 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
Jun 04, 2021
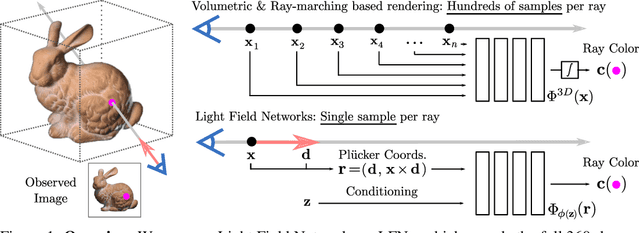

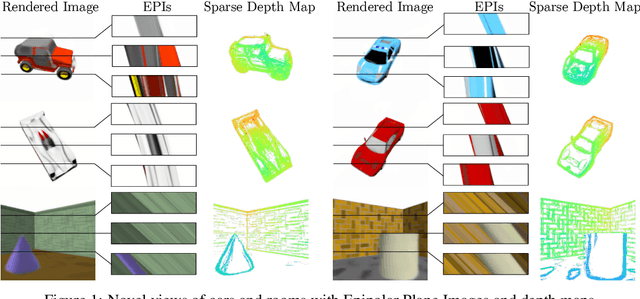
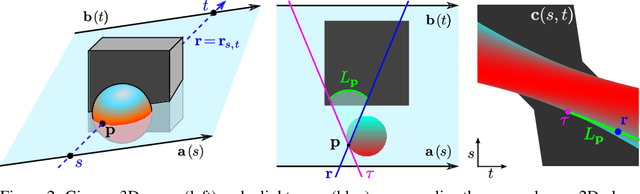
Inferring representations of 3D scenes from 2D observations is a fundamental problem of computer graphics, computer vision, and artificial intelligence. Emerging 3D-structured neural scene representations are a promising approach to 3D scene understanding. In this work, we propose a novel neural scene representation, Light Field Networks or LFNs, which represent both geometry and appearance of the underlying 3D scene in a 360-degree, four-dimensional light field parameterized via a neural implicit representation. Rendering a ray from an LFN requires only a *single* network evaluation, as opposed to hundreds of evaluations per ray for ray-marching or volumetric based renderers in 3D-structured neural scene representations. In the setting of simple scenes, we leverage meta-learning to learn a prior over LFNs that enables multi-view consistent light field reconstruction from as little as a single image observation. This results in dramatic reductions in time and memory complexity, and enables real-time rendering. The cost of storing a 360-degree light field via an LFN is two orders of magnitude lower than conventional methods such as the Lumigraph. Utilizing the analytical differentiability of neural implicit representations and a novel parameterization of light space, we further demonstrate the extraction of sparse depth maps from LFNs.
Video-Streaming Biomedical Implants using Ultrasonic Waves for Communication
Jun 28, 2021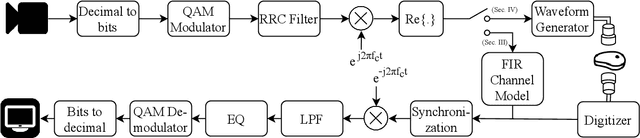
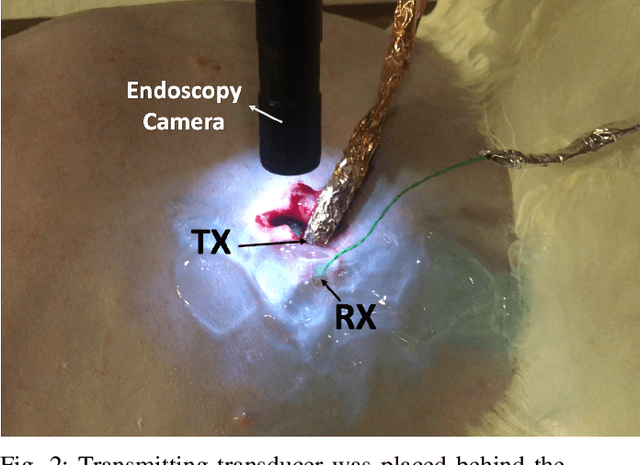


The use of wireless implanted medical devices (IMDs) is growing because they facilitate continuous monitoring of patients during normal activities, simplify medical procedures required for data retrieval and reduce the likelihood of infection associated with trailing wires. However, most of the state-of-the-art IMDs are passive and offline devices. One of the key obstacles to an active and online IMD is the infeasibility of real-time, high-quality video broadcast from the IMD. Such broadcast would help develop innovative devices such as a video-streaming capsule endoscopy (CE) pill with therapeutic intervention capabilities. State-of-the-art IMDs employ radio-frequency electromagnetic waves for information transmission. However, high attenuation of RF-EM waves in tissues and federal restrictions on the transmit power and operable bandwidth lead to fundamental performance constraints for IMDs employing RF links, and prevent achieving high data rates that could accomodate video broadcast. In this work, ultrasonic waves were used for video transmission and broadcast through biological tissues. The proposed proof-of-concept system was tested on a porcine intestine ex vivo and a rabbit in vivo. It was demonstrated that using a millimeter-sized, implanted biocompatible transducer operating at 1.1-1.2 MHz, it was possible to transmit endoscopic video with high resolution (1280 pixels by 720 pixels) through porcine intestine wrapped with bacon, and to broadcast standard definition (640 pixels by 480 pixels) video near real-time through rabbit abdomen in vivo. A media repository that includes experimental demonstrations and media files accompanies this paper. The accompanying media repository can be found at this link: https://bit.ly/3wuc7tk.
Enlisting 3D Crop Models and GANs for More Data Efficient and Generalizable Fruit Detection
Aug 30, 2021


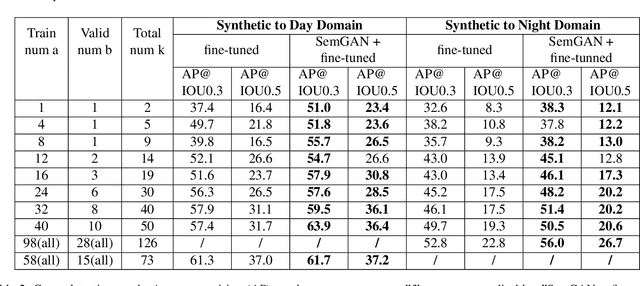
Training real-world neural network models to achieve high performance and generalizability typically requires a substantial amount of labeled data, spanning a broad range of variation. This data-labeling process can be both labor and cost intensive. To achieve desirable predictive performance, a trained model is typically applied into a domain where the data distribution is similar to the training dataset. However, for many agricultural machine learning problems, training datasets are collected at a specific location, during a specific period in time of the growing season. Since agricultural systems exhibit substantial variability in terms of crop type, cultivar, management, seasonal growth dynamics, lighting condition, sensor type, etc, a model trained from one dataset often does not generalize well across domains. To enable more data efficient and generalizable neural network models in agriculture, we propose a method that generates photorealistic agricultural images from a synthetic 3D crop model domain into real world crop domains. The method uses a semantically constrained GAN (generative adversarial network) to preserve the fruit position and geometry. We observe that a baseline CycleGAN method generates visually realistic target domain images but does not preserve fruit position information while our method maintains fruit positions well. Image generation results in vineyard grape day and night images show the visual outputs of our network are much better compared to a baseline network. Incremental training experiments in vineyard grape detection tasks show that the images generated from our method can significantly speed the domain adaption process, increase performance for a given number of labeled images (i.e. data efficiency), and decrease labeling requirements.
HistoCartography: A Toolkit for Graph Analytics in Digital Pathology
Jul 21, 2021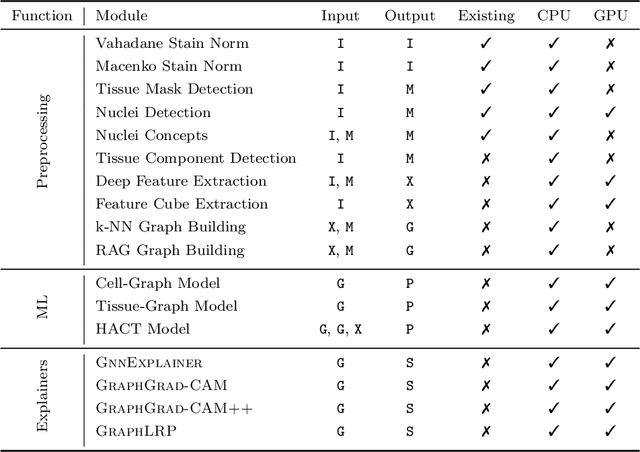
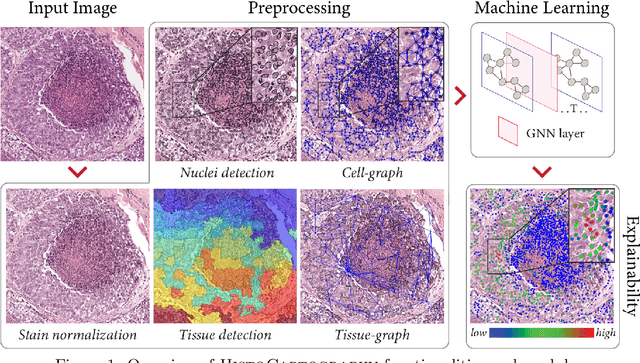
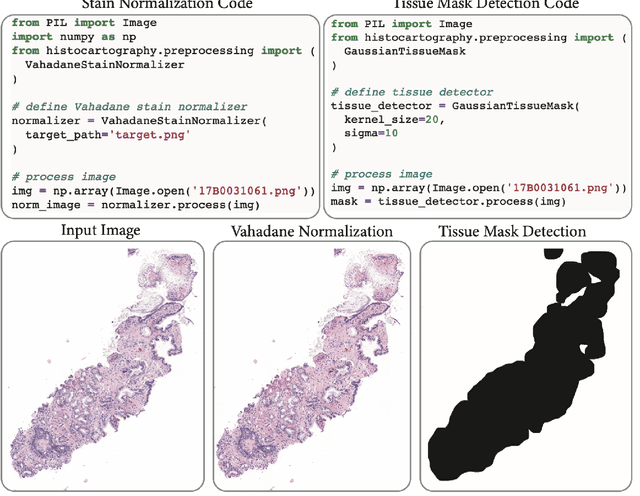
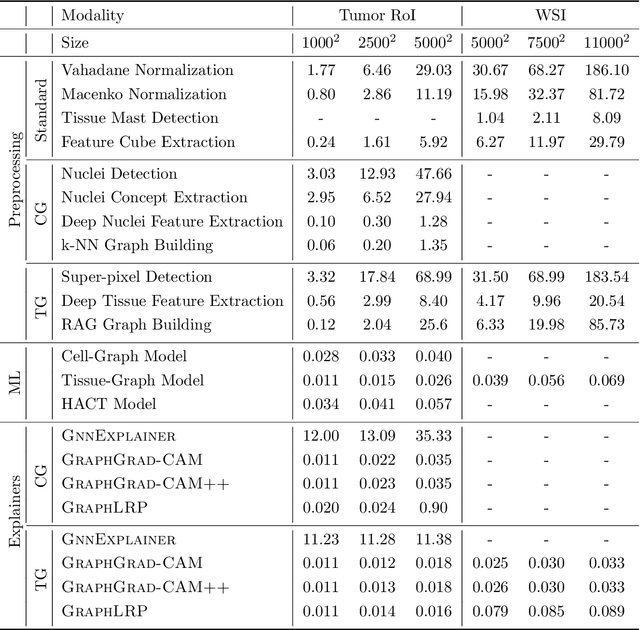
Advances in entity-graph based analysis of histopathology images have brought in a new paradigm to describe tissue composition, and learn the tissue structure-to-function relationship. Entity-graphs offer flexible and scalable representations to characterize tissue organization, while allowing the incorporation of prior pathological knowledge to further support model interpretability and explainability. However, entity-graph analysis requires prerequisites for image-to-graph translation and knowledge of state-of-the-art machine learning algorithms applied to graph-structured data, which can potentially hinder their adoption. In this work, we aim to alleviate these issues by developing HistoCartography, a standardized python API with necessary preprocessing, machine learning and explainability tools to facilitate graph-analytics in computational pathology. Further, we have benchmarked the computational time and performance on multiple datasets across different imaging types and histopathology tasks to highlight the applicability of the API for building computational pathology workflows.
ParK: Sound and Efficient Kernel Ridge Regression by Feature Space Partitions
Jun 23, 2021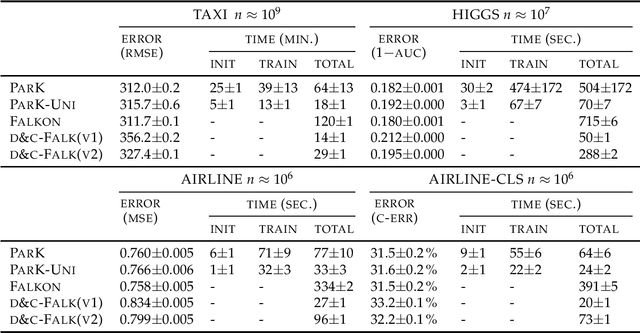
We introduce ParK, a new large-scale solver for kernel ridge regression. Our approach combines partitioning with random projections and iterative optimization to reduce space and time complexity while provably maintaining the same statistical accuracy. In particular, constructing suitable partitions directly in the feature space rather than in the input space, we promote orthogonality between the local estimators, thus ensuring that key quantities such as local effective dimension and bias remain under control. We characterize the statistical-computational tradeoff of our model, and demonstrate the effectiveness of our method by numerical experiments on large-scale datasets.
Sentinel-1 and Sentinel-2 Spatio-Temporal Data Fusion for Clouds Removal
Jun 23, 2021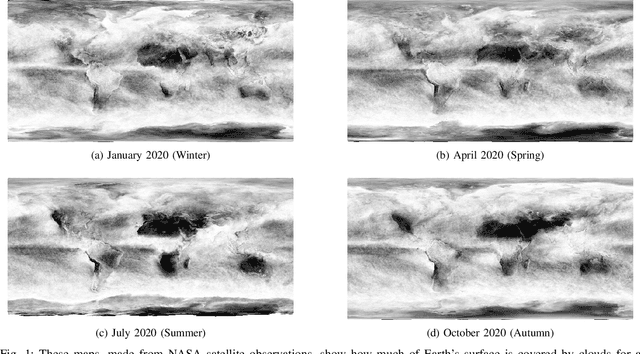
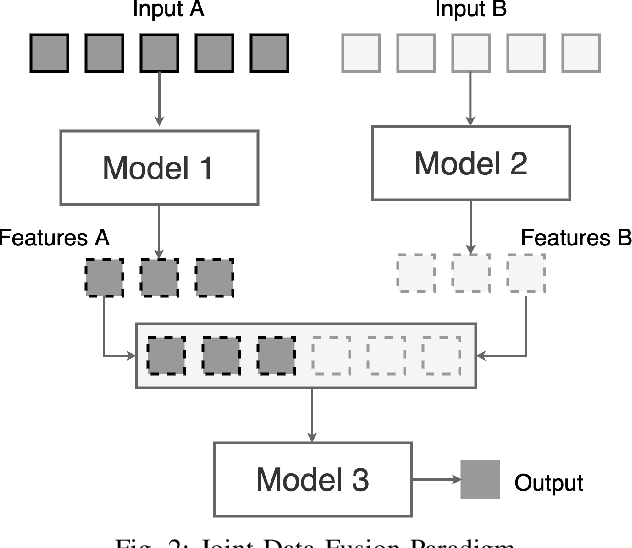
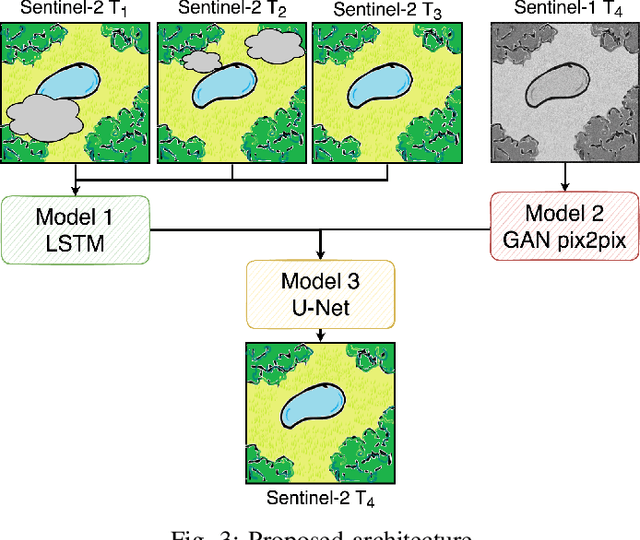
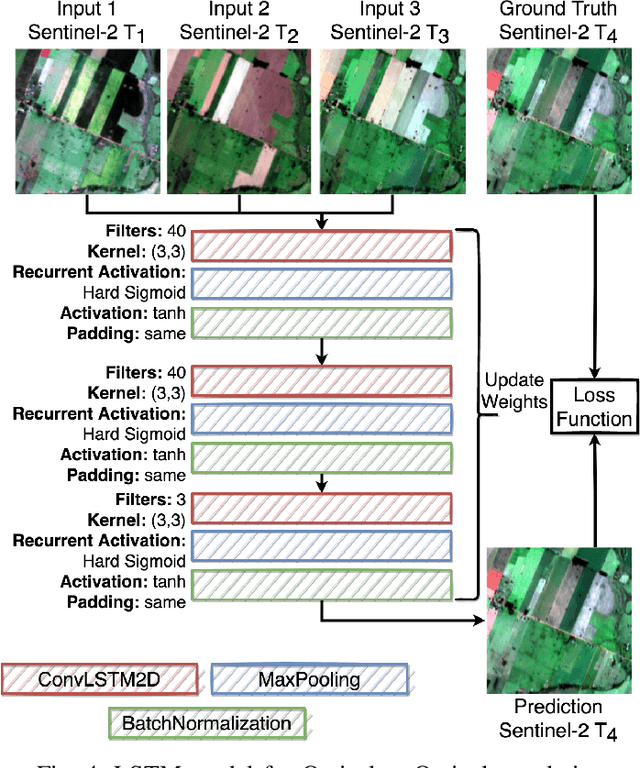
The abundance of clouds, located both spatially and temporally, often makes remote sensing applications with optical images difficult or even impossible. In this manuscript, a novel method for clouds-corrupted optical image restoration has been presented and developed, based on a joint data fusion paradigm, where three deep neural networks have been combined in order to fuse spatio-temporal features extracted from Sentinel-1 and Sentinel-2 time-series of data. It is worth highlighting that both the code and the dataset have been implemented from scratch and made available to interested research for further analysis and investigation.
Comparison of Czech Transformers on Text Classification Tasks
Jul 21, 2021
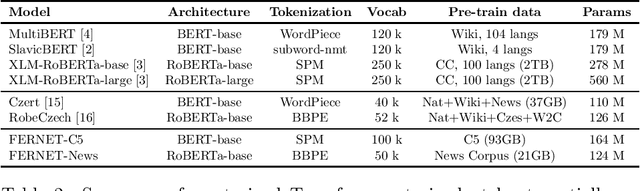
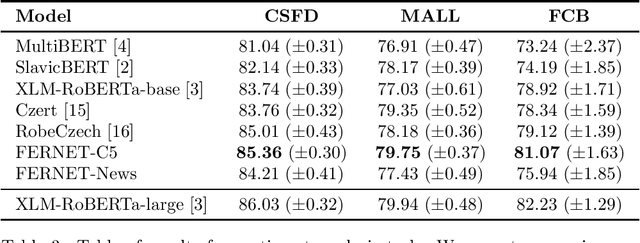
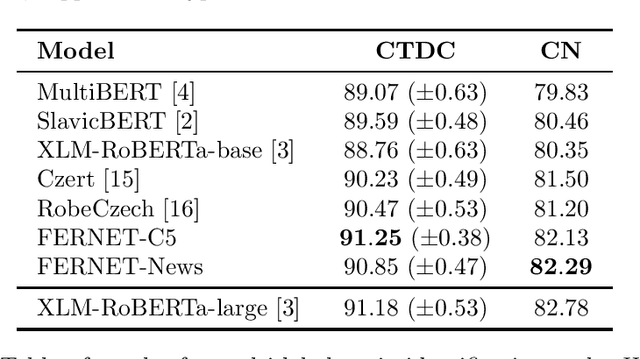
In this paper, we present our progress in pre-training monolingual Transformers for Czech and contribute to the research community by releasing our models for public. The need for such models emerged from our effort to employ Transformers in our language-specific tasks, but we found the performance of the published multilingual models to be very limited. Since the multilingual models are usually pre-trained from 100+ languages, most of low-resourced languages (including Czech) are under-represented in these models. At the same time, there is a huge amount of monolingual training data available in web archives like Common Crawl. We have pre-trained and publicly released two monolingual Czech Transformers and compared them with relevant public models, trained (at least partially) for Czech. The paper presents the Transformers pre-training procedure as well as a comparison of pre-trained models on text classification task from various domains.
Covariance-Free Sparse Bayesian Learning
May 21, 2021
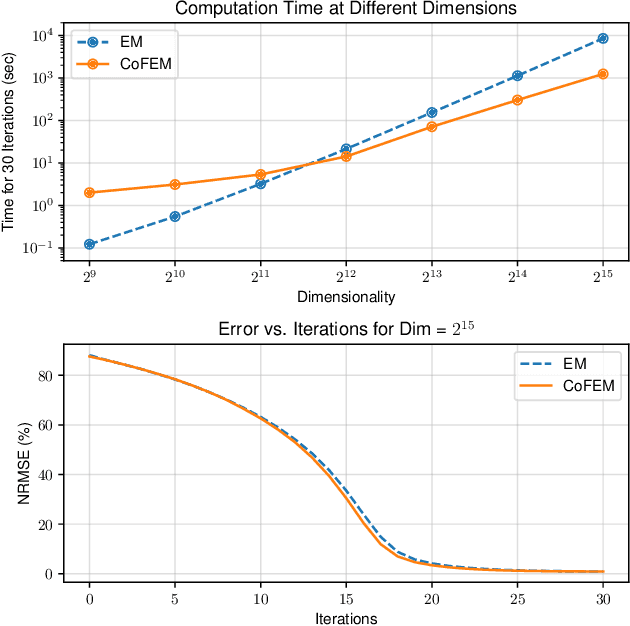
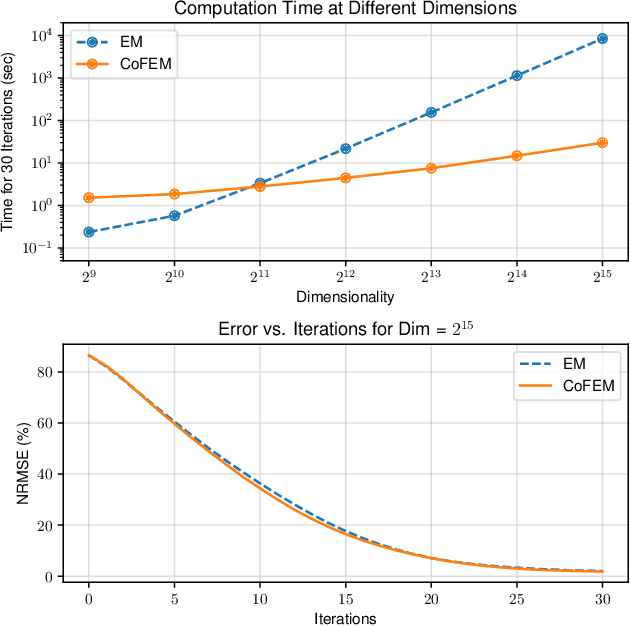
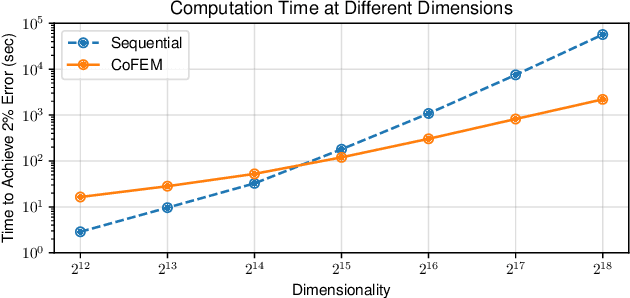
Sparse Bayesian learning (SBL) is a powerful framework for tackling the sparse coding problem while also providing uncertainty quantification. However, the most popular inference algorithms for SBL become too expensive for high-dimensional problems due to the need to maintain a large covariance matrix. To resolve this issue, we introduce a new SBL inference algorithm that avoids explicit computation of the covariance matrix, thereby saving significant time and space. Instead of performing costly matrix inversions, our covariance-free method solves multiple linear systems to obtain provably unbiased estimates of the posterior statistics needed by SBL. These systems can be solved in parallel, enabling further acceleration of the algorithm via graphics processing units. In practice, our method can be up to thousands of times faster than existing baselines, reducing hours of computation time to seconds. We showcase how our new algorithm enables SBL to tractably tackle high-dimensional signal recovery problems, such as deconvolution of calcium imaging data and multi-contrast reconstruction of magnetic resonance images. Finally, we open-source a toolbox containing all of our implementations to drive future research in SBL.
RSKNet-MTSP: Effective and Portable Deep Architecture for Speaker Verification
Aug 30, 2021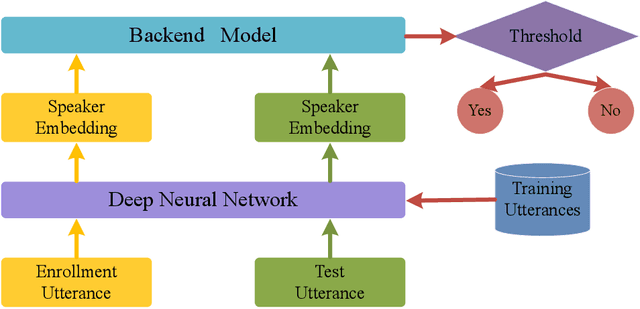
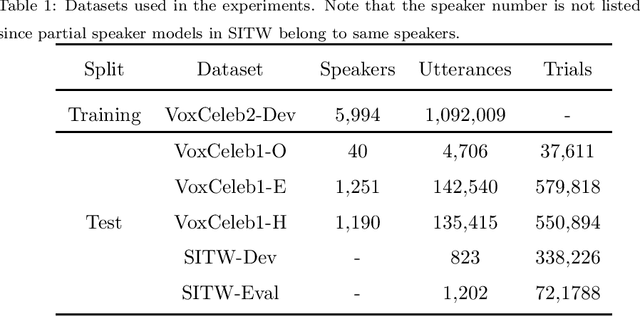
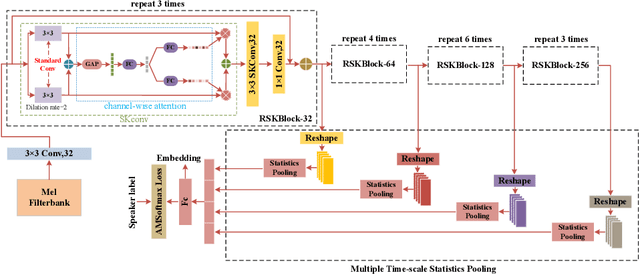

The convolutional neural network (CNN) based approaches have shown great success for speaker verification (SV) tasks, where modeling long temporal context and reducing information loss of speaker characteristics are two important challenges significantly affecting the verification performance. Previous works have introduced dilated convolution and multi-scale aggregation methods to address above challenges. However, such methods are also hard to make full use of some valuable information, which make it difficult to substantially improve the verification performance. To address above issues, we construct a novel CNN-based architecture for SV, called RSKNet-MTSP, where a residual selective kernel block (RSKBlock) and a multiple time-scale statistics pooling (MTSP) module are first proposed. The RSKNet-MTSP can capture both long temporal context and neighbouring information, and gather more speaker-discriminative information from multi-scale features. In order to design a portable model for real applications with limited resources, we then present a lightweight version of RSKNet-MTSP, namely RSKNet-MTSP-L, which employs a combination technique associating the depthwise separable convolutions with low-rank factorization of weight matrices. Extensive experiments are conducted on two public SV datasets, VoxCeleb and Speaker in the Wild (SITW). The results demonstrate that 1) RSKNet-MTSP outperforms the state-of-the-art deep embedding architectures by at least 9%-26% in all test sets. 2) RSKNet-MTSP-L achieves competitive performance compared with baseline models with 17%-39% less network parameters. The ablation experiments further illustrate that our proposed approaches can achieve substantial improvement over prior methods.
Scalable Coverage Path Planning of Multi-Robot Teams for Monitoring Non-Convex Areas
Mar 26, 2021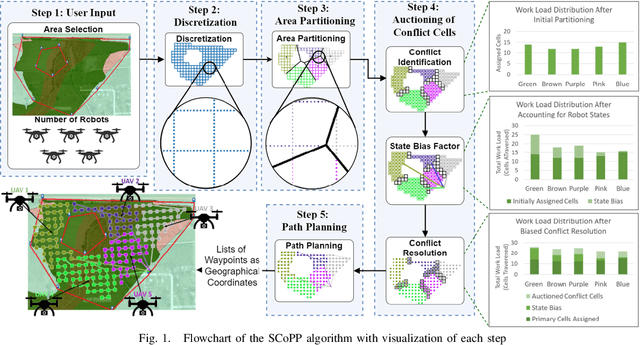
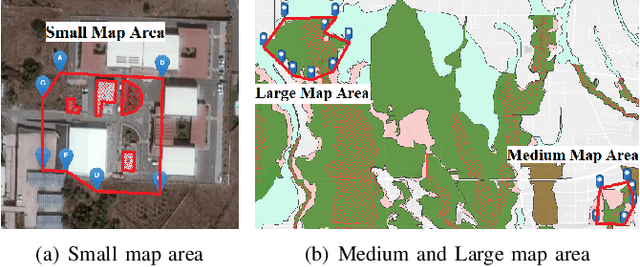
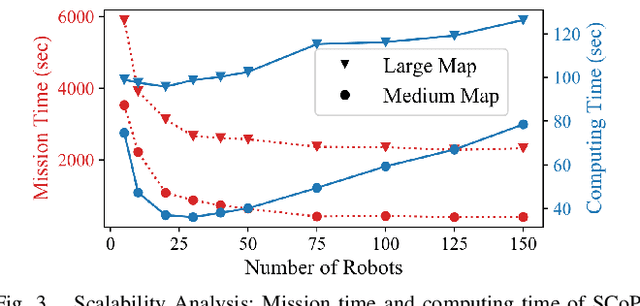
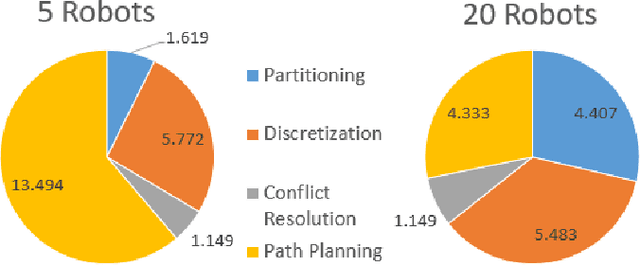
This paper presents a novel multi-robot coverage path planning (CPP) algorithm - aka SCoPP - that provides a time-efficient solution, with workload balanced plans for each robot in a multi-robot system, based on their initial states. This algorithm accounts for discontinuities (e.g., no-fly zones) in a specified area of interest, and provides an optimized ordered list of way-points per robot using a discrete, computationally efficient, nearest neighbor path planning algorithm. This algorithm involves five main stages, which include the transformation of the user's input as a set of vertices in geographical coordinates, discretization, load-balanced partitioning, auctioning of conflict cells in a discretized space, and a path planning procedure. To evaluate the effectiveness of the primary algorithm, a multi-unmanned aerial vehicle (UAV) post-flood assessment application is considered, and the performance of the algorithm is tested on three test maps of varying sizes. Additionally, our method is compared with a state-of-the-art method created by Guasella et al. Further analyses on scalability and computational time of SCoPP are conducted. The results show that SCoPP is superior in terms of mission completion time; its computing time is found to be under 2 mins for a large map covered by a 150-robot team, thereby demonstrating its computationally scalability.