 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Uncertainty-Aware Signal Temporal logic
May 24, 2021




Temporal logic inference is the process of extracting formal descriptions of system behaviors from data in the form of temporal logic formulas. The existing temporal logic inference methods mostly neglect uncertainties in the data, which results in limited applicability of such methods in real-world deployments. In this paper, we first investigate the uncertainties associated with trajectories of a system and represent such uncertainties in the form of interval trajectories. We then propose two uncertainty-aware signal temporal logic (STL) inference approaches to classify the undesired behaviors and desired behaviors of a system. Instead of classifying finitely many trajectories, we classify infinitely many trajectories within the interval trajectories. In the first approach, we incorporate robust semantics of STL formulas with respect to an interval trajectory to quantify the margin at which an STL formula is satisfied or violated by the interval trajectory. The second approach relies on the first learning algorithm and exploits the decision tree to infer STL formulas to classify behaviors of a given system. The proposed approaches also work for non-separable data by optimizing the worst-case robustness in inferring an STL formula. Finally, we evaluate the performance of the proposed algorithms in two case studies, where the proposed algorithms show reductions in the computation time by up to four orders of magnitude in comparison with the sampling-based baseline algorithms (for a dataset with 800 sampled trajectories in total).
Accuracy-Privacy Trade-off in Deep Ensemble
May 12, 2021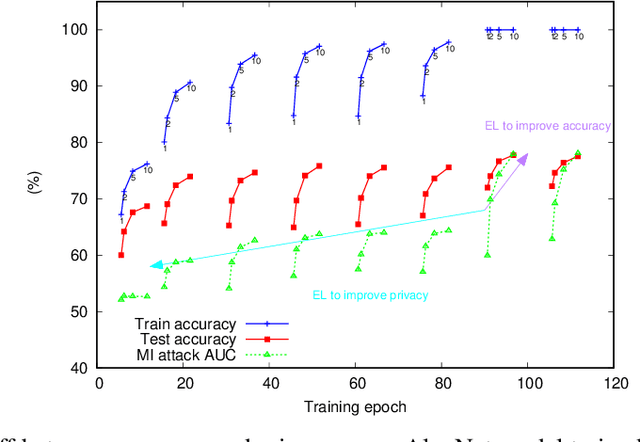
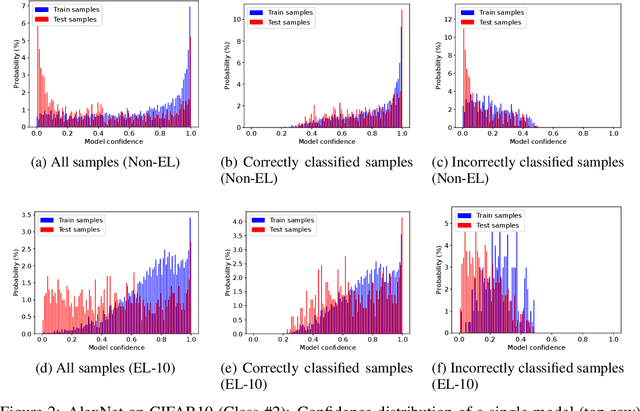
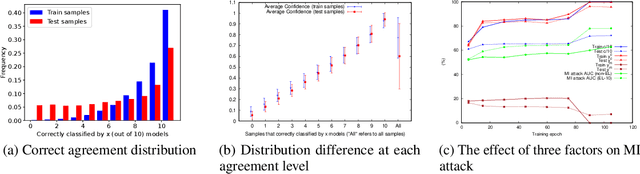
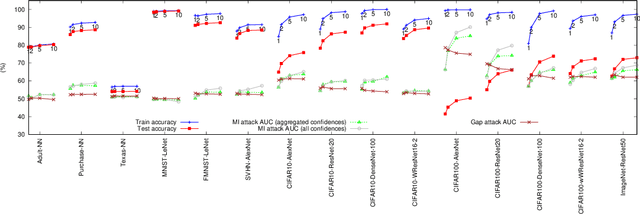
Deep ensemble learning aims to improve the classification accuracy by training several neural networks and fusing their outputs. It has been widely shown to improve accuracy. At the same time, ensemble learning has also been proposed to mitigate privacy leakage in terms of membership inference (MI), where the goal of an attacker is to infer whether a particular data sample has been used to train a target model. In this paper, we show that these two goals of ensemble learning, namely improving accuracy and privacy, directly conflict with each other. Using a wide range of datasets and model architectures, we empirically demonstrate the trade-off between privacy and accuracy in deep ensemble learning. We find that ensembling can improve either privacy or accuracy, but not both simultaneously -- when ensembling improves the classification accuracy, the effectiveness of the MI attack also increases. We analyze various factors that contribute to such privacy leakage in ensembling such as prediction confidence and agreement between models that constitute the ensemble. Our evaluation of defenses against MI attacks, such as regularization and differential privacy, shows that they can mitigate the effectiveness of the MI attack but simultaneously degrade ensemble accuracy. The source code is available at https://github.com/shrezaei/MI-on-EL.
Online Adversarial Purification based on Self-Supervision
Jan 23, 2021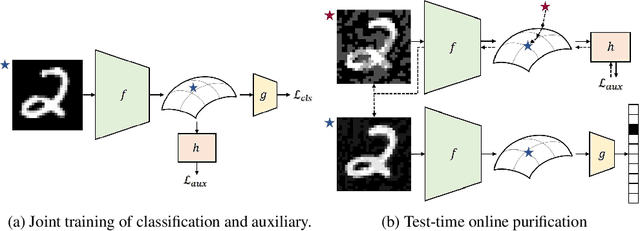
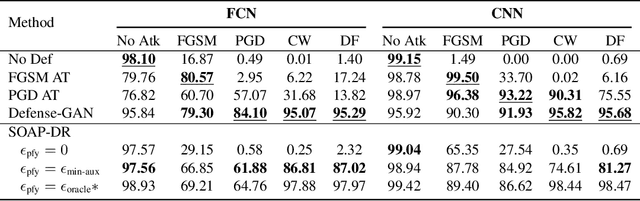

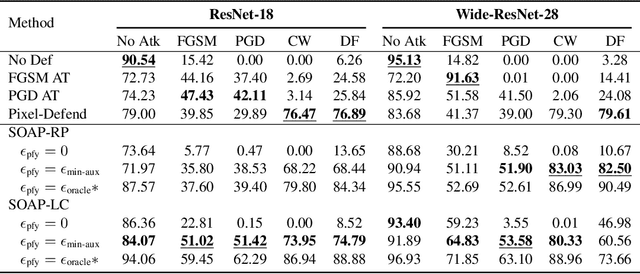
Deep neural networks are known to be vulnerable to adversarial examples, where a perturbation in the input space leads to an amplified shift in the latent network representation. In this paper, we combine canonical supervised learning with self-supervised representation learning, and present Self-supervised Online Adversarial Purification (SOAP), a novel defense strategy that uses a self-supervised loss to purify adversarial examples at test-time. Our approach leverages the label-independent nature of self-supervised signals and counters the adversarial perturbation with respect to the self-supervised tasks. SOAP yields competitive robust accuracy against state-of-the-art adversarial training and purification methods, with considerably less training complexity. In addition, our approach is robust even when adversaries are given knowledge of the purification defense strategy. To the best of our knowledge, our paper is the first that generalizes the idea of using self-supervised signals to perform online test-time purification.
ASM2TV: An Adaptive Semi-Supervised Multi-Task Multi-View Learning Framework
May 18, 2021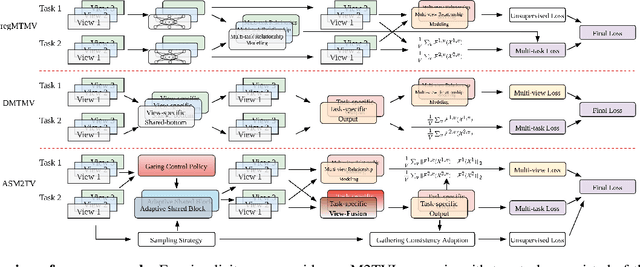
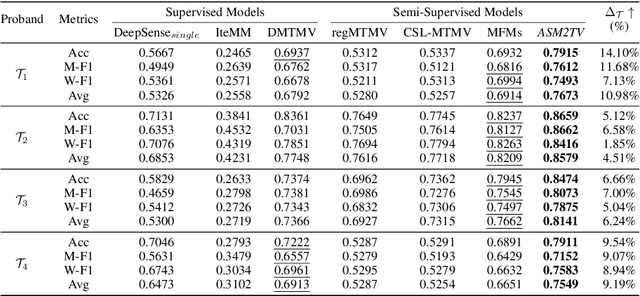
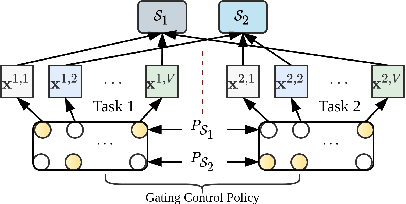
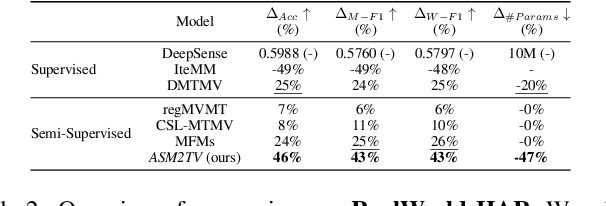
Many real-world scenarios, such as human activity recognition (HAR) in IoT, can be formalized as a multi-task multi-view learning problem. Each specific task consists of multiple shared feature views collected from multiple sources, either homogeneous or heterogeneous. Common among recent approaches is to employ a typical hard/soft sharing strategy at the initial phase separately for each view across tasks to uncover common knowledge, underlying the assumption that all views are conditionally independent. On the one hand, multiple views across tasks possibly relate to each other under practical situations. On the other hand, supervised methods might be insufficient when labeled data is scarce. To tackle these challenges, we introduce a novel framework ASM2TV for semi-supervised multi-task multi-view learning. We present a new perspective named gating control policy, a learnable task-view-interacted sharing policy that adaptively selects the most desirable candidate shared block for any view across any task, which uncovers more fine-grained task-view-interacted relatedness and improves inference efficiency. Significantly, our proposed gathering consistency adaption procedure takes full advantage of large amounts of unlabeled fragmented time-series, making it a general framework that accommodates a wide range of applications. Experiments on two diverse real-world HAR benchmark datasets collected from various subjects and sources demonstrate our framework's superiority over other state-of-the-arts.
Adversarial autoencoders and adversarial LSTM for improved forecasts of urban air pollution simulations
Apr 13, 2021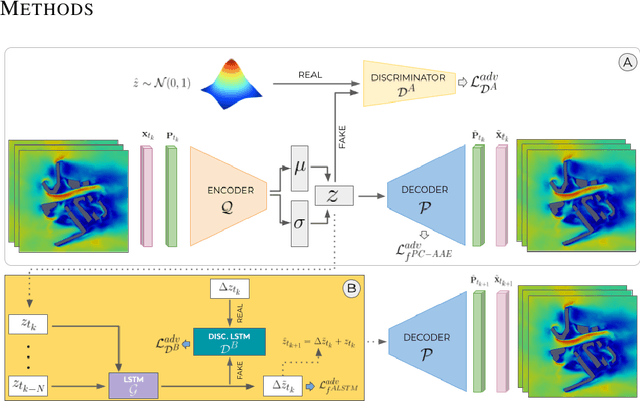
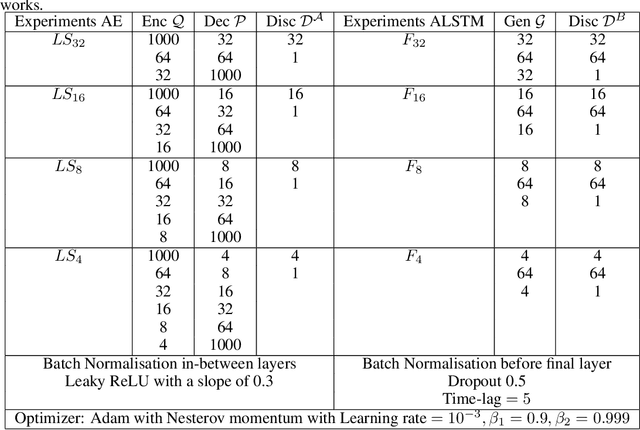
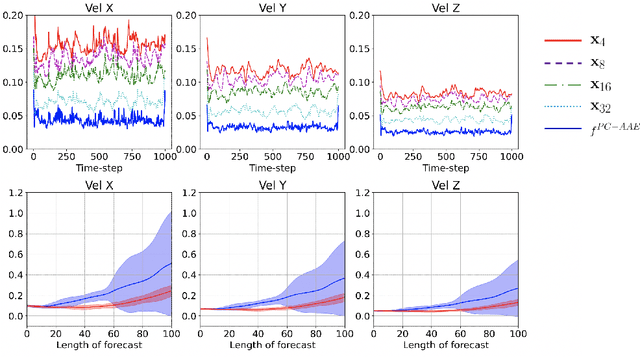
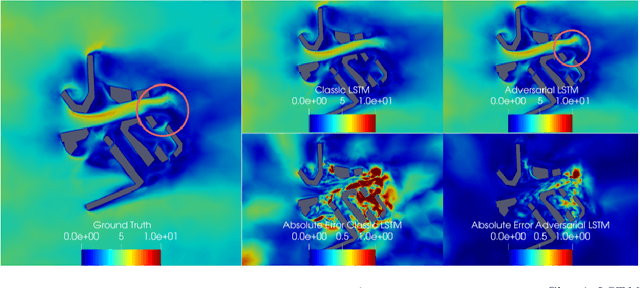
This paper presents an approach to improve the forecast of computational fluid dynamics (CFD) simulations of urban air pollution using deep learning, and most specifically adversarial training. This adversarial approach aims to reduce the divergence of the forecasts from the underlying physical model. Our two-step method integrates a Principal Components Analysis (PCA) based adversarial autoencoder (PC-AAE) with adversarial Long short-term memory (LSTM) networks. Once the reduced-order model (ROM) of the CFD solution is obtained via PCA, an adversarial autoencoder is used on the principal components time series. Subsequentially, a Long Short-Term Memory network (LSTM) is adversarially trained on the latent space produced by the PC-AAE to make forecasts. Once trained, the adversarially trained LSTM outperforms a LSTM trained in a classical way. The study area is in South London, including three-dimensional velocity vectors in a busy traffic junction.
Vision Transformer for Fast and Efficient Scene Text Recognition
May 18, 2021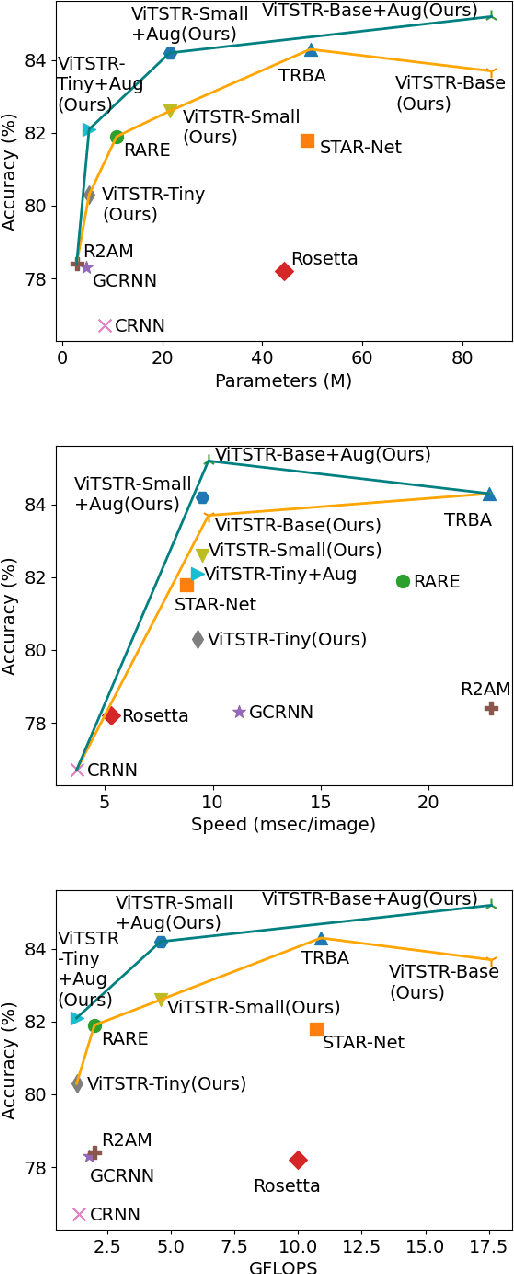


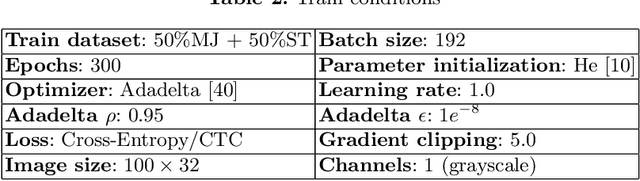
Scene text recognition (STR) enables computers to read text in natural scenes such as object labels, road signs and instructions. STR helps machines perform informed decisions such as what object to pick, which direction to go, and what is the next step of action. In the body of work on STR, the focus has always been on recognition accuracy. There is little emphasis placed on speed and computational efficiency which are equally important especially for energy-constrained mobile machines. In this paper we propose ViTSTR, an STR with a simple single stage model architecture built on a compute and parameter efficient vision transformer (ViT). On a comparable strong baseline method such as TRBA with accuracy of 84.3%, our small ViTSTR achieves a competitive accuracy of 82.6% (84.2% with data augmentation) at 2.4x speed up, using only 43.4% of the number of parameters and 42.2% FLOPS. The tiny version of ViTSTR achieves 80.3% accuracy (82.1% with data augmentation), at 2.5x the speed, requiring only 10.9% of the number of parameters and 11.9% FLOPS. With data augmentation, our base ViTSTR outperforms TRBA at 85.2% accuracy (83.7% without augmentation) at 2.3x the speed but requires 73.2% more parameters and 61.5% more FLOPS. In terms of trade-offs, nearly all ViTSTR configurations are at or near the frontiers to maximize accuracy, speed and computational efficiency all at the same time.
* To appear at ICDAR2021 Springer Lecture Notes in Computer Science series
InfinityGAN: Towards Infinite-Resolution Image Synthesis
Apr 08, 2021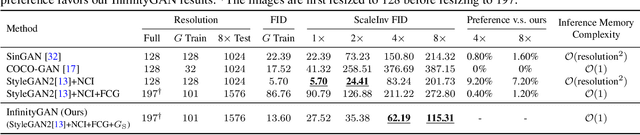
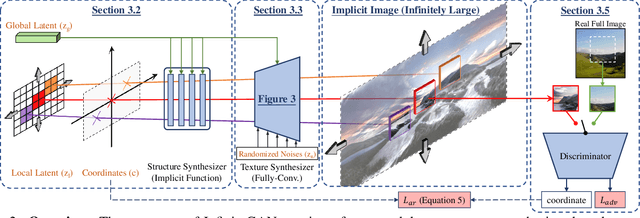
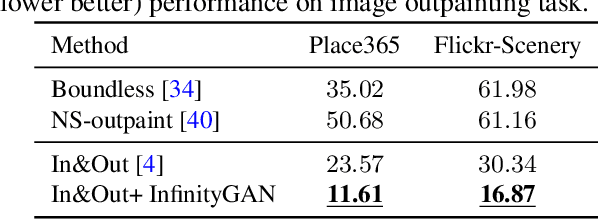
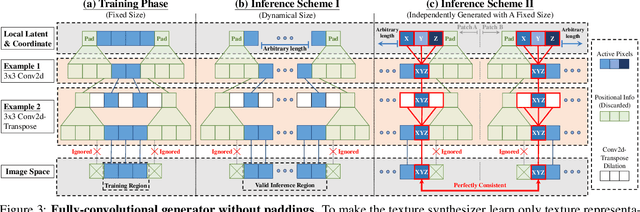
We present InfinityGAN, a method to generate arbitrary-resolution images. The problem is associated with several key challenges. First, scaling existing models to a high resolution is resource-constrained, both in terms of computation and availability of high-resolution training data. Infinity-GAN trains and infers patch-by-patch seamlessly with low computational resources. Second, large images should be locally and globally consistent, avoid repetitive patterns, and look realistic. To address these, InfinityGAN takes global appearance, local structure and texture into account.With this formulation, we can generate images with resolution and level of detail not attainable before. Experimental evaluation supports that InfinityGAN generates imageswith superior global structure compared to baselines at the same time featuring parallelizable inference. Finally, we how several applications unlocked by our approach, such as fusing styles spatially, multi-modal outpainting and image inbetweening at arbitrary input and output resolutions
Video Frame Interpolation via Structure-Motion based Iterative Fusion
May 11, 2021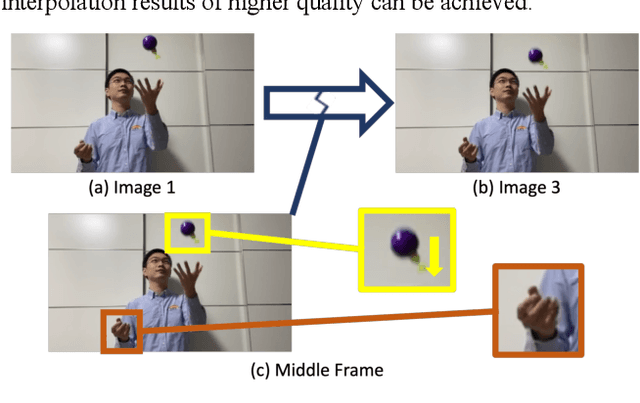
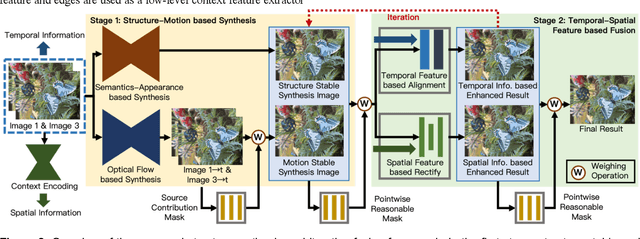
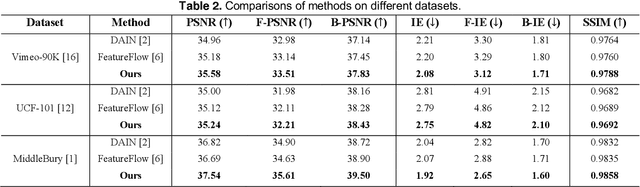
Video Frame Interpolation synthesizes non-existent images between adjacent frames, with the aim of providing a smooth and consistent visual experience. Two approaches for solving this challenging task are optical flow based and kernel-based methods. In existing works, optical flow based methods can provide accurate point-to-point motion description, however, they lack constraints on object structure. On the contrary, kernel-based methods focus on structural alignment, which relies on semantic and apparent features, but tends to blur results. Based on these observations, we propose a structure-motion based iterative fusion method. The framework is an end-to-end learnable structure with two stages. First, interpolated frames are synthesized by structure-based and motion-based learning branches respectively, then, an iterative refinement module is established via spatial and temporal feature integration. Inspired by the observation that audiences have different visual preferences on foreground and background objects, we for the first time propose to use saliency masks in the evaluation processes of the task of video frame interpolation. Experimental results on three typical benchmarks show that the proposed method achieves superior performance on all evaluation metrics over the state-of-the-art methods, even when our models are trained with only one-tenth of the data other methods use.
Unsupervised Instance Selection with Low-Label, Supervised Learning for Outlier Detection
Apr 26, 2021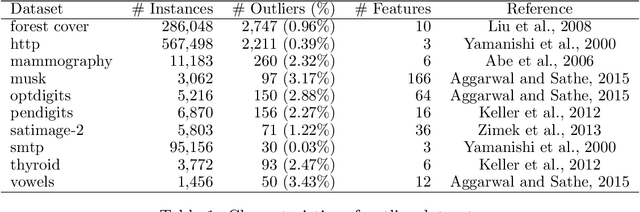
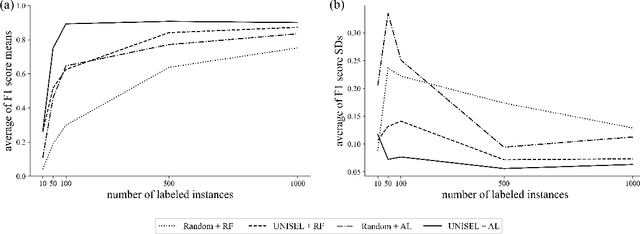
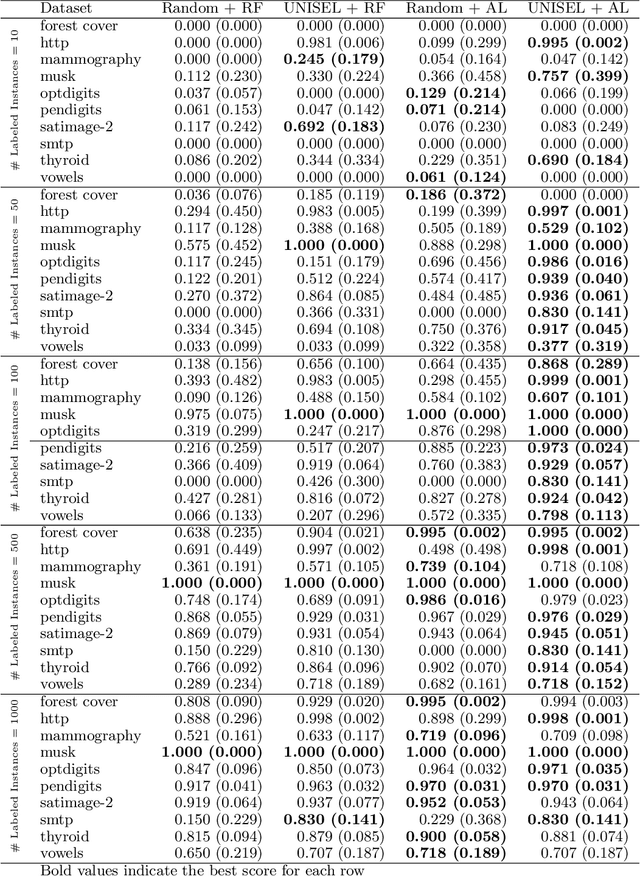
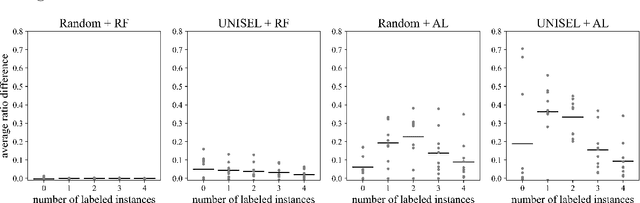
The laborious process of labeling data often bottlenecks projects that aim to leverage the power of supervised machine learning. Active Learning (AL) has been established as a technique to ameliorate this condition through an iterative framework that queries a human annotator for labels of instances with the most uncertain class assignment. Via this mechanism, AL produces a binary classifier trained on less labeled data but with little, if any, loss in predictive performance. Despite its advantages, AL can have difficulty with class-imbalanced datasets and results in an inefficient labeling process. To address these drawbacks, we investigate our unsupervised instance selection (UNISEL) technique followed by a Random Forest (RF) classifier on 10 outlier detection datasets under low-label conditions. These results are compared to AL performed on the same datasets. Further, we investigate the combination of UNISEL and AL. Results indicate that UNISEL followed by an RF performs comparably to AL with an RF and that the combination of UNISEL and AL demonstrates superior performance. The practical implications of these findings in terms of time savings and generalizability afforded by UNISEL are discussed.
Aliasing is your Ally: End-to-End Super-Resolution from Raw Image Bursts
Apr 13, 2021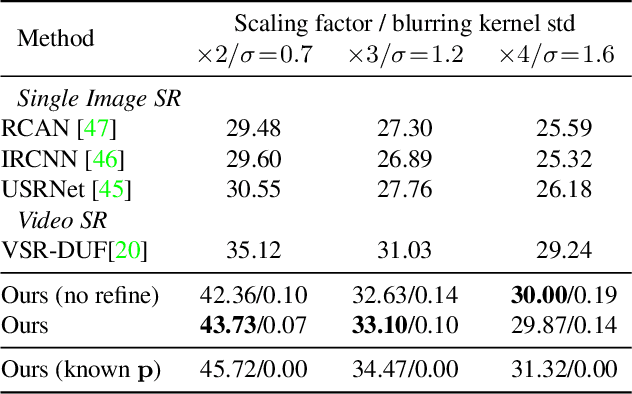

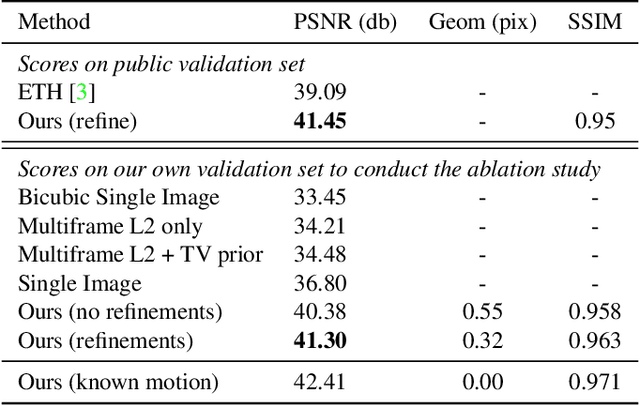

This presentation addresses the problem of reconstructing a high-resolution image from multiple lower-resolution snapshots captured from slightly different viewpoints in space and time. Key challenges for solving this problem include (i) aligning the input pictures with sub-pixel accuracy, (ii) handling raw (noisy) images for maximal faithfulness to native camera data, and (iii) designing/learning an image prior (regularizer) well suited to the task. We address these three challenges with a hybrid algorithm building on the insight from Wronski et al. that aliasing is an ally in this setting, with parameters that can be learned end to end, while retaining the interpretability of classical approaches to inverse problems. The effectiveness of our approach is demonstrated on synthetic and real image bursts, setting a new state of the art on several benchmarks and delivering excellent qualitative results on real raw bursts captured by smartphones and prosumer cameras.