 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom News to Returns: A Granger-Causal Hypergraph Transformer on the Sphere
Oct 05, 2025We propose the Causal Sphere Hypergraph Transformer (CSHT), a novel architecture for interpretable financial time-series forecasting that unifies \emph{Granger-causal hypergraph structure}, \emph{Riemannian geometry}, and \emph{causally masked Transformer attention}. CSHT models the directional influence of financial news and sentiment on asset returns by extracting multivariate Granger-causal dependencies, which are encoded as directional hyperedges on the surface of a hypersphere. Attention is constrained via angular masks that preserve both temporal directionality and geometric consistency. Evaluated on S\&P 500 data from 2018 to 2023, including the 2020 COVID-19 shock, CSHT consistently outperforms baselines across return prediction, regime classification, and top-asset ranking tasks. By enforcing predictive causal structure and embedding variables in a Riemannian manifold, CSHT delivers both \emph{robust generalisation across market regimes} and \emph{transparent attribution pathways} from macroeconomic events to stock-level responses. These results suggest that CSHT is a principled and practical solution for trustworthy financial forecasting under uncertainty.
ManifoldMind: Dynamic Hyperbolic Reasoning for Trustworthy Recommendations
Jul 02, 2025We introduce ManifoldMind, a probabilistic geometric recommender system for exploratory reasoning over semantic hierarchies in hyperbolic space. Unlike prior methods with fixed curvature and rigid embeddings, ManifoldMind represents users, items, and tags as adaptive-curvature probabilistic spheres, enabling personalised uncertainty modeling and geometry-aware semantic exploration. A curvature-aware semantic kernel supports soft, multi-hop inference, allowing the model to explore diverse conceptual paths instead of overfitting to shallow or direct interactions. Experiments on four public benchmarks show superior NDCG, calibration, and diversity compared to strong baselines. ManifoldMind produces explicit reasoning traces, enabling transparent, trustworthy, and exploration-driven recommendations in sparse or abstract domains.
Breaking Down Financial News Impact: A Novel AI Approach with Geometric Hypergraphs
Aug 31, 2024



In the fast-paced and volatile financial markets, accurately predicting stock movements based on financial news is critical for investors and analysts. Traditional models often struggle to capture the intricate and dynamic relationships between news events and market reactions, limiting their ability to provide actionable insights. This paper introduces a novel approach leveraging Explainable Artificial Intelligence (XAI) through the development of a Geometric Hypergraph Attention Network (GHAN) to analyze the impact of financial news on market behaviours. Geometric hypergraphs extend traditional graph structures by allowing edges to connect multiple nodes, effectively modelling high-order relationships and interactions among financial entities and news events. This unique capability enables the capture of complex dependencies, such as the simultaneous impact of a single news event on multiple stocks or sectors, which traditional models frequently overlook. By incorporating attention mechanisms within hypergraphs, GHAN enhances the model's ability to focus on the most relevant information, ensuring more accurate predictions and better interpretability. Additionally, we employ BERT-based embeddings to capture the semantic richness of financial news texts, providing a nuanced understanding of the content. Using a comprehensive financial news dataset, our GHAN model addresses key challenges in financial news impact analysis, including the complexity of high-order interactions, the necessity for model interpretability, and the dynamic nature of financial markets. Integrating attention mechanisms and SHAP values within GHAN ensures transparency, highlighting the most influential factors driving market predictions. Empirical validation demonstrates the superior effectiveness of our approach over traditional sentiment analysis and time-series models.
Deep Latent Variable Models for Semi-supervised Paraphrase Generation
Jan 05, 2023



This paper explores deep latent variable models for semi-supervised paraphrase generation, where the missing target pair is modelled as a latent paraphrase sequence. We present a novel unsupervised model named variational sequence auto-encoding reconstruction (VSAR), which performs latent sequence inference given an observed text. To leverage information from text pairs, we introduce a supervised model named dual directional learning (DDL). Combining VSAR with DDL (DDL+VSAR) enables us to conduct semi-supervised learning; however, the combined model suffers from a cold-start problem. To combat this issue, we propose to deal with better weight initialisation, leading to a two-stage training scheme named knowledge reinforced training. Our empirical evaluations suggest that the combined model yields competitive performance against the state-of-the-art supervised baselines on complete data. Furthermore, in scenarios where only a fraction of the labelled pairs are available, our combined model consistently outperforms the strong supervised model baseline (DDL and Transformer) by a significant margin.
INTERACTION: A Generative XAI Framework for Natural Language Inference Explanations
Sep 02, 2022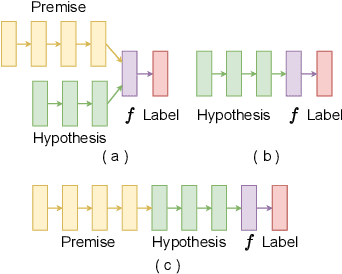
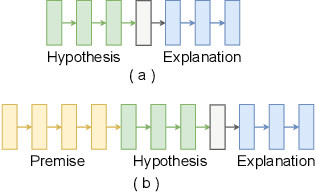
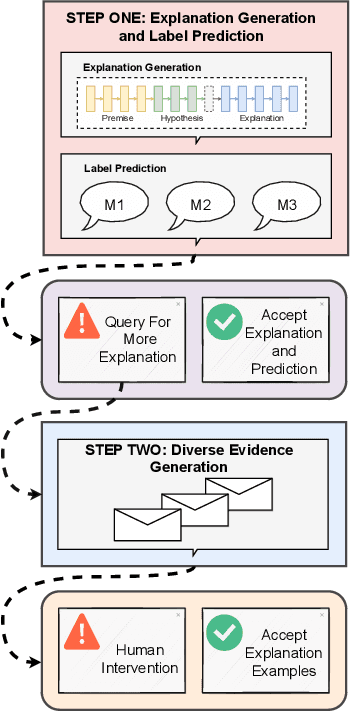

XAI with natural language processing aims to produce human-readable explanations as evidence for AI decision-making, which addresses explainability and transparency. However, from an HCI perspective, the current approaches only focus on delivering a single explanation, which fails to account for the diversity of human thoughts and experiences in language. This paper thus addresses this gap, by proposing a generative XAI framework, INTERACTION (explaIn aNd predicT thEn queRy with contextuAl CondiTional varIational autO-eNcoder). Our novel framework presents explanation in two steps: (step one) Explanation and Label Prediction; and (step two) Diverse Evidence Generation. We conduct intensive experiments with the Transformer architecture on a benchmark dataset, e-SNLI. Our method achieves competitive or better performance against state-of-the-art baseline models on explanation generation (up to 4.7% gain in BLEU) and prediction (up to 4.4% gain in accuracy) in step one; it can also generate multiple diverse explanations in step two.
Exploring Bayesian Deep Learning for Urgent Instructor Intervention Need in MOOC Forums
Apr 26, 2021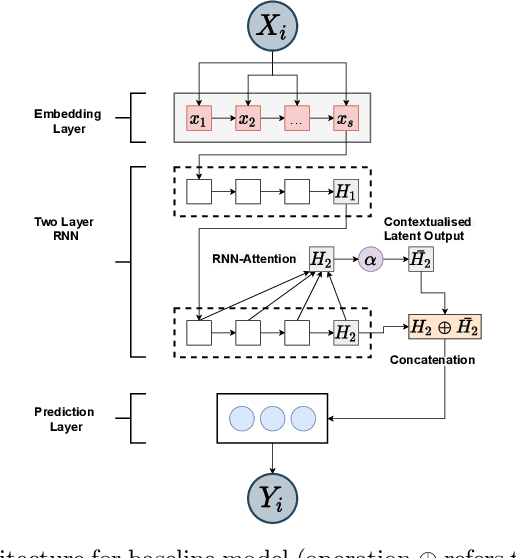
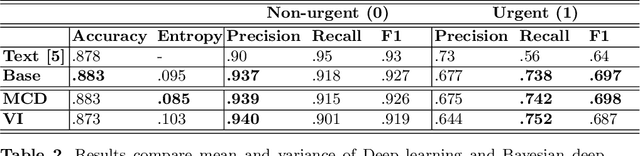
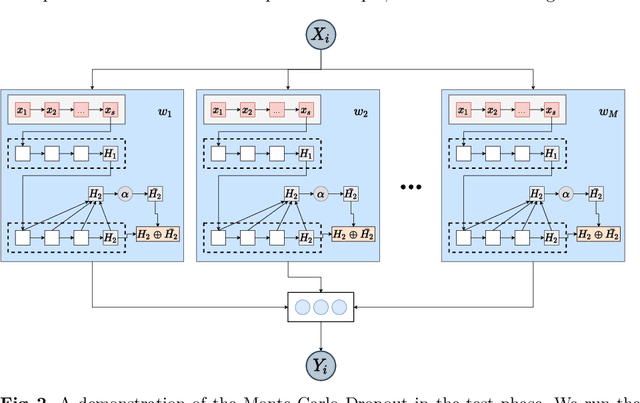
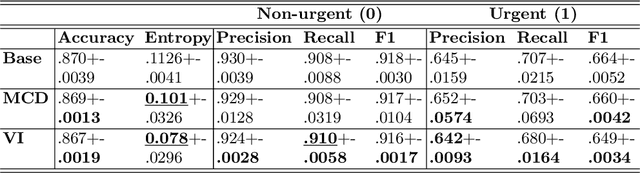
Massive Open Online Courses (MOOCs) have become a popular choice for e-learning thanks to their great flexibility. However, due to large numbers of learners and their diverse backgrounds, it is taxing to offer real-time support. Learners may post their feelings of confusion and struggle in the respective MOOC forums, but with the large volume of posts and high workloads for MOOC instructors, it is unlikely that the instructors can identify all learners requiring intervention. This problem has been studied as a Natural Language Processing (NLP) problem recently, and is known to be challenging, due to the imbalance of the data and the complex nature of the task. In this paper, we explore for the first time Bayesian deep learning on learner-based text posts with two methods: Monte Carlo Dropout and Variational Inference, as a new solution to assessing the need of instructor interventions for a learner's post. We compare models based on our proposed methods with probabilistic modelling to its baseline non-Bayesian models under similar circumstances, for different cases of applying prediction. The results suggest that Bayesian deep learning offers a critical uncertainty measure that is not supplied by traditional neural networks. This adds more explainability, trust and robustness to AI, which is crucial in education-based applications. Additionally, it can achieve similar or better performance compared to non-probabilistic neural networks, as well as grant lower variance.