 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
X-view: Non-egocentric Multi-View 3D Object Detector
Mar 24, 2021
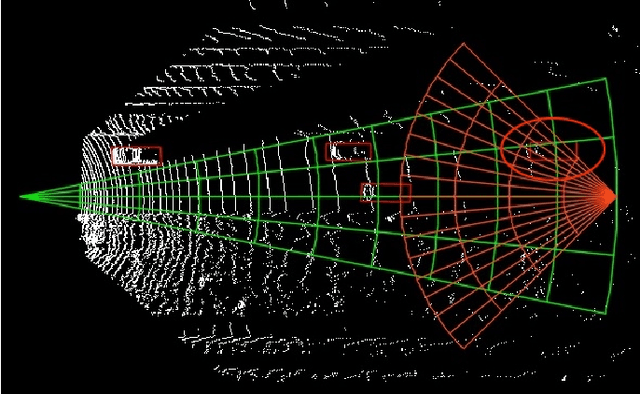
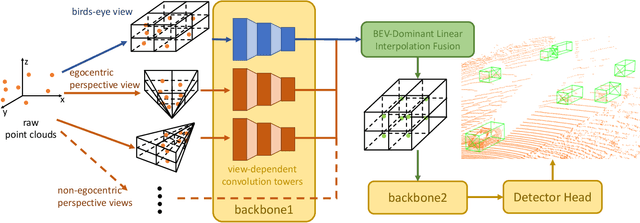

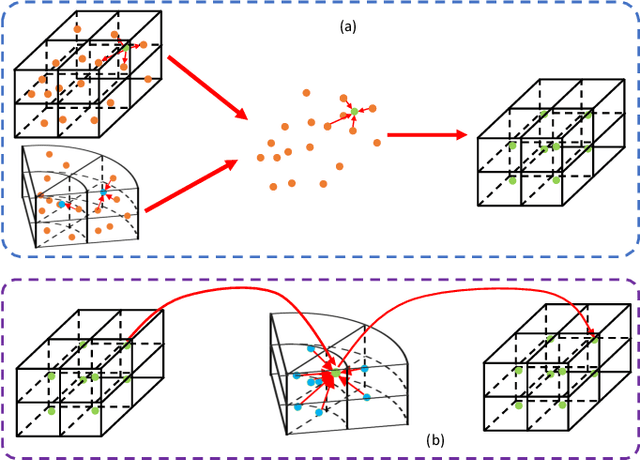
3D object detection algorithms for autonomous driving reason about 3D obstacles either from 3D birds-eye view or perspective view or both. Recent works attempt to improve the detection performance via mining and fusing from multiple egocentric views. Although the egocentric perspective view alleviates some weaknesses of the birds-eye view, the sectored grid partition becomes so coarse in the distance that the targets and surrounding context mix together, which makes the features less discriminative. In this paper, we generalize the research on 3D multi-view learning and propose a novel multi-view-based 3D detection method, named X-view, to overcome the drawbacks of the multi-view methods. Specifically, X-view breaks through the traditional limitation about the perspective view whose original point must be consistent with the 3D Cartesian coordinate. X-view is designed as a general paradigm that can be applied on almost any 3D detectors based on LiDAR with only little increment of running time, no matter it is voxel/grid-based or raw-point-based. We conduct experiments on KITTI and NuScenes datasets to demonstrate the robustness and effectiveness of our proposed X-view. The results show that X-view obtains consistent improvements when combined with four mainstream state-of-the-art 3D methods: SECOND, PointRCNN, Part-A^2, and PV-RCNN.
Shuffler: A Large Scale Data Management Tool for ML in Computer Vision
Apr 11, 2021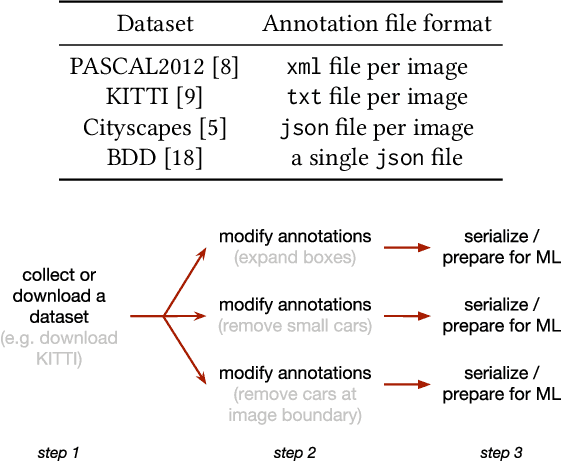

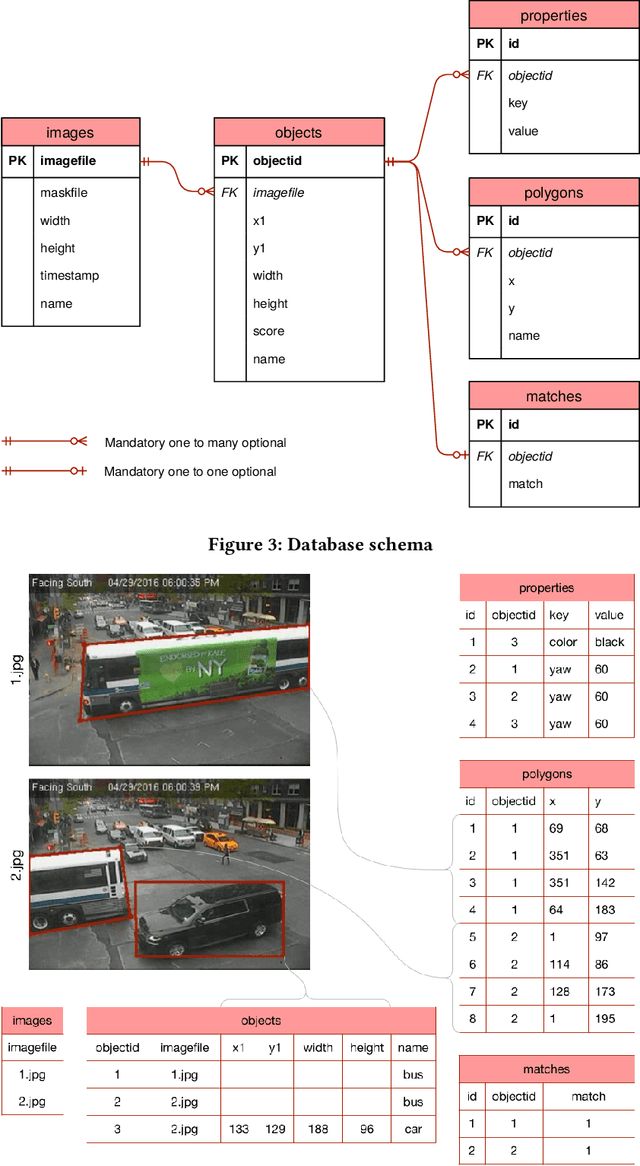
Datasets in the computer vision academic research community are primarily static. Once a dataset is accepted as a benchmark for a computer vision task, researchers working on this task will not alter it in order to make their results reproducible. At the same time, when exploring new tasks and new applications, datasets tend to be an ever changing entity. A practitioner may combine existing public datasets, filter images or objects in them, change annotations or add new ones to fit a task at hand, visualize sample images, or perhaps output statistics in the form of text or plots. In fact, datasets change as practitioners experiment with data as much as with algorithms, trying to make the most out of machine learning models. Given that ML and deep learning call for large volumes of data to produce satisfactory results, it is no surprise that the resulting data and software management associated to dealing with live datasets can be quite complex. As far as we know, there is no flexible, publicly available instrument to facilitate manipulating image data and their annotations throughout a ML pipeline. In this work, we present Shuffler, an open source tool that makes it easy to manage large computer vision datasets. It stores annotations in a relational, human-readable database. Shuffler defines over 40 data handling operations with annotations that are commonly useful in supervised learning applied to computer vision and supports some of the most well-known computer vision datasets. Finally, it is easily extensible, making the addition of new operations and datasets a task that is fast and easy to accomplish.
ThetA -- fast and robust clustering via a distance parameter
Feb 13, 2021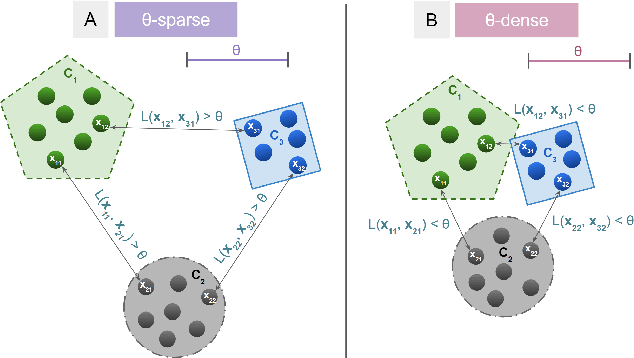
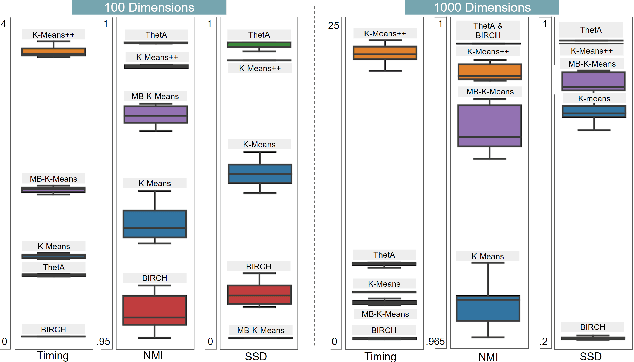
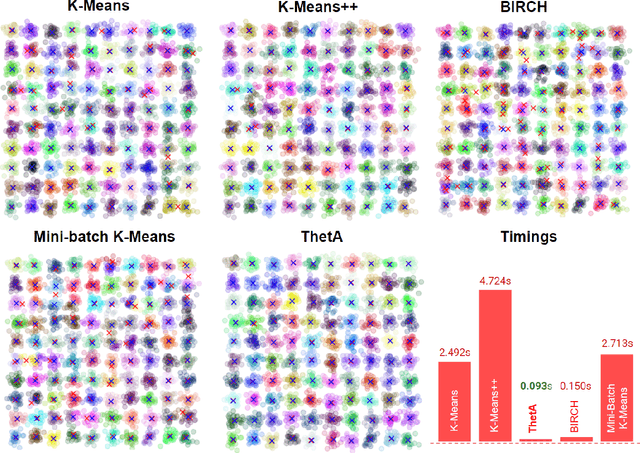
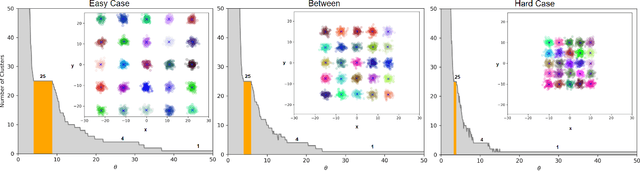
Clustering is a fundamental problem in machine learning where distance-based approaches have dominated the field for many decades. This set of problems is often tackled by partitioning the data into K clusters where the number of clusters is chosen apriori. While significant progress has been made on these lines over the years, it is well established that as the number of clusters or dimensions increase, current approaches dwell in local minima resulting in suboptimal solutions. In this work, we propose a new set of distance threshold methods called Theta-based Algorithms (ThetA). Via experimental comparisons and complexity analyses we show that our proposed approach outperforms existing approaches in: a) clustering accuracy and b) time complexity. Additionally, we show that for a large class of problems, learning the optimal threshold is straightforward in comparison to learning K. Moreover, we show how ThetA can infer the sparsity of datasets in higher dimensions.
Learning-Based Phase Compression and Quantization for Massive MIMO CSI Feedback with Magnitude-Aided Information
Feb 28, 2021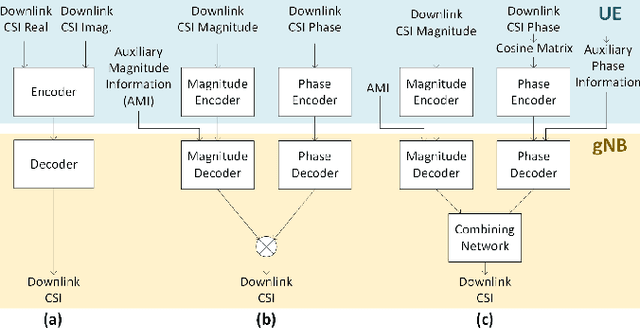
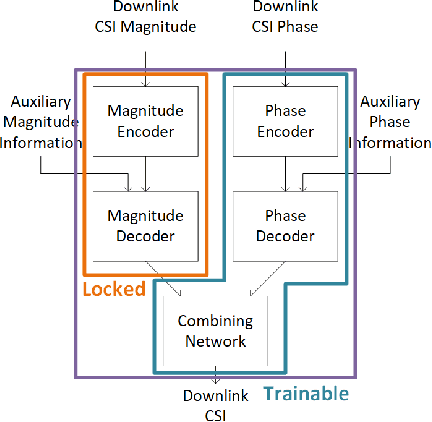
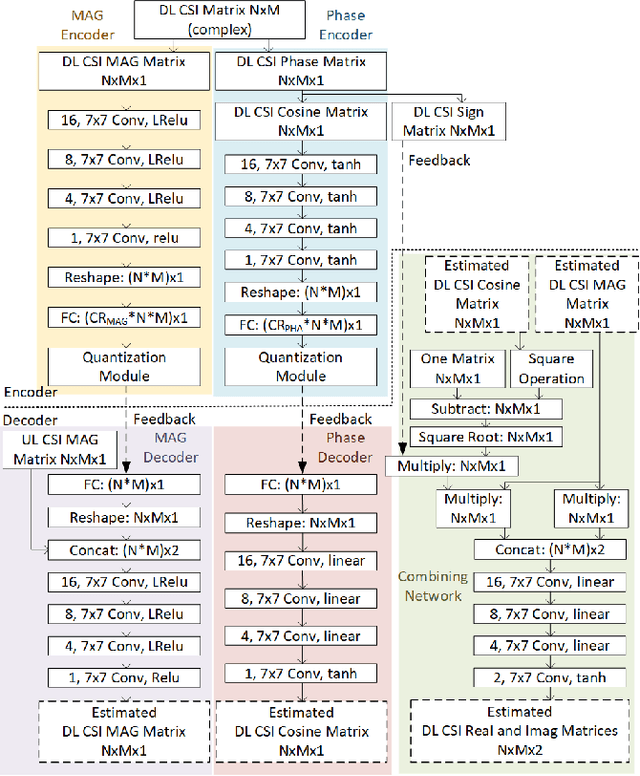
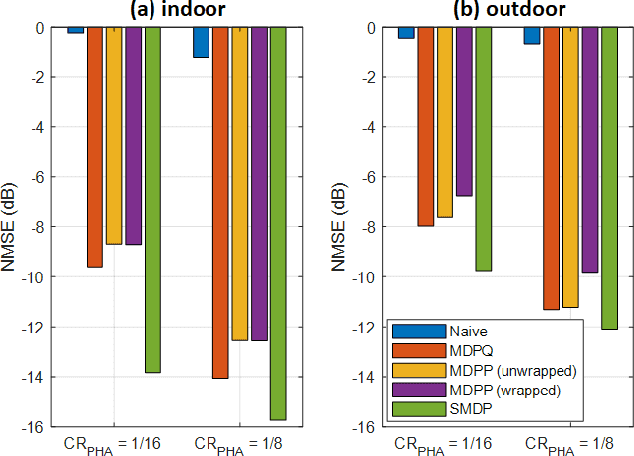
In frequency-division duplexing (FDD) massive multiple-input multiple-output (MIMO) wireless systems, deep learning techniques are regarded as one of the most efficient solutions for CSI recovery. In recent times, to achieve better CSI magnitude recovery at base stations, advanced learning-based CSI feedback solutions decouple magnitude and phase recovery to fully leverage the strong correlation between current CSI magnitudes and those of previous time slots, uplink band, and near locations. However, the CSI phase recovery is a major challenge to further enhance the CSI recovery owing to its complicated patterns. In this letter, we propose a learning-based CSI feedback framework based on limited feedback and magnitude-aided information. In contrast to previous works, our proposed framework with a proposed loss function enables end-to-end learning to jointly optimize the CSI magnitude and phase recovery performance. Numerical simulations show that, the proposed loss function outperform alternate approaches for phase recovery over the overall CSI recovery in both indoor and outdoor scenarios. The performance of the proposed framework was also examined using different core layer designs.
Longitudinal detection of radiological abnormalities with time-modulated LSTM
Jul 16, 2018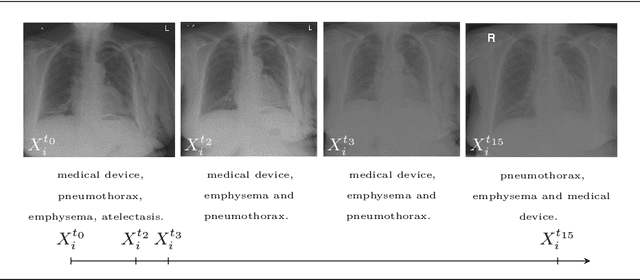
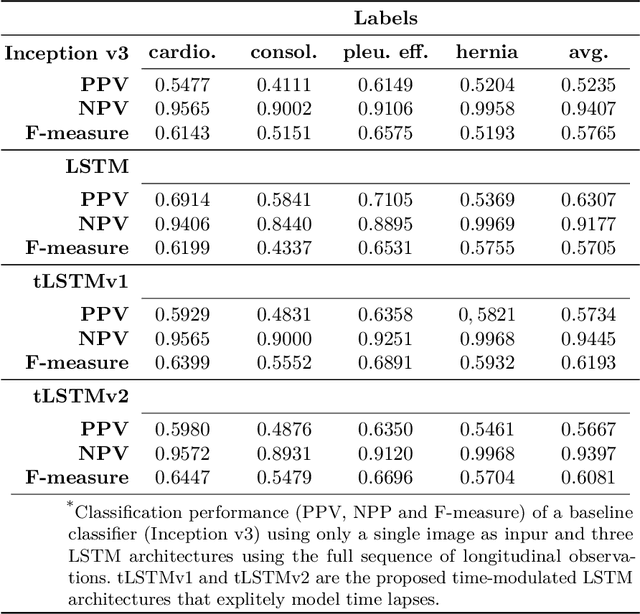
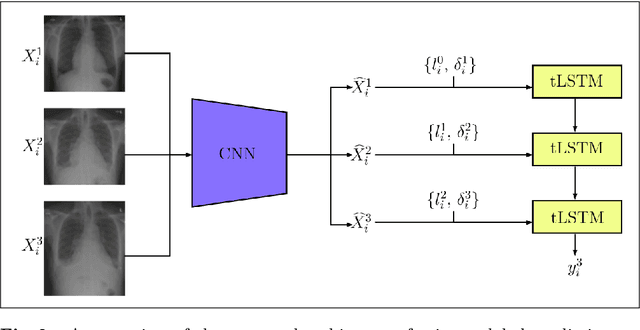
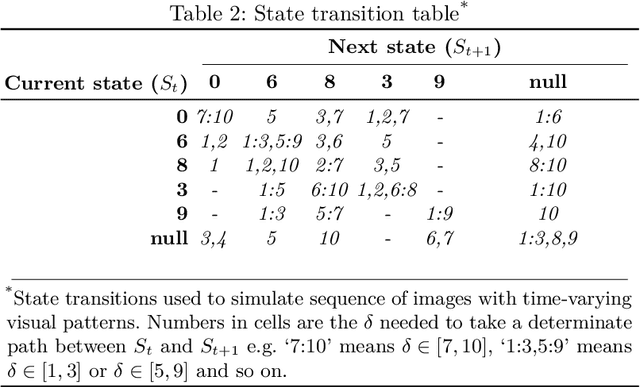
Convolutional neural networks (CNNs) have been successfully employed in recent years for the detection of radiological abnormalities in medical images such as plain x-rays. To date, most studies use CNNs on individual examinations in isolation and discard previously available clinical information. In this study we set out to explore whether Long-Short-Term-Memory networks (LSTMs) can be used to improve classification performance when modelling the entire sequence of radiographs that may be available for a given patient, including their reports. A limitation of traditional LSTMs, though, is that they implicitly assume equally-spaced observations, whereas the radiological exams are event-based, and therefore irregularly sampled. Using both a simulated dataset and a large-scale chest x-ray dataset, we demonstrate that a simple modification of the LSTM architecture, which explicitly takes into account the time lag between consecutive observations, can boost classification performance. Our empirical results demonstrate improved detection of commonly reported abnormalities on chest x-rays such as cardiomegaly, consolidation, pleural effusion and hiatus hernia.
* Submitted to 4th MICCAI Workshop on Deep Learning in Medical Imaging Analysis
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 05, 2019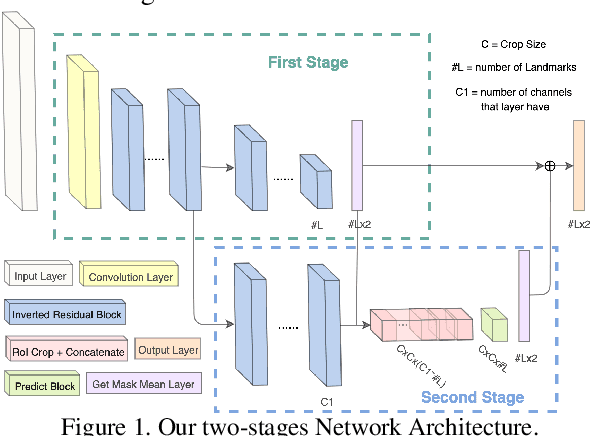

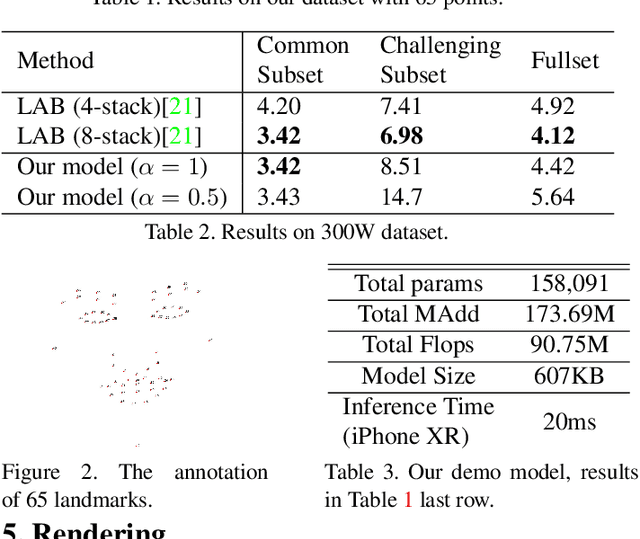
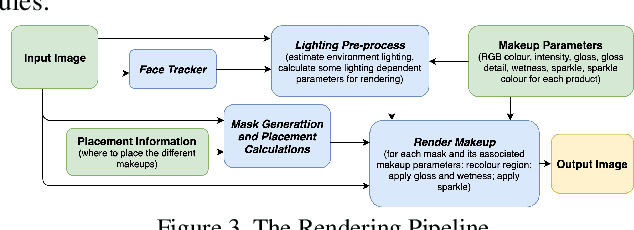
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. We prepared a demo link to our Web demo that can be tested in Chrome and Firefox on Android, or in Safari on iOS: https://s3.amazonaws.com/makeup-paper-demo/index.html
ICASSP 2021 Deep Noise Suppression Challenge: Decoupling Magnitude and Phase Optimization with a Two-Stage Deep Network
Feb 08, 2021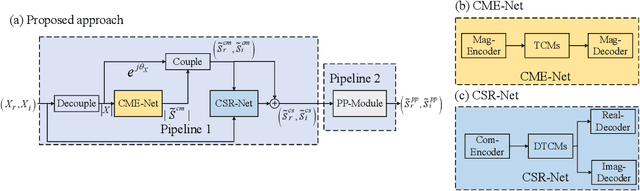
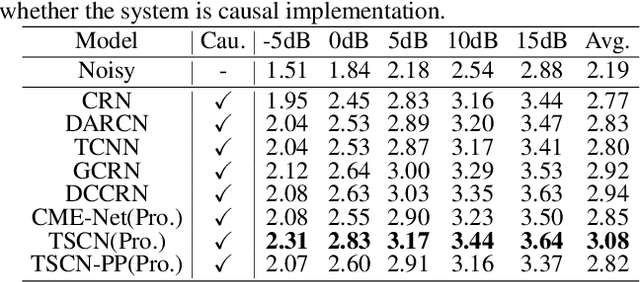
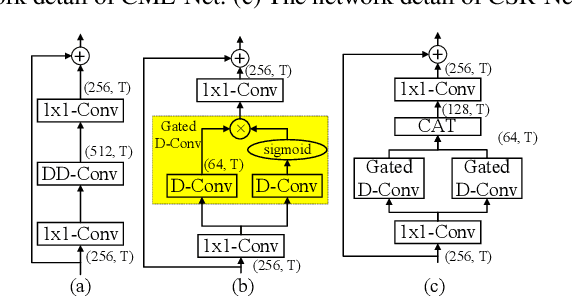
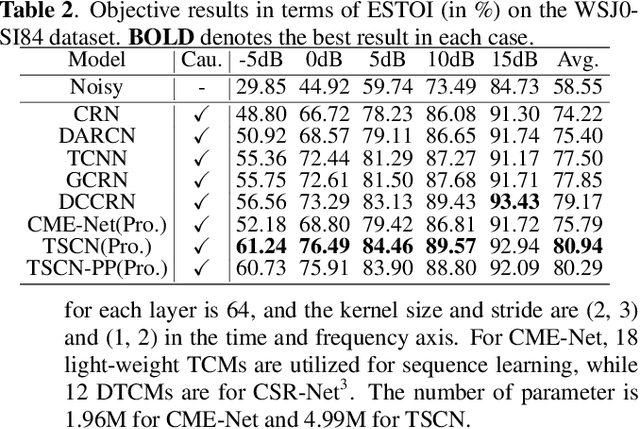
It remains a tough challenge to recover the speech signals contaminated by various noises under real acoustic environments. To this end, we propose a novel system for denoising in the complicated applications, which is mainly comprised of two pipelines, namely a two-stage network and a post-processing module. The first pipeline is proposed to decouple the optimization problem w:r:t: magnitude and phase, i.e., only the magnitude is estimated in the first stage and both of them are further refined in the second stage. The second pipeline aims to further suppress the remaining unnatural distorted noise, which is demonstrated to sufficiently improve the subjective quality. In the ICASSP 2021 Deep Noise Suppression (DNS) Challenge, our submitted system ranked top-1 for the real-time track 1 in terms of Mean Opinion Score (MOS) with ITU-T P.808 framework.
Deep Transfer Learning for WiFi Localization
Mar 08, 2021
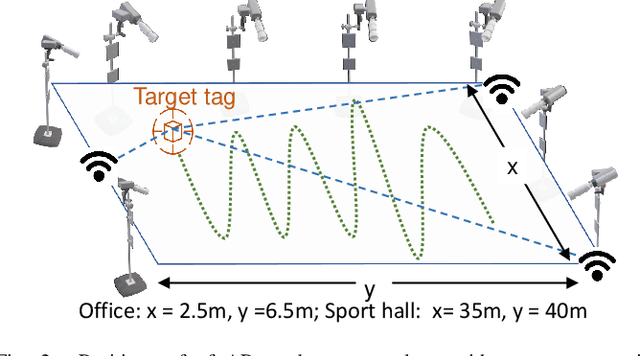
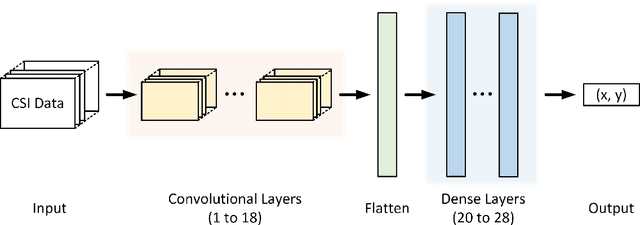
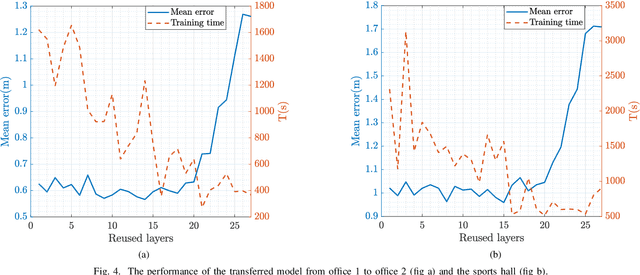
This paper studies a WiFi indoor localisation technique based on using a deep learning model and its transfer strategies. We take CSI packets collected via the WiFi standard channel sounding as the training dataset and verify the CNN model on the subsets collected in three experimental environments. We achieve a localisation accuracy of 46.55 cm in an ideal $(6.5m \times 2.5m)$ office with no obstacles, 58.30 cm in an office with obstacles, and 102.8 cm in a sports hall $(40 \times 35m)$. Then, we evaluate the transfer ability of the proposed model to different environments. The experimental results show that, for a trained localisation model, feature extraction layers can be directly transferred to other models and only the fully connected layers need to be retrained to achieve the same baseline accuracy with non-transferred base models. This can save 60% of the training parameters and reduce the training time by more than half. Finally, an ablation study of the training dataset shows that, in both office and sport hall scenarios, after reusing the feature extraction layers of the base model, only 55% of the training data is required to obtain the models' accuracy similar to the base models.
Exploiting Attention-based Sequence-to-Sequence Architectures for Sound Event Localization
Feb 28, 2021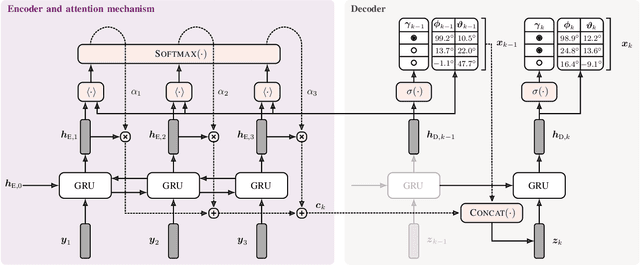
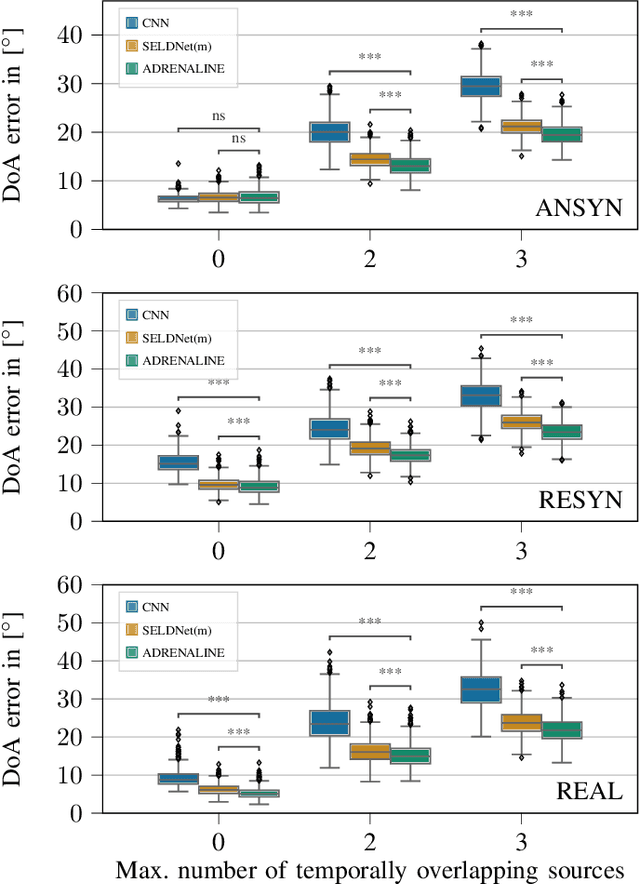
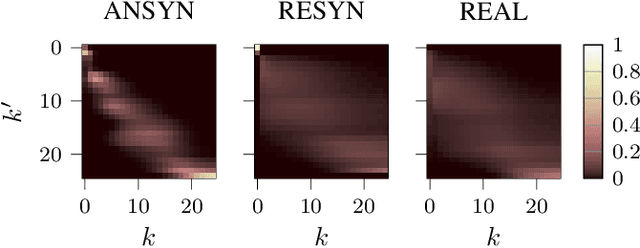
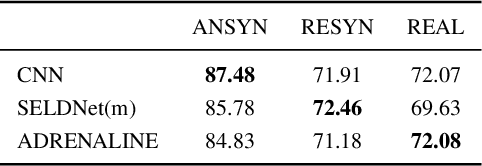
Sound event localization frameworks based on deep neural networks have shown increased robustness with respect to reverberation and noise in comparison to classical parametric approaches. In particular, recurrent architectures that incorporate temporal context into the estimation process seem to be well-suited for this task. This paper proposes a novel approach to sound event localization by utilizing an attention-based sequence-to-sequence model. These types of models have been successfully applied to problems in natural language processing and automatic speech recognition. In this work, a multi-channel audio signal is encoded to a latent representation, which is subsequently decoded to a sequence of estimated directions-of-arrival. Herein, attentions allow for capturing temporal dependencies in the audio signal by focusing on specific frames that are relevant for estimating the activity and direction-of-arrival of sound events at the current time-step. The framework is evaluated on three publicly available datasets for sound event localization. It yields superior localization performance compared to state-of-the-art methods in both anechoic and reverberant conditions.
Forecasting blood sugar levels in Diabetes with univariate algorithms
Jan 21, 2021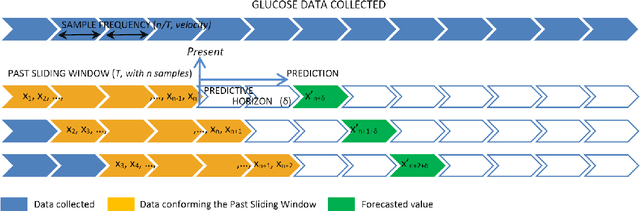
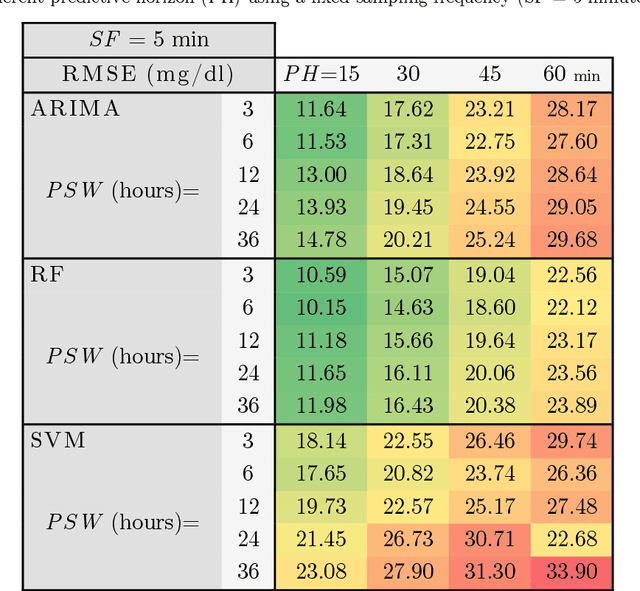
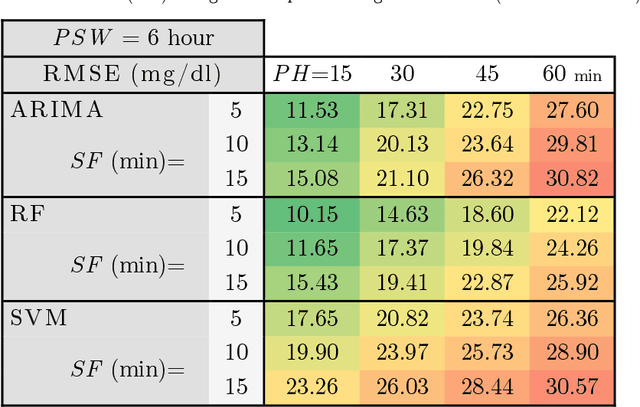
AI procedures joined with wearable gadgets can convey exact transient blood glucose level forecast models. Also, such models can learn customized glucose-insulin elements dependent on the sensor information gathered by observing a few parts of the physiological condition and every day movement of a person. Up to this point, the predominant methodology for creating information driven forecast models was to gather "however much information as could be expected" to help doctors and patients ideally change treatment. The goal of this work was to examine the base information assortment, volume, and speed needed to accomplish exact individual driven diminutive term expectation models. We built up a progression of these models utilizing distinctive AI time arrangement guaging strategies that are appropriate for execution inside a wearable processor. We completed a broad aloof patient checking concentrate in genuine conditions to fabricate a strong informational collection. The examination included a subset of type-1 diabetic subjects wearing a glimmer glucose checking framework. We directed a relative quantitative assessment of the presentation of the created information driven expectation models and comparing AI methods. Our outcomes show that precise momentary forecast can be accomplished by just checking interstitial glucose information over a brief timeframe and utilizing a low examining recurrence. The models created can anticipate glucose levels inside a 15-minute skyline with a normal mistake as low as 15.43 mg/dL utilizing just 24 memorable qualities gathered inside a time of 6 hours, and by expanding the inspecting recurrence to incorporate 72 qualities, the normal blunder is limited to 10.15 mg/dL. Our forecast models are reasonable for execution inside a wearable gadget, requiring the base equipment necessities while simultaneously accomplishing high expectation precision.