 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The SpaceNet Multi-Temporal Urban Development Challenge
Feb 23, 2021
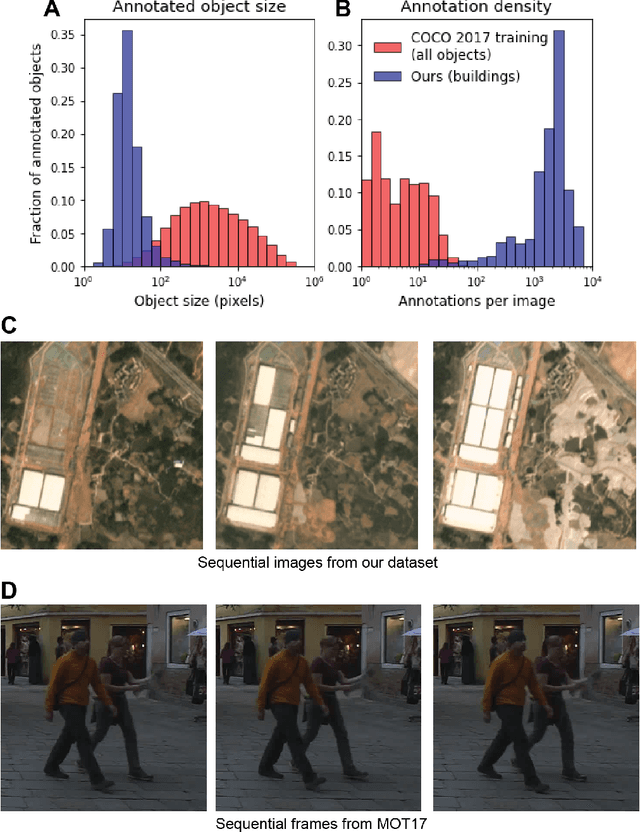



Building footprints provide a useful proxy for a great many humanitarian applications. For example, building footprints are useful for high fidelity population estimates, and quantifying population statistics is fundamental to ~1/4 of the United Nations Sustainable Development Goals Indicators. In this paper we (the SpaceNet Partners) discuss efforts to develop techniques for precise building footprint localization, tracking, and change detection via the SpaceNet Multi-Temporal Urban Development Challenge (also known as SpaceNet 7). In this NeurIPS 2020 competition, participants were asked identify and track buildings in satellite imagery time series collected over rapidly urbanizing areas. The competition centered around a brand new open source dataset of Planet Labs satellite imagery mosaics at 4m resolution, which includes 24 images (one per month) covering ~100 unique geographies. Tracking individual buildings at this resolution is quite challenging, yet the winning participants demonstrated impressive performance with the newly developed SpaceNet Change and Object Tracking (SCOT) metric. This paper details the top-5 winning approaches, as well as analysis of results that yielded a handful of interesting anecdotes such as decreasing performance with latitude.
Multitarget Tracking with Transformers
Apr 01, 2021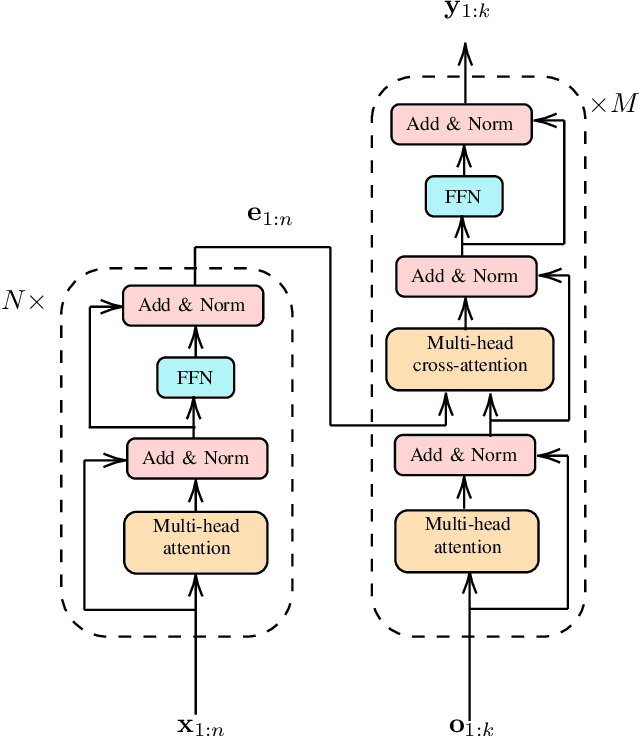
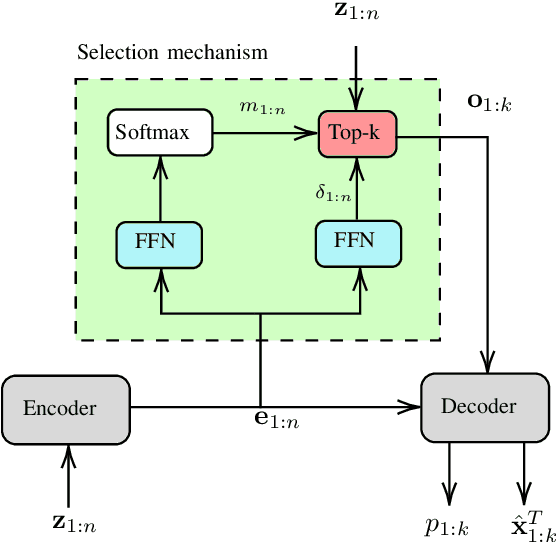
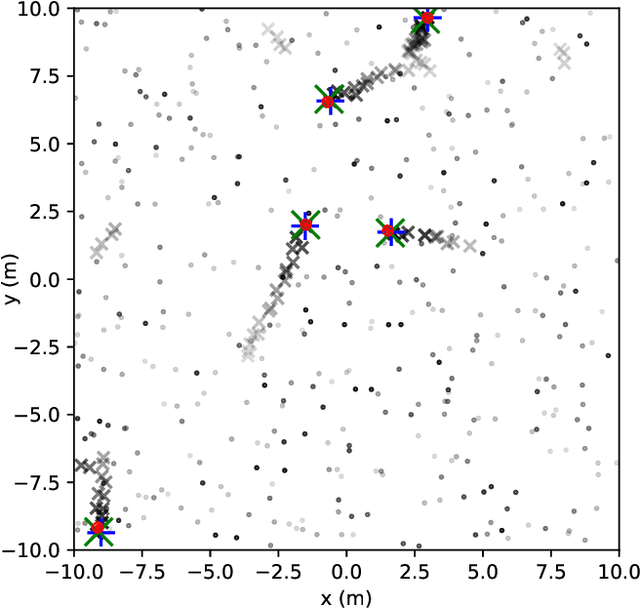
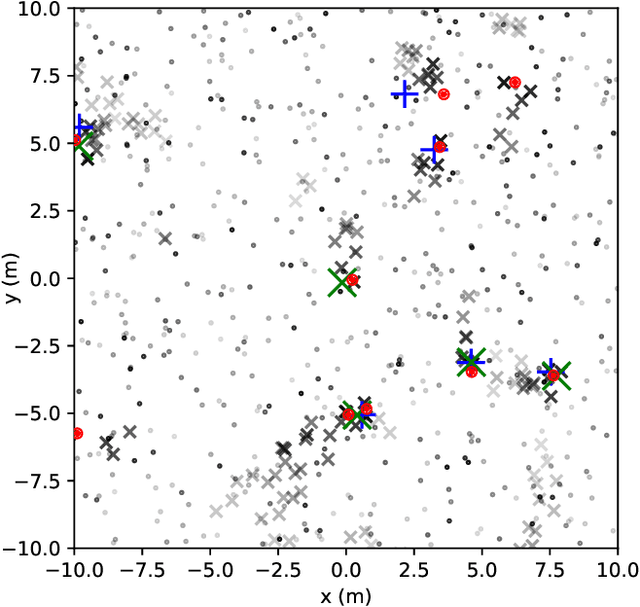
Multitarget Tracking (MTT) is the problem of tracking the states of an unknown number of objects using noisy measurements, with important applications to autonomous driving, surveillance, robotics, and others. In the model-based Bayesian setting, there are conjugate priors that enable us to express the multi-object posterior in closed form, which could theoretically provide Bayes-optimal estimates. However, the posterior involves a super-exponential growth of the number of hypotheses over time, forcing state-of-the-art methods to resort to approximations for remaining tractable, which can impact their performance in complex scenarios. Model-free methods based on deep-learning provide an attractive alternative, as they can in principle learn the optimal filter from data, but to the best of our knowledge were never compared to current state-of-the-art Bayesian filters, specially not in contexts where accurate models are available. In this paper, we propose a high-performing deep-learning method for MTT based on the Transformer architecture and compare it to two state-of-the-art Bayesian filters, in a setting where we assume the correct model is provided. Although this gives an edge to the model-based filters, it also allows us to generate unlimited training data. We show that the proposed model outperforms state-of-the-art Bayesian filters in complex scenarios, while macthing their performance in simpler cases, which validates the applicability of deep-learning also in the model-based regime. The code for all our implementations is made available at (github link to be provided).
BERTSurv: BERT-Based Survival Models for Predicting Outcomes of Trauma Patients
Mar 19, 2021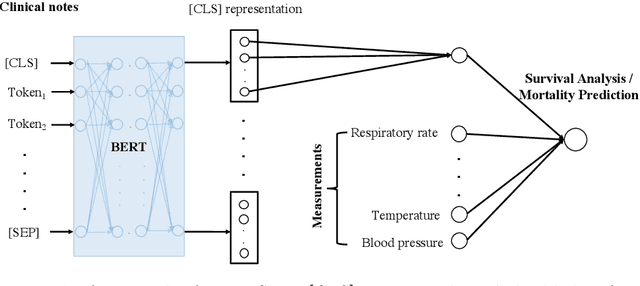
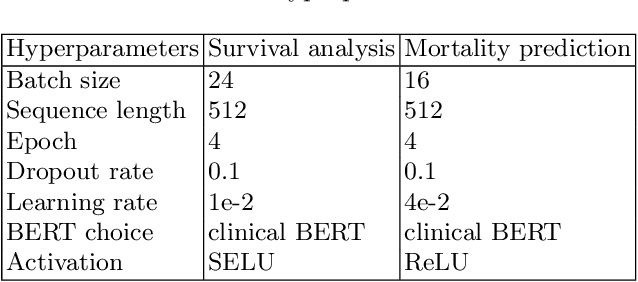
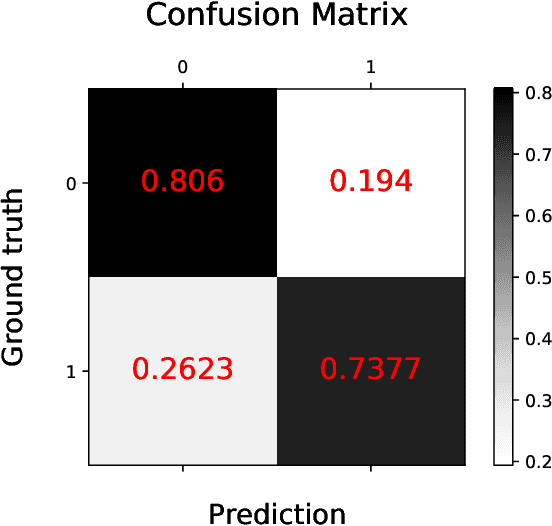
Survival analysis is a technique to predict the times of specific outcomes, and is widely used in predicting the outcomes for intensive care unit (ICU) trauma patients. Recently, deep learning models have drawn increasing attention in healthcare. However, there is a lack of deep learning methods that can model the relationship between measurements, clinical notes and mortality outcomes. In this paper we introduce BERTSurv, a deep learning survival framework which applies Bidirectional Encoder Representations from Transformers (BERT) as a language representation model on unstructured clinical notes, for mortality prediction and survival analysis. We also incorporate clinical measurements in BERTSurv. With binary cross-entropy (BCE) loss, BERTSurv can predict mortality as a binary outcome (mortality prediction). With partial log-likelihood (PLL) loss, BERTSurv predicts the probability of mortality as a time-to-event outcome (survival analysis). We apply BERTSurv on Medical Information Mart for Intensive Care III (MIMIC III) trauma patient data. For mortality prediction, BERTSurv obtained an area under the curve of receiver operating characteristic curve (AUC-ROC) of 0.86, which is an improvement of 3.6% over baseline of multilayer perceptron (MLP) without notes. For survival analysis, BERTSurv achieved a concordance index (C-index) of 0.7. In addition, visualizations of BERT's attention heads help to extract patterns in clinical notes and improve model interpretability by showing how the model assigns weights to different inputs.
Semiparametric Methods for Exposure Misclassification in Propensity Score-Based Time-to-Event Data Analysis
Mar 19, 2019
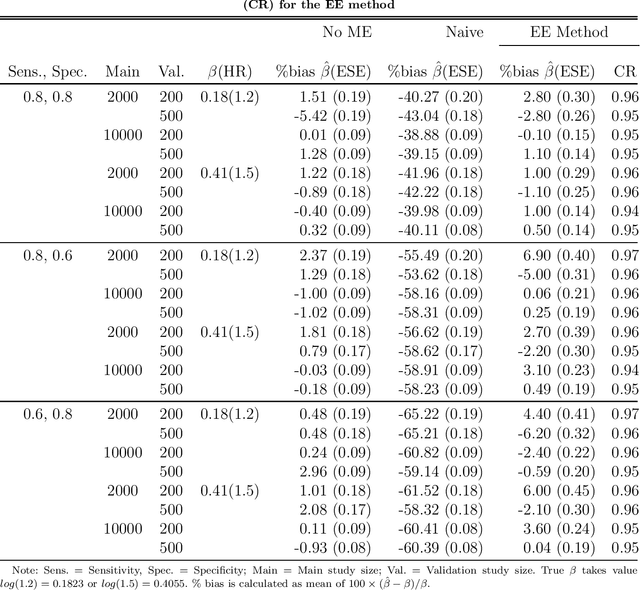
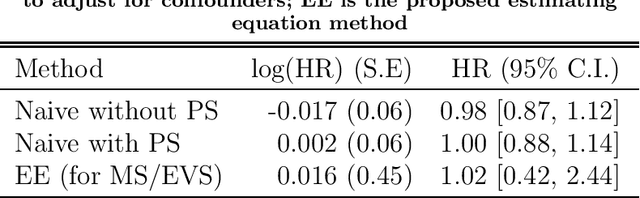
In epidemiology, identifying the effect of exposure variables in relation to a time-to-event outcome is a classical research area of practical importance. Incorporating propensity score in the Cox regression model, as a measure to control for confounding, has certain advantages when outcome is rare. However, in situations involving exposure measured with moderate to substantial error, identifying the exposure effect using propensity score in Cox models remains a challenging yet unresolved problem. In this paper, we propose an estimating equation method to correct for the exposure misclassification-caused bias in the estimation of exposure-outcome associations. We also discuss the asymptotic properties and derive the asymptotic variances of the proposed estimators. We conduct a simulation study to evaluate the performance of the proposed estimators in various settings. As an illustration, we apply our method to correct for the misclassification-caused bias in estimating the association of PM2.5 level with lung cancer mortality using a nationwide prospective cohort, the Nurses' Health Study (NHS). The proposed methodology can be applied using our user-friendly R function published online.
Online Stochastic Gradient Descent Learns Linear Dynamical Systems from A Single Trajectory
Feb 23, 2021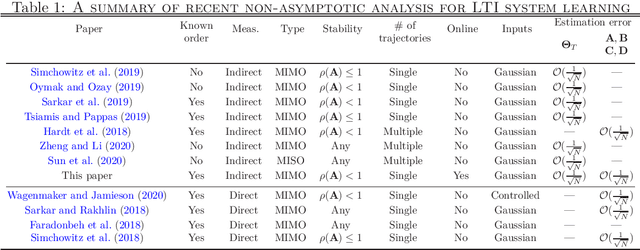
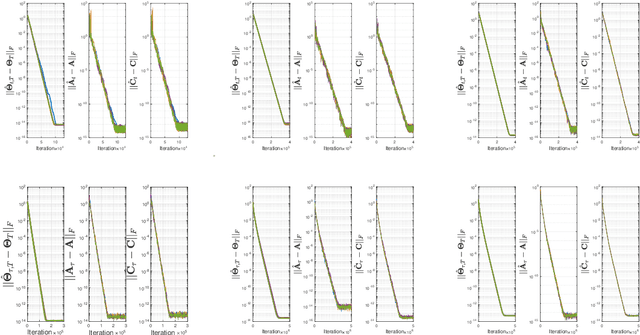
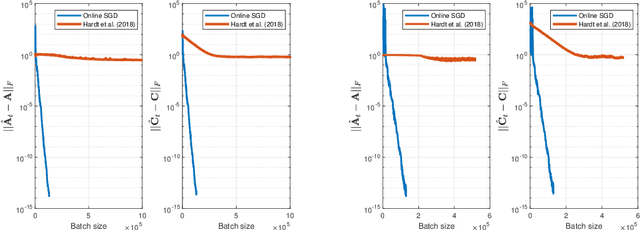
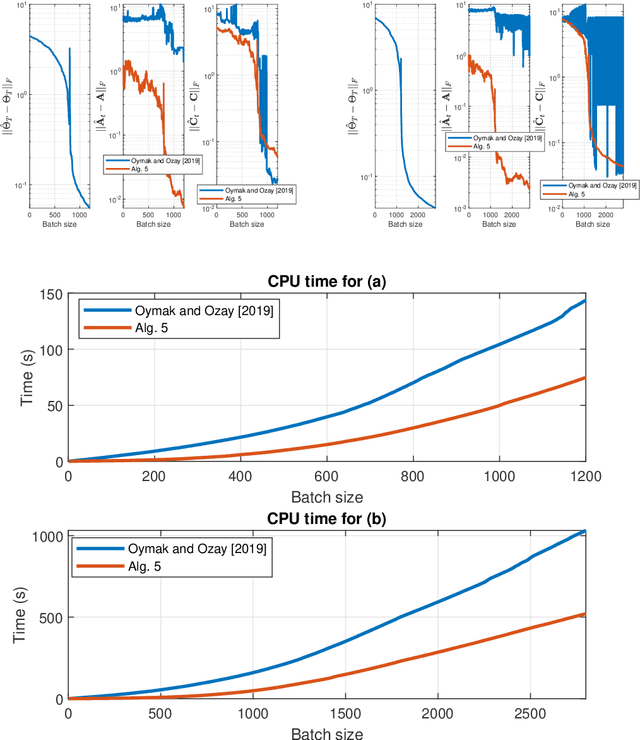
This work investigates the problem of estimating the weight matrices of a stable time-invariant linear dynamical system from a single sequence of noisy measurements. We show that if the unknown weight matrices describing the system are in Brunovsky canonical form, we can efficiently estimate the ground truth unknown matrices of the system from a linear system of equations formulated based on the transfer function of the system, using both online and offline stochastic gradient descent (SGD) methods. Specifically, by deriving concrete complexity bounds, we show that SGD converges linearly in expectation to any arbitrary small Frobenius norm distance from the ground truth weights. To the best of our knowledge, ours is the first work to establish linear convergence characteristics for online and offline gradient-based iterative methods for weight matrix estimation in linear dynamical systems from a single trajectory. Extensive numerical tests verify that the performance of the proposed methods is consistent with our theory, and show their superior performance relative to existing state of the art methods.
Dynamic Domain Adaptation for Efficient Inference
Mar 26, 2021
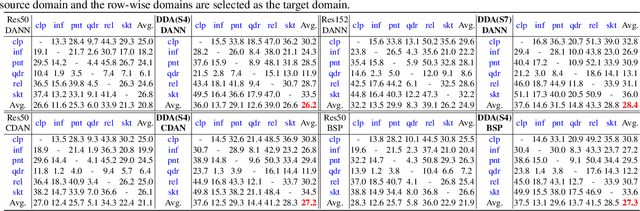
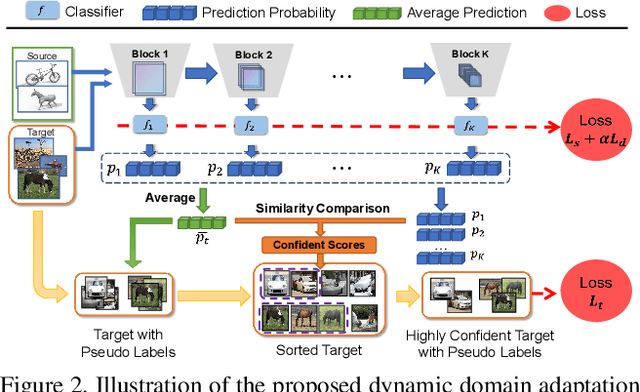

Domain adaptation (DA) enables knowledge transfer from a labeled source domain to an unlabeled target domain by reducing the cross-domain distribution discrepancy. Most prior DA approaches leverage complicated and powerful deep neural networks to improve the adaptation capacity and have shown remarkable success. However, they may have a lack of applicability to real-world situations such as real-time interaction, where low target inference latency is an essential requirement under limited computational budget. In this paper, we tackle the problem by proposing a dynamic domain adaptation (DDA) framework, which can simultaneously achieve efficient target inference in low-resource scenarios and inherit the favorable cross-domain generalization brought by DA. In contrast to static models, as a simple yet generic method, DDA can integrate various domain confusion constraints into any typical adaptive network, where multiple intermediate classifiers can be equipped to infer "easier" and "harder" target data dynamically. Moreover, we present two novel strategies to further boost the adaptation performance of multiple prediction exits: 1) a confidence score learning strategy to derive accurate target pseudo labels by fully exploring the prediction consistency of different classifiers; 2) a class-balanced self-training strategy to explicitly adapt multi-stage classifiers from source to target without losing prediction diversity. Extensive experiments on multiple benchmarks are conducted to verify that DDA can consistently improve the adaptation performance and accelerate target inference under domain shift and limited resources scenarios
Fair Multi-Stakeholder News Recommender System with Hypergraph ranking
Dec 01, 2020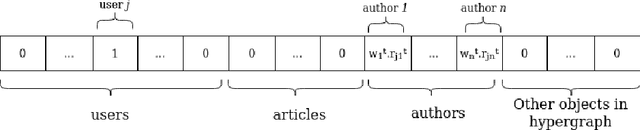
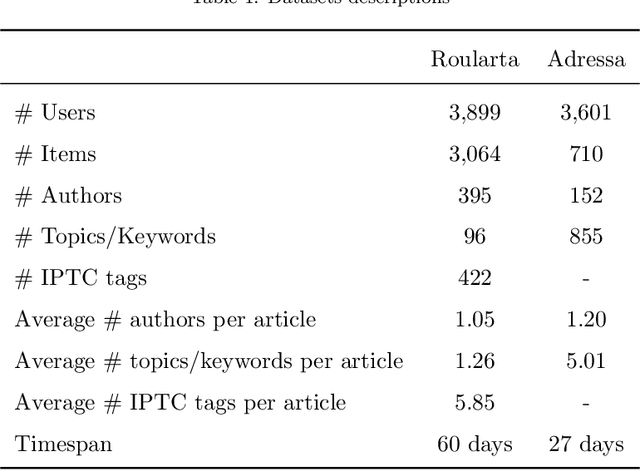
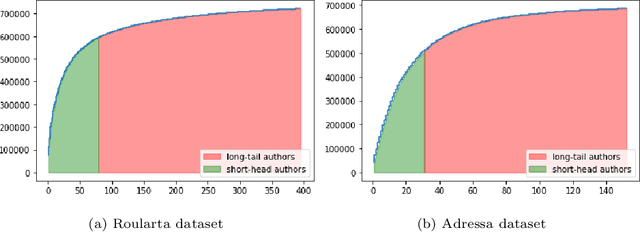

Recommender systems are typically designed to fulfill end user needs. However, in some domains the users are not the only stakeholders in the system. For instance, in a news aggregator website users, authors, magazines as well as the platform itself are potential stakeholders. Most of the collaborative filtering recommender systems suffer from popularity bias. Therefore, if the recommender system only considers users' preferences, presumably it over-represents popular providers and under-represents less popular providers. To address this issue one should consider other stakeholders in the generated ranked lists. In this paper we demonstrate that hypergraph learning has the natural capability of handling a multi-stakeholder recommendation task. A hypergraph can model high order relations between different types of objects and therefore is naturally inclined to generate recommendation lists considering multiple stakeholders. We form the recommendations in time-wise rounds and learn to adapt the weights of stakeholders to increase the coverage of low-covered stakeholders over time. The results show that the proposed approach counters popularity bias and produces fairer recommendations with respect to authors in two news datasets, at a low cost in precision.
FastHand: Fast Hand Pose Estimation From A Monocular Camera
Feb 14, 2021
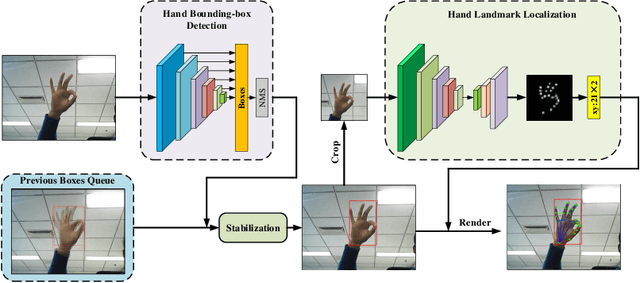
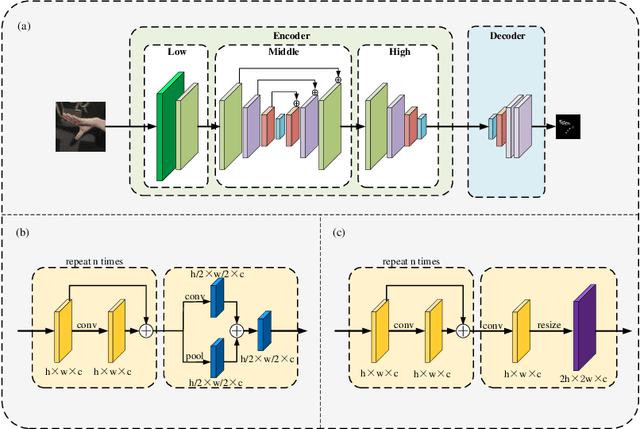

Hand gesture recognition constitutes the initial step in most methods related to human-robot interaction. There are two key challenges in this task. The first one corresponds to the difficulty of achieving stable and accurate hand landmark predictions in real-world scenarios, while the second to the decreased time of forward inference. In this paper, we propose a fast and accurate framework for hand pose estimation, dubbed as "FastHand". Using a lightweight encoder-decoder network architecture, we achieve to fulfil the requirements of practical applications running on embedded devices. The encoder consists of deep layers with a small number of parameters, while the decoder makes use of spatial location information to obtain more accurate results. The evaluation took place on two publicly available datasets demonstrating the improved performance of the proposed pipeline compared to other state-of-the-art approaches. FastHand offers high accuracy scores while reaching a speed of 25 frames per second on an NVIDIA Jetson TX2 graphics processing unit.
Semantic Models for the First-stage Retrieval: A Comprehensive Review
Mar 12, 2021
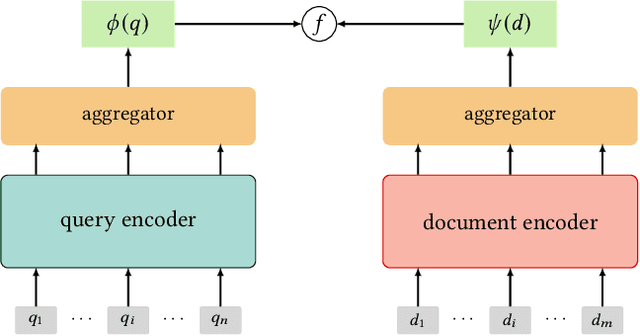

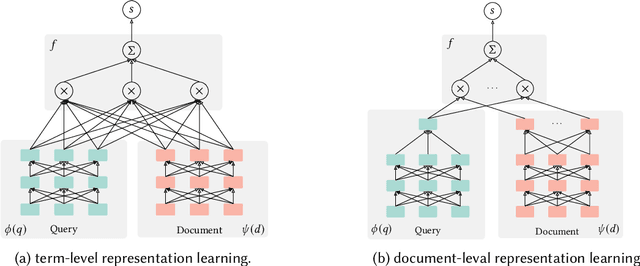
Multi-stage ranking pipelines have been a practical solution in modern search systems, where the first-stage retrieval is to return a subset of candidate documents, and the latter stages attempt to re-rank those candidates. Unlike the re-ranking stages going through quick technique shifts during the past decades, the first-stage retrieval has long been dominated by classical term-based models. Unfortunately, these models suffer from the vocabulary mismatch problem, which may block the re-ranking stages from relevant documents at the very beginning. Therefore, it has been a long-term desire to build semantic models for the first-stage retrieval that can achieve high recall efficiently. Recently, we have witnessed an explosive growth of research interests on the first-stage semantic retrieval models. We believe it is the right time to survey the current status, learn from existing methods, and gain some insights for future development. In this paper, we describe the current landscape of semantic retrieval models from three major paradigms, paying special attention to recent neural-based methods. We review the benchmark datasets, optimization methods and evaluation metrics, and summarize the state-of-the-art models. We also discuss the unresolved challenges and suggest potentially promising directions for future work.
AutoWeka4MCPS-AVATAR: Accelerating Automated Machine Learning Pipeline Composition and Optimisation
Nov 21, 2020
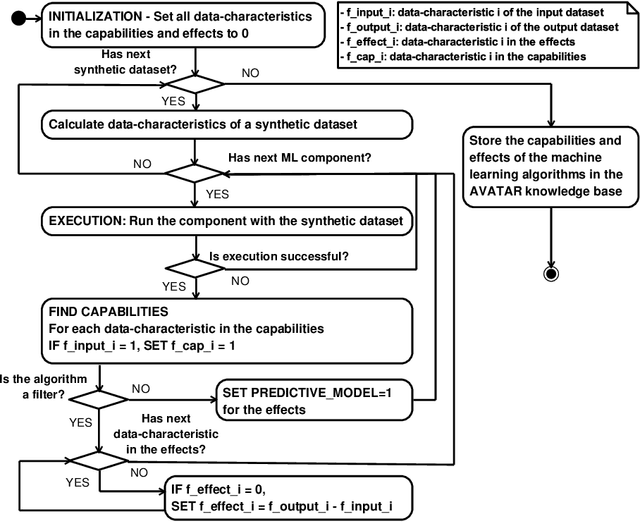
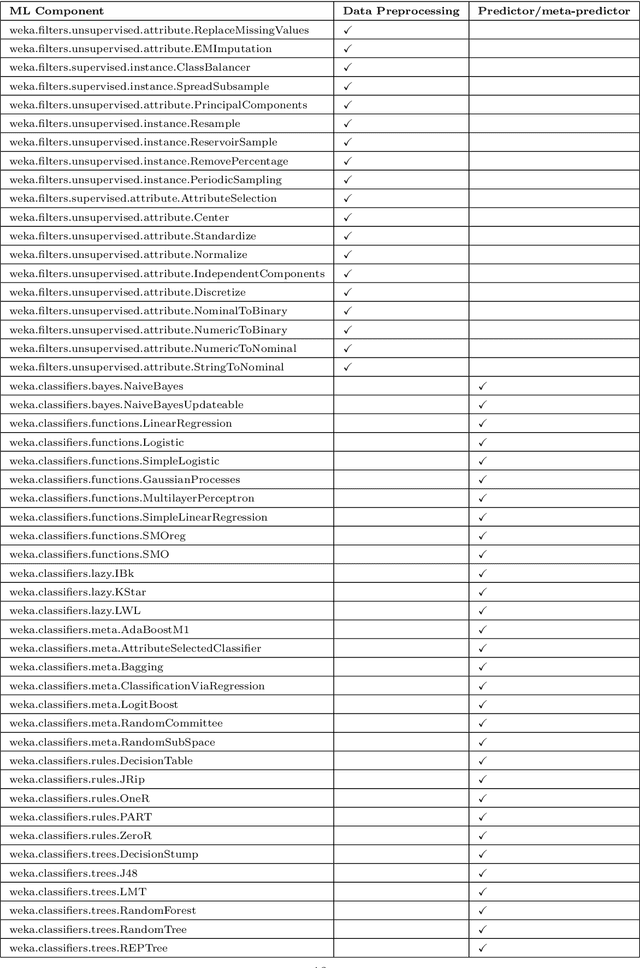
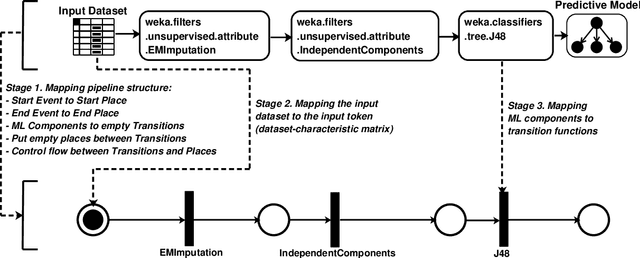
Automated machine learning pipeline (ML) composition and optimisation aim at automating the process of finding the most promising ML pipelines within allocated resources (i.e., time, CPU and memory). Existing methods, such as Bayesian-based and genetic-based optimisation, which are implemented in Auto-Weka, Auto-sklearn and TPOT, evaluate pipelines by executing them. Therefore, the pipeline composition and optimisation of these methods frequently require a tremendous amount of time that prevents them from exploring complex pipelines to find better predictive models. To further explore this research challenge, we have conducted experiments showing that many of the generated pipelines are invalid in the first place, and attempting to execute them is a waste of time and resources. To address this issue, we propose a novel method to evaluate the validity of ML pipelines, without their execution, using a surrogate model (AVATAR). The AVATAR generates a knowledge base by automatically learning the capabilities and effects of ML algorithms on datasets' characteristics. This knowledge base is used for a simplified mapping from an original ML pipeline to a surrogate model which is a Petri net based pipeline. Instead of executing the original ML pipeline to evaluate its validity, the AVATAR evaluates its surrogate model constructed by capabilities and effects of the ML pipeline components and input/output simplified mappings. Evaluating this surrogate model is less resource-intensive than the execution of the original pipeline. As a result, the AVATAR enables the pipeline composition and optimisation methods to evaluate more pipelines by quickly rejecting invalid pipelines. We integrate the AVATAR into the sequential model-based algorithm configuration (SMAC). Our experiments show that when SMAC employs AVATAR, it finds better solutions than on its own.