 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuarkMedBench: A Real-World Scenario Driven Benchmark for Evaluating Large Language Models
Mar 14, 2026While Large Language Models (LLMs) excel on standardized medical exams, high scores often fail to translate to high-quality responses for real-world medical queries. Current evaluations rely heavily on multiple-choice questions, failing to capture the unstructured, ambiguous, and long-tail complexities inherent in genuine user inquiries. To bridge this gap, we introduce QuarkMedBench, an ecologically valid benchmark tailored for real-world medical LLM assessment. We compiled a massive dataset spanning Clinical Care, Wellness Health, and Professional Inquiry, comprising 20,821 single-turn queries and 3,853 multi-turn sessions. To objectively evaluate open-ended answers, we propose an automated scoring framework that integrates multi-model consensus with evidence-based retrieval to dynamically generate 220,617 fine-grained scoring rubrics (~9.8 per query). During evaluation, hierarchical weighting and safety constraints structurally quantify medical accuracy, key-point coverage, and risk interception, effectively mitigating the high costs and subjectivity of human grading. Experimental results demonstrate that the generated rubrics achieve a 91.8% concordance rate with clinical expert blind audits, establishing highly dependable medical reliability. Crucially, baseline evaluations on this benchmark reveal significant performance disparities among state-of-the-art models when navigating real-world clinical nuances, highlighting the limitations of conventional exam-based metrics. Ultimately, QuarkMedBench establishes a rigorous, reproducible yardstick for measuring LLM performance on complex health issues, while its framework inherently supports dynamic knowledge updates to prevent benchmark obsolescence.
Generation and frame characteristics of predefined evenly-distributed class centroids for pattern classification
May 02, 2021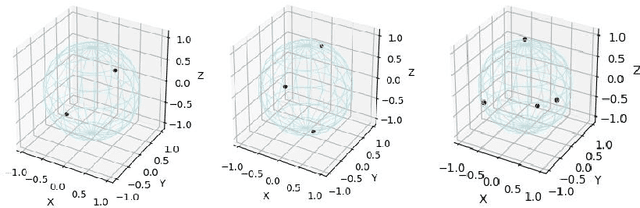
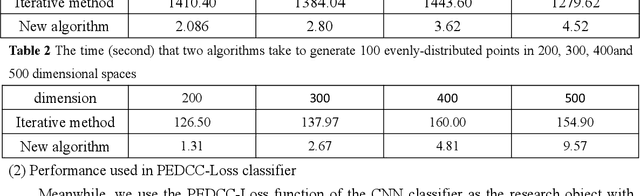
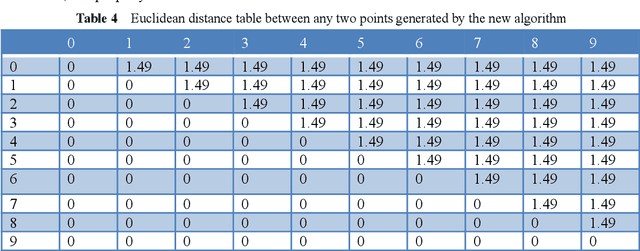
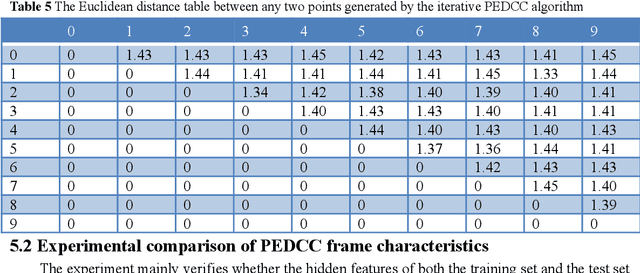
Predefined evenly-distributed class centroids (PEDCC) can be widely used in models and algorithms of pattern classification, such as CNN classifiers, classification autoencoders, clustering, and semi-supervised learning, etc. Its basic idea is to predefine the class centers, which are evenly-distributed on the unit hypersphere in feature space, to maximize the inter-class distance. The previous method of generating PEDCC uses an iterative algorithm based on a charge model, that is, the initial values of various centers (charge positions) are randomly set from the normal distribution, and the charge positions are updated iteratively with the help of the repulsive force between charges of the same polarity. The class centers generated by the algorithm will produce some errors with the theoretically evenly-distributed points, and the generation time will be longer. This paper takes advantage of regular polyhedron in high-dimensional space and the evenly distribution of points on the n dimensional hypersphere to generate PEDCC mathematically. Then, we discussed the basic and extensive characteristics of the frames formed by PEDCC. Finally, experiments show that new algorithm is not only faster than the iterative method, but also more accurate in position. The mathematical analysis and experimental results of this paper can provide a theoretical tool for using PEDCC to solve the key problems in the field of pattern recognition, such as interpretable supervised/unsupervised learning, incremental learning, uncertainty analysis and so on.