 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Concept Drift and Covariate Shift Detection Ensemble with Lagged Labels
Dec 12, 2020
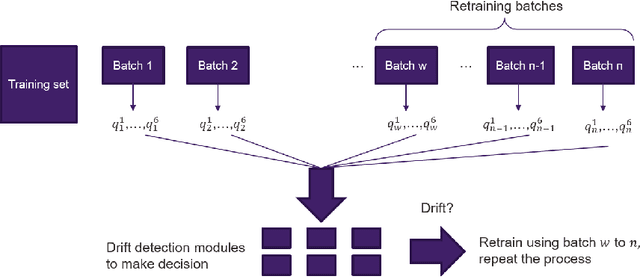
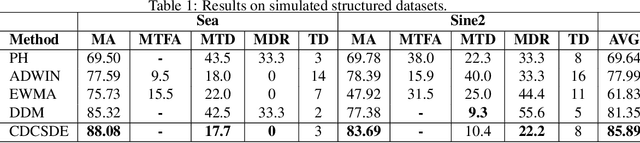
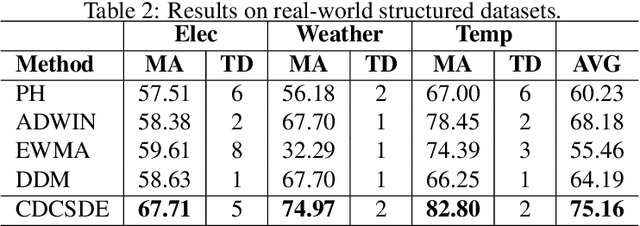
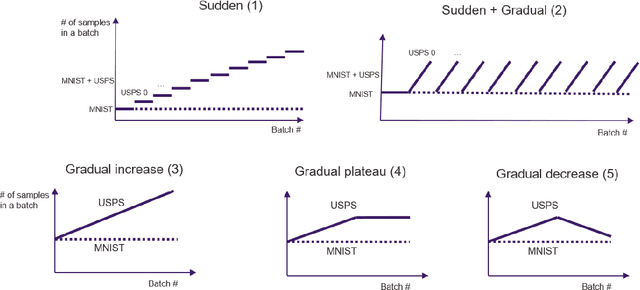
In model serving, having one fixed model during the entire often life-long inference process is usually detrimental to model performance, as data distribution evolves over time, resulting in lack of reliability of the model trained on historical data. It is important to detect changes and retrain the model in time. The existing methods generally have three weaknesses: 1) using only classification error rate as signal, 2) assuming ground truth labels are immediately available after features from samples are received and 3) unable to decide what data to use to retrain the model when change occurs. We address the first problem by utilizing six different signals to capture a wide range of characteristics of data, and we address the second problem by allowing lag of labels, where labels of corresponding features are received after a lag in time. For the third problem, our proposed method automatically decides what data to use to retrain based on the signals. Extensive experiments on structured and unstructured data for different type of data changes establish that our method consistently outperforms the state-of-the-art methods by a large margin.
Sentiment and Emotion Classification of Epidemic Related Bilingual data from Social Media
May 04, 2021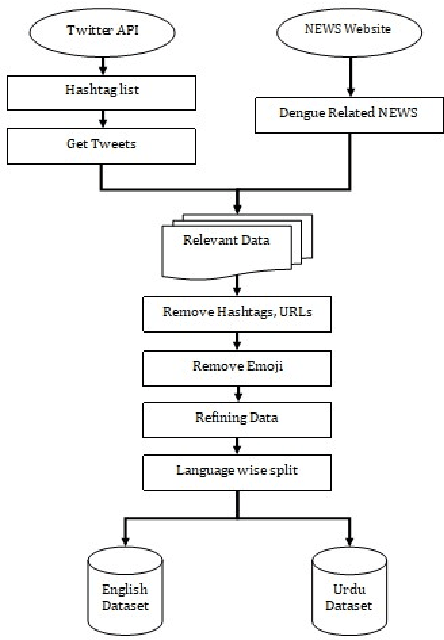
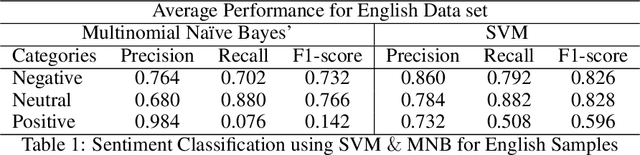
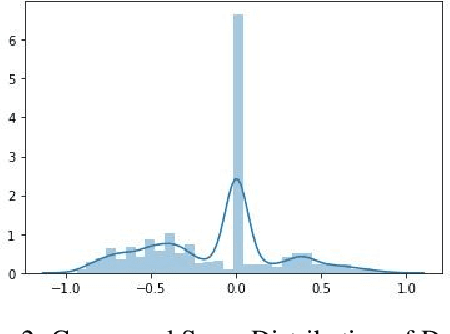
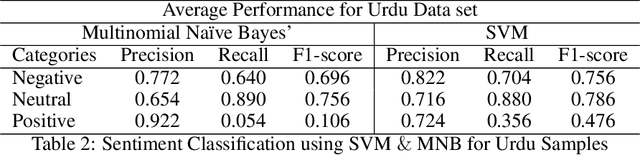
In recent years, sentiment analysis and emotion classification are two of the most abundantly used techniques in the field of Natural Language Processing (NLP). Although sentiment analysis and emotion classification are used commonly in applications such as analyzing customer reviews, the popularity of candidates contesting in elections, and comments about various sporting events; however, in this study, we have examined their application for epidemic outbreak detection. Early outbreak detection is the key to deal with epidemics effectively, however, the traditional ways of outbreak detection are time-consuming which inhibits prompt response from the respective departments. Social media platforms such as Twitter, Facebook, Instagram, etc. allow the users to express their thoughts related to different aspects of life, and therefore, serve as a substantial source of information in such situations. The proposed study exploits the bilingual (Urdu and English) data from Twitter and NEWS websites related to the dengue epidemic in Pakistan, and sentiment analysis and emotion classification are performed to acquire deep insights from the data set for gaining a fair idea related to an epidemic outbreak. Machine learning and deep learning algorithms have been used to train and implement the models for the execution of both tasks. The comparative performance of each model has been evaluated using accuracy, precision, recall, and f1-measure.
Ray-based framework for state identification in quantum dot devices
Feb 23, 2021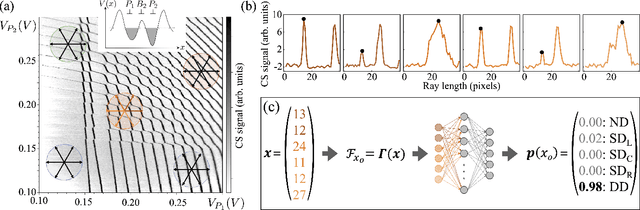
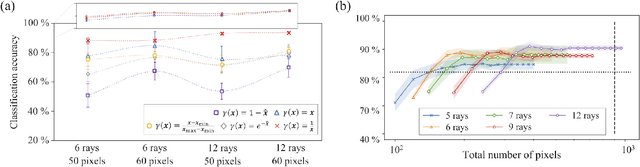
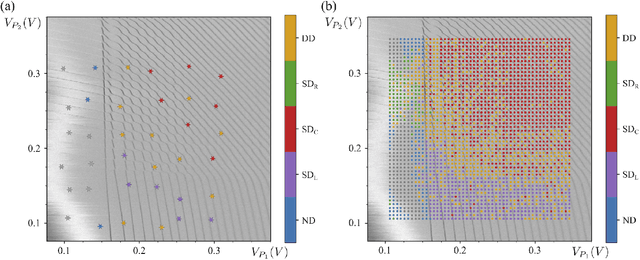
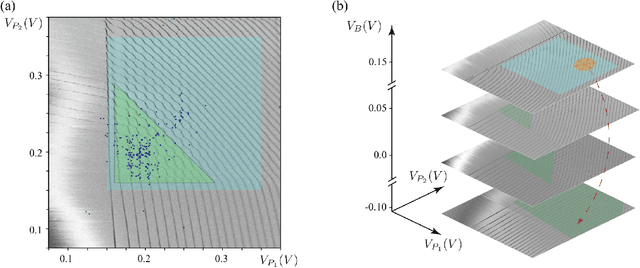
Quantum dots (QDs) defined with electrostatic gates are a leading platform for a scalable quantum computing implementation. However, with increasing numbers of qubits, the complexity of the control parameter space also grows. Traditional measurement techniques, relying on complete or near-complete exploration via two-parameter scans (images) of the device response, quickly become impractical with increasing numbers of gates. Here, we propose to circumvent this challenge by introducing a measurement technique relying on one-dimensional projections of the device response in the multi-dimensional parameter space. Dubbed as the ray-based classification (RBC) framework, we use this machine learning (ML) approach to implement a classifier for QD states, enabling automated recognition of qubit-relevant parameter regimes. We show that RBC surpasses the 82 % accuracy benchmark from the experimental implementation of image-based classification techniques from prior work while cutting down the number of measurement points needed by up to 70 %. The reduction in measurement cost is a significant gain for time-intensive QD measurements and is a step forward towards the scalability of these devices. We also discuss how the RBC-based optimizer, which tunes the device to a multi-qubit regime, performs when tuning in the two- and three-dimensional parameter spaces defined by plunger and barrier gates that control the dots. This work provides experimental validation of both efficient state identification and optimization with ML techniques for non-traditional measurements in quantum systems with high-dimensional parameter spaces and time-intensive measurements.
Neural Unsupervised Semantic Role Labeling
Apr 19, 2021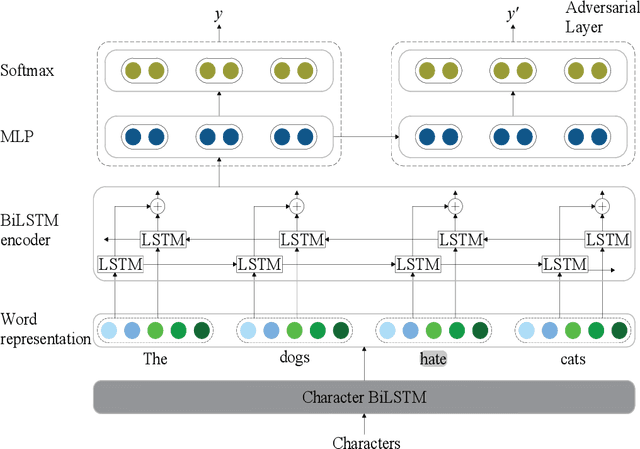
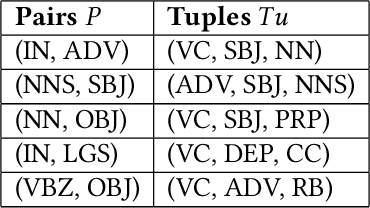
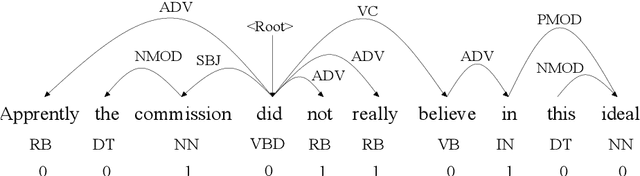
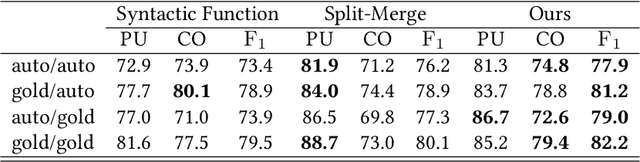
The task of semantic role labeling (SRL) is dedicated to finding the predicate-argument structure. Previous works on SRL are mostly supervised and do not consider the difficulty in labeling each example which can be very expensive and time-consuming. In this paper, we present the first neural unsupervised model for SRL. To decompose the task as two argument related subtasks, identification and clustering, we propose a pipeline that correspondingly consists of two neural modules. First, we train a neural model on two syntax-aware statistically developed rules. The neural model gets the relevance signal for each token in a sentence, to feed into a BiLSTM, and then an adversarial layer for noise-adding and classifying simultaneously, thus enabling the model to learn the semantic structure of a sentence. Then we propose another neural model for argument role clustering, which is done through clustering the learned argument embeddings biased towards their dependency relations. Experiments on CoNLL-2009 English dataset demonstrate that our model outperforms previous state-of-the-art baseline in terms of non-neural models for argument identification and classification.
Understanding the Performance of Knowledge Graph Embeddings in Drug Discovery
May 17, 2021
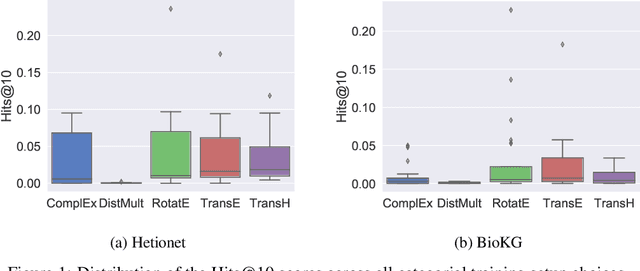
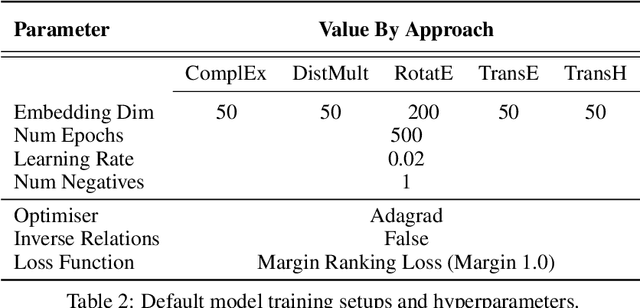
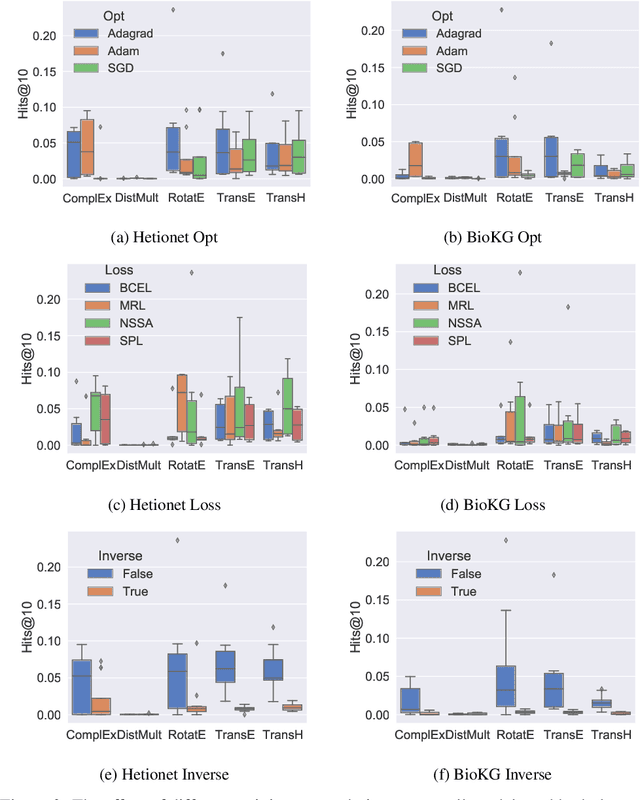
Knowledge Graphs (KG) and associated Knowledge Graph Embedding (KGE) models have recently begun to be explored in the context of drug discovery and have the potential to assist in key challenges such as target identification. In the drug discovery domain, KGs can be employed as part of a process which can result in lab-based experiments being performed, or impact on other decisions, incurring significant time and financial costs and most importantly, ultimately influencing patient healthcare. For KGE models to have impact in this domain, a better understanding of not only of performance, but also the various factors which determine it, is required. In this study we investigate, over the course of many thousands of experiments, the predictive performance of five KGE models on two public drug discovery-oriented KGs. Our goal is not to focus on the best overall model or configuration, instead we take a deeper look at how performance can be affected by changes in the training setup, choice of hyperparameters, model parameter initialisation seed and different splits of the datasets. Our results highlight that these factors have significant impact on performance and can even affect the ranking of models. Indeed these factors should be reported along with model architectures to ensure complete reproducibility and fair comparisons of future work, and we argue this is critical for the acceptance of use, and impact of KGEs in a biomedical setting. To aid reproducibility of our own work, we release all experimentation code.
Real-Time Document Image Classification using Deep CNN and Extreme Learning Machines
Nov 03, 2017


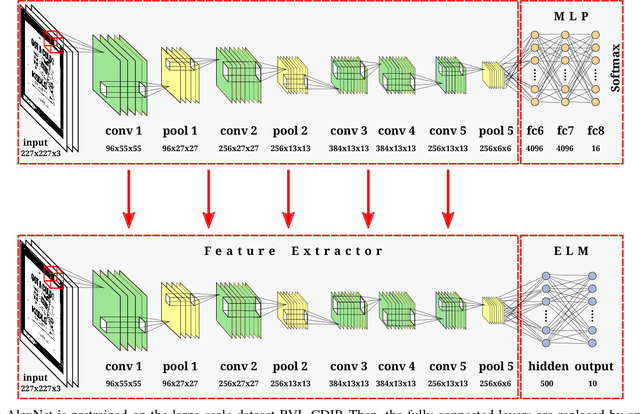
This paper presents an approach for real-time training and testing for document image classification. In production environments, it is crucial to perform accurate and (time-)efficient training. Existing deep learning approaches for classifying documents do not meet these requirements, as they require much time for training and fine-tuning the deep architectures. Motivated from Computer Vision, we propose a two-stage approach. The first stage trains a deep network that works as feature extractor and in the second stage, Extreme Learning Machines (ELMs) are used for classification. The proposed approach outperforms all previously reported structural and deep learning based methods with a final accuracy of 83.24% on Tobacco-3482 dataset, leading to a relative error reduction of 25% when compared to a previous Convolutional Neural Network (CNN) based approach (DeepDocClassifier). More importantly, the training time of the ELM is only 1.176 seconds and the overall prediction time for 2,482 images is 3.066 seconds. As such, this novel approach makes deep learning-based document classification suitable for large-scale real-time applications.
Fool Me Twice: Entailment from Wikipedia Gamification
Apr 10, 2021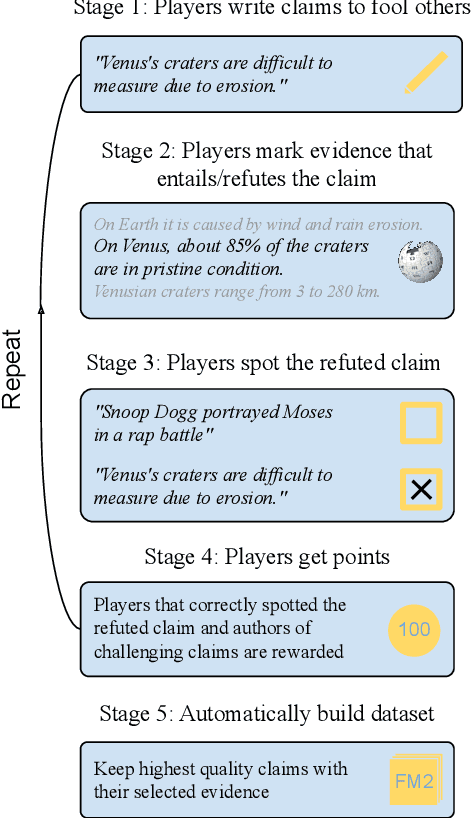
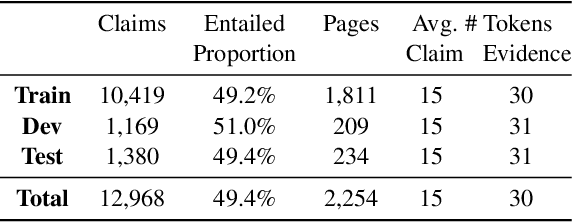

We release FoolMeTwice (FM2 for short), a large dataset of challenging entailment pairs collected through a fun multi-player game. Gamification encourages adversarial examples, drastically lowering the number of examples that can be solved using "shortcuts" compared to other popular entailment datasets. Players are presented with two tasks. The first task asks the player to write a plausible claim based on the evidence from a Wikipedia page. The second one shows two plausible claims written by other players, one of which is false, and the goal is to identify it before the time runs out. Players "pay" to see clues retrieved from the evidence pool: the more evidence the player needs, the harder the claim. Game-play between motivated players leads to diverse strategies for crafting claims, such as temporal inference and diverting to unrelated evidence, and results in higher quality data for the entailment and evidence retrieval tasks. We open source the dataset and the game code.
Deep Learning for EEG Seizure Detection in Preterm Infants
May 28, 2021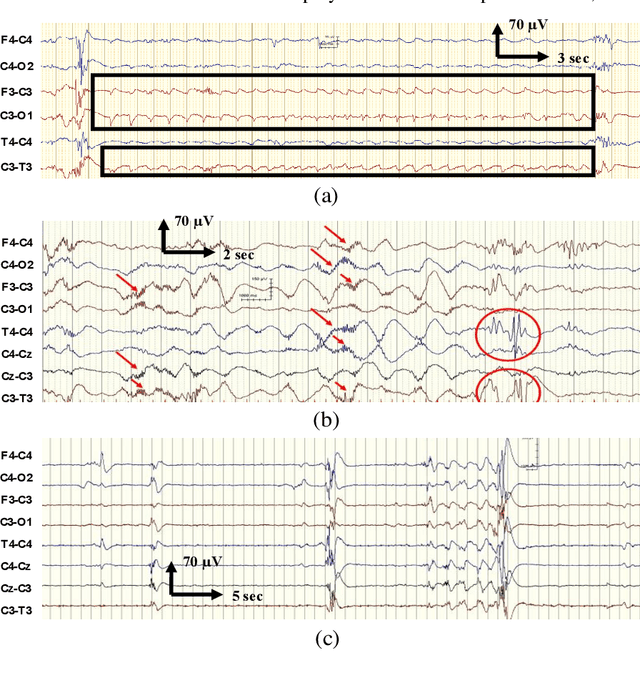

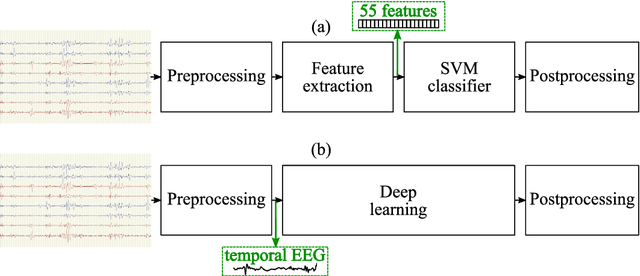
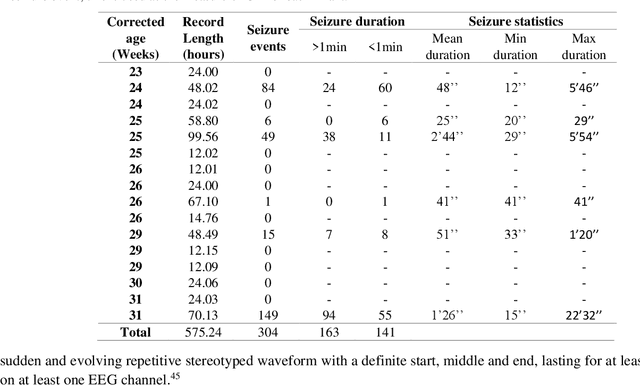
EEG is the gold standard for seizure detection in the newborn infant, but EEG interpretation in the preterm group is particularly challenging; trained experts are scarce and the task of interpreting EEG in real-time is arduous. Preterm infants are reported to have a higher incidence of seizures compared to term infants. Preterm EEG morphology differs from that of term infants, which implies that seizure detection algorithms trained on term EEG may not be appropriate. The task of developing preterm specific algorithms becomes extra-challenging given the limited amount of annotated preterm EEG data available. This paper explores novel deep learning (DL) architectures for the task of neonatal seizure detection in preterm infants. The study tests and compares several approaches to address the problem: training on data from full-term infants; training on data from preterm infants; training on age-specific preterm data and transfer learning. The system performance is assessed on a large database of continuous EEG recordings of 575h in duration. It is shown that the accuracy of a validated term-trained EEG seizure detection algorithm, based on a support vector machine classifier, when tested on preterm infants falls well short of the performance achieved for full-term infants. An AUC of 88.3% was obtained when tested on preterm EEG as compared to 96.6% obtained when tested on term EEG. When re-trained on preterm EEG, the performance marginally increases to 89.7%. An alternative DL approach shows a more stable trend when tested on the preterm cohort, starting with an AUC of 93.3% for the term-trained algorithm and reaching 95.0% by transfer learning from the term model using available preterm data.
Writing in The Air: Unconstrained Text Recognition from Finger Movement Using Spatio-Temporal Convolution
Apr 19, 2021
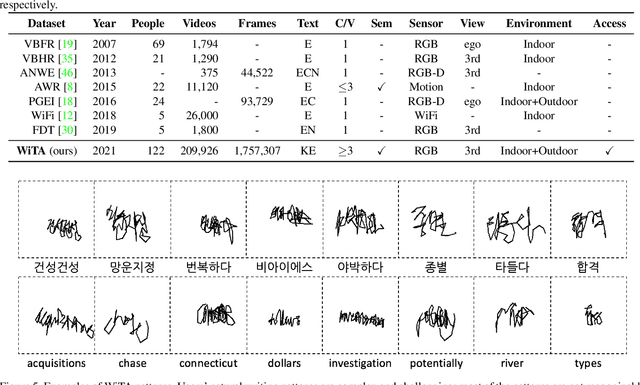

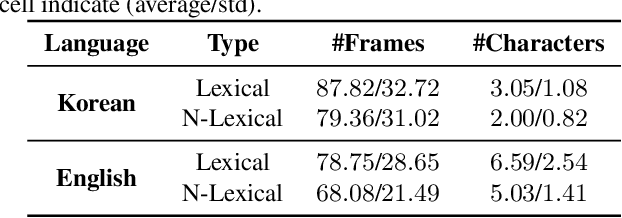
In this paper, we introduce a new benchmark dataset for the challenging writing in the air (WiTA) task -- an elaborate task bridging vision and NLP. WiTA implements an intuitive and natural writing method with finger movement for human-computer interaction (HCI). Our WiTA dataset will facilitate the development of data-driven WiTA systems which thus far have displayed unsatisfactory performance -- due to lack of dataset as well as traditional statistical models they have adopted. Our dataset consists of five sub-datasets in two languages (Korean and English) and amounts to 209,926 video instances from 122 participants. We capture finger movement for WiTA with RGB cameras to ensure wide accessibility and cost-efficiency. Next, we propose spatio-temporal residual network architectures inspired by 3D ResNet. These models perform unconstrained text recognition from finger movement, guarantee a real-time operation by processing 435 and 697 decoding frames-per-second for Korean and English, respectively, and will serve as an evaluation standard. Our dataset and the source codes are available at https://github.com/Uehwan/WiTA.
Labels, Information, and Computation: Efficient, Privacy-Preserving Learning Using Sufficient Labels
Apr 19, 2021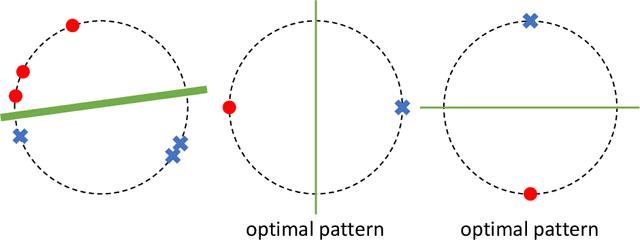
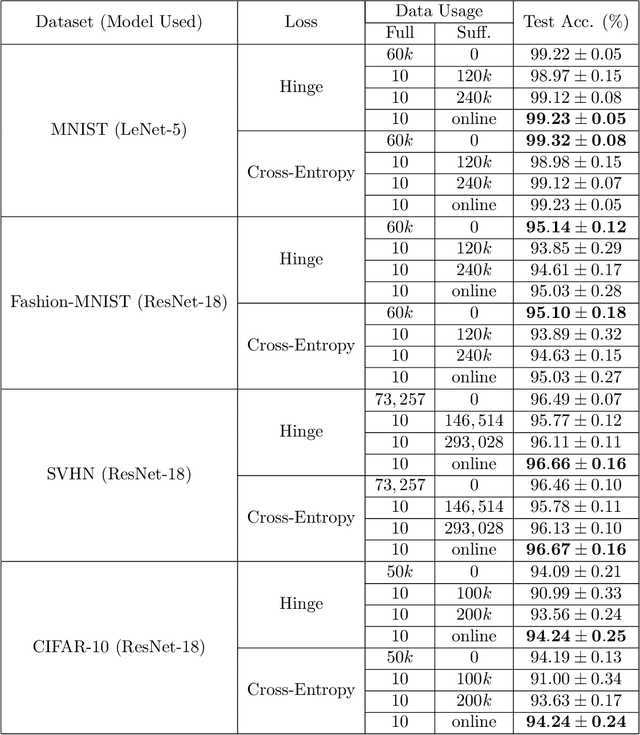
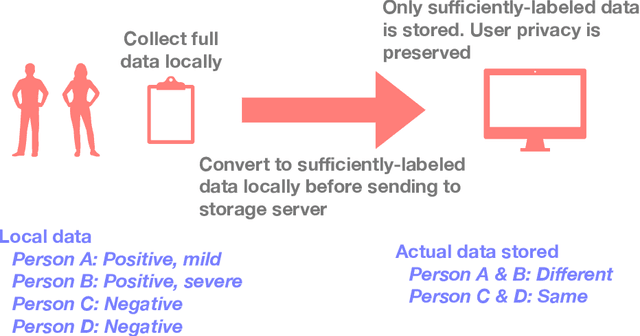
In supervised learning, obtaining a large set of fully-labeled training data is expensive. We show that we do not always need full label information on every single training example to train a competent classifier. Specifically, inspired by the principle of sufficiency in statistics, we present a statistic (a summary) of the fully-labeled training set that captures almost all the relevant information for classification but at the same time is easier to obtain directly. We call this statistic "sufficiently-labeled data" and prove its sufficiency and efficiency for finding the optimal hidden representations, on which competent classifier heads can be trained using as few as a single randomly-chosen fully-labeled example per class. Sufficiently-labeled data can be obtained from annotators directly without collecting the fully-labeled data first. And we prove that it is easier to directly obtain sufficiently-labeled data than obtaining fully-labeled data. Furthermore, sufficiently-labeled data naturally preserves user privacy by storing relative, instead of absolute, information. Extensive experimental results are provided to support our theory.