 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pairwise Weights for Temporal Credit Assignment
Feb 09, 2021

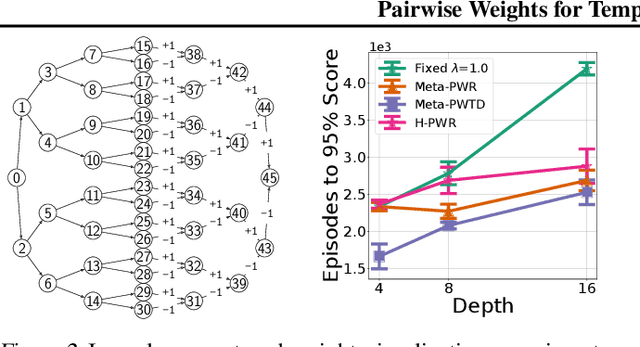
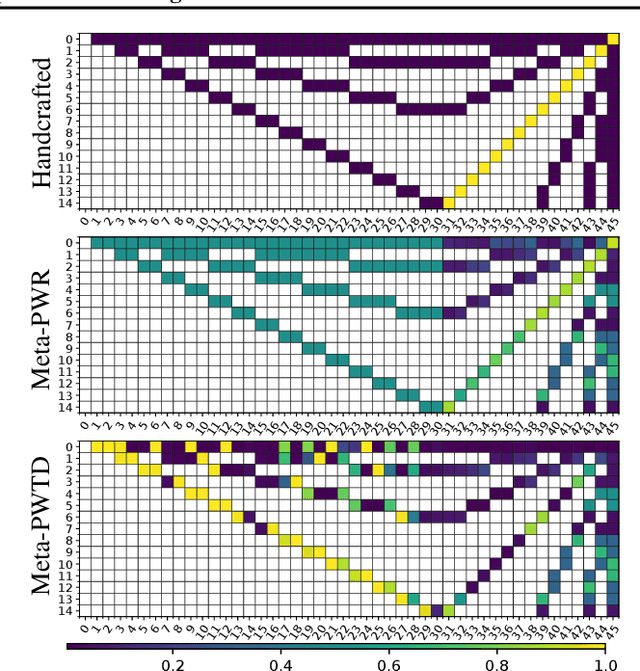

How much credit (or blame) should an action taken in a state get for a future reward? This is the fundamental temporal credit assignment problem in Reinforcement Learning (RL). One of the earliest and still most widely used heuristics is to assign this credit based on a scalar coefficient $\lambda$ (treated as a hyperparameter) raised to the power of the time interval between the state-action and the reward. In this empirical paper, we explore heuristics based on more general pairwise weightings that are functions of the state in which the action was taken, the state at the time of the reward, as well as the time interval between the two. Of course it isn't clear what these pairwise weight functions should be, and because they are too complex to be treated as hyperparameters we develop a metagradient procedure for learning these weight functions during the usual RL training of a policy. Our empirical work shows that it is often possible to learn these pairwise weight functions during learning of the policy to achieve better performance than competing approaches.
Self-Supervised Adaptation for Video Super-Resolution
Mar 18, 2021
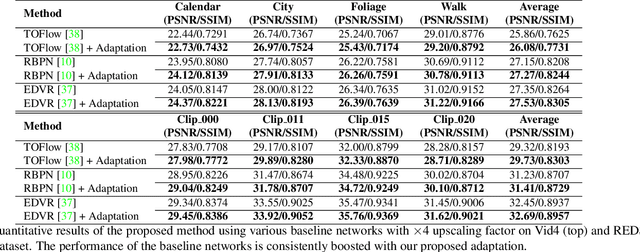
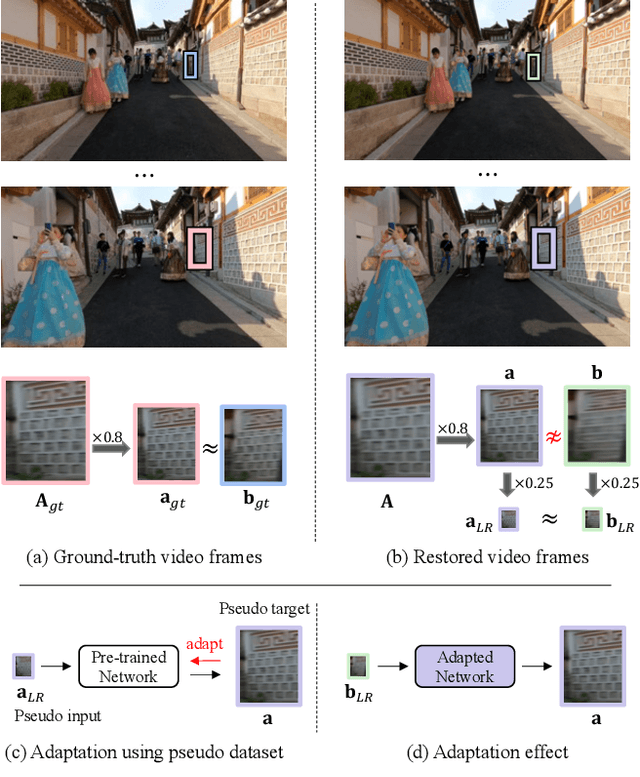
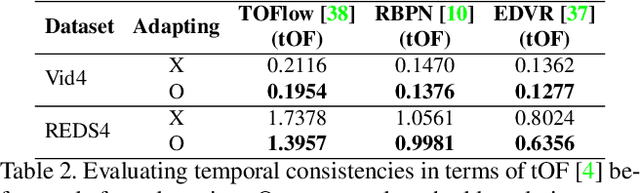
Recent single-image super-resolution (SISR) networks, which can adapt their network parameters to specific input images, have shown promising results by exploiting the information available within the input data as well as large external datasets. However, the extension of these self-supervised SISR approaches to video handling has yet to be studied. Thus, we present a new learning algorithm that allows conventional video super-resolution (VSR) networks to adapt their parameters to test video frames without using the ground-truth datasets. By utilizing many self-similar patches across space and time, we improve the performance of fully pre-trained VSR networks and produce temporally consistent video frames. Moreover, we present a test-time knowledge distillation technique that accelerates the adaptation speed with less hardware resources. In our experiments, we demonstrate that our novel learning algorithm can fine-tune state-of-the-art VSR networks and substantially elevate performance on numerous benchmark datasets.
Gated2Depth: Real-time Dense Lidar from Gated Images
Feb 13, 2019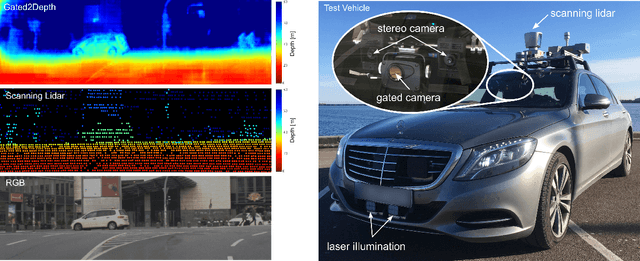


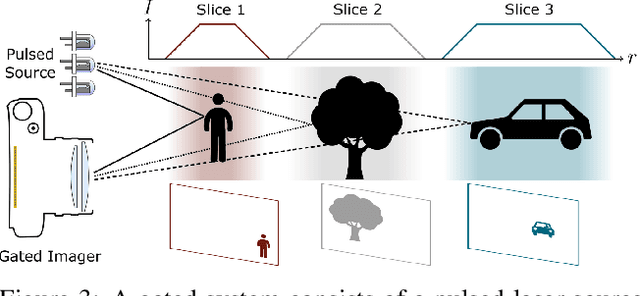
We present an imaging framework which converts three images from a gated camera into high-resolution depth maps with depth resolution comparable to pulsed lidar measurements. Existing scanning lidar systems achieve low spatial resolution at large ranges due to mechanically-limited angular sampling rates, restricting scene understanding tasks to close-range clusters with dense sampling. In addition, today's lidar detector technologies, short-pulsed laser sources and scanning mechanics result in high cost, power consumption and large form-factors. We depart from point scanning and propose a learned architecture that recovers high-fidelity dense depth from three temporally gated images, acquired with a flash source and a high-resolution CMOS sensor. The proposed architecture exploits semantic context across gated slices, and is trained on a synthetic discriminator loss without the need of dense depth labels. The method is real-time and essentially turns a gated camera into a low-cost dense flash lidar which we validate on a wide range of outdoor driving captures and in simulations.
Deep Unsupervised Learning for Generalized Assignment Problems: A Case-Study of User-Association in Wireless Networks
Mar 26, 2021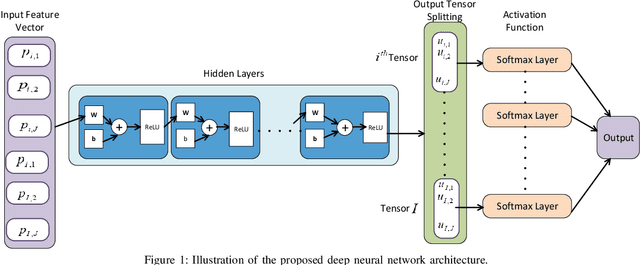
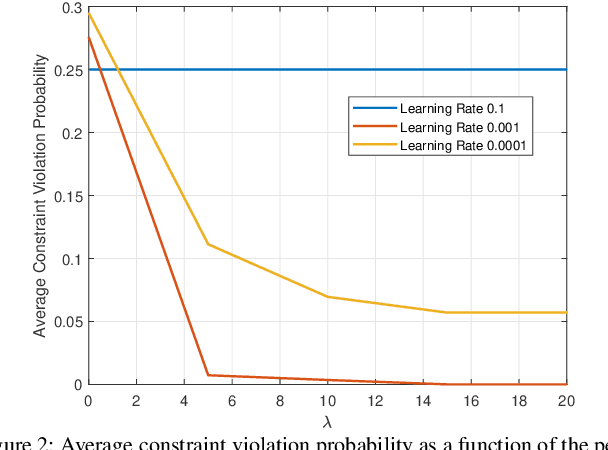
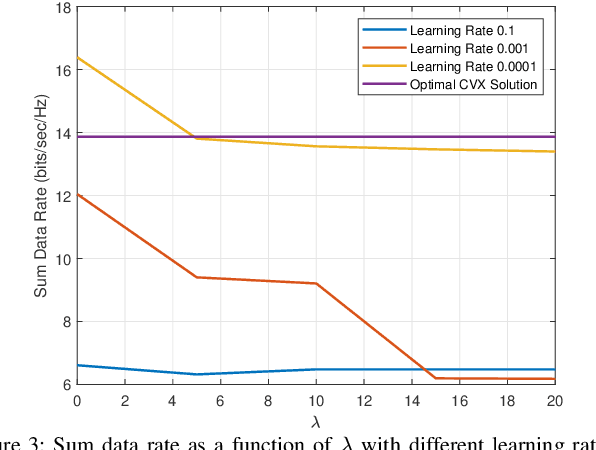
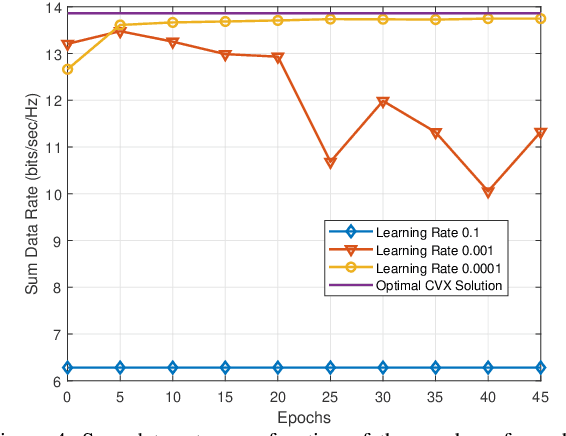
There exists many resource allocation problems in the field of wireless communications which can be formulated as the generalized assignment problems (GAP). GAP is a generic form of linear sum assignment problem (LSAP) and is more challenging to solve owing to the presence of both equality and inequality constraints. We propose a novel deep unsupervised learning (DUL) approach to solve GAP in a time-efficient manner. More specifically, we propose a new approach that facilitates to train a deep neural network (DNN) using a customized loss function. This customized loss function constitutes the objective function and penalty terms corresponding to both equality and inequality constraints. Furthermore, we propose to employ a Softmax activation function at the output of DNN along with tensor splitting which simplifies the customized loss function and guarantees to meet the equality constraint. As a case-study, we consider a typical user-association problem in a wireless network, formulate it as GAP, and consequently solve it using our proposed DUL approach. Numerical results demonstrate that the proposed DUL approach provides near-optimal results with significantly lower time-complexity.
Tag, Copy or Predict: A Unified Weakly-Supervised Learning Framework for Visual Information Extraction using Sequences
Jun 20, 2021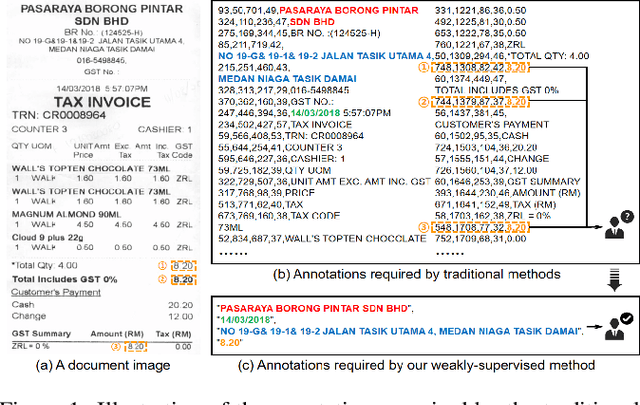


Visual information extraction (VIE) has attracted increasing attention in recent years. The existing methods usually first organized optical character recognition (OCR) results into plain texts and then utilized token-level entity annotations as supervision to train a sequence tagging model. However, it expends great annotation costs and may be exposed to label confusion, and the OCR errors will also significantly affect the final performance. In this paper, we propose a unified weakly-supervised learning framework called TCPN (Tag, Copy or Predict Network), which introduces 1) an efficient encoder to simultaneously model the semantic and layout information in 2D OCR results; 2) a weakly-supervised training strategy that utilizes only key information sequences as supervision; and 3) a flexible and switchable decoder which contains two inference modes: one (Copy or Predict Mode) is to output key information sequences of different categories by copying a token from the input or predicting one in each time step, and the other (Tag Mode) is to directly tag the input sequence in a single forward pass. Our method shows new state-of-the-art performance on several public benchmarks, which fully proves its effectiveness.
Physics-Informed Neural Network Method for Solving One-Dimensional Advection Equation Using PyTorch
Mar 18, 2021

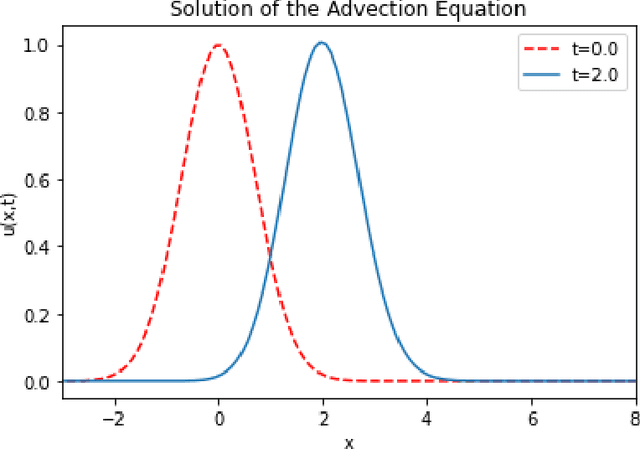
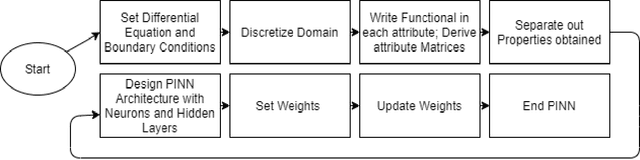
Numerical solutions to the equation for advection are determined using different finite-difference approximations and physics-informed neural networks (PINNs) under conditions that allow an analytical solution. Their accuracy is examined by comparing them to the analytical solution. We used a machine learning framework like PyTorch to implement PINNs. PINNs approach allows training neural networks while respecting the PDEs as a strong constraint in the optimization as apposed to making them part of the loss function. In standard small-scale circulation simulations, it is shown that the conventional approach incorporates a pseudo diffusive effect that is almost as large as the effect of the turbulent diffusion model; hence the numerical solution is rendered inconsistent with the PDEs. This oscillation causes inaccuracy and computational uncertainty. Of all the schemes tested, only the PINNs approximation accurately predicted the outcome. We assume that the PINNs approach can transform the physics simulation area by allowing real-time physics simulation and geometry optimization without costly and time-consuming simulations on large supercomputers.
Multi-Task Hierarchical Learning Based Network Traffic Analytics
Jun 05, 2021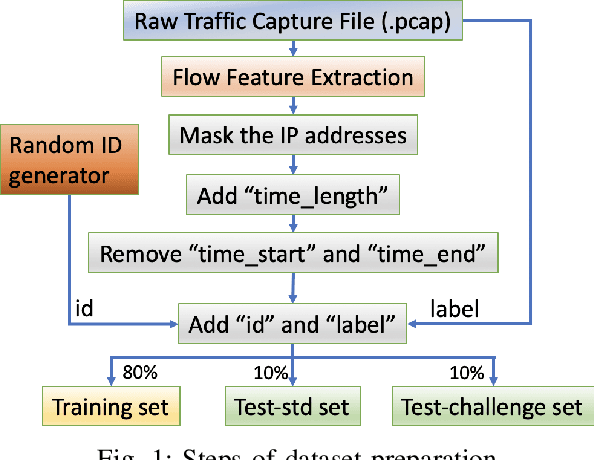
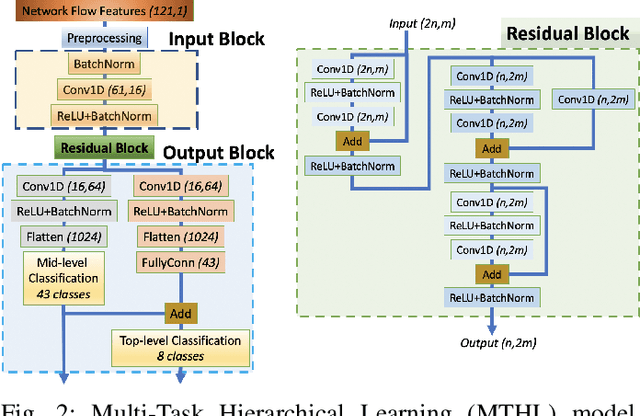
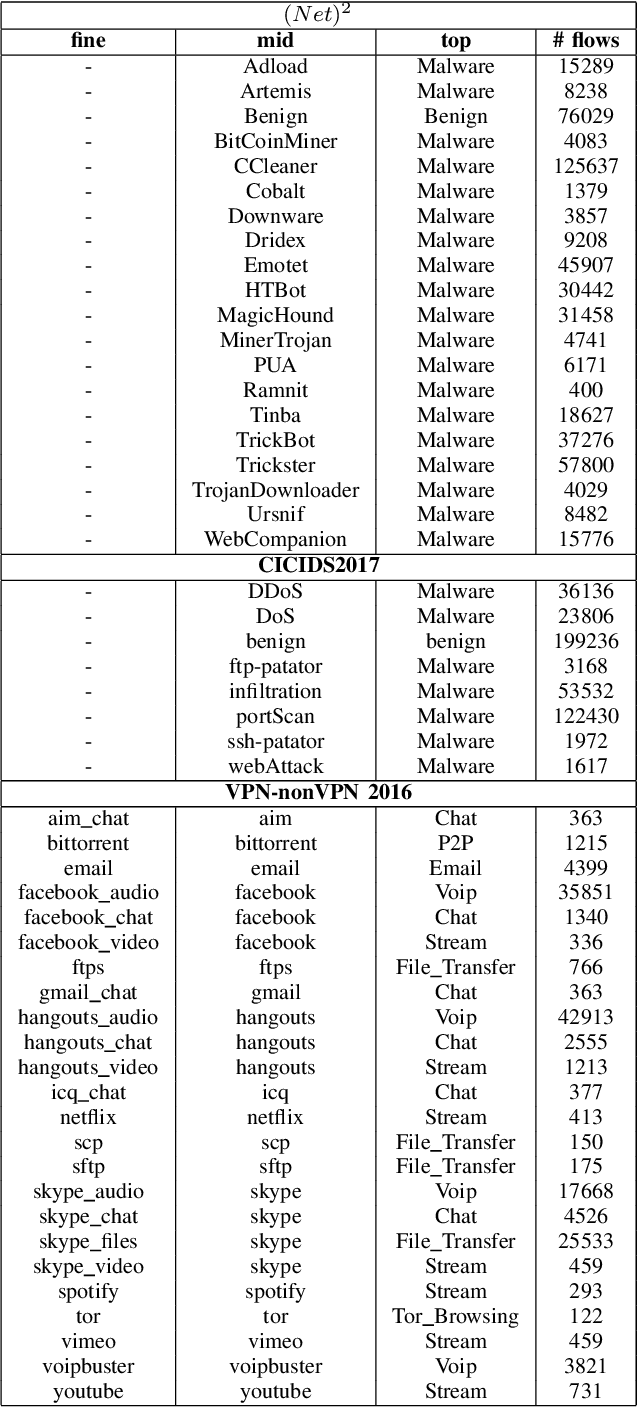

Classifying network traffic is the basis for important network applications. Prior research in this area has faced challenges on the availability of representative datasets, and many of the results cannot be readily reproduced. Such a problem is exacerbated by emerging data-driven machine learning based approaches. To address this issue, we present(N et)2databasewith three open datasets containing nearly 1.3M labeled flows in total, with a comprehensive list of flow features, for there search community1. We focus on broad aspects in network traffic analysis, including both malware detection and application classification. As we continue to grow them, we expect the datasets to serve as a common ground for AI driven, reproducible research on network flow analytics. We release the datasets publicly and also introduce a Multi-Task Hierarchical Learning (MTHL)model to perform all tasks in a single model. Our results show that MTHL is capable of accurately performing multiple tasks with hierarchical labeling with a dramatic reduction in training time.
Graph Jigsaw Learning for Cartoon Face Recognition
Jul 14, 2021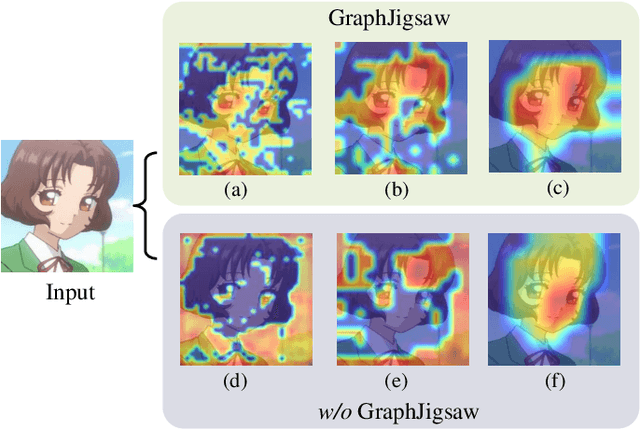
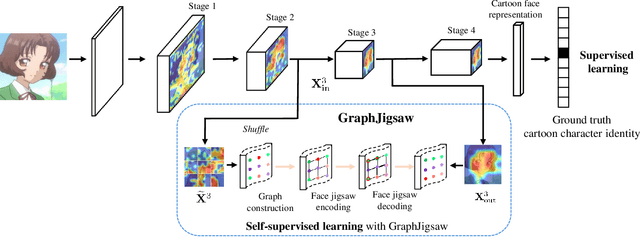
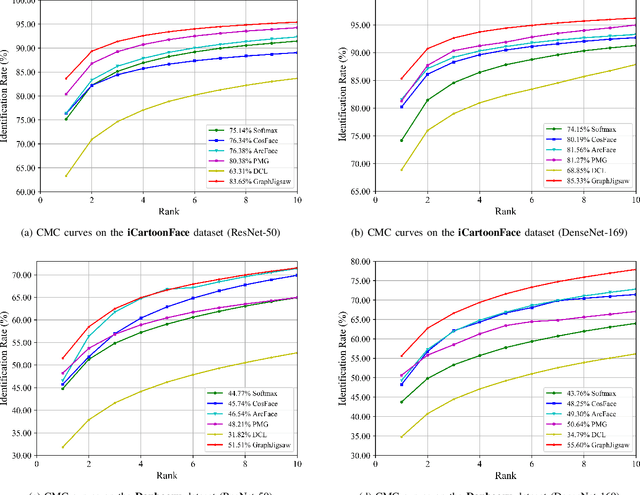

Cartoon face recognition is challenging as they typically have smooth color regions and emphasized edges, the key to recognize cartoon faces is to precisely perceive their sparse and critical shape patterns. However, it is quite difficult to learn a shape-oriented representation for cartoon face recognition with convolutional neural networks (CNNs). To mitigate this issue, we propose the GraphJigsaw that constructs jigsaw puzzles at various stages in the classification network and solves the puzzles with the graph convolutional network (GCN) in a progressive manner. Solving the puzzles requires the model to spot the shape patterns of the cartoon faces as the texture information is quite limited. The key idea of GraphJigsaw is constructing a jigsaw puzzle by randomly shuffling the intermediate convolutional feature maps in the spatial dimension and exploiting the GCN to reason and recover the correct layout of the jigsaw fragments in a self-supervised manner. The proposed GraphJigsaw avoids training the classification model with the deconstructed images that would introduce noisy patterns and are harmful for the final classification. Specially, GraphJigsaw can be incorporated at various stages in a top-down manner within the classification model, which facilitates propagating the learned shape patterns gradually. GraphJigsaw does not rely on any extra manual annotation during the training process and incorporates no extra computation burden at inference time. Both quantitative and qualitative experimental results have verified the feasibility of our proposed GraphJigsaw, which consistently outperforms other face recognition or jigsaw-based methods on two popular cartoon face datasets with considerable improvements.
Recursively Refined R-CNN: Instance Segmentation with Self-RoI Rebalancing
Apr 03, 2021
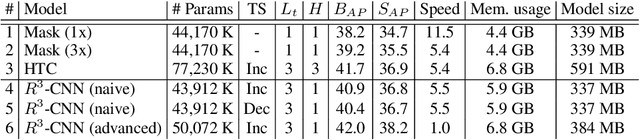
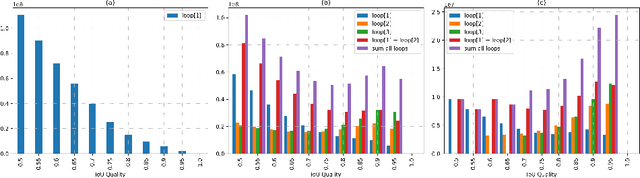

Within the field of instance segmentation, most of the state-of-the-art deep learning networks rely nowadays on cascade architectures, where multiple object detectors are trained sequentially, re-sampling the ground truth at each step. This offers a solution to the problem of exponentially vanishing positive samples. However, it also translates into an increase in network complexity in terms of the number of parameters. To address this issue, we propose Recursively Refined R-CNN ($R^3$-CNN) which avoids duplicates by introducing a loop mechanism instead. At the same time, it achieves a quality boost using a recursive re-sampling technique, where a specific IoU quality is utilized in each recursion to eventually equally cover the positive spectrum. Our experiments highlight the specific encoding of the loop mechanism in the weights, requiring its usage at inference time. The $R^3$-CNN architecture is able to surpass the recently proposed HTC model, while reducing the number of parameters significantly. Experiments on COCO minival 2017 dataset show performance boost independently from the utilized baseline model. The code is available online at https://github.com/IMPLabUniPr/mmdetection/tree/r3_cnn.
CRPS Learning
Feb 01, 2021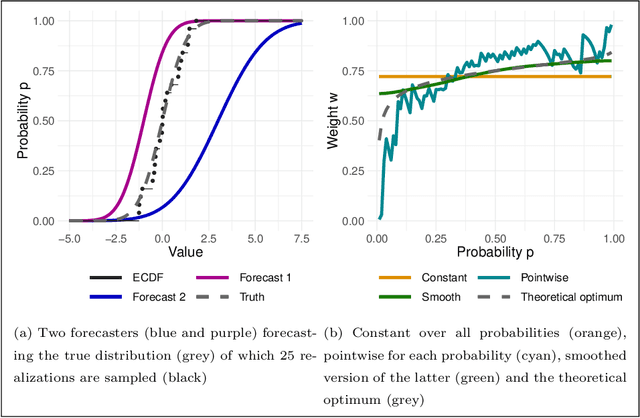
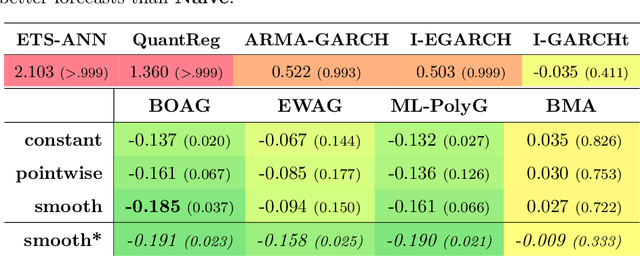
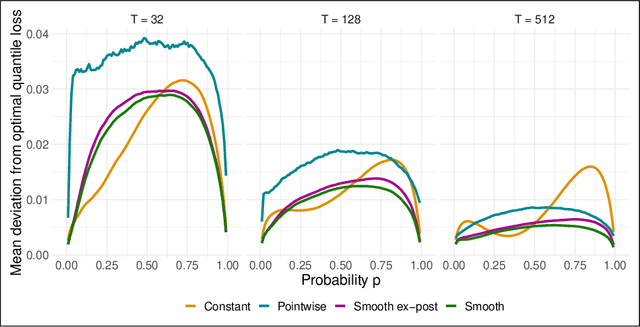
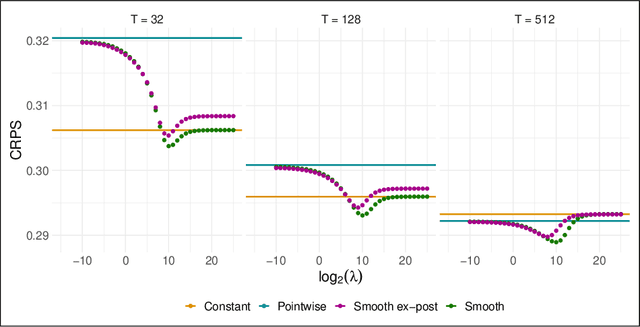
Combination and aggregation techniques can improve forecast accuracy substantially. This also holds for probabilistic forecasting methods where full predictive distributions are combined. There are several time-varying and adaptive weighting schemes like Bayesian model averaging (BMA). However, the performance of different forecasters may vary not only over time but also in parts of the distribution. So one may be more accurate in the center of the distributions, and other ones perform better in predicting the distribution's tails. Consequently, we introduce a new weighting procedure that considers both varying performance across time and the distribution. We discuss pointwise online aggregation algorithms that optimize with respect to the continuous ranked probability score (CRPS). After analyzing the theoretical properties of a fully adaptive Bernstein online aggregation (BOA) method, we introduce smoothing procedures for pointwise CRPS learning. The properties are confirmed and discussed using simulation studies. Additionally, we illustrate the performance in a forecasting study for carbon markets. In detail, we predict the distribution of European emission allowance prices.