 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TransVOS: Video Object Segmentation with Transformers
Jun 01, 2021
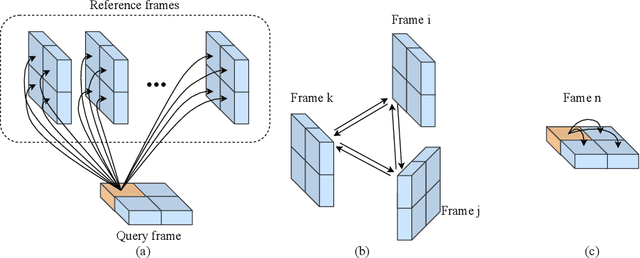
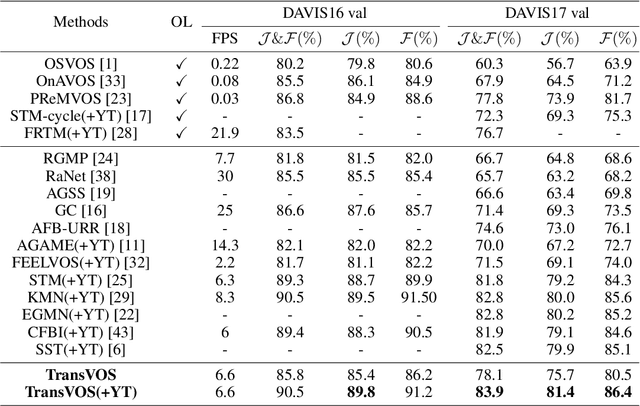
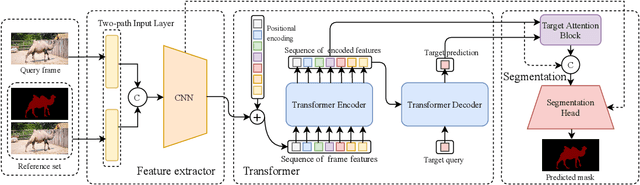
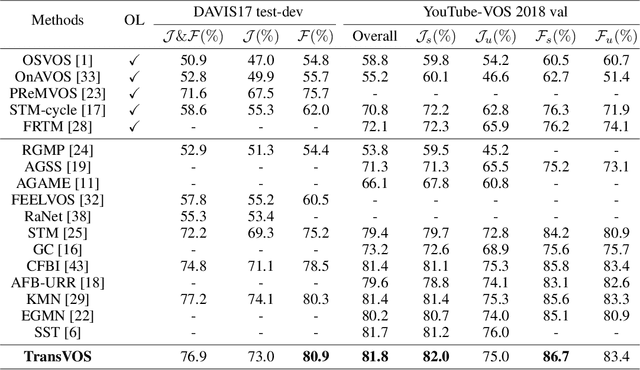
Recently, Space-Time Memory Network (STM) based methods have achieved state-of-the-art performance in semi-supervised video object segmentation (VOS). A critical problem in this task is how to model the dependency both among different frames and inside every frame. However, most of these methods neglect the spatial relationships (inside each frame) and do not make full use of the temporal relationships (among different frames). In this paper, we propose a new transformer-based framework, termed TransVOS, introducing a vision transformer to fully exploit and model both the temporal and spatial relationships. Moreover, most STM-based approaches employ two disparate encoders to extract features of two significant inputs, i.e., reference sets (history frames with predicted masks) and query frame, respectively, increasing the models' parameters and complexity. To slim the popular two-encoder pipeline while keeping the effectiveness, we design a single two-path feature extractor to encode the above two inputs in a unified way. Extensive experiments demonstrate the superiority of our TransVOS over state-of-the-art methods on both DAVIS and YouTube-VOS datasets. Codes will be released when it is published.
Modeling Fuzzy Cluster Transitions for Topic Tracing
Apr 16, 2021
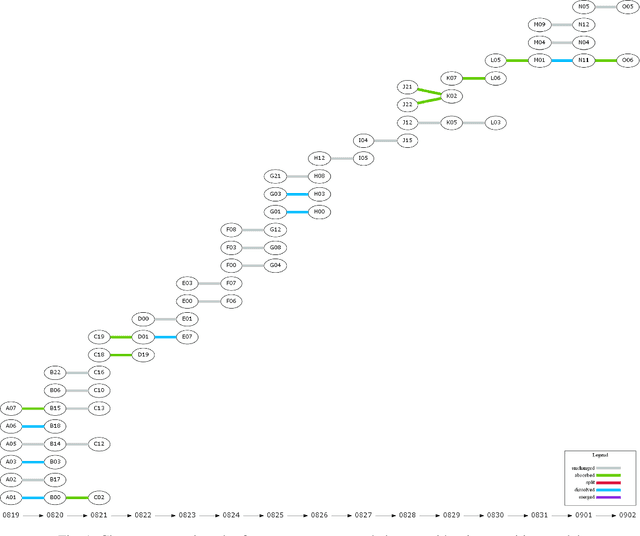

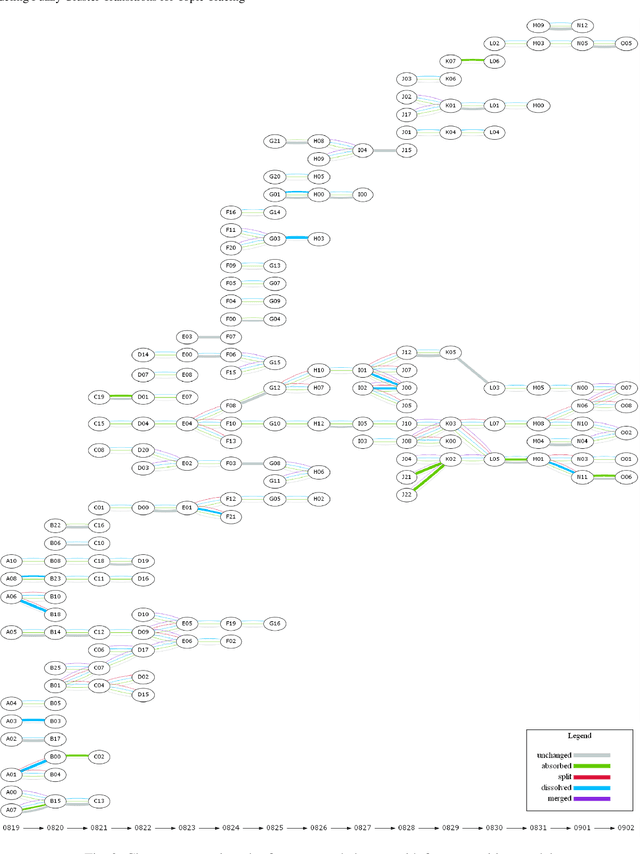
Twitter can be viewed as a data source for Natural Language Processing (NLP) tasks. The continuously updating data streams on Twitter make it challenging to trace real-time topic evolution. In this paper, we propose a framework for modeling fuzzy transitions of topic clusters. We extend our previous work on crisp cluster transitions by incorporating fuzzy logic in order to enrich the underlying structures identified by the framework. We apply the methodology to both computer generated clusters of nouns from tweets and human tweet annotations. The obtained fuzzy transitions are compared with the crisp transitions, on both computer generated clusters and human labeled topic sets.
DoT: An efficient Double Transformer for NLP tasks with tables
Jun 01, 2021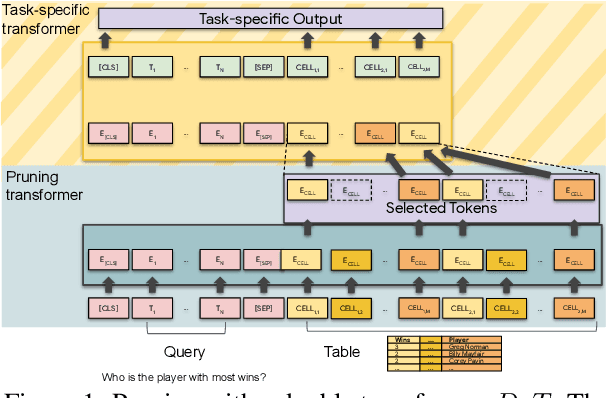
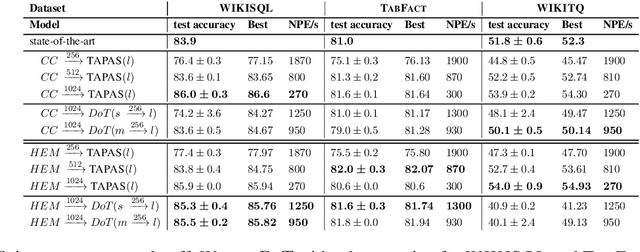
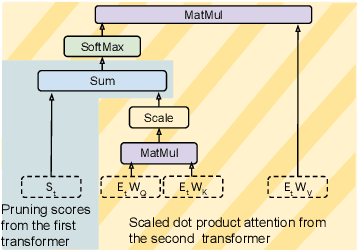
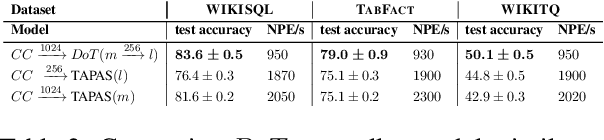
Transformer-based approaches have been successfully used to obtain state-of-the-art accuracy on natural language processing (NLP) tasks with semi-structured tables. These model architectures are typically deep, resulting in slow training and inference, especially for long inputs. To improve efficiency while maintaining a high accuracy, we propose a new architecture, DoT, a double transformer model, that decomposes the problem into two sub-tasks: A shallow pruning transformer that selects the top-K tokens, followed by a deep task-specific transformer that takes as input those K tokens. Additionally, we modify the task-specific attention to incorporate the pruning scores. The two transformers are jointly trained by optimizing the task-specific loss. We run experiments on three benchmarks, including entailment and question-answering. We show that for a small drop of accuracy, DoT improves training and inference time by at least 50%. We also show that the pruning transformer effectively selects relevant tokens enabling the end-to-end model to maintain similar accuracy as slower baseline models. Finally, we analyse the pruning and give some insight into its impact on the task model.
Multi-Phase Locking Value: A Generalized Method for Determining Instantaneous Multi-frequency Phase Coupling
Feb 20, 2021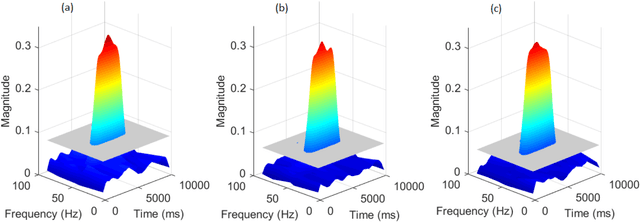
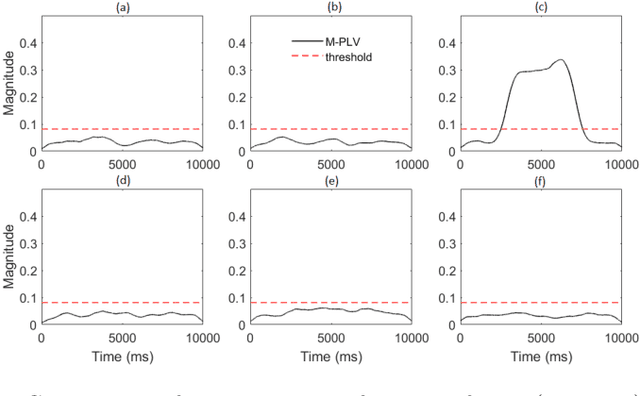
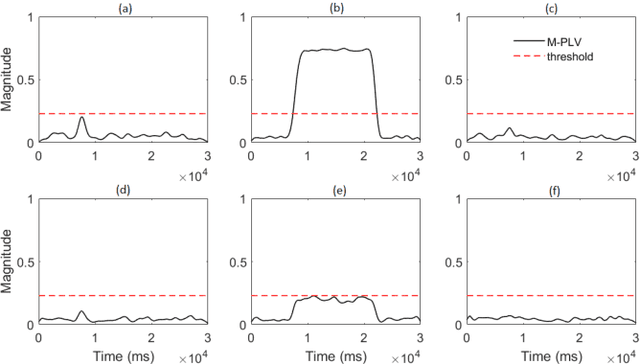
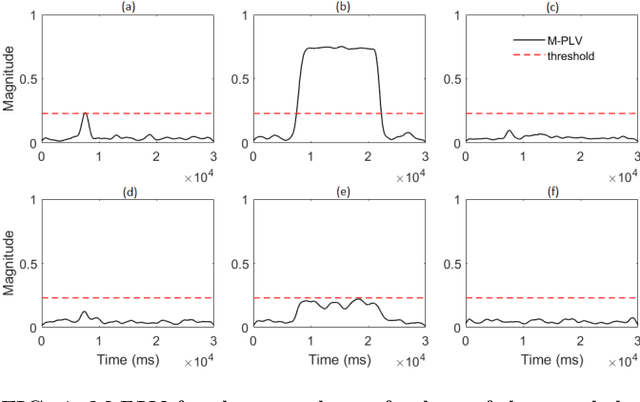
Many physical, biological and neural systems behave as coupled oscillators, with characteristic phase coupling across different frequencies. Methods such as $n:m$ phase locking value and bi-phase locking value have previously been proposed to quantify phase coupling between two resonant frequencies (e.g. $f$, $2f/3$) and across three frequencies (e.g. $f_1$, $f_2$, $f_1+f_2$), respectively. However, the existing phase coupling metrics have their limitations and limited applications. They cannot be used to detect or quantify phase coupling across multiple frequencies (e.g. $f_1$, $f_2$, $f_3$, $f_4$, $f_1+f_2+f_3-f_4$), or coupling that involves non-integer multiples of the frequencies (e.g. $f_1$, $f_2$, $2f_1/3+f_2/3$). To address the gap, this paper proposes a generalized approach, named multi-phase locking value (M-PLV), for the quantification of various types of instantaneous multi-frequency phase coupling. Different from most instantaneous phase coupling metrics that measure the simultaneous phase coupling, the proposed M-PLV method also allows the detection of delayed phase coupling and the associated time lag between coupled oscillators. The M-PLV has been tested on cases where synthetic coupled signals are generated using white Gaussian signals, and a system comprised of multiple coupled R\"ossler oscillators. Results indicate that the M-PLV can provide a reliable estimation of the time window and frequency combination where the phase coupling is significant, as well as a precise determination of time lag in the case of delayed coupling. This method has the potential to become a powerful new tool for exploring phase coupling in complex nonlinear dynamic systems.
Decentralized Learning in Online Queuing Systems
Jun 08, 2021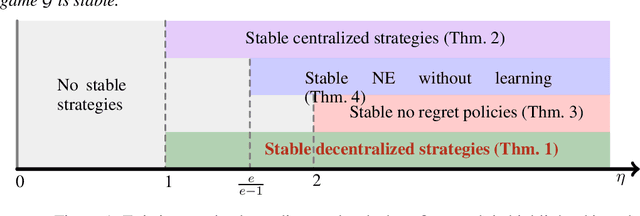
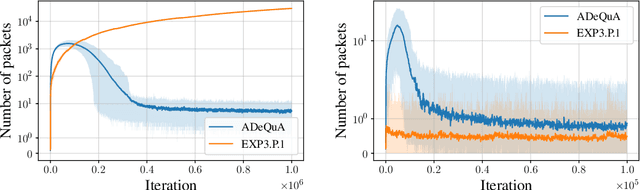
Motivated by packet routing in computer networks, online queuing systems are composed of queues receiving packets at different rates. Repeatedly, they send packets to servers, each of them treating only at most one packet at a time. In the centralized case, the number of accumulated packets remains bounded (i.e., the system is \textit{stable}) as long as the ratio between service rates and arrival rates is larger than $1$. In the decentralized case, individual no-regret strategies ensures stability when this ratio is larger than $2$. Yet, myopically minimizing regret disregards the long term effects due to the carryover of packets to further rounds. On the other hand, minimizing long term costs leads to stable Nash equilibria as soon as the ratio exceeds $\frac{e}{e-1}$. Stability with decentralized learning strategies with a ratio below $2$ was a major remaining question. We first argue that for ratios up to $2$, cooperation is required for stability of learning strategies, as selfish minimization of policy regret, a \textit{patient} notion of regret, might indeed still be unstable in this case. We therefore consider cooperative queues and propose the first learning decentralized algorithm guaranteeing stability of the system as long as the ratio of rates is larger than $1$, thus reaching performances comparable to centralized strategies.
Post-Contextual-Bandit Inference
Jun 01, 2021
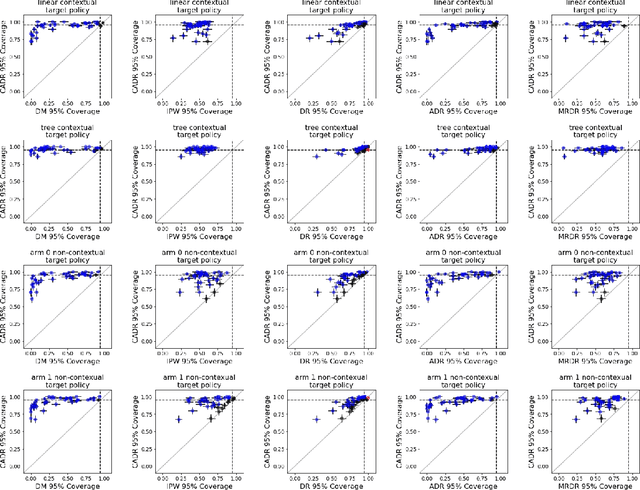
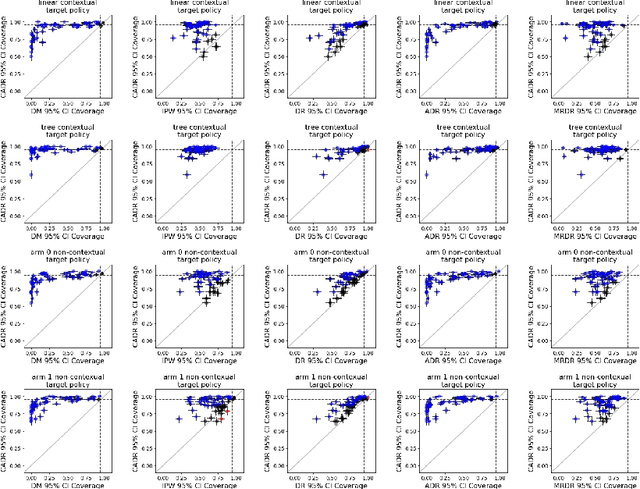
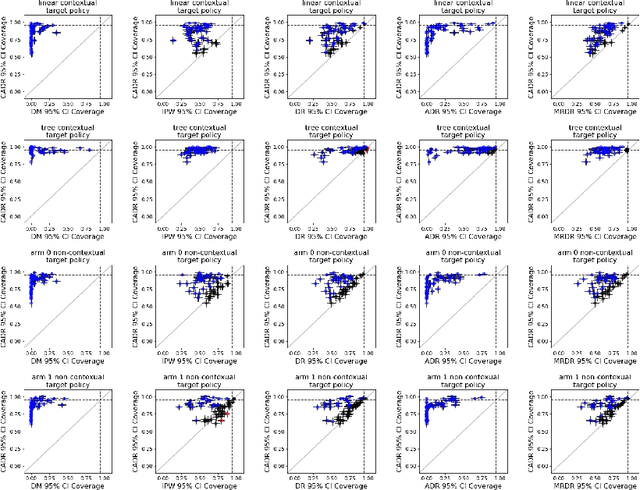
Contextual bandit algorithms are increasingly replacing non-adaptive A/B tests in e-commerce, healthcare, and policymaking because they can both improve outcomes for study participants and increase the chance of identifying good or even best policies. To support credible inference on novel interventions at the end of the study, nonetheless, we still want to construct valid confidence intervals on average treatment effects, subgroup effects, or value of new policies. The adaptive nature of the data collected by contextual bandit algorithms, however, makes this difficult: standard estimators are no longer asymptotically normally distributed and classic confidence intervals fail to provide correct coverage. While this has been addressed in non-contextual settings by using stabilized estimators, the contextual setting poses unique challenges that we tackle for the first time in this paper. We propose the Contextual Adaptive Doubly Robust (CADR) estimator, the first estimator for policy value that is asymptotically normal under contextual adaptive data collection. The main technical challenge in constructing CADR is designing adaptive and consistent conditional standard deviation estimators for stabilization. Extensive numerical experiments using 57 OpenML datasets demonstrate that confidence intervals based on CADR uniquely provide correct coverage.
Grapevine Winter Pruning Automation: On Potential Pruning Points Detection through 2D Plant Modeling using Grapevine Segmentation
Jun 08, 2021



Grapevine winter pruning is a complex task, that requires skilled workers to execute it correctly. The complexity of this task is also the reason why it is time consuming. Considering that this operation takes about 80-120 hours/ha to be completed, and therefore is even more crucial in large-size vineyards, an automated system can help to speed up the process. To this end, this paper presents a novel multidisciplinary approach that tackles this challenging task by performing object segmentation on grapevine images, used to create a representative model of the grapevine plants. Second, a set of potential pruning points is generated from this plant representation. We will describe (a) a methodology for data acquisition and annotation, (b) a neural network fine-tuning for grapevine segmentation, (c) an image processing based method for creating the representative model of grapevines, starting from the inferred segmentation and (d) potential pruning points detection and localization, based on the plant model which is a simplification of the grapevine structure. With this approach, we are able to identify a significant set of potential pruning points on the canes, that can be used, with further selection, to derive the final set of the real pruning points.
Learning by Distillation: A Self-Supervised Learning Framework for Optical Flow Estimation
Jun 08, 2021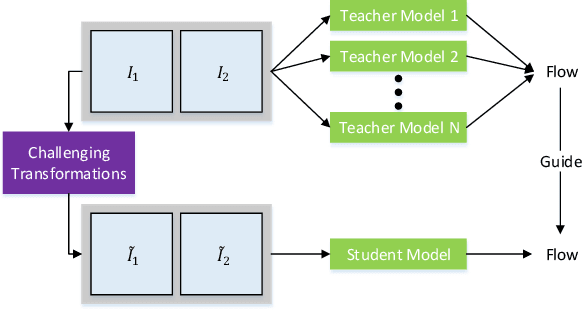
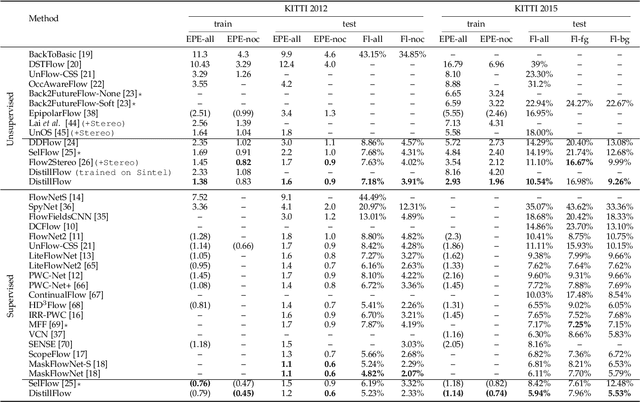
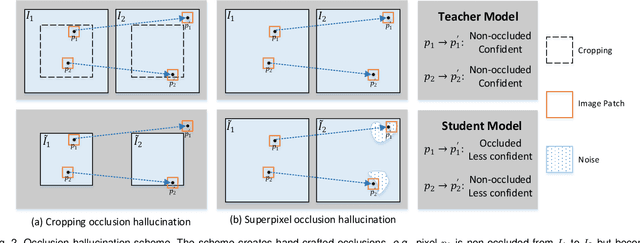
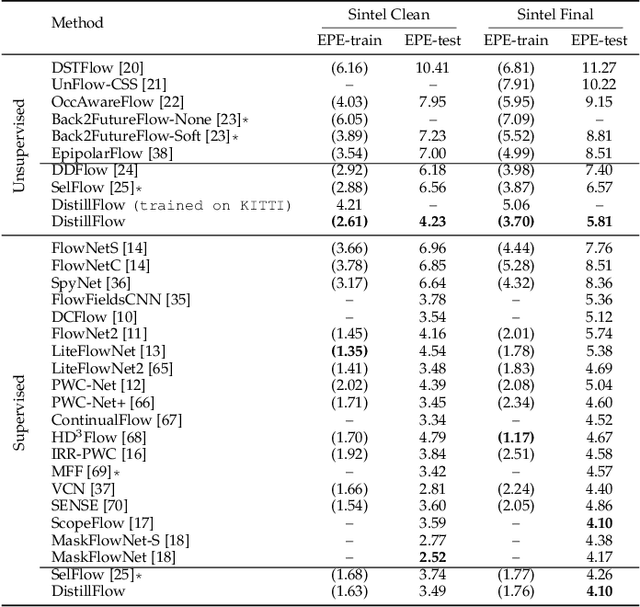
We present DistillFlow, a knowledge distillation approach to learning optical flow. DistillFlow trains multiple teacher models and a student model, where challenging transformations are applied to the input of the student model to generate hallucinated occlusions as well as less confident predictions. Then, a self-supervised learning framework is constructed: confident predictions from teacher models are served as annotations to guide the student model to learn optical flow for those less confident predictions. The self-supervised learning framework enables us to effectively learn optical flow from unlabeled data, not only for non-occluded pixels, but also for occluded pixels. DistillFlow achieves state-of-the-art unsupervised learning performance on both KITTI and Sintel datasets. Our self-supervised pre-trained model also provides an excellent initialization for supervised fine-tuning, suggesting an alternate training paradigm in contrast to current supervised learning methods that highly rely on pre-training on synthetic data. At the time of writing, our fine-tuned models ranked 1st among all monocular methods on the KITTI 2015 benchmark, and outperform all published methods on the Sintel Final benchmark. More importantly, we demonstrate the generalization capability of DistillFlow in three aspects: framework generalization, correspondence generalization and cross-dataset generalization.
Grasping force estimation using state-space model and Kalman filter
Jun 14, 2021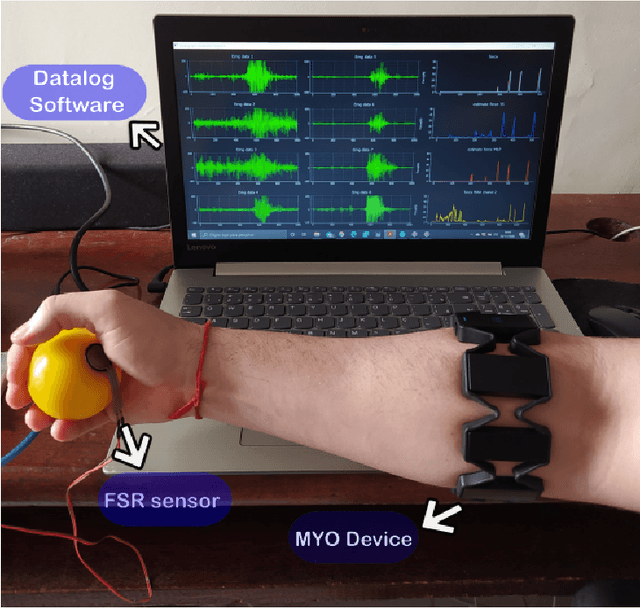
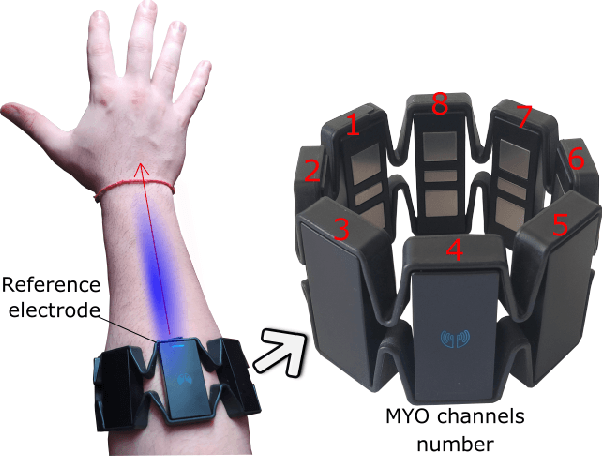
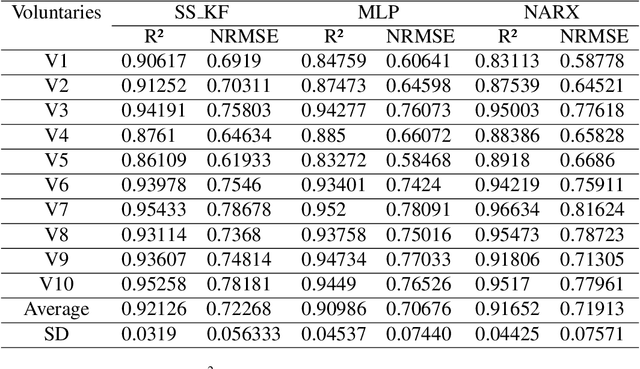
The grip force required to handle an object depends on it mass and the friction between the skin and the object. The control of grip force in myoelectric prosthesis is crucial for handling objects adequately. The current paper proposes a method for improving the estimation of grip force in myoelectric prosthesis based on surface myoelectric (sEMG) recordings. For this purpose, we develop an approach based on multivariable system identification in the state-space (SS) and continuous force estimation with Kalman filter (KF). The sEMG recordings of ten healthy individuals performing a grip task were used as data set for model identification. The root mean square (RMS), the mean absolute value (MAV), and the waveform length (WL) extracted from the sEMG signals were used at the model's input and the measured grasping force was the output. The performance of the proposed method was evaluated using the normalized root-mean-squared-error (NRMSE) and the square of Pearson's correlation coefficient ($ R^2 $). In this study, the CC and NRMSE values were 0.92$ \pm $ 0.0319 and 0.723$ \pm $ 0.0563, respectively. The performance of the system was superior to results obtained with a recurrent nonlinear autoregressive exogenous (NARX)-based neural network and the multi-layer perceptron (MLP) network. The results confirmed that the method is an excellent tool for real-time applications with hand prostheses.
Large-scale, Dynamic and Distributed Coalition Formation with Spatial and Temporal Constraints
Jun 01, 2021
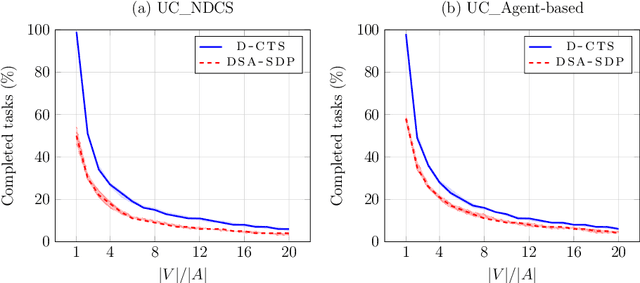
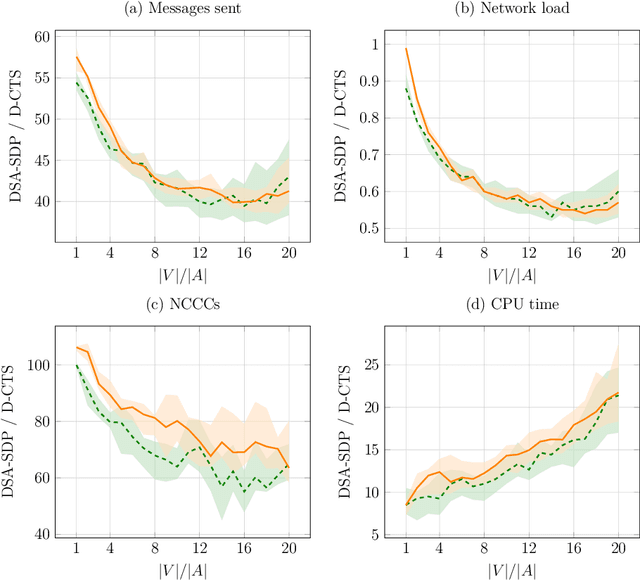
The Coalition Formation with Spatial and Temporal constraints Problem (CFSTP) is a multi-agent task allocation problem in which few agents have to perform many tasks, each with its deadline and workload. To maximize the number of completed tasks, the agents need to cooperate by forming, disbanding and reforming coalitions. The original mathematical programming formulation of the CFSTP is difficult to implement, since it is lengthy and based on the problematic Big-M method. In this paper, we propose a compact and easy-to-implement formulation. Moreover, we design D-CTS, a distributed version of the state-of-the-art CFSTP algorithm. Using public London Fire Brigade records, we create a dataset with $347588$ tasks and a test framework that simulates the mobilization of firefighters in dynamic environments. In problems with up to $150$ agents and $3000$ tasks, compared to DSA-SDP, a state-of-the-art distributed algorithm, D-CTS completes $3.79\% \pm [42.22\%, 1.96\%]$ more tasks, and is one order of magnitude more efficient in terms of communication overhead and time complexity. D-CTS sets the first large-scale, dynamic and distributed CFSTP benchmark.