 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian Optimisation for a Biologically Inspired Population Neural Network
Apr 13, 2021
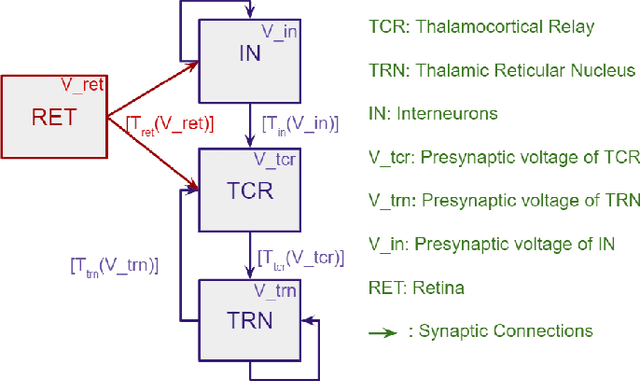
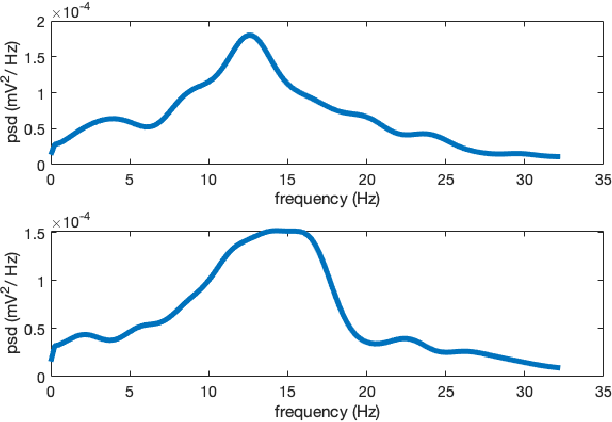

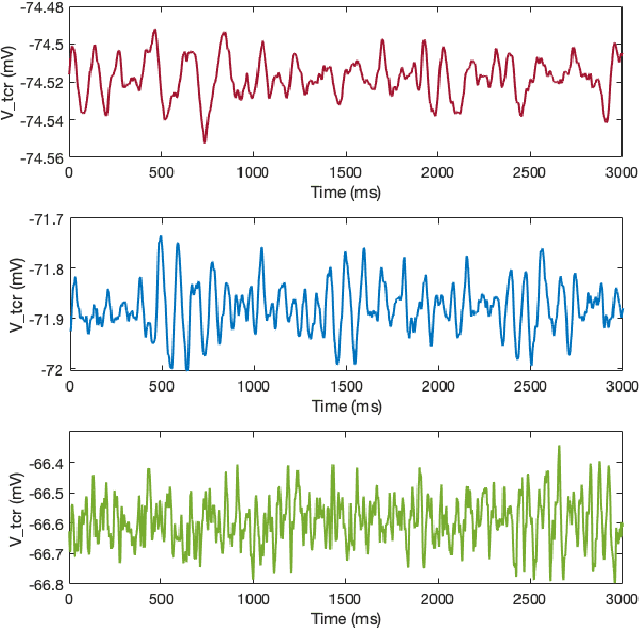
We have used Bayesian Optimisation (BO) to find hyper-parameters in an existing biologically plausible population neural network. The 8-dimensional optimal hyper-parameter combination should be such that the network dynamics simulate the resting state alpha rhythm (8 - 13 Hz rhythms in brain signals). Each combination of these eight hyper-parameters constitutes a 'datapoint' in the parameter space. The best combination of these parameters leads to the neural network's output power spectral peak being constraint within the alpha band. Further, constraints were introduced to the BO algorithm based on qualitative observation of the network output time series, so that high amplitude pseudo-periodic oscillations are removed. Upon successful implementation for alpha band, we further optimised the network to oscillate within the theta (4 - 8 Hz) and beta (13 - 30 Hz) bands. The changing rhythms in the model can now be studied using the identified optimal hyper-parameters for the respective frequency bands. We have previously tuned parameters in the existing neural network by the trial-and-error approach; however, due to time and computational constraints, we could not vary more than three parameters at once. The approach detailed here, allows an automatic hyper-parameter search, producing reliable parameter sets for the network.
Empirical Bayesian Independent Deeply Learned Matrix Analysis For Multichannel Audio Source Separation
Jun 07, 2021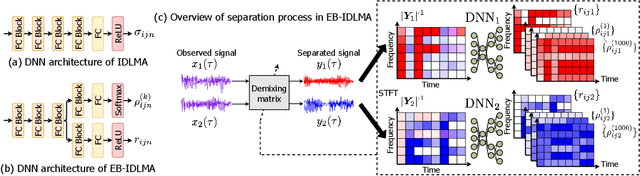
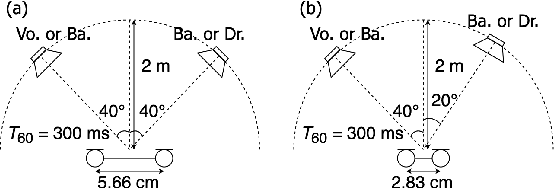
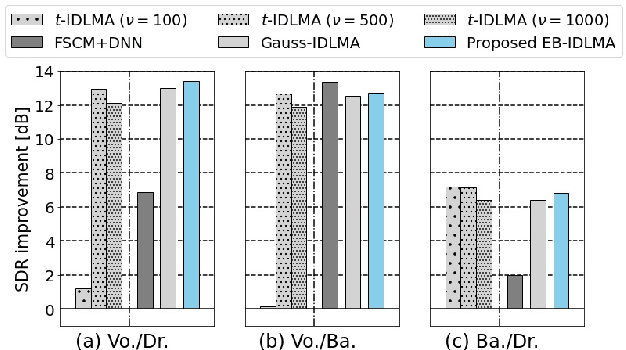
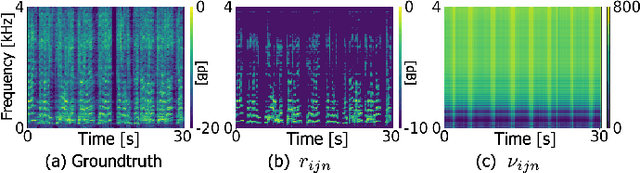
Independent deeply learned matrix analysis (IDLMA) is one of the state-of-the-art supervised multichannel audio source separation methods. It blindly estimates the demixing filters on the basis of source independence, using the source model estimated by the deep neural network (DNN). However, since the ratios of the source to interferer signals vary widely among time-frequency (TF) slots, it is difficult to obtain reliable estimated power spectrograms of sources at all TF slots. In this paper, we propose an IDLMA extension, empirical Bayesian IDLMA (EB-IDLMA), by introducing a prior distribution of source power spectrograms and treating the source power spectrograms as latent random variables. This treatment allows us to implicitly consider the reliability of the estimated source power spectrograms for the estimation of demixing filters through the hyperparameters of the prior distribution estimated by the DNN. Experimental evaluations show the effectiveness of EB-IDLMA and the importance of introducing the reliability of the estimated source power spectrograms.
Transitive Learning: Exploring the Transitivity of Degradations for Blind Super-Resolution
Mar 29, 2021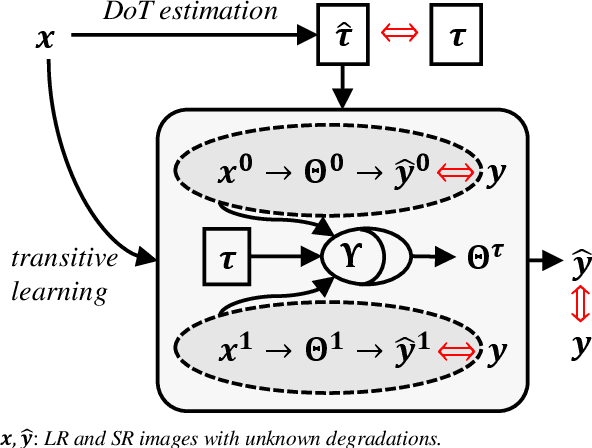
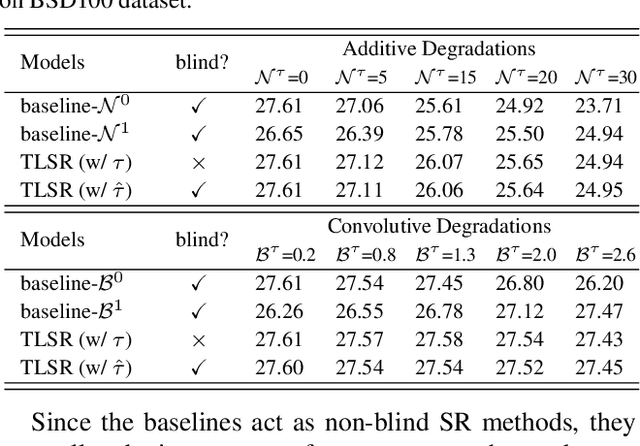
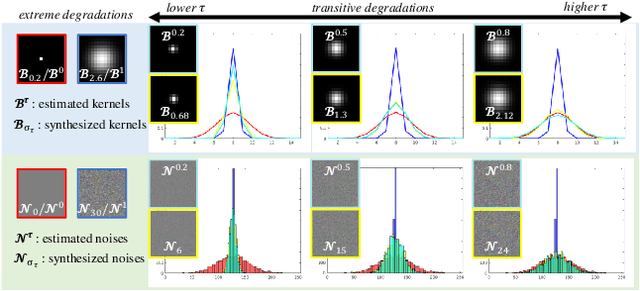
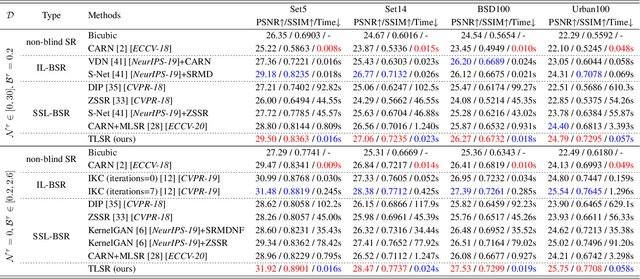
Being extremely dependent on the iterative estimation and correction of data or models, the existing blind super-resolution (SR) methods are generally time-consuming and less effective. To address it, this paper proposes a transitive learning method for blind SR using an end-to-end network without any additional iterations in inference. To begin with, we analyze and demonstrate the transitivity of degradations, including the widely used additive and convolutive degradations. We then propose a novel Transitive Learning method for blind Super-Resolution on transitive degradations (TLSR), by adaptively inferring a transitive transformation function to solve the unknown degradations without any iterative operations in inference. Specifically, the end-to-end TLSR network consists of a degree of transitivity (DoT) estimation network, a homogeneous feature extraction network, and a transitive learning module. Quantitative and qualitative evaluations on blind SR tasks demonstrate that the proposed TLSR achieves superior performance and consumes less time against the state-of-the-art blind SR methods. The code is available at https://github.com/YuanfeiHuang/TLSR.
An Efficient Approach for Anomaly Detection in Traffic Videos
Apr 20, 2021
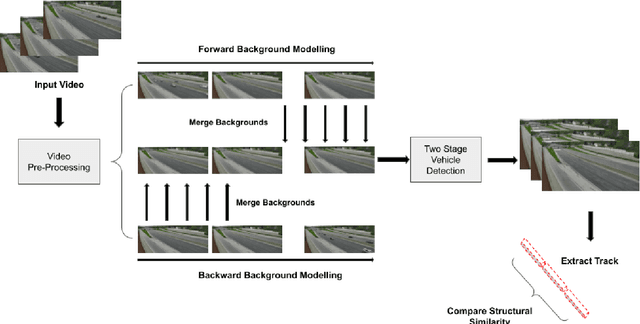

Due to its relevance in intelligent transportation systems, anomaly detection in traffic videos has recently received much interest. It remains a difficult problem due to a variety of factors influencing the video quality of a real-time traffic feed, such as temperature, perspective, lighting conditions, and so on. Even though state-of-the-art methods perform well on the available benchmark datasets, they need a large amount of external training data as well as substantial computational resources. In this paper, we propose an efficient approach for a video anomaly detection system which is capable of running at the edge devices, e.g., on a roadside camera. The proposed approach comprises a pre-processing module that detects changes in the scene and removes the corrupted frames, a two-stage background modelling module and a two-stage object detector. Finally, a backtracking anomaly detection algorithm computes a similarity statistic and decides on the onset time of the anomaly. We also propose a sequential change detection algorithm that can quickly adapt to a new scene and detect changes in the similarity statistic. Experimental results on the Track 4 test set of the 2021 AI City Challenge show the efficacy of the proposed framework as we achieve an F1-score of 0.9157 along with 8.4027 root mean square error (RMSE) and are ranked fourth in the competition.
Enhancing the Analysis of Software Failures in Cloud Computing Systems with Deep Learning
Jun 29, 2021



Identifying the failure modes of cloud computing systems is a difficult and time-consuming task, due to the growing complexity of such systems, and the large volume and noisiness of failure data. This paper presents a novel approach for analyzing failure data from cloud systems, in order to relieve human analysts from manually fine-tuning the data for feature engineering. The approach leverages Deep Embedded Clustering (DEC), a family of unsupervised clustering algorithms based on deep learning, which uses an autoencoder to optimize data dimensionality and inter-cluster variance. We applied the approach in the context of the OpenStack cloud computing platform, both on the raw failure data and in combination with an anomaly detection pre-processing algorithm. The results show that the performance of the proposed approach, in terms of purity of clusters, is comparable to, or in some cases even better than manually fine-tuned clustering, thus avoiding the need for deep domain knowledge and reducing the effort to perform the analysis. In all cases, the proposed approach provides better performance than unsupervised clustering when no feature engineering is applied to the data. Moreover, the distribution of failure modes from the proposed approach is closer to the actual frequency of the failure modes.
Simultaneous boundary shape estimation and velocity field de-noising in Magnetic Resonance Velocimetry using Physics-informed Neural Networks
Jul 16, 2021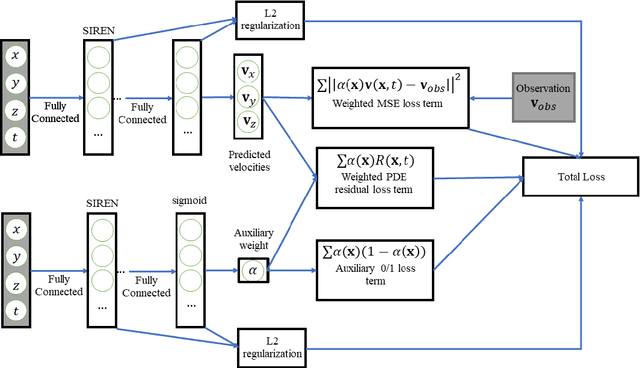
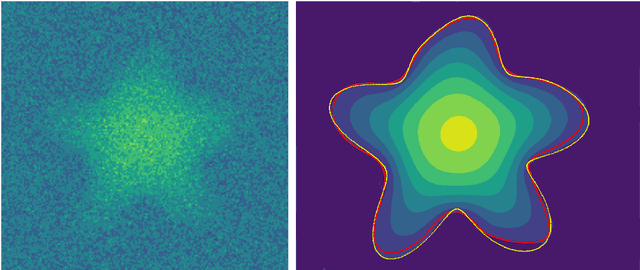
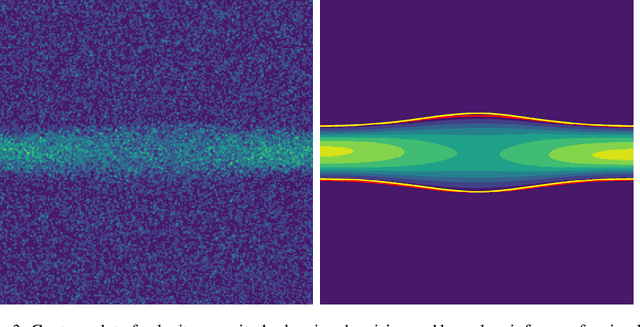
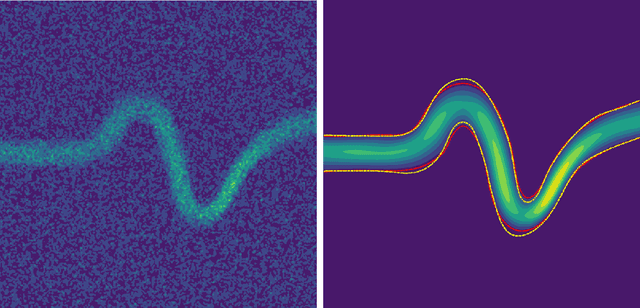
Magnetic resonance velocimetry (MRV) is a non-invasive experimental technique widely used in medicine and engineering to measure the velocity field of a fluid. These measurements are dense but have a low signal-to-noise ratio (SNR). The measurements can be de-noised by imposing physical constraints on the flow, which are encapsulated in governing equations for mass and momentum. Previous studies have required the shape of the boundary (for example, a blood vessel) to be known a priori. This, however, requires a set of additional measurements, which can be expensive to obtain. In this paper, we present a physics-informed neural network that instead uses the noisy MRV data alone to simultaneously infer the most likely boundary shape and de-noised velocity field. We achieve this by training an auxiliary neural network that takes the value 1.0 within the inferred domain of the governing PDE and 0.0 outside. This network is used to weight the PDE residual term in the loss function accordingly and implicitly learns the geometry of the system. We test our algorithm by assimilating both synthetic and real MRV measurements for flows that can be well modeled by the Poisson and Stokes equations. We find that we are able to reconstruct very noisy (SNR = 2.5) MRV signals and recover the ground truth with low reconstruction errors of 3.7 - 7.5%. The simplicity and flexibility of our physics-informed neural network approach can readily scale to assimilating MRV data with complex 3D geometries, time-varying 4D data, or unknown parameters in the physical model.
End-to-End Unsupervised Document Image Blind Denoising
May 19, 2021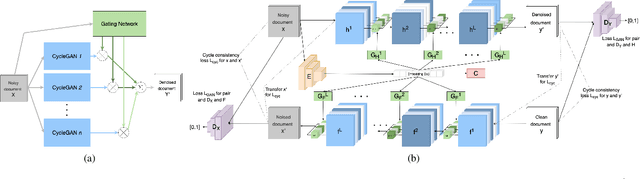
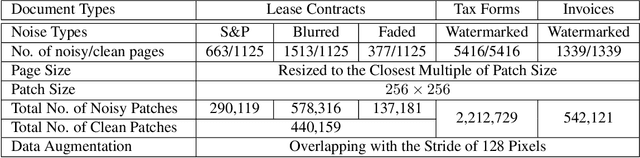
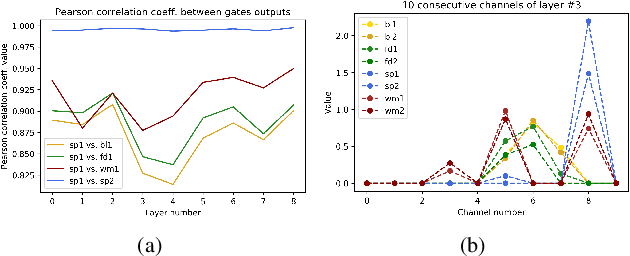
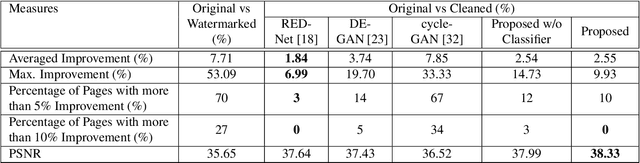
Removing noise from scanned pages is a vital step before their submission to optical character recognition (OCR) system. Most available image denoising methods are supervised where the pairs of noisy/clean pages are required. However, this assumption is rarely met in real settings. Besides, there is no single model that can remove various noise types from documents. Here, we propose a unified end-to-end unsupervised deep learning model, for the first time, that can effectively remove multiple types of noise, including salt \& pepper noise, blurred and/or faded text, as well as watermarks from documents at various levels of intensity. We demonstrate that the proposed model significantly improves the quality of scanned images and the OCR of the pages on several test datasets.
Over-the-Air Equalization with Reconfigurable Intelligent Surfaces
Jun 29, 2021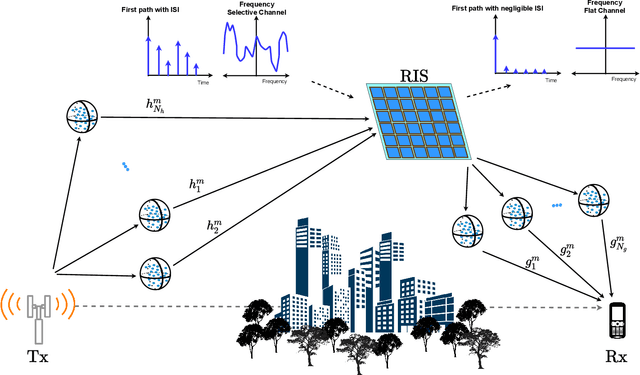
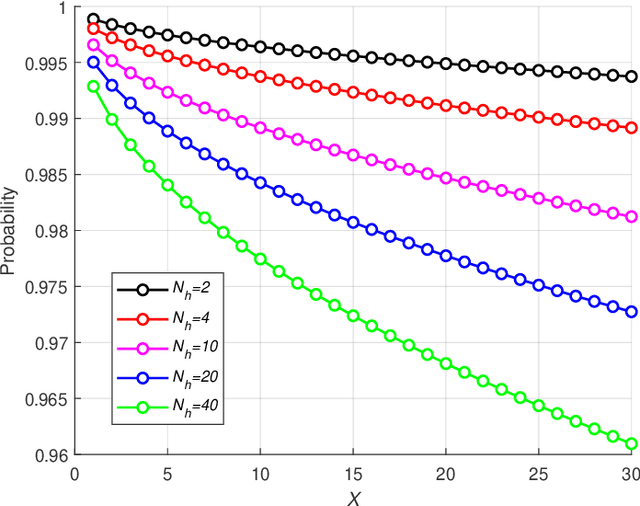
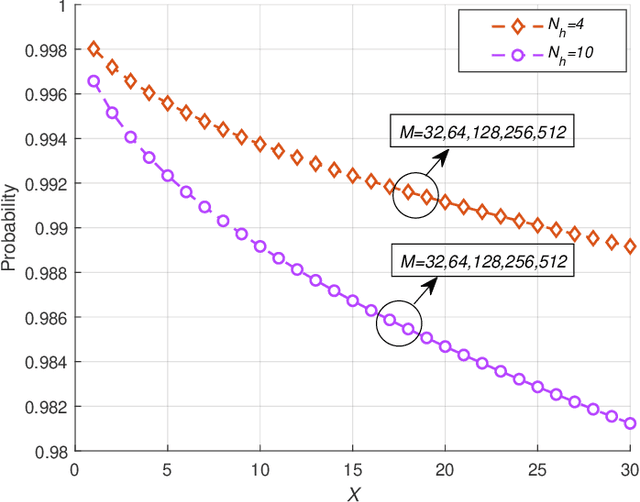
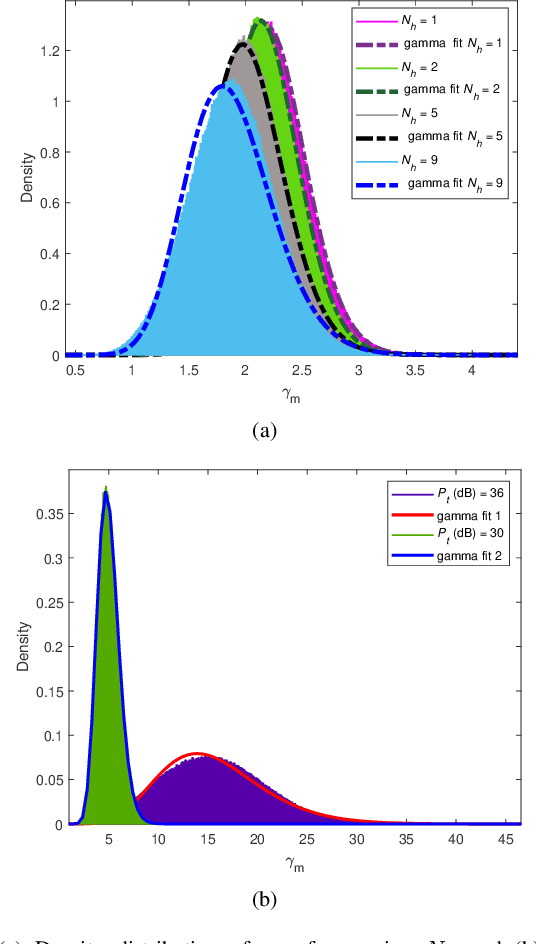
Reconfigurable intelligent surface (RIS)-empowered communications is on the rise and is a promising technology envisioned to aid in 6G and beyond wireless communication networks. RISs can manipulate impinging waves through their electromagnetic elements enabling some sort of a control over the wireless channel. In this paper, the potential of RIS technology is explored to perform equalization over-the-air for frequency-selective channels whereas, equalization is generally conducted at either the transmitter or receiver in conventional communication systems. Specifically, with the aid of an RIS, the frequency-selective channel from the transmitter to the RIS is transformed to a frequency-flat channel through elimination of inter-symbol interference (ISI) components at the receiver. ISI is eliminated by adjusting the phases of impinging signals particularly to maximize the incoming signal of the strongest tap. First, a general end-to-end system model is provided and a continuous to discrete-time signal model is presented. Subsequently, a probabilistic analysis for the elimination of ISI terms is conducted and reinforced with computer simulations. Furthermore, a theoretical error probability analysis is performed along with computer simulations. It is demonstrated that with the proposed method, ISI can successfully be eliminated and the RIS-aided communication channel can be converted from frequency-selective to frequency-flat.
Exploring Bayesian Deep Learning for Urgent Instructor Intervention Need in MOOC Forums
Apr 26, 2021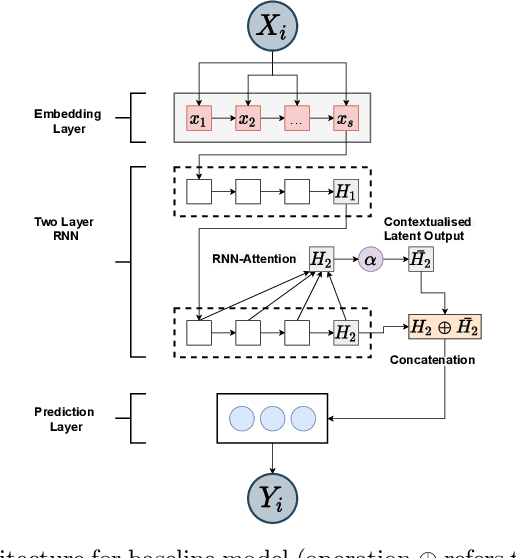
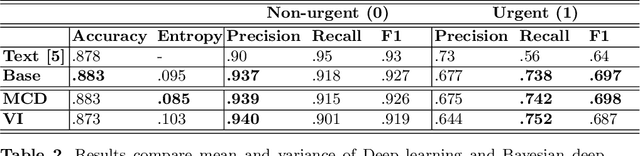
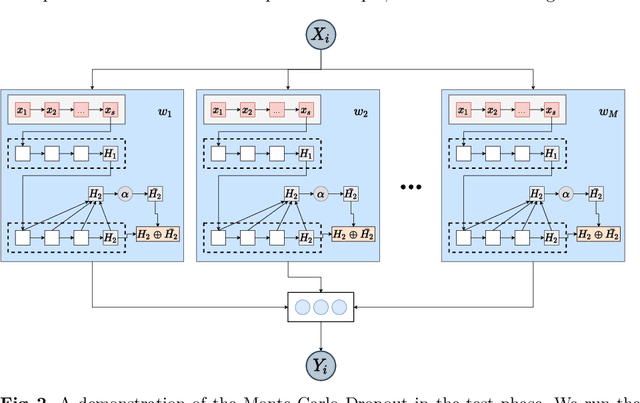
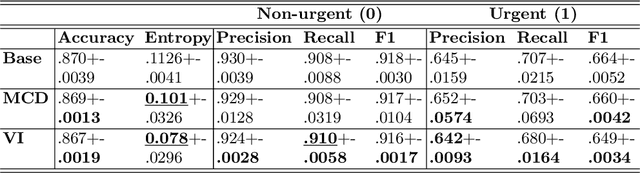
Massive Open Online Courses (MOOCs) have become a popular choice for e-learning thanks to their great flexibility. However, due to large numbers of learners and their diverse backgrounds, it is taxing to offer real-time support. Learners may post their feelings of confusion and struggle in the respective MOOC forums, but with the large volume of posts and high workloads for MOOC instructors, it is unlikely that the instructors can identify all learners requiring intervention. This problem has been studied as a Natural Language Processing (NLP) problem recently, and is known to be challenging, due to the imbalance of the data and the complex nature of the task. In this paper, we explore for the first time Bayesian deep learning on learner-based text posts with two methods: Monte Carlo Dropout and Variational Inference, as a new solution to assessing the need of instructor interventions for a learner's post. We compare models based on our proposed methods with probabilistic modelling to its baseline non-Bayesian models under similar circumstances, for different cases of applying prediction. The results suggest that Bayesian deep learning offers a critical uncertainty measure that is not supplied by traditional neural networks. This adds more explainability, trust and robustness to AI, which is crucial in education-based applications. Additionally, it can achieve similar or better performance compared to non-probabilistic neural networks, as well as grant lower variance.
A Theoretical Analysis of Granulometry-based Roughness Measures on Cartosat DEMs
Jul 16, 2021
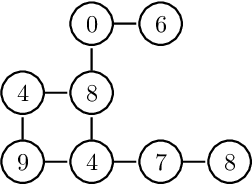
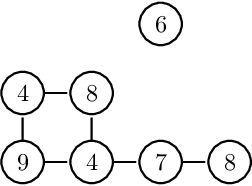
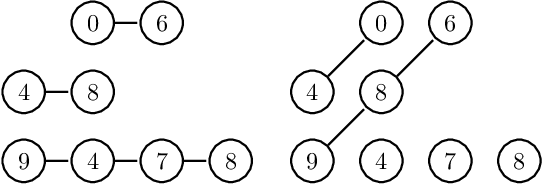
The study of water bodies such as rivers is an important problem in the remote sensing community. A meaningful set of quantitative features reflecting the geophysical properties help us better understand the formation and evolution of rivers. Typically, river sub-basins are analysed using Cartosat Digital Elevation Models (DEMs), obtained at regular time epochs. One of the useful geophysical features of a river sub-basin is that of a roughness measure on DEMs. However, to the best of our knowledge, there is not much literature available on theoretical analysis of roughness measures. In this article, we revisit the roughness measure on DEM data adapted from multiscale granulometries in mathematical morphology, namely multiscale directional granulometric index (MDGI). This measure was classically used to obtain shape-size analysis in greyscale images. In earlier works, MDGIs were introduced to capture the characteristic surficial roughness of a river sub-basin along specific directions. Also, MDGIs can be efficiently computed and are known to be useful features for classification of river sub-basins. In this article, we provide a theoretical analysis of a MDGI. In particular, we characterize non-trivial sufficient conditions on the structure of DEMs under which MDGIs are invariant. These properties are illustrated with some fictitious DEMs. We also provide connections to a discrete derivative of volume of a DEM. Based on these connections, we provide intuition as to why a MDGI is considered a roughness measure. Further, we experimentally illustrate on Lower-Indus, Wardha, and Barmer river sub-basins that the proposed features capture the characteristics of the river sub-basin.