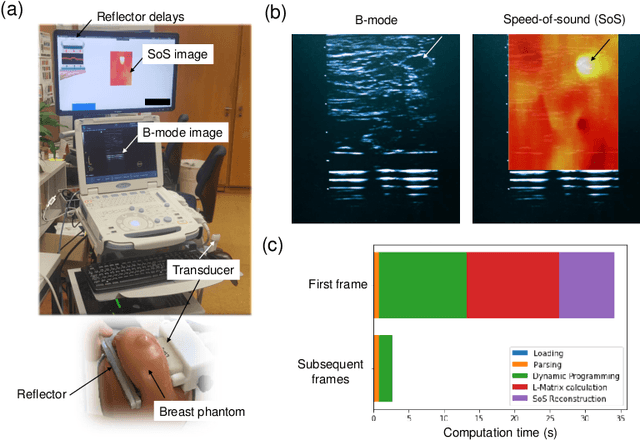
Speed-of-sound is a biomechanical property for quantitative tissue differentiation, with great potential as a new ultrasound-based image modality. A conventional ultrasound array transducer can be used together with an acoustic mirror, or so-called reflector, to reconstruct sound-speed images from time-of-flight measurements to the reflector collected between transducer element pairs, which constitutes a challenging problem of limited-angle computed tomography. For this problem, we herein present a variational network based image reconstruction architecture that is based on optimization loop unrolling, and provide an efficient training protocol of this network architecture on fully synthetic inclusion data. Our results indicate that the learned model presents good generalization ability, being able to reconstruct images with significantly different statistics compared to the training set. Complex inclusion geometries were shown to be successfully reconstructed, also improving over the prior-art by 23% in reconstruction error and by 10% in contrast on synthetic data. In a phantom study, we demonstrated the detection of multiple inclusions that were not distinguishable by prior-art reconstruction, meanwhile improving the contrast by 27% for a stiff inclusion and by 219% for a soft inclusion. Our reconstruction algorithm takes approximately 10ms, enabling its use as a real-time imaging method on an ultrasound machine, for which we are demonstrating an example preliminary setup herein.
Adversarial Attacks and Defenses in Physiological Computing: A Systematic Review
Feb 11, 2021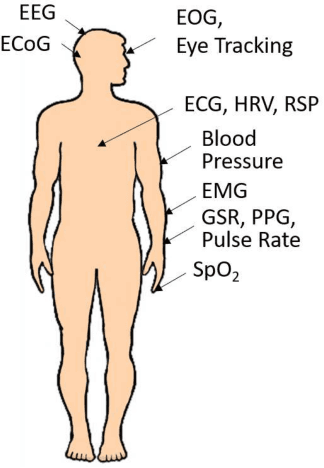
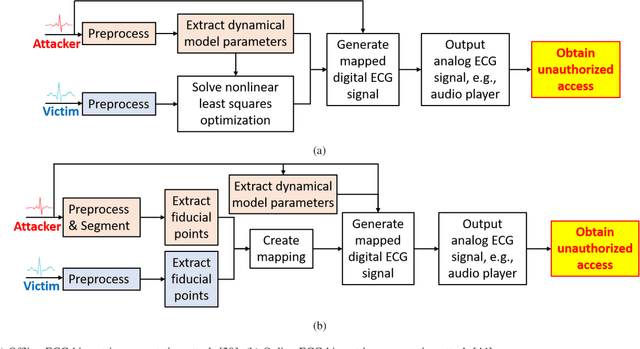
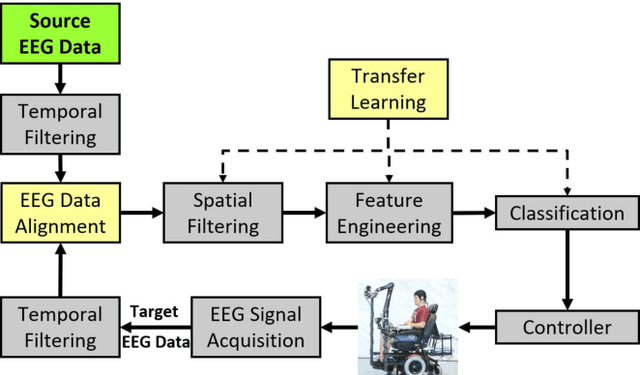
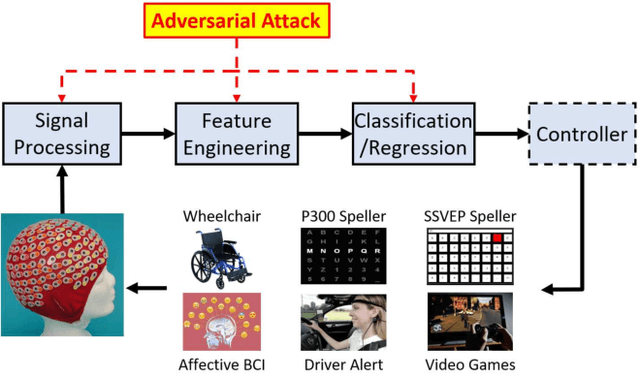
Physiological computing uses human physiological data as system inputs in real time. It includes, or significantly overlaps with, brain-computer interfaces, affective computing, adaptive automation, health informatics, and physiological signal based biometrics. Physiological computing increases the communication bandwidth from the user to the computer, but is also subject to various types of adversarial attacks, in which the attacker deliberately manipulates the training and/or test examples to hijack the machine learning algorithm output, leading to possibly user confusion, frustration, injury, or even death. However, the vulnerability of physiological computing systems has not been paid enough attention to, and there does not exist a comprehensive review on adversarial attacks to it. This paper fills this gap, by providing a systematic review on the main research areas of physiological computing, different types of adversarial attacks and their applications to physiological computing, and the corresponding defense strategies. We hope this review will attract more research interests on the vulnerability of physiological computing systems, and more importantly, defense strategies to make them more secure.
Reflective-Net: Learning from Explanations
Nov 27, 2020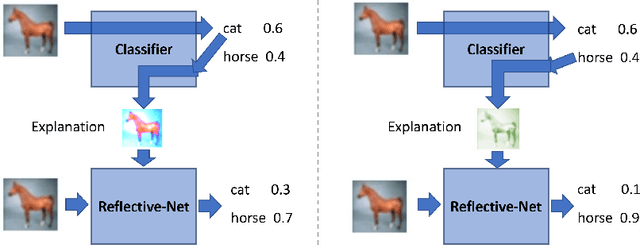
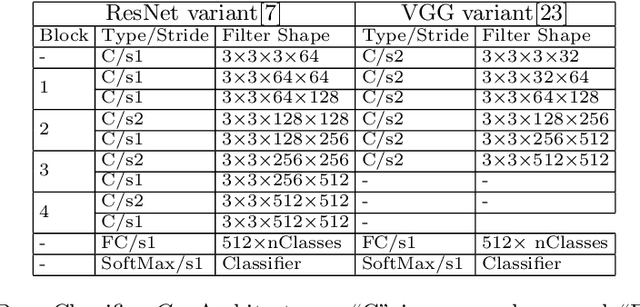
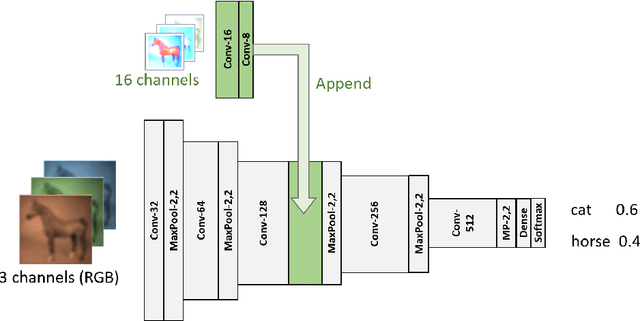
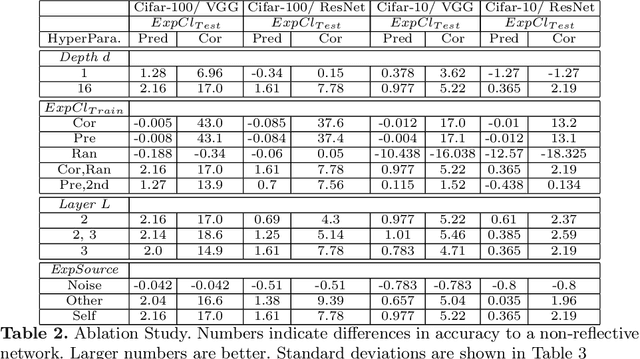
Humans possess a remarkable capability to make fast, intuitive decisions, but also to self-reflect, i.e., to explain to oneself, and to efficiently learn from explanations by others. This work provides the first steps toward mimicking this process by capitalizing on the explanations generated based on existing explanation methods, i.e. Grad-CAM. Learning from explanations combined with conventional labeled data yields significant improvements for classification in terms of accuracy and training time.
EXTRA: Explanation Ranking Datasets for Explainable Recommendation
Feb 20, 2021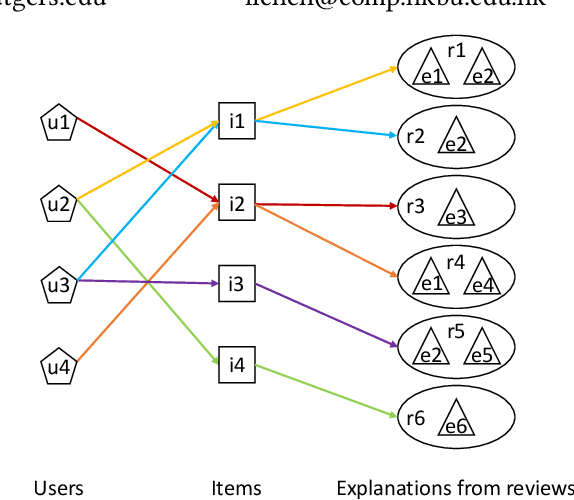

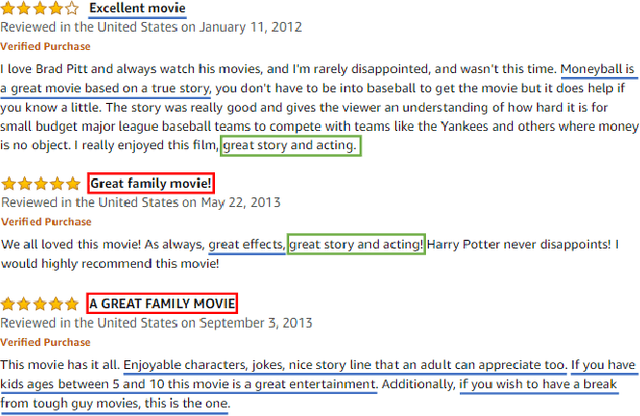
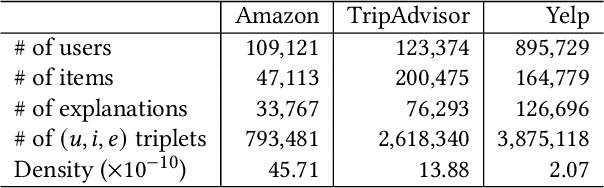
Recently, research on explainable recommender systems (RS) has drawn much attention from both academia and industry, resulting in a variety of explainable models. As a consequence, their evaluation approaches vary from model to model, which makes it quite difficult to compare the explainability of different models. To achieve a standard way of evaluating recommendation explanations, we provide three benchmark datasets for EXplanaTion RAnking (denoted as EXTRA), on which explainability can be measured by ranking-oriented metrics. Constructing such datasets, however, presents great challenges. First, user-item-explanation interactions are rare in existing RS, so how to find alternatives becomes a challenge. Our solution is to identify nearly duplicate or even identical sentences from user reviews. This idea then leads to the second challenge, i.e., how to efficiently categorize the sentences in a dataset into different groups, since it has quadratic runtime complexity to estimate the similarity between any two sentences. To mitigate this issue, we provide a more efficient method based on Locality Sensitive Hashing (LSH) that can detect near-duplicates in sub-linear time for a given query. Moreover, we plan to make our code publicly available, to allow other researchers create their own datasets.
Automatic Volumetric Segmentation of Additive Manufacturing Defects with 3D U-Net
Jan 22, 2021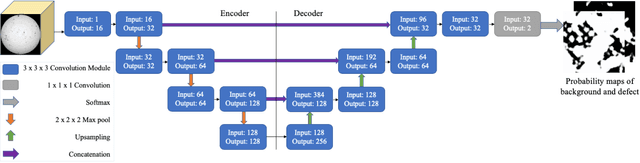
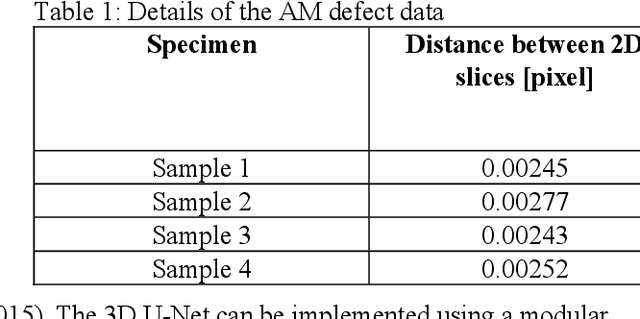

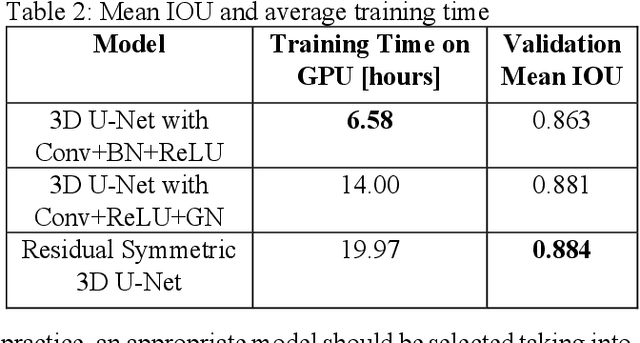
Segmentation of additive manufacturing (AM) defects in X-ray Computed Tomography (XCT) images is challenging, due to the poor contrast, small sizes and variation in appearance of defects. Automatic segmentation can, however, provide quality control for additive manufacturing. Over recent years, three-dimensional convolutional neural networks (3D CNNs) have performed well in the volumetric segmentation of medical images. In this work, we leverage techniques from the medical imaging domain and propose training a 3D U-Net model to automatically segment defects in XCT images of AM samples. This work not only contributes to the use of machine learning for AM defect detection but also demonstrates for the first time 3D volumetric segmentation in AM. We train and test with three variants of the 3D U-Net on an AM dataset, achieving a mean intersection of union (IOU) value of 88.4%.
* Accepted by AAAI 2020 Spring Symposia
Efficient grouping for keypoint detection
Oct 23, 2020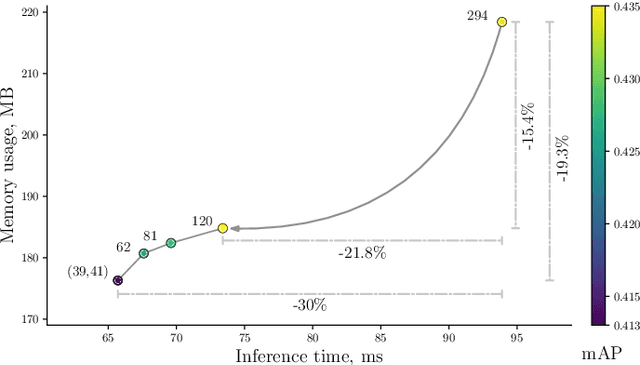
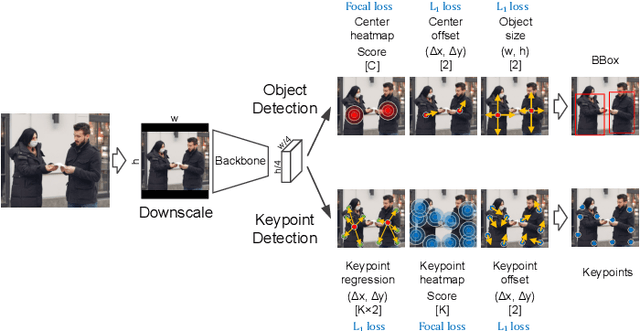
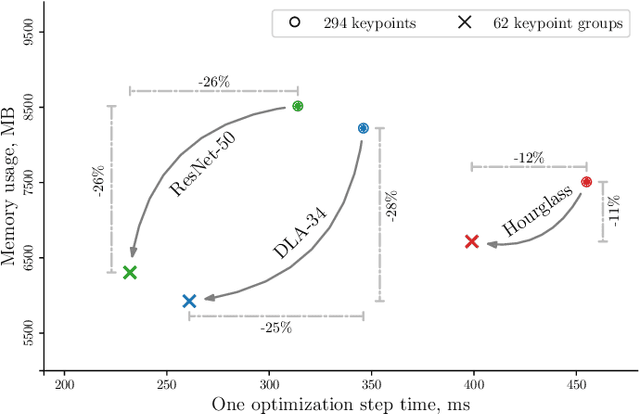
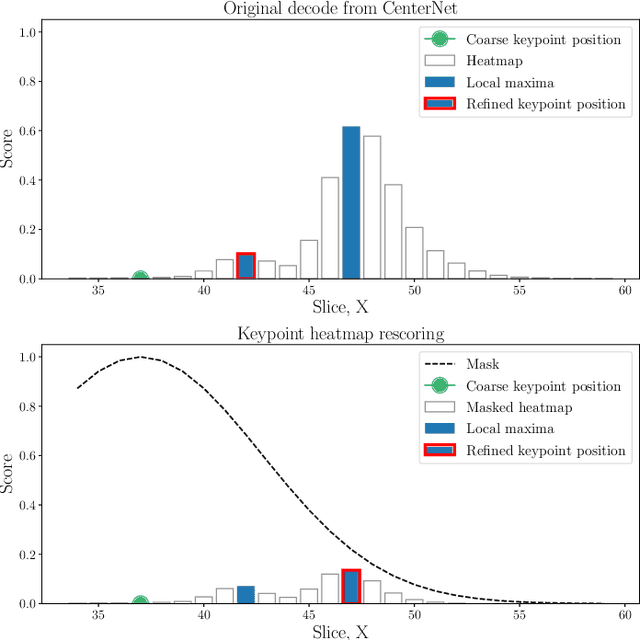
The success of deep neural networks in the traditional keypoint detection task encourages researchers to solve new problems and collect more complex datasets. The size of the DeepFashion2 dataset poses a new challenge on the keypoint detection task, as it comprises 13 clothing categories that span a wide range of keypoints (294 in total). The direct prediction of all keypoints leads to huge memory consumption, slow training, and a slow inference time. This paper studies the keypoint grouping approach and how it affects the performance of the CenterNet architecture. We propose a simple and efficient automatic grouping technique with a powerful post-processing method and apply it to the DeepFashion2 fashion landmark task and the MS COCO pose estimation task. This reduces memory consumption and processing time during inference by up to 19% and 30% respectively, and during the training stage by 28% and 26% respectively, without compromising accuracy.
Explainable Predictive Process Monitoring
Sep 16, 2020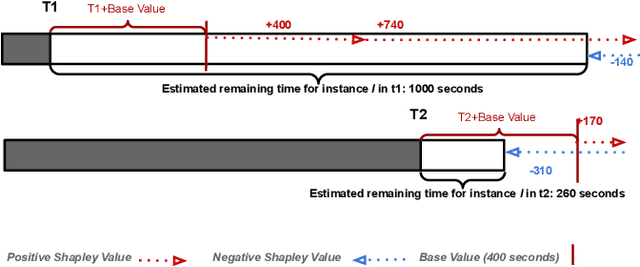
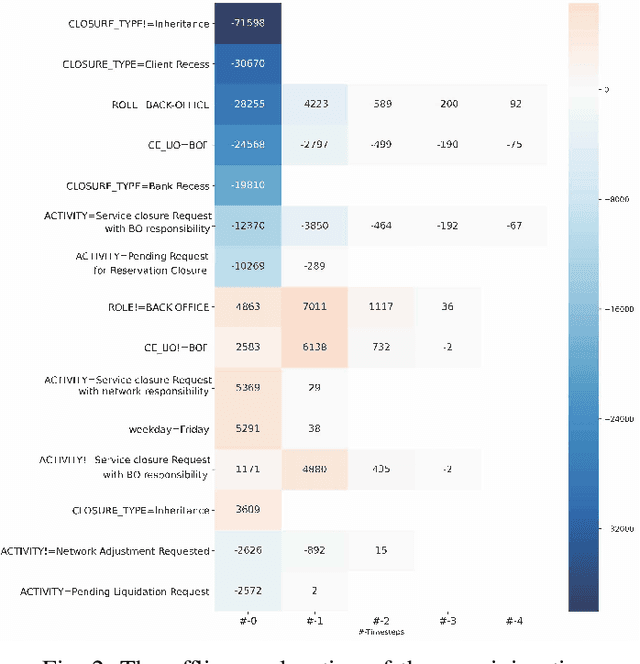
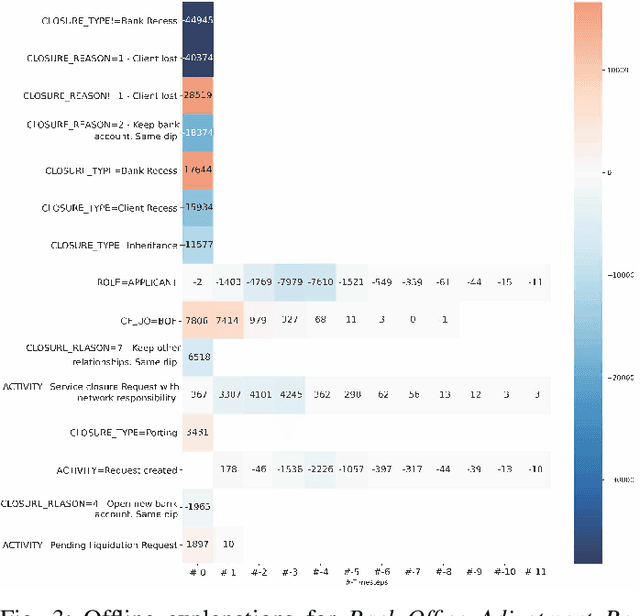
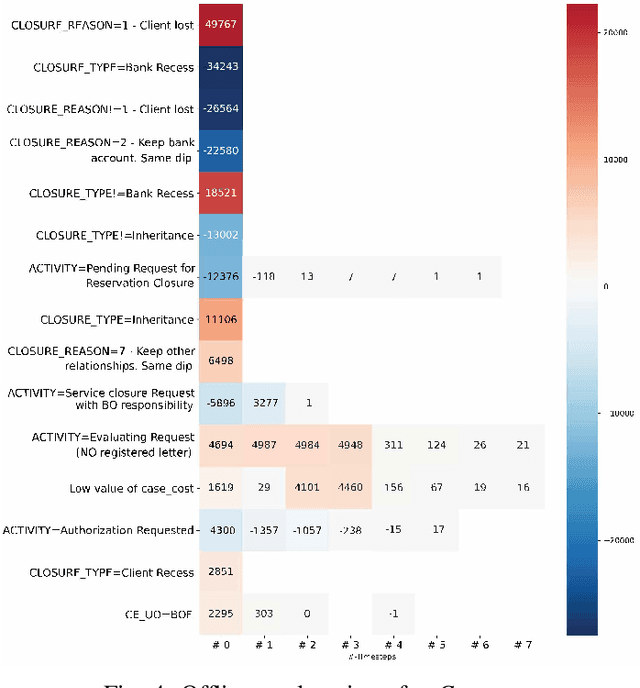
Predictive Business Process Monitoring is becoming an essential aid for organizations, providing online operational support of their processes. This paper tackles the fundamental problem of equipping predictive business process monitoring with explanation capabilities, so that not only the what but also the why is reported when predicting generic KPIs like remaining time, or activity execution. We use the game theory of Shapley Values to obtain robust explanations of the predictions. The approach has been implemented and tested on real-life benchmarks, showing for the first time how explanations can be given in the field of predictive business process monitoring.
Anomaly detection and motif discovery in symbolic representations of time series
Apr 18, 2017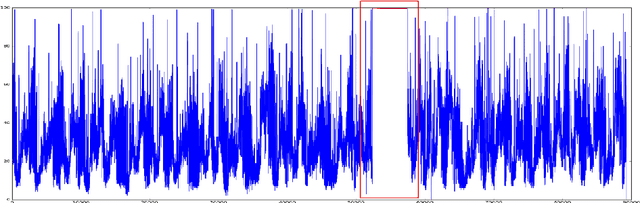
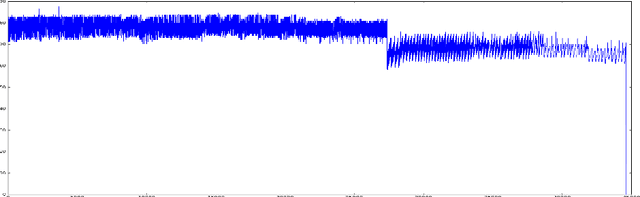
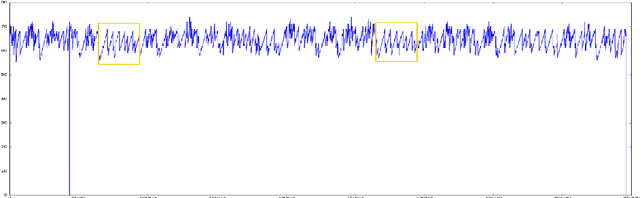
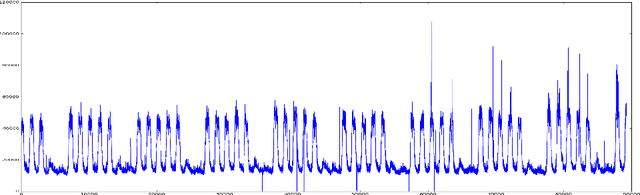
The advent of the Big Data hype and the consistent recollection of event logs and real-time data from sensors, monitoring software and machine configuration has generated a huge amount of time-varying data in about every sector of the industry. Rule-based processing of such data has ceased to be relevant in many scenarios where anomaly detection and pattern mining have to be entirely accomplished by the machine. Since the early 2000s, the de-facto standard for representing time series has been the Symbolic Aggregate approXimation (SAX).In this document, we present a few algorithms using this representation for anomaly detection and motif discovery, also known as pattern mining, in such data. We propose a benchmark of anomaly detection algorithms using data from Cloud monitoring software.
Optimal Conversion of Conventional Artificial Neural Networks to Spiking Neural Networks
Feb 28, 2021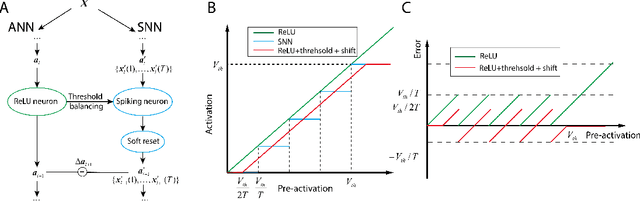
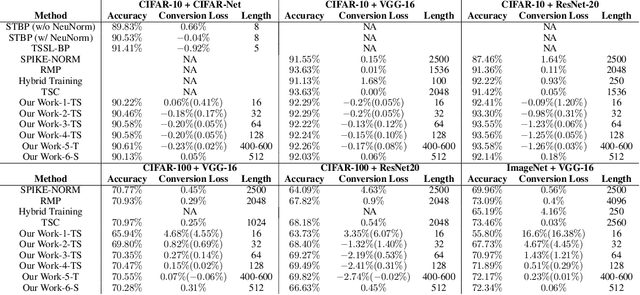
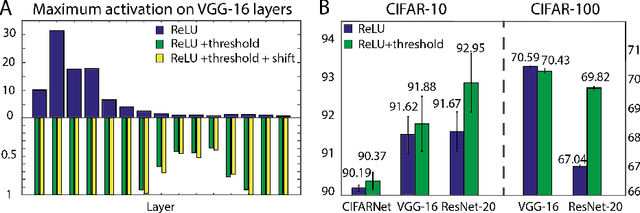
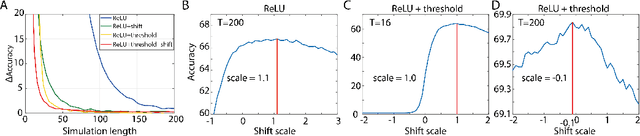
Spiking neural networks (SNNs) are biology-inspired artificial neural networks (ANNs) that comprise of spiking neurons to process asynchronous discrete signals. While more efficient in power consumption and inference speed on the neuromorphic hardware, SNNs are usually difficult to train directly from scratch with spikes due to the discreteness. As an alternative, many efforts have been devoted to converting conventional ANNs into SNNs by copying the weights from ANNs and adjusting the spiking threshold potential of neurons in SNNs. Researchers have designed new SNN architectures and conversion algorithms to diminish the conversion error. However, an effective conversion should address the difference between the SNN and ANN architectures with an efficient approximation \DSK{of} the loss function, which is missing in the field. In this work, we analyze the conversion error by recursive reduction to layer-wise summation and propose a novel strategic pipeline that transfers the weights to the target SNN by combining threshold balance and soft-reset mechanisms. This pipeline enables almost no accuracy loss between the converted SNNs and conventional ANNs with only $\sim1/10$ of the typical SNN simulation time. Our method is promising to get implanted onto embedded platforms with better support of SNNs with limited energy and memory.
Linear Time Clustering for High Dimensional Mixtures of Gaussian Clouds
Mar 01, 2018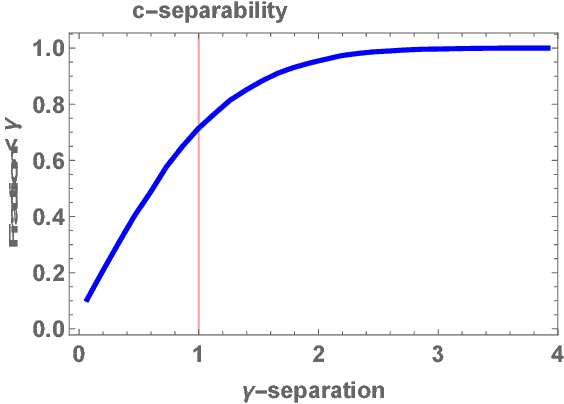
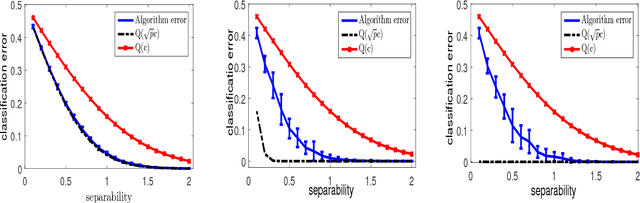
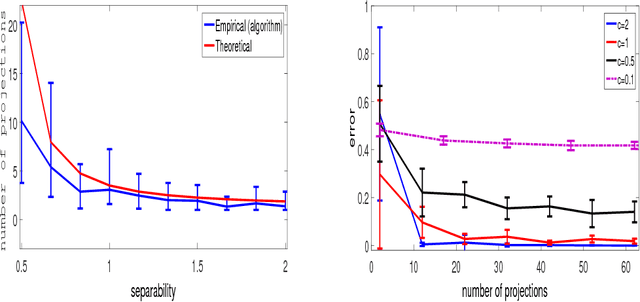
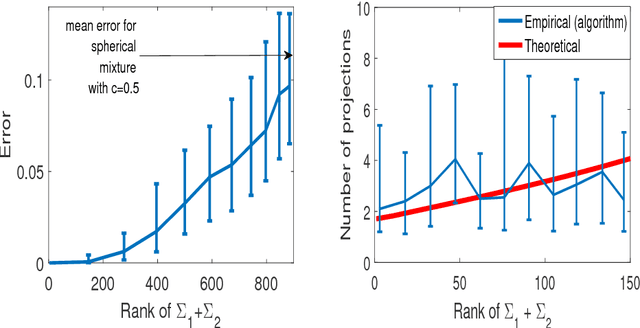
Clustering mixtures of Gaussian distributions is a fundamental and challenging problem that is ubiquitous in various high-dimensional data processing tasks. While state-of-the-art work on learning Gaussian mixture models has focused primarily on improving separation bounds and their generalization to arbitrary classes of mixture models, less emphasis has been paid to practical computational efficiency of the proposed solutions. In this paper, we propose a novel and highly efficient clustering algorithm for $n$ points drawn from a mixture of two arbitrary Gaussian distributions in $\mathbb{R}^p$. The algorithm involves performing random 1-dimensional projections until a direction is found that yields a user-specified clustering error $e$. For a 1-dimensional separation parameter $\gamma$ satisfying $\gamma=Q^{-1}(e)$, the expected number of such projections is shown to be bounded by $o(\ln p)$, when $\gamma$ satisfies $\gamma\leq c\sqrt{\ln{\ln{p}}}$, with $c$ as the separability parameter of the two Gaussians in $\mathbb{R}^p$. Consequently, the expected overall running time of the algorithm is linear in $n$ and quasi-linear in $p$ at $o(\ln{p})O(np)$, and the sample complexity is independent of $p$. This result stands in contrast to prior works which provide polynomial, with at-best quadratic, running time in $p$ and $n$. We show that our bound on the expected number of 1-dimensional projections extends to the case of three or more Gaussian components, and we present a generalization of our results to mixture distributions beyond the Gaussian model.