 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
OLED: One-Class Learned Encoder-Decoder Network with Adversarial Context Masking for Novelty Detection
Mar 27, 2021
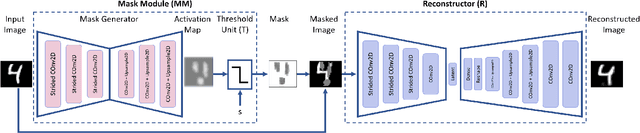
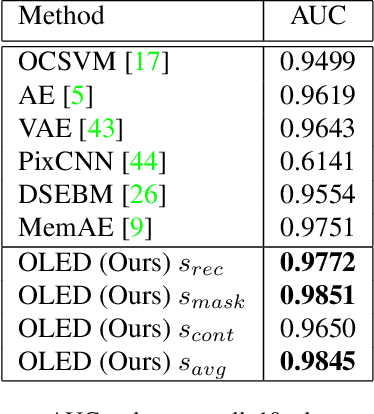

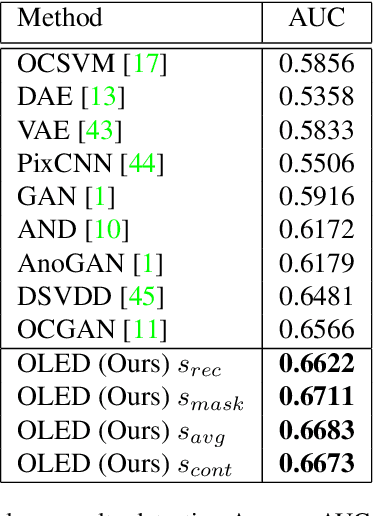
Novelty detection is the task of recognizing samples that do not belong to the distribution of the target class. During training, the novelty class is absent, preventing the use of traditional classification approaches. Deep autoencoders have been widely used as a base of many unsupervised novelty detection methods. In particular, context autoencoders have been successful in the novelty detection task because of the more effective representations they learn by reconstructing original images from randomly masked images. However, a significant drawback of context autoencoders is that random masking fails to consistently cover important structures of the input image, leading to suboptimal representations - especially for the novelty detection task. In this paper, to optimize input masking, we have designed a framework consisting of two competing networks, a Mask Module and a Reconstructor. The Mask Module is a convolutional autoencoder that learns to generate optimal masks that cover the most important parts of images. Alternatively, the Reconstructor is a convolutional encoder-decoder that aims to reconstruct unperturbed images from masked images. The networks are trained in an adversarial manner in which the Mask Module generates masks that are applied to images given to the Reconstructor. In this way, the Mask Module seeks to maximize the reconstruction error that the Reconstructor is minimizing. When applied to novelty detection, the proposed approach learns semantically richer representations compared to context autoencoders and enhances novelty detection at test time through more optimal masking. Novelty detection experiments on the MNIST and CIFAR-10 image datasets demonstrate the proposed approach's superiority over cutting-edge methods. In a further experiment on the UCSD video dataset for novelty detection, the proposed approach achieves state-of-the-art results.
The Adaptive Dynamic Programming Toolbox
Dec 29, 2020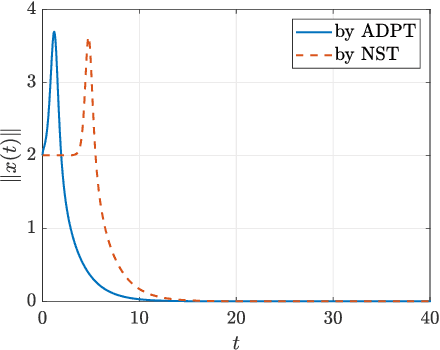
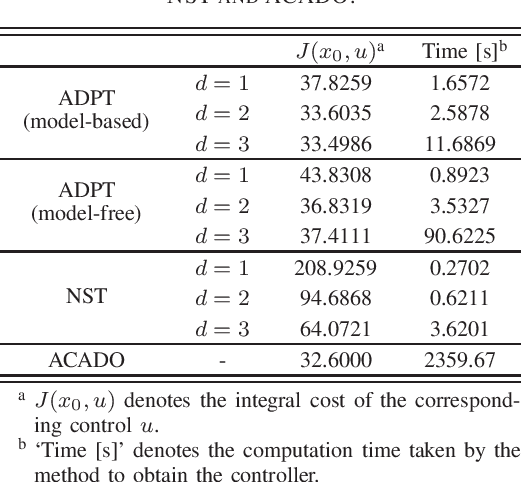


The paper develops the Adaptive Dynamic Programming Toolbox (ADPT), which solves optimal control problems for continuous-time nonlinear systems. Based on the adaptive dynamic programming technique, the ADPT computes optimal feedback controls from the system dynamics in the model-based working mode, or from measurements of trajectories of the system in the model-free working mode without the requirement of knowledge of the system model. Multiple options are provided such that the ADPT can accommodate various customized circumstances. Compared to other popular software toolboxes for optimal control, the ADPT enjoys its computational precision and speed, which is illustrated with its applications to a satellite attitude control problem.
Understanding the Failure Modes of Out-of-Distribution Generalization
Oct 29, 2020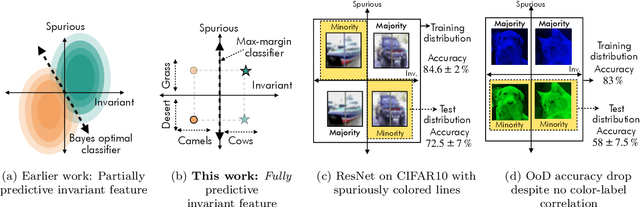
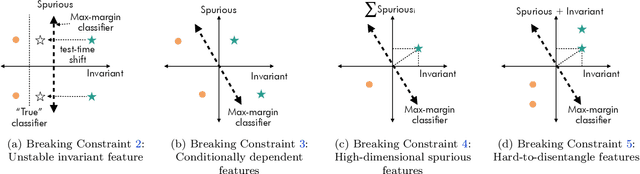
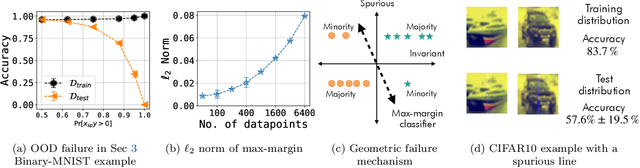
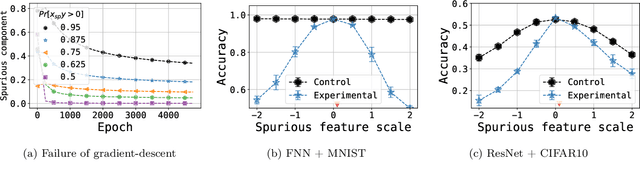
Empirical studies suggest that machine learning models often rely on features, such as the background, that may be spuriously correlated with the label only during training time, resulting in poor accuracy during test-time. In this work, we identify the fundamental factors that give rise to this behavior, by explaining why models fail this way {\em even} in easy-to-learn tasks where one would expect these models to succeed. In particular, through a theoretical study of gradient-descent-trained linear classifiers on some easy-to-learn tasks, we uncover two complementary failure modes. These modes arise from how spurious correlations induce two kinds of skews in the data: one geometric in nature, and another, statistical in nature. Finally, we construct natural modifications of image classification datasets to understand when these failure modes can arise in practice. We also design experiments to isolate the two failure modes when training modern neural networks on these datasets.
A Comprehensive Review on the NILM Algorithms for Energy Disaggregation
Feb 20, 2021



The housing structures have changed with urbanization and the growth due to the construction of high-rise buildings all around the world requires end-use appliance energy conservation and management in real-time. This shift also came along with smart-meters which enabled the estimation of appliance-specific power consumption from the buildings aggregate power consumption reading. Non-intrusive load monitoring (NILM) or energy disaggregation is aimed at separating the household energy measured at the aggregate level into constituent appliances. Over the years, signal processing and machine learning algorithms have been combined to achieve this. Incredible research and publications have been conducted on energy disaggregation, non-intrusive load monitoring, home energy management and appliance classification. There exists an API, NILMTK, a reproducible benchmark algorithm for the same. Many other approaches to perform energy disaggregation has been adapted such as deep neural network architectures and big data approach for household energy disaggregation. This paper provides a survey of the effective NILM system frameworks and reviews the performance of the benchmark algorithms in a comprehensive manner. This paper also summarizes the wide application scope and the effectiveness of the algorithmic performance on three publicly available data sets.
Real-time Surgical Tools Recognition in Total Knee Arthroplasty Using Deep Neural Networks
Jun 06, 2018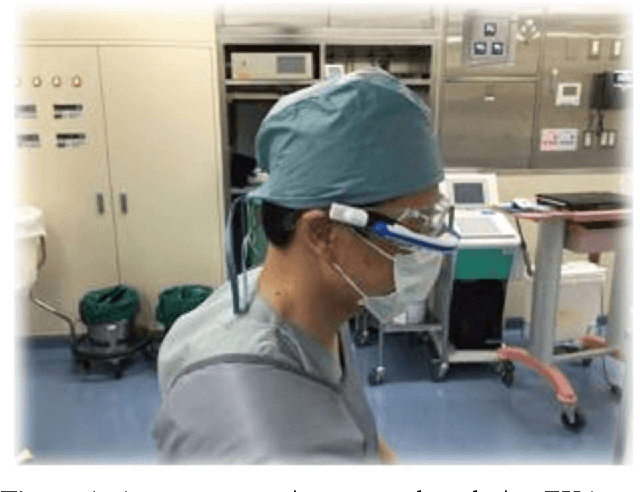
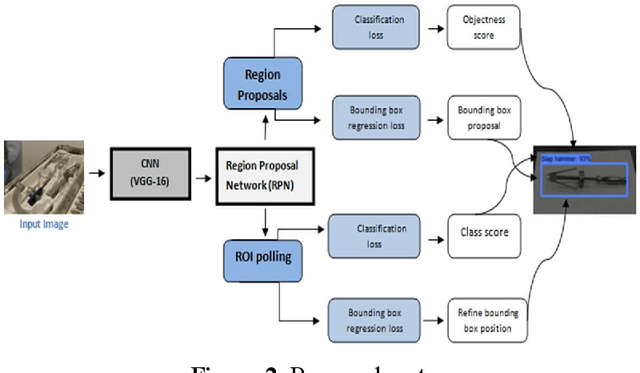
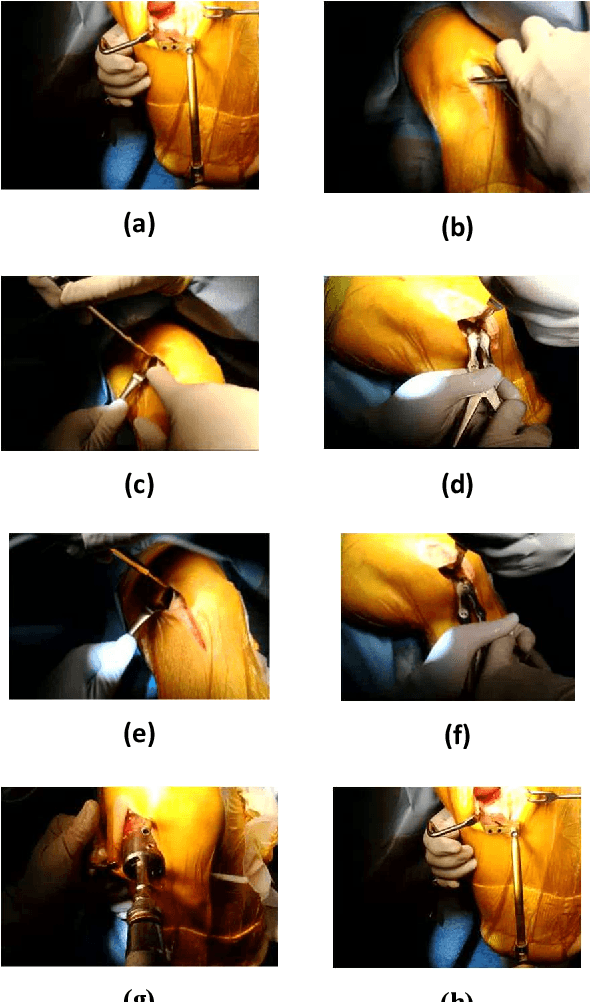
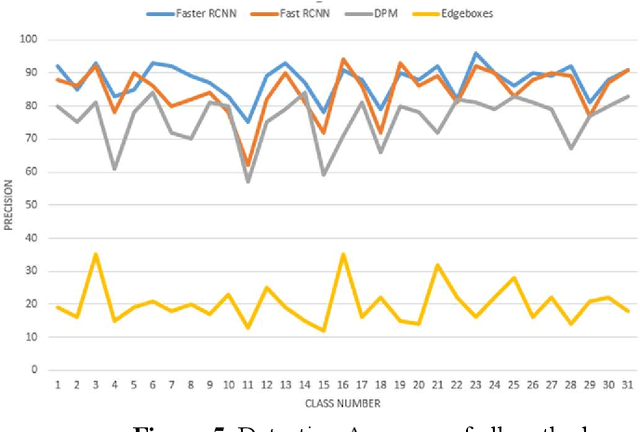
Total knee arthroplasty (TKA) is a commonly performed surgical procedure to mitigate knee pain and improve functions for people with knee arthritis. The procedure is complicated due to the different surgical tools used in the stages of surgery. The recognition of surgical tools in real-time can be a solution to simplify surgical procedures for the surgeon. Also, the presence and movement of tools in surgery are crucial information for the recognition of the operational phase and to identify the surgical workflow. Therefore, this research proposes the development of a real-time system for the recognition of surgical tools during surgery using a convolutional neural network (CNN). Surgeons wearing smart glasses can see essential information about tools during surgery that may reduce the complication of the procedures. To evaluate the performance of the proposed method, we calculated and compared the Mean Average Precision (MAP) with state-of-the-art methods which are fast R-CNN and deformable part models (DPM). We achieved 87.6% mAP which is better in comparison to the existing methods. With the additional improvements of our proposed method, it can be a future point of reference, also the baseline for operational phase recognition.
Some open questions on morphological operators and representations in the deep learning era
May 05, 2021During recent years, the renaissance of neural networks as the major machine learning paradigm and more specifically, the confirmation that deep learning techniques provide state-of-the-art results for most of computer vision tasks has been shaking up traditional research in image processing. The same can be said for research in communities working on applied harmonic analysis, information geometry, variational methods, etc. For many researchers, this is viewed as an existential threat. On the one hand, research funding agencies privilege mainstream approaches especially when these are unquestionably suitable for solving real problems and for making progress on artificial intelligence. On the other hand, successful publishing of research in our communities is becoming almost exclusively based on a quantitative improvement of the accuracy of any benchmark task. As most of my colleagues sharing this research field, I am confronted with the dilemma of continuing to invest my time and intellectual effort on mathematical morphology as my driving force for research, or simply focussing on how to use deep learning and contributing to it. The solution is not obvious to any of us since our research is not fundamental, it is just oriented to solve challenging problems, which can be more or less theoretical. Certainly, it would be foolish for anyone to claim that deep learning is insignificant or to think that one's favourite image processing domain is productive enough to ignore the state-of-the-art. I fully understand that the labs and leading people in image processing communities have been shifting their research to almost exclusively focus on deep learning techniques. My own position is different: I do think there is room for progress on mathematically grounded image processing branches, under the condition that these are rethought in a broader sense from the deep learning paradigm. Indeed, I firmly believe that the convergence between mathematical morphology and the computation methods which gravitate around deep learning (fully connected networks, convolutional neural networks, residual neural networks, recurrent neural networks, etc.) is worthwhile. The goal of this talk is to discuss my personal vision regarding these potential interactions. Without any pretension of being exhaustive, I want to address it with a series of open questions, covering a wide range of specificities of morphological operators and representations, which could be tackled and revisited under the paradigm of deep learning. An expected benefit of such convergence between morphology and deep learning is a cross-fertilization of concepts and techniques between both fields. In addition, I think the future answer to some of these questions can provide some insight on understanding, interpreting and simplifying deep learning networks.
CoRe: An Efficient Coarse-refined Training Framework for BERT
Nov 27, 2020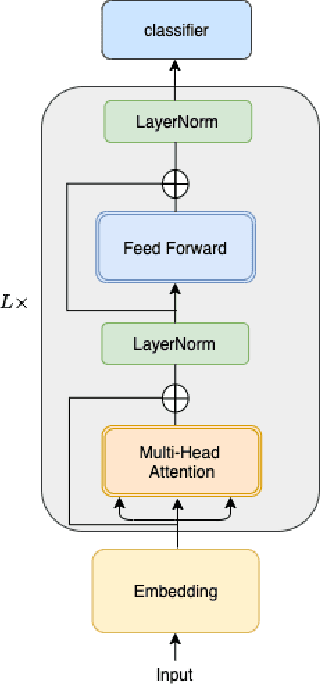
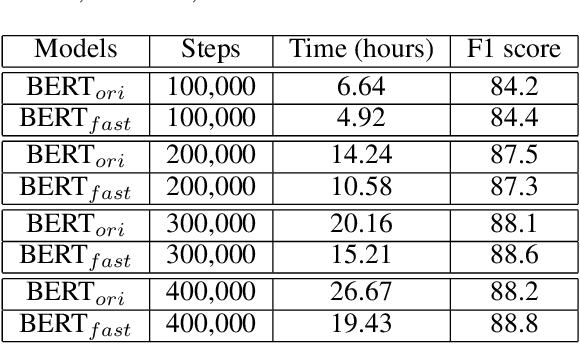
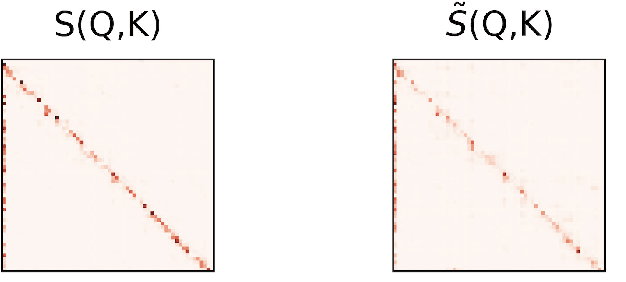
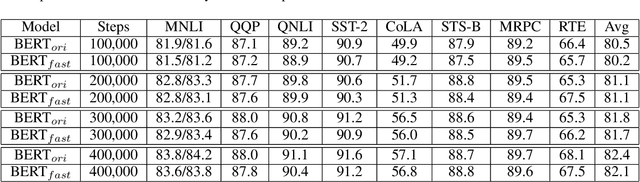
In recent years, BERT has made significant breakthroughs on many natural language processing tasks and attracted great attentions. Despite its accuracy gains, the BERT model generally involves a huge number of parameters and needs to be trained on massive datasets, so training such a model is computationally very challenging and time-consuming. Hence, training efficiency should be a critical issue. In this paper, we propose a novel coarse-refined training framework named CoRe to speed up the training of BERT. Specifically, we decompose the training process of BERT into two phases. In the first phase, by introducing fast attention mechanism and decomposing the large parameters in the feed-forward network sub-layer, we construct a relaxed BERT model which has much less parameters and much lower model complexity than the original BERT, so the relaxed model can be quickly trained. In the second phase, we transform the trained relaxed BERT model into the original BERT and further retrain the model. Thanks to the desired initialization provided by the relaxed model, the retraining phase requires much less training steps, compared with training an original BERT model from scratch with a random initialization. Experimental results show that the proposed CoRe framework can greatly reduce the training time without reducing the performance.
You Only Learn Once: Universal Anatomical Landmark Detection
Mar 08, 2021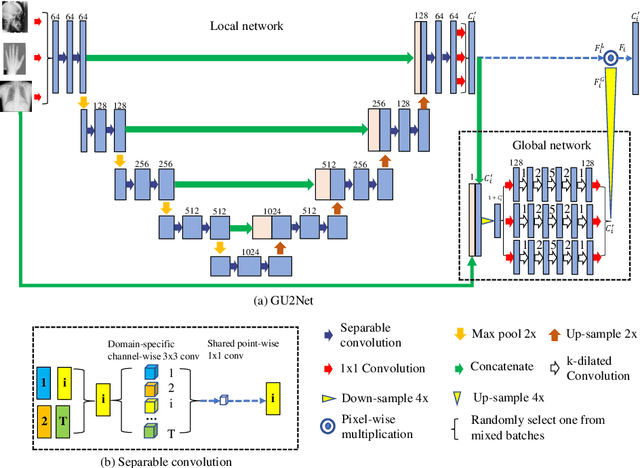
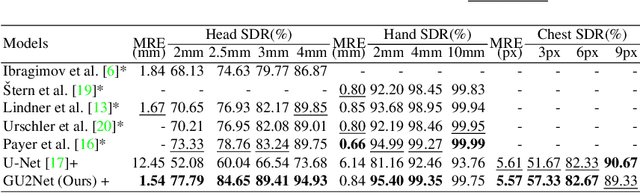
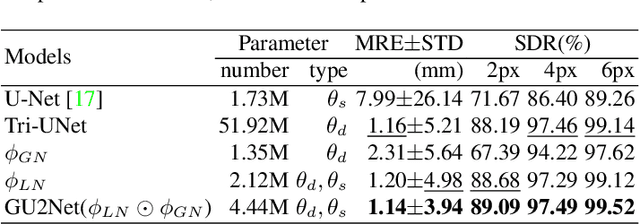
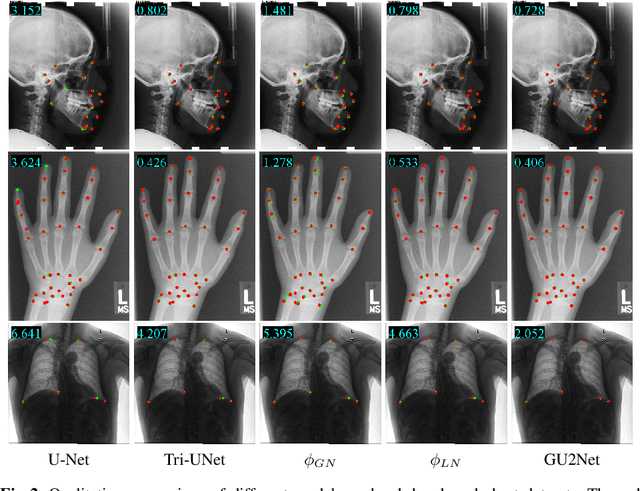
Detecting anatomical landmarks in medical images plays an essential role in understanding the anatomy and planning automated processing. In recent years, a variety of deep neural network methods have been developed to detect landmarks automatically. However, all of those methods are unary in the sense that a highly specialized network is trained for a single task say associated with a particular anatomical region. In this work, for the first time, we investigate the idea of "You Only Learn Once (YOLO)" and develop a universal anatomical landmark detection model to realize multiple landmark detection tasks with end-to-end training based on mixed datasets. The model consists of a local network and a global network: The local network is built upon the idea of universal UNet to learn multi-domain local features and the global network is a parallelly-duplicated sequential of dilated convolutions that extract global features to further disambiguate the landmark locations. It is worth mentioning that the new model design requires fewer parameters than models with standard convolutions to train. We evaluate our YOLO model on three X-ray datasets of 1,588 images on the head, hand, and chest, collectively contributing 62 landmarks. The experimental results show that our proposed universal model behaves largely better than any previous models trained on multiple datasets. It even beats the performance of the model that is trained separately for every single dataset.
Deep4Air: A Novel Deep Learning Framework for Airport Airside Surveillance
Oct 02, 2020
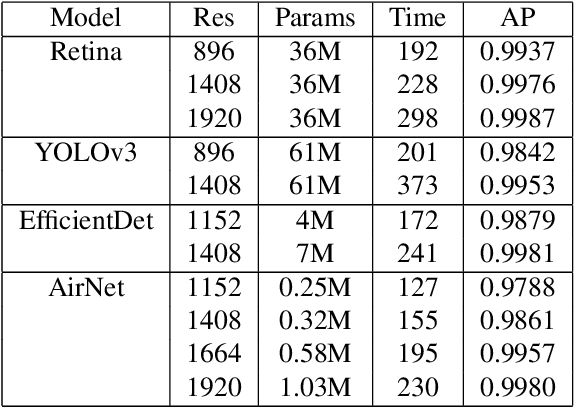
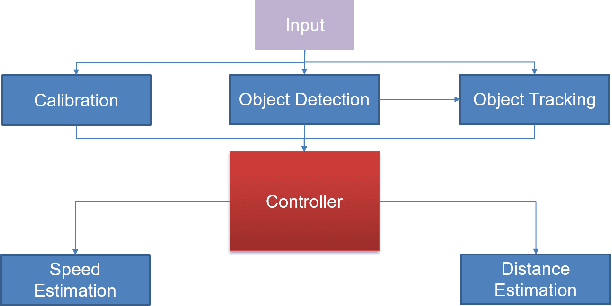

An airport runway and taxiway (airside) area is a highly dynamic and complex environment featuring interactions between different types of vehicles (speed and dimension), under varying visibility and traffic conditions. Airport ground movements are deemed safety-critical activities, and safe-separation procedures must be maintained by Air Traffic Controllers (ATCs). Large airports with complicated runway-taxiway systems use advanced ground surveillance systems. However, these systems have inherent limitations and a lack of real-time analytics. In this paper, we propose a novel computer-vision based framework, namely "Deep4Air", which can not only augment the ground surveillance systems via the automated visual monitoring of runways and taxiways for aircraft location, but also provide real-time speed and distance analytics for aircraft on runways and taxiways. The proposed framework includes an adaptive deep neural network for efficiently detecting and tracking aircraft. The experimental results show an average precision of detection and tracking of up to 99.8% on simulated data with validations on surveillance videos from the digital tower at George Bush Intercontinental Airport. The results also demonstrate that "Deep4Air" can locate aircraft positions relative to the airport runway and taxiway infrastructure with high accuracy. Furthermore, aircraft speed and separation distance are monitored in real-time, providing enhanced safety management.
Spatially Adaptive Computation Time for Residual Networks
Jul 02, 2017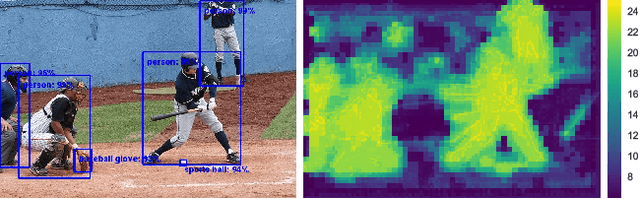
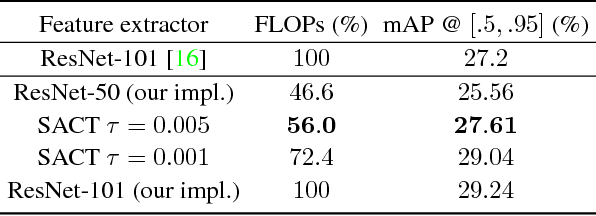
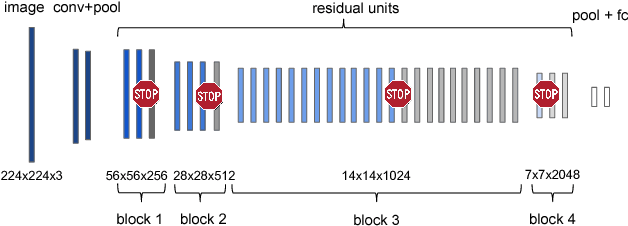

This paper proposes a deep learning architecture based on Residual Network that dynamically adjusts the number of executed layers for the regions of the image. This architecture is end-to-end trainable, deterministic and problem-agnostic. It is therefore applicable without any modifications to a wide range of computer vision problems such as image classification, object detection and image segmentation. We present experimental results showing that this model improves the computational efficiency of Residual Networks on the challenging ImageNet classification and COCO object detection datasets. Additionally, we evaluate the computation time maps on the visual saliency dataset cat2000 and find that they correlate surprisingly well with human eye fixation positions.