 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discovering Causal Structure with Reproducing-Kernel Hilbert Space $ε$-Machines
Nov 23, 2020
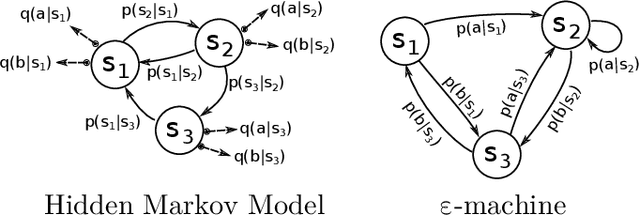
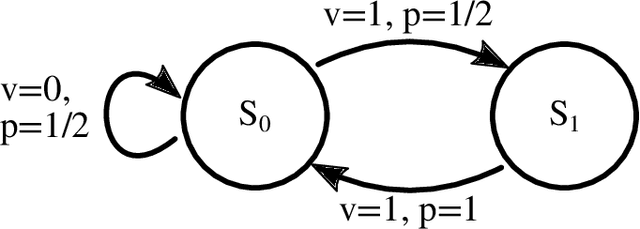
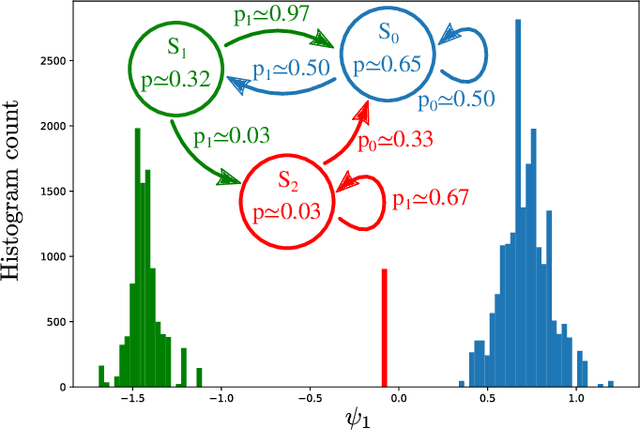
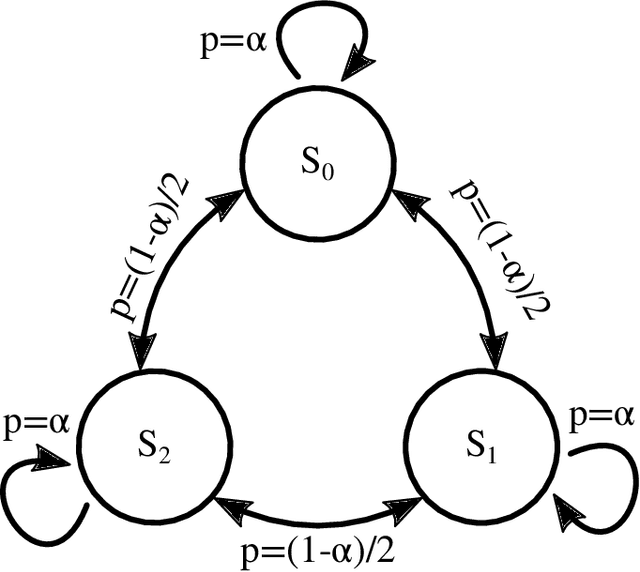
We merge computational mechanics' definition of causal states (predictively-equivalent histories) with reproducing-kernel Hilbert space (RKHS) representation inference. The result is a widely-applicable method that infers causal structure directly from observations of a system's behaviors whether they are over discrete or continuous events or time. A structural representation -- a finite- or infinite-state kernel $\epsilon$-machine -- is extracted by a reduced-dimension transform that gives an efficient representation of causal states and their topology. In this way, the system dynamics are represented by a stochastic (ordinary or partial) differential equation that acts on causal states. We introduce an algorithm to estimate the associated evolution operator. Paralleling the Fokker-Plank equation, it efficiently evolves causal-state distributions and makes predictions in the original data space via an RKHS functional mapping. We demonstrate these techniques, together with their predictive abilities, on discrete-time, discrete-value infinite Markov-order processes generated by finite-state hidden Markov models with (i) finite or (ii) uncountably-infinite causal states and (iii) a continuous-time, continuous-value process generated by a thermally-driven chaotic flow. The method robustly estimates causal structure in the presence of varying external and measurement noise levels.
Dynamic Routing for Traffic Flow through Multi-agent Systems
May 02, 2021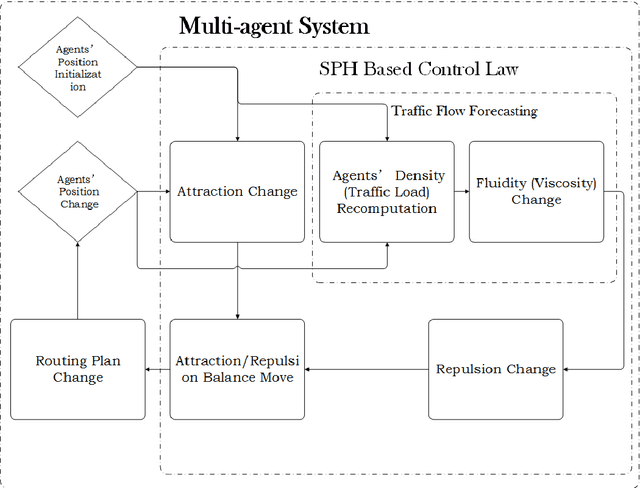
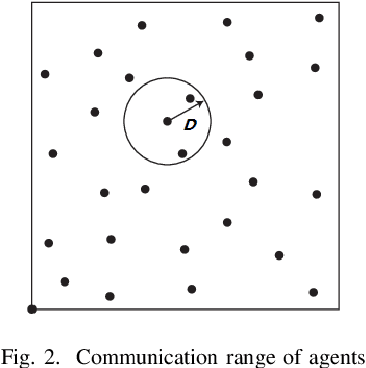
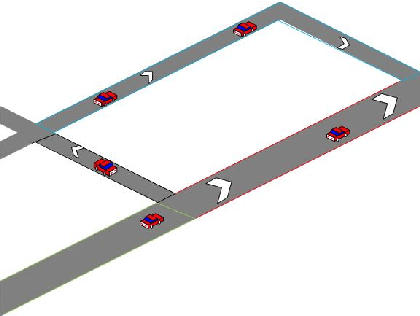
Routing strategies for traffics and vehicles have been historically studied. However, in the absence of considering drivers' preferences, current route planning algorithms are developed under ideal situations where all drivers are expected to behave rationally and properly. Especially, for jumbled urban road networks, drivers' actual routing strategies deteriorated to a series of empirical and selfish decisions that result in congestion. Self-evidently, if minimum mobility can be kept, traffic congestion is avoidable by traffic load dispersing. In this paper, we establish a novel dynamic routing method catering drivers' preferences and retaining maximum traffic mobility simultaneously through multi-agent systems (MAS). Modeling human-drivers' behavior through agents' dynamics, MAS can analyze the global behavior of the entire traffic flow. Therefore, regarding agents as particles in smoothed particles hydrodynamics (SPH), we can enforce the traffic flow to behave like a real flow. Thereby, with the characteristic of distributing itself uniformly in road networks, our dynamic routing method realizes traffic load balancing without violating the individual time-saving motivation. Moreover, as a discrete control mechanism, our method is robust to chaos meaning driver's disobedience can be tolerated. As controlled by SPH based density, the only intelligent transportation system (ITS) we require is the location-based service (LBS). A mathematical proof is accomplished to scrutinize the stability of the proposed control law. Also, multiple testing cases are built to verify the effectiveness of the proposed dynamic routing algorithm.
The MIT Humanoid Robot: Design, Motion Planning, and Control For Acrobatic Behaviors
Apr 19, 2021
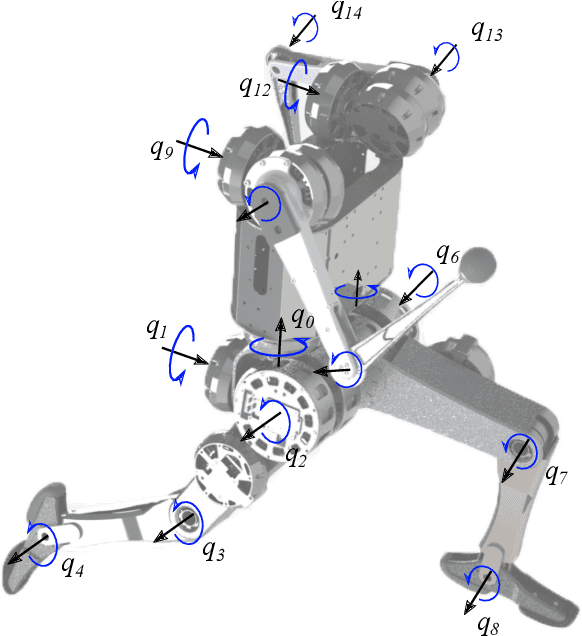

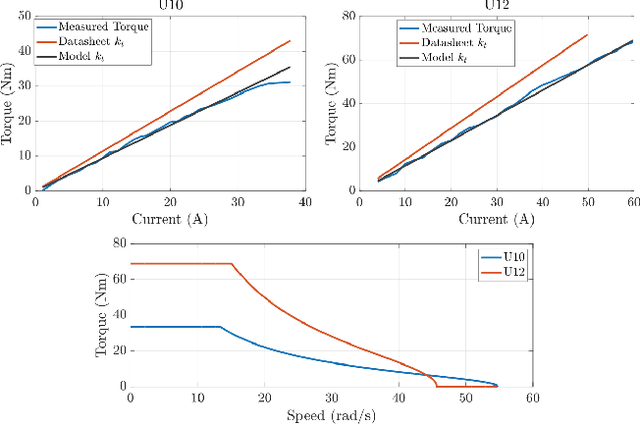
Demonstrating acrobatic behavior of a humanoid robot such as flips and spinning jumps requires systematic approaches across hardware design, motion planning, and control. In this paper, we present a new humanoid robot design, an actuator-aware kino-dynamic motion planner, and a landing controller as part of a practical system design for highly dynamic motion control of the humanoid robot. To achieve the impulsive motions, we develop two new proprioceptive actuators and experimentally evaluate their performance using our custom-designed dynamometer. The actuator's torque, velocity, and power limits are reflected in our kino-dynamic motion planner by approximating the configuration-dependent reaction force limits and in our dynamics simulator by including actuator dynamics along with the robot's full-body dynamics. For the landing control, we effectively integrate model-predictive control and whole-body impulse control by connecting them in a dynamically consistent way to accomplish both the long-time horizon optimal control and high-bandwidth full-body dynamics-based feedback. Actuators' torque output over the entire motion are validated based on the velocity-torque model including battery voltage droop and back-EMF voltage. With the carefully designed hardware and control framework, we successfully demonstrate dynamic behaviors such as back flips, front flips, and spinning jumps in our realistic dynamics simulation.
Guided Upsampling Network for Real-Time Semantic Segmentation
Jul 19, 2018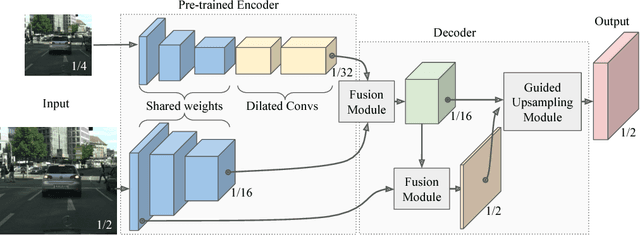
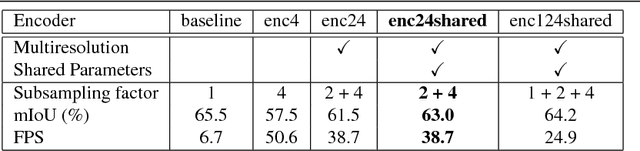
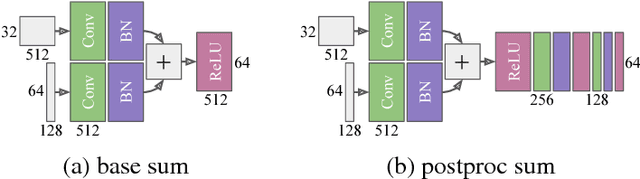
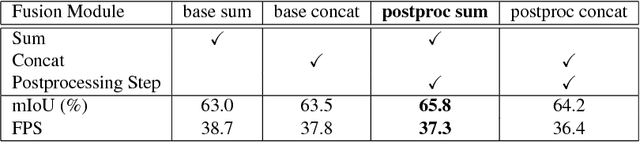
Semantic segmentation architectures are mainly built upon an encoder-decoder structure. These models perform subsequent downsampling operations in the encoder. Since operations on high-resolution activation maps are computationally expensive, usually the decoder produces output segmentation maps by upsampling with parameters-free operators like bilinear or nearest-neighbor. We propose a Neural Network named Guided Upsampling Network which consists of a multiresolution architecture that jointly exploits high-resolution and large context information. Then we introduce a new module named Guided Upsampling Module (GUM) that enriches upsampling operators by introducing a learnable transformation for semantic maps. It can be plugged into any existing encoder-decoder architecture with little modifications and low additional computation cost. We show with quantitative and qualitative experiments how our network benefits from the use of GUM module. A comprehensive set of experiments on the publicly available Cityscapes dataset demonstrates that Guided Upsampling Network can efficiently process high-resolution images in real-time while attaining state-of-the art performances.
ECINN: Efficient Counterfactuals from Invertible Neural Networks
Mar 25, 2021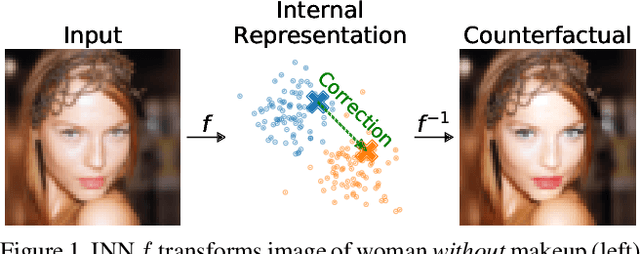
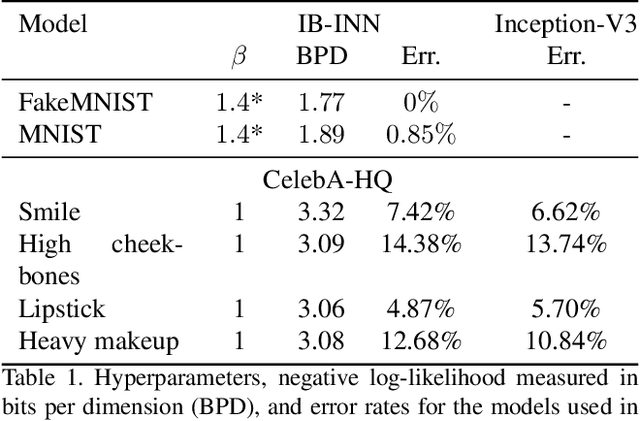
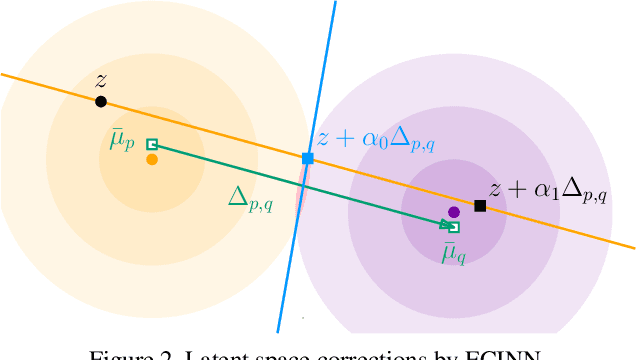

Counterfactual examples identify how inputs can be altered to change the predicted class of a classifier, thus opening up the black-box nature of, e.g., deep neural networks. We propose a method, ECINN, that utilizes the generative capacities of invertible neural networks for image classification to generate counterfactual examples efficiently. In contrast to competing methods that sometimes need a thousand evaluations or more of the classifier, ECINN has a closed-form expression and generates a counterfactual in the time of only two evaluations. Arguably, the main challenge of generating counterfactual examples is to alter only input features that affect the predicted outcome, i.e., class-dependent features. Our experiments demonstrate how ECINN alters class-dependent image regions to change the perceptual and predicted class of the counterfactuals. Additionally, we extend ECINN to also produce heatmaps (ECINNh) for easy inspection of, e.g., pairwise class-dependent changes in the generated counterfactual examples. Experimentally, we find that ECINNh outperforms established methods that generate heatmap-based explanations.
Generation and frame characteristics of predefined evenly-distributed class centroids for pattern classification
May 02, 2021
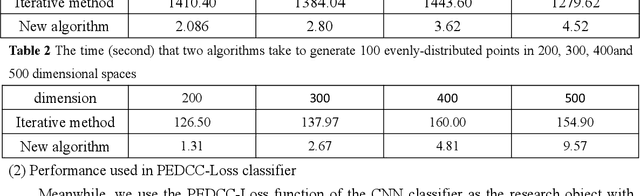
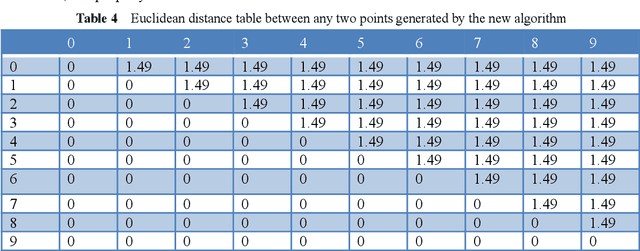
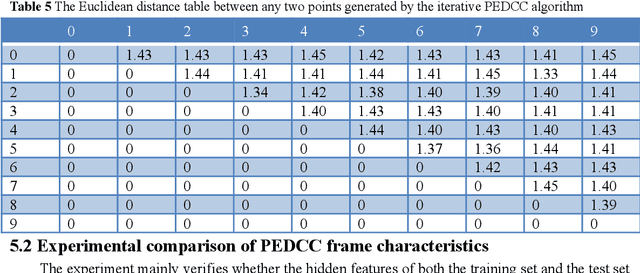
Predefined evenly-distributed class centroids (PEDCC) can be widely used in models and algorithms of pattern classification, such as CNN classifiers, classification autoencoders, clustering, and semi-supervised learning, etc. Its basic idea is to predefine the class centers, which are evenly-distributed on the unit hypersphere in feature space, to maximize the inter-class distance. The previous method of generating PEDCC uses an iterative algorithm based on a charge model, that is, the initial values of various centers (charge positions) are randomly set from the normal distribution, and the charge positions are updated iteratively with the help of the repulsive force between charges of the same polarity. The class centers generated by the algorithm will produce some errors with the theoretically evenly-distributed points, and the generation time will be longer. This paper takes advantage of regular polyhedron in high-dimensional space and the evenly distribution of points on the n dimensional hypersphere to generate PEDCC mathematically. Then, we discussed the basic and extensive characteristics of the frames formed by PEDCC. Finally, experiments show that new algorithm is not only faster than the iterative method, but also more accurate in position. The mathematical analysis and experimental results of this paper can provide a theoretical tool for using PEDCC to solve the key problems in the field of pattern recognition, such as interpretable supervised/unsupervised learning, incremental learning, uncertainty analysis and so on.
A LiDAR Assisted Control Module with High Precision in Parking Scenarios for Autonomous Driving Vehicle
May 02, 2021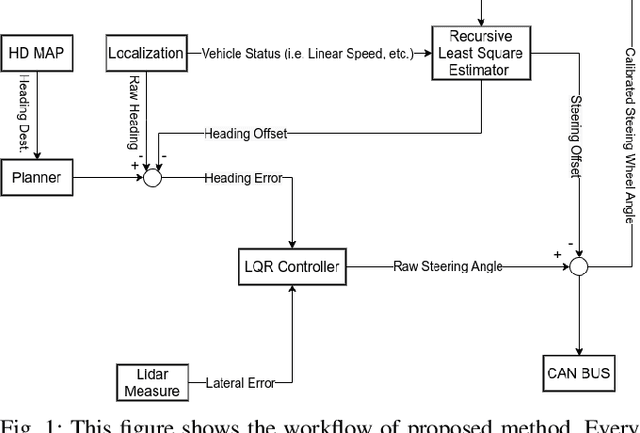
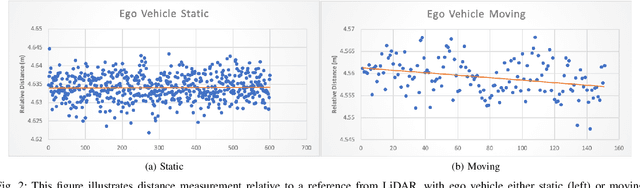
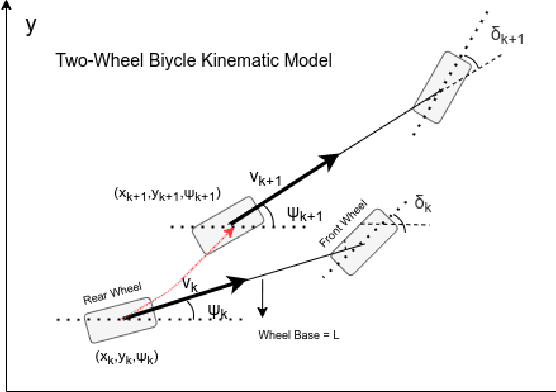
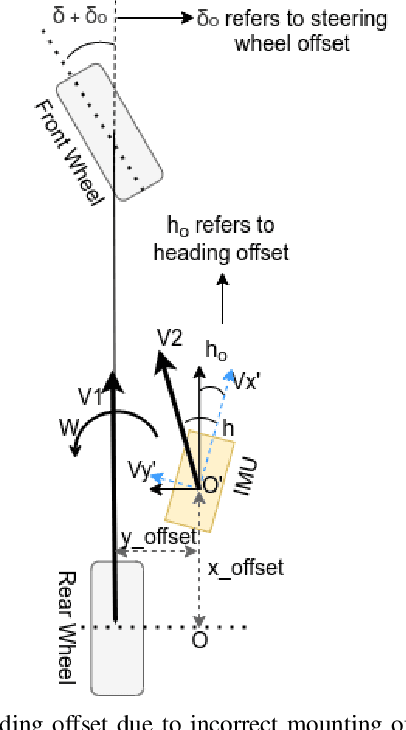
Autonomous driving has been quite promising in recent years. The public has seen Robotaxi delivered by Waymo, Baidu, Cruise, and so on. While autonomous driving vehicles certainly have a bright future, we have to admit that it is still a long way to go for products such as Robotaxi. On the other hand, in less complex scenarios autonomous driving may have the potentiality to reliably outperform humans. For example, humans are good at interactive tasks (while autonomous driving systems usually do not), but we are often incompetent for tasks with strict precision demands. In this paper, we introduce a real-world, industrial scenario of which human drivers are not capable. The task required the ego vehicle to keep a stationary lateral distance (i.e. 3? <= 5 centimeters) with respect to a reference. To address this challenge, we redesigned the control module from Baidu Apollo open-source autonomous driving system. A precise (3? <= 2 centimeters) Error Feedback System was first built to partly replace the localization module. Then we investigated the control module thoroughly and added a real-time calibration algorithm to gain extra precision. We also built a simulation to fine-tune the control parameters. After all those works, the results are encouraging, showing that an end-to-end lateral precision with 3? <= 5 centimeters has been achieved. Further, we show that the results not only outperformed original Apollo modules but also beat specially trained and highly experienced human test drivers.
A Koopman Approach to Understanding Sequence Neural Models
Mar 10, 2021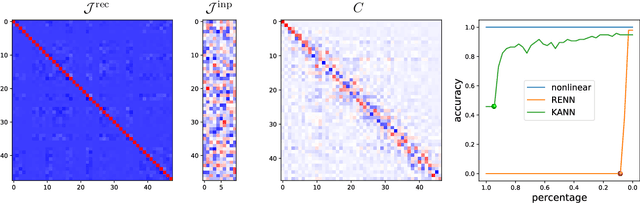

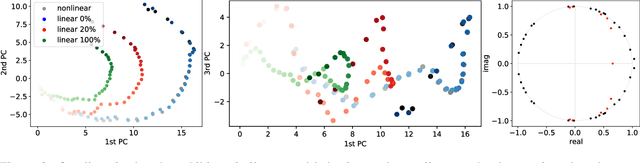

We introduce a new approach to understanding trained sequence neural models: the Koopman Analysis of Neural Networks (KANN) method. Motivated by the relation between time-series models and self-maps, we compute approximate Koopman operators that encode well the latent dynamics. Unlike other existing methods whose applicability is limited, our framework is global, and it has only weak constraints over the inputs. Moreover, the Koopman operator is linear, and it is related to a rich mathematical theory. Thus, we can use tools and insights from linear analysis and Koopman Theory in our study. For instance, we show that the operator eigendecomposition is instrumental in exploring the dominant features of the network. Our results extend across tasks and architectures as we demonstrate for the copy problem, and ECG classification and sentiment analysis tasks.
Approximating the Log-Partition Function
Feb 19, 2021
Variational approximation, such as mean-field (MF) and tree-reweighted (TRW), provide a computationally efficient approximation of the log-partition function for a generic graphical model. TRW provably provides an upper bound, but the approximation ratio is generally not quantified. As the primary contribution of this work, we provide an approach to quantify the approximation ratio through the property of the underlying graph structure. Specifically, we argue that (a variant of) TRW produces an estimate that is within factor $\frac{1}{\sqrt{\kappa(G)}}$ of the true log-partition function for any discrete pairwise graphical model over graph $G$, where $\kappa(G) \in (0,1]$ captures how far $G$ is from tree structure with $\kappa(G) = 1$ for trees and $2/N$ for the complete graph over $N$ vertices. As a consequence, the approximation ratio is $1$ for trees, $\sqrt{(d+1)/2}$ for any graph with maximum average degree $d$, and $\stackrel{\beta\to\infty}{\approx} 1+1/(2\beta)$ for graphs with girth (shortest cycle) at least $\beta \log N$. In general, $\kappa(G)$ is the solution of a max-min problem associated with $G$ that can be evaluated in polynomial time for any graph. Using samples from the uniform distribution over the spanning trees of G, we provide a near linear-time variant that achieves an approximation ratio equal to the inverse of square-root of minimal (across edges) effective resistance of the graph. We connect our results to the graph partition-based approximation method and thus provide a unified perspective. Keywords: variational inference, log-partition function, spanning tree polytope, minimum effective resistance, min-max spanning tree, local inference
Submodular Maximization via Taylor Series Approximation
Jan 19, 2021

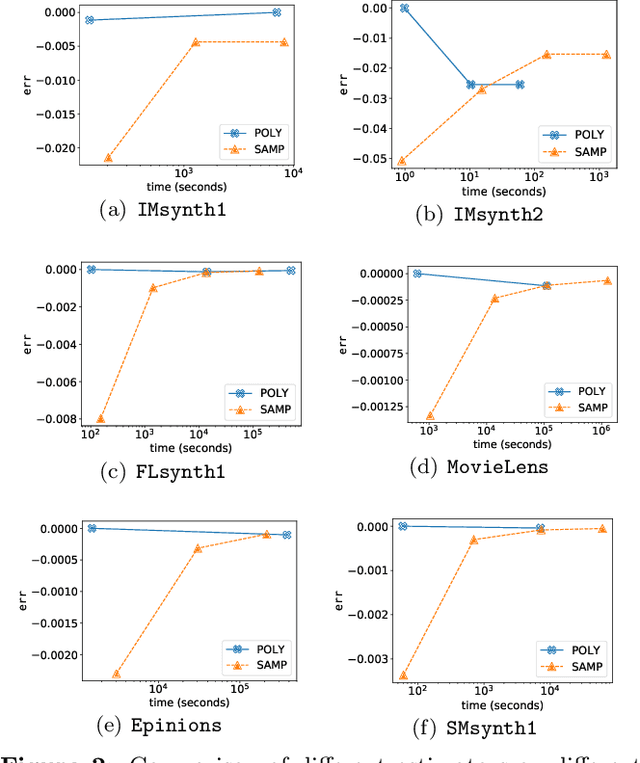
We study submodular maximization problems with matroid constraints, in particular, problems where the objective can be expressed via compositions of analytic and multilinear functions. We show that for functions of this form, the so-called continuous greedy algorithm attains a ratio arbitrarily close to $(1-1/e) \approx 0.63$ using a deterministic estimation via Taylor series approximation. This drastically reduces execution time over prior art that uses sampling.