 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRED QUEEN: Safeguarding Large Language Models against Concealed Multi-Turn Jailbreaking
Sep 26, 2024



The rapid progress of Large Language Models (LLMs) has opened up new opportunities across various domains and applications; yet it also presents challenges related to potential misuse. To mitigate such risks, red teaming has been employed as a proactive security measure to probe language models for harmful outputs via jailbreak attacks. However, current jailbreak attack approaches are single-turn with explicit malicious queries that do not fully capture the complexity of real-world interactions. In reality, users can engage in multi-turn interactions with LLM-based chat assistants, allowing them to conceal their true intentions in a more covert manner. To bridge this gap, we, first, propose a new jailbreak approach, RED QUEEN ATTACK. This method constructs a multi-turn scenario, concealing the malicious intent under the guise of preventing harm. We craft 40 scenarios that vary in turns and select 14 harmful categories to generate 56k multi-turn attack data points. We conduct comprehensive experiments on the RED QUEEN ATTACK with four representative LLM families of different sizes. Our experiments reveal that all LLMs are vulnerable to RED QUEEN ATTACK, reaching 87.62% attack success rate on GPT-4o and 75.4% on Llama3-70B. Further analysis reveals that larger models are more susceptible to the RED QUEEN ATTACK, with multi-turn structures and concealment strategies contributing to its success. To prioritize safety, we introduce a straightforward mitigation strategy called RED QUEEN GUARD, which aligns LLMs to effectively counter adversarial attacks. This approach reduces the attack success rate to below 1% while maintaining the model's performance across standard benchmarks. Full implementation and dataset are publicly accessible at https://github.com/kriti-hippo/red_queen.
Neural Unsupervised Semantic Role Labeling
Apr 19, 2021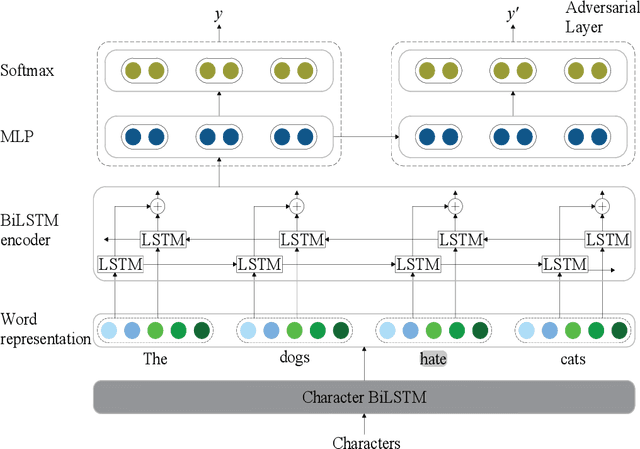
The task of semantic role labeling (SRL) is dedicated to finding the predicate-argument structure. Previous works on SRL are mostly supervised and do not consider the difficulty in labeling each example which can be very expensive and time-consuming. In this paper, we present the first neural unsupervised model for SRL. To decompose the task as two argument related subtasks, identification and clustering, we propose a pipeline that correspondingly consists of two neural modules. First, we train a neural model on two syntax-aware statistically developed rules. The neural model gets the relevance signal for each token in a sentence, to feed into a BiLSTM, and then an adversarial layer for noise-adding and classifying simultaneously, thus enabling the model to learn the semantic structure of a sentence. Then we propose another neural model for argument role clustering, which is done through clustering the learned argument embeddings biased towards their dependency relations. Experiments on CoNLL-2009 English dataset demonstrate that our model outperforms previous state-of-the-art baseline in terms of non-neural models for argument identification and classification.
Adaptive Convolution for Semantic Role Labeling
Dec 27, 2020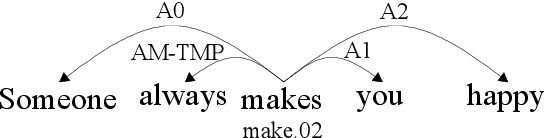
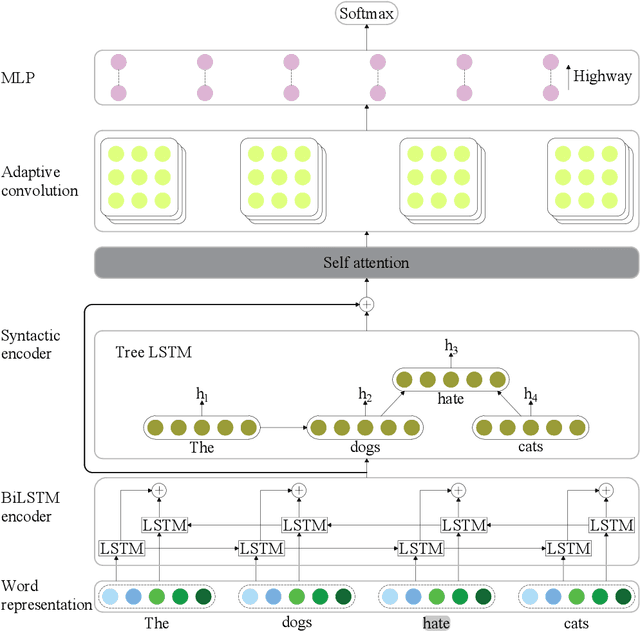
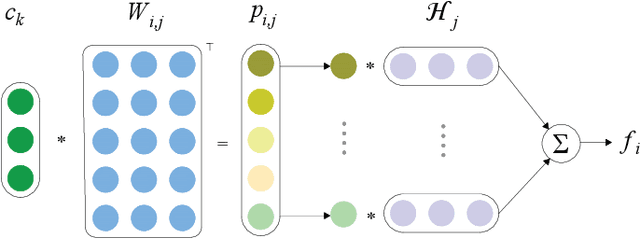
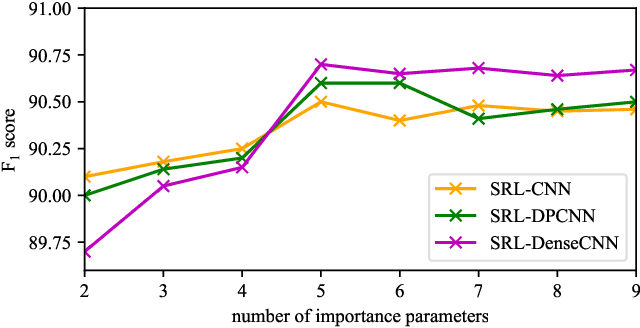
Semantic role labeling (SRL) aims at elaborating the meaning of a sentence by forming a predicate-argument structure. Recent researches depicted that the effective use of syntax can improve SRL performance. However, syntax is a complicated linguistic clue and is hard to be effectively applied in a downstream task like SRL. This work effectively encodes syntax using adaptive convolution which endows strong flexibility to existing convolutional networks. The existing CNNs may help in encoding a complicated structure like syntax for SRL, but it still has shortcomings. Contrary to traditional convolutional networks that use same filters for different inputs, adaptive convolution uses adaptively generated filters conditioned on syntactically informed inputs. We achieve this with the integration of a filter generation network which generates the input specific filters. This helps the model to focus on important syntactic features present inside the input, thus enlarging the gap between syntax-aware and syntax-agnostic SRL systems. We further study a hashing technique to compress the size of the filter generation network for SRL in terms of trainable parameters. Experiments on CoNLL-2009 dataset confirm that the proposed model substantially outperforms most previous SRL systems for both English and Chinese languages