 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
High-Dimensional Robust Mean Estimation in Nearly-Linear Time
Nov 23, 2018
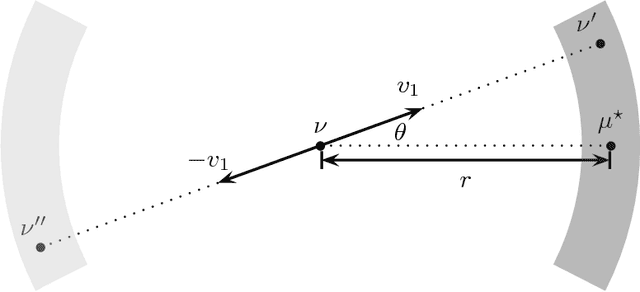
We study the fundamental problem of high-dimensional mean estimation in a robust model where a constant fraction of the samples are adversarially corrupted. Recent work gave the first polynomial time algorithms for this problem with dimension-independent error guarantees for several families of structured distributions. In this work, we give the first nearly-linear time algorithms for high-dimensional robust mean estimation. Specifically, we focus on distributions with (i) known covariance and sub-gaussian tails, and (ii) unknown bounded covariance. Given $N$ samples on $\mathbb{R}^d$, an $\epsilon$-fraction of which may be arbitrarily corrupted, our algorithms run in time $\tilde{O}(Nd) / \mathrm{poly}(\epsilon)$ and approximate the true mean within the information-theoretically optimal error, up to constant factors. Previous robust algorithms with comparable error guarantees have running times $\tilde{\Omega}(N d^2)$, for $\epsilon = \Omega(1)$. Our algorithms rely on a natural family of SDPs parameterized by our current guess $\nu$ for the unknown mean $\mu^\star$. We give a win-win analysis establishing the following: either a near-optimal solution to the primal SDP yields a good candidate for $\mu^\star$ -- independent of our current guess $\nu$ -- or the dual SDP yields a new guess $\nu'$ whose distance from $\mu^\star$ is smaller by a constant factor. We exploit the special structure of the corresponding SDPs to show that they are approximately solvable in nearly-linear time. Our approach is quite general, and we believe it can also be applied to obtain nearly-linear time algorithms for other high-dimensional robust learning problems.
A Dataset and Method for Hallux Valgus Angle Estimation Based on Deep Learing
Jul 08, 2021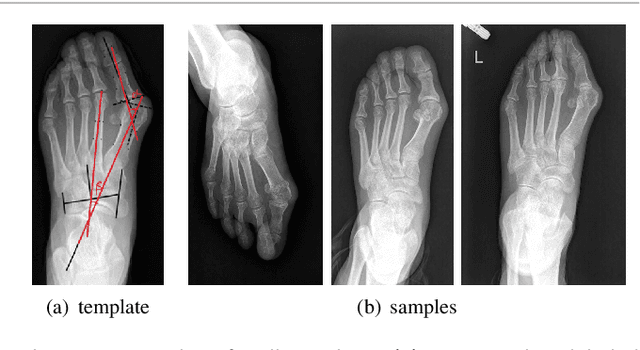

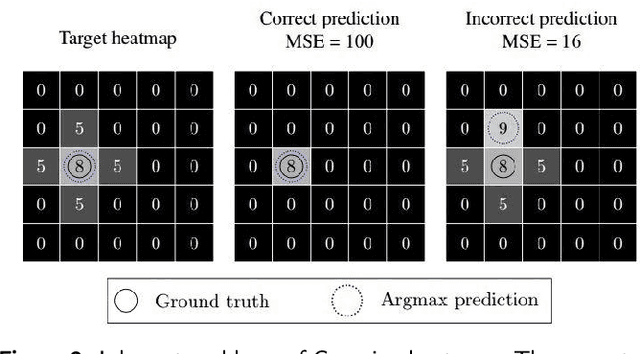
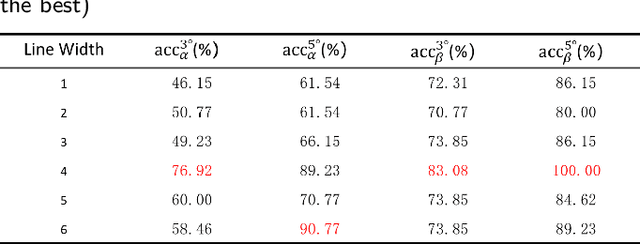
Angular measurements is essential to make a resonable treatment for Hallux valgus (HV), a common forefoot deformity. However, it still depends on manual labeling and measurement, which is time-consuming and sometimes unreliable. Automating this process is a thing of concern. However, it lack of dataset and the keypoints based method which made a great success in pose estimation is not suitable for this field.To solve the problems, we made a dataset and developed an algorithm based on deep learning and linear regression. It shows great fitting ability to the ground truth.
Sparse Travel Time Estimation from Streaming Data
Jun 27, 2018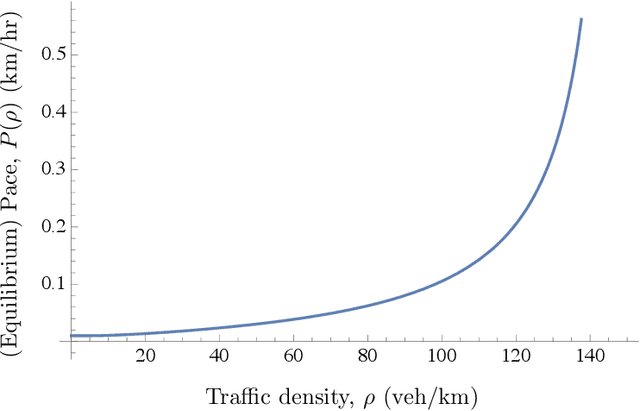

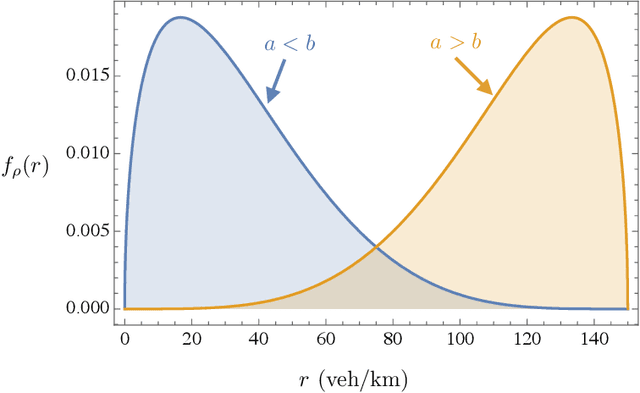

We address two shortcomings in online travel time estimation methods for congested urban traffic. The first shortcoming is related to the determination of the number of mixture modes, which can change dynamically, within day and from day to day. The second shortcoming is the wide-spread use of Gaussian probability densities as mixture components. Gaussian densities fail to capture the positive skew in travel time distributions and, consequently, large numbers of mixture components are needed for reasonable fitting accuracy when applied as mixture components. They also assign positive probabilities to negative travel times. To address these issues, this paper develops a mixture distribution with asymmetric components supported on the positive numbers. We use sparse estimation techniques to ensure parsimonious models. Specifically, we derive a novel generalization of Gamma mixture densities using Mittag-Leffler functions, which provides enhanced fitting flexibility and improved parsimony. In order to accommodate within-day variability and allow for online implementation of the proposed methodology (i.e., fast computations on streaming travel time data), we introduce a recursive algorithm which efficiently updates the fitted distribution whenever new data become available. Experimental results using real-world travel time data illustrate the efficacy of the proposed methods.
Neural Fixed-Point Acceleration for Convex Optimization
Jul 23, 2021

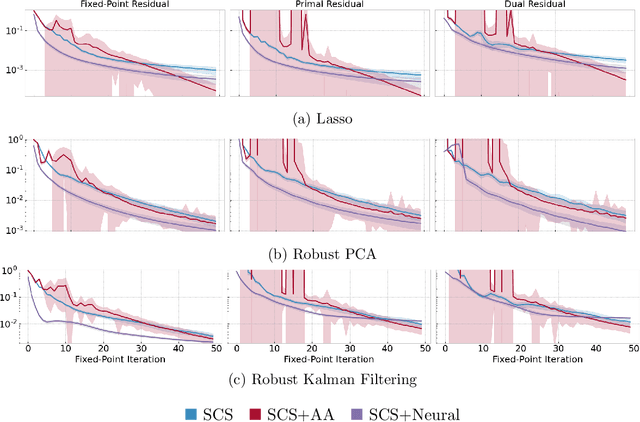

Fixed-point iterations are at the heart of numerical computing and are often a computational bottleneck in real-time applications that typically need a fast solution of moderate accuracy. We present neural fixed-point acceleration which combines ideas from meta-learning and classical acceleration methods to automatically learn to accelerate fixed-point problems that are drawn from a distribution. We apply our framework to SCS, the state-of-the-art solver for convex cone programming, and design models and loss functions to overcome the challenges of learning over unrolled optimization and acceleration instabilities. Our work brings neural acceleration into any optimization problem expressible with CVXPY. The source code behind this paper is available at https://github.com/facebookresearch/neural-scs
An Algorithm to Effect Prompt Termination of Myopic Local Search on Kauffman-s NK Landscape
Apr 26, 2021
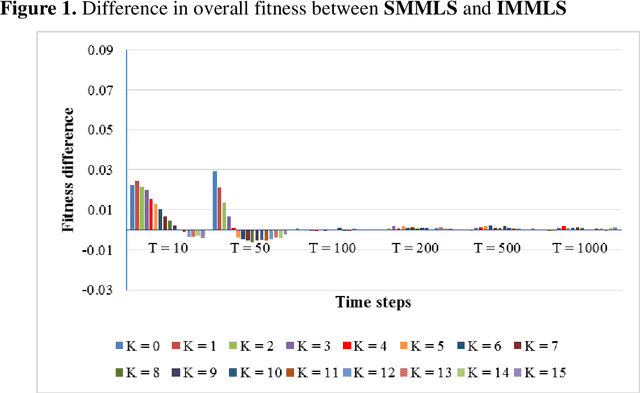
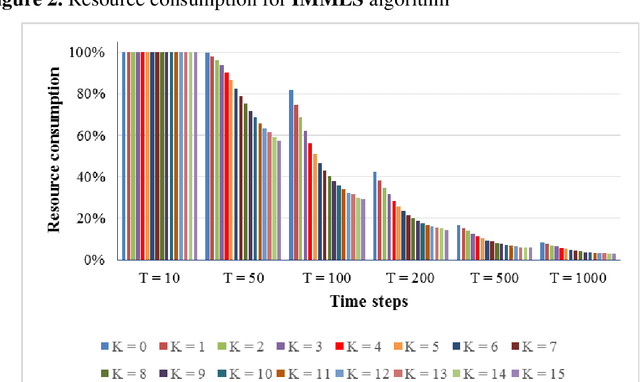
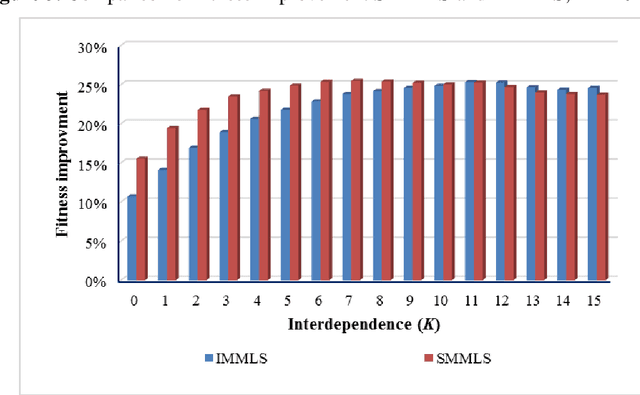
In the NK model given by Kauffman, myopic local search involves flipping one randomly-chosen bit of an N-bit decision string in every time step and accepting the new configuration if that has higher fitness. One issue is that, this algorithm consumes the full extent of computational resources allocated - given by the number of alternative configurations inspected - even though search is expected to terminate the moment there are no neighbors having higher fitness. Otherwise, the algorithm must compute the fitness of all N neighbors in every time step, consuming a high amount of resources. In order to get around this problem, I describe an algorithm that allows search to logically terminate relatively early, without having to evaluate fitness of all N neighbors at every time step. I further suggest that when the efficacy of two algorithms need to be compared head to head, imposing a common limit on the number of alternatives evaluated - metering - provides the necessary level field.
One-shot Key Information Extraction from Document with Deep Partial Graph Matching
Sep 26, 2021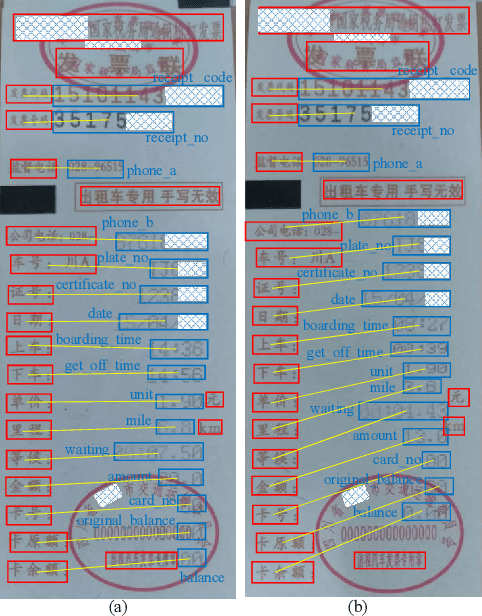
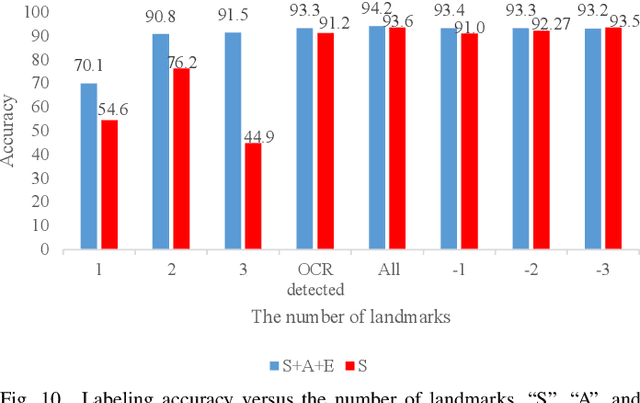
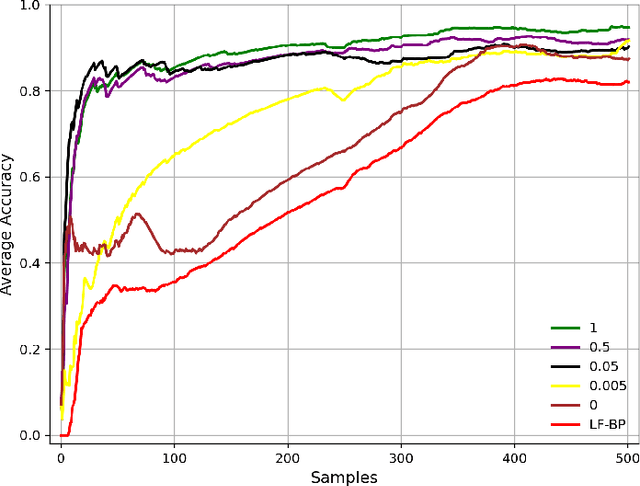
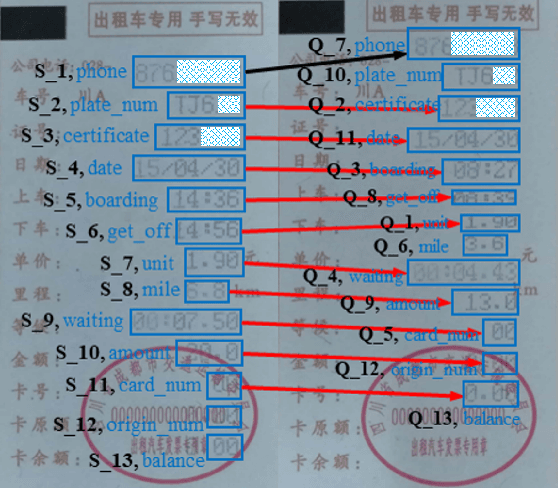
Automating the Key Information Extraction (KIE) from documents improves efficiency, productivity, and security in many industrial scenarios such as rapid indexing and archiving. Many existing supervised learning methods for the KIE task need to feed a large number of labeled samples and learn separate models for different types of documents. However, collecting and labeling a large dataset is time-consuming and is not a user-friendly requirement for many cloud platforms. To overcome these challenges, we propose a deep end-to-end trainable network for one-shot KIE using partial graph matching. Contrary to previous methods that the learning of similarity and solving are optimized separately, our method enables the learning of the two processes in an end-to-end framework. Existing one-shot KIE methods are either template or simple attention-based learning approach that struggle to handle texts that are shifted beyond their desired positions caused by printers, as illustrated in Fig.1. To solve this problem, we add one-to-(at most)-one constraint such that we will find the globally optimized solution even if some texts are drifted. Further, we design a multimodal context ensemble block to boost the performance through fusing features of spatial, textual, and aspect representations. To promote research of KIE, we collected and annotated a one-shot document KIE dataset named DKIE with diverse types of images. The DKIE dataset consists of 2.5K document images captured by mobile phones in natural scenes, and it is the largest available one-shot KIE dataset up to now. The results of experiments on DKIE show that our method achieved state-of-the-art performance compared with recent one-shot and supervised learning approaches. The dataset and proposed one-shot KIE model will be released soo
Prediction of Metacarpophalangeal joint angles and Classification of Hand configurations based on Ultrasound Imaging of the Forearm
Sep 26, 2021

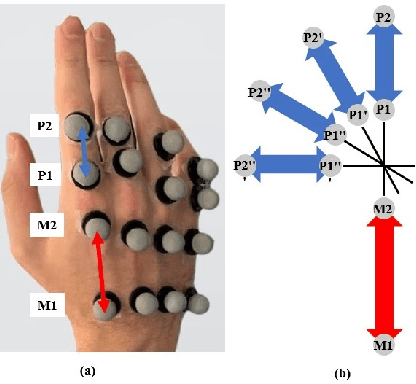
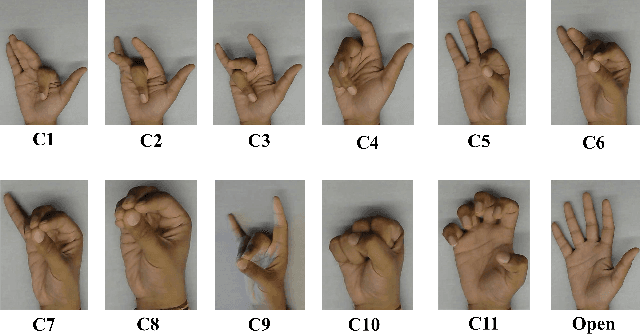
With the advancement in computing and robotics, it is necessary to develop fluent and intuitive methods for interacting with digital systems, AR/VR interfaces, and physical robotic systems. Hand movement recognition is widely used to enable this interaction. Hand configuration classification and Metacarpophalangeal (MCP) joint angle detection are important for a comprehensive reconstruction of the hand motion. Surface electromyography and other technologies have been used for the detection of hand motions. Ultrasound images of the forearm offer a way to visualize the internal physiology of the hand from a musculoskeletal perspective. Recent work has shown that these images can be classified using machine learning to predict various hand configurations. In this paper, we propose a Convolutional Neural Network (CNN) based deep learning pipeline for predicting the MCP joint angles. We supplement our results by using a Support Vector Classifier (SVC) to classify the ultrasound information into several predefined hand configurations based on activities of daily living (ADL). Ultrasound data from the forearm was obtained from 6 subjects who were instructed to move their hands according to predefined hand configurations relevant to ADLs. Motion capture data was acquired as the ground truth for hand movements at different speeds (0.5 Hz, 1 Hz, & 2 Hz) for the index, middle, ring, and pinky fingers. We were able to get promising SVC classification results on a subset of our collected data set. We demonstrated a correspondence between the predicted MCP joint angles and the actual MCP joint angles for the fingers, with an average root mean square error of 7.35 degrees. We implemented a low latency (6.25 - 9.1 Hz) pipeline for the prediction of both MCP joint angles and hand configuration estimation aimed at real-time control of digital devices, AR/VR interfaces, and physical robots.
StreaMRAK a Streaming Multi-Resolution Adaptive Kernel Algorithm
Sep 07, 2021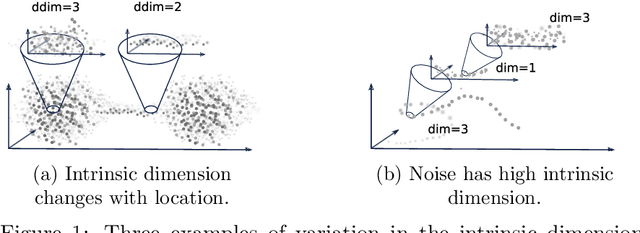
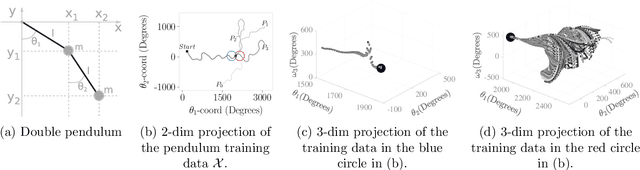
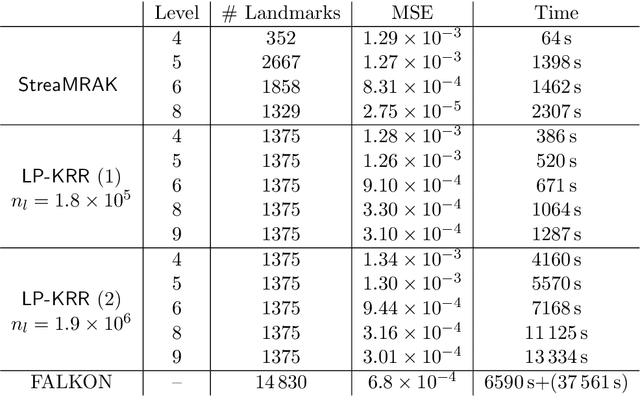
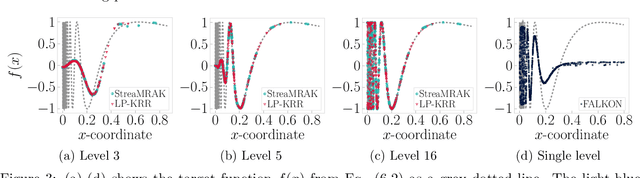
Kernel ridge regression (KRR) is a popular scheme for non-linear non-parametric learning. However, existing implementations of KRR require that all the data is stored in the main memory, which severely limits the use of KRR in contexts where data size far exceeds the memory size. Such applications are increasingly common in data mining, bioinformatics, and control. A powerful paradigm for computing on data sets that are too large for memory is the streaming model of computation, where we process one data sample at a time, discarding each sample before moving on to the next one. In this paper, we propose StreaMRAK - a streaming version of KRR. StreaMRAK improves on existing KRR schemes by dividing the problem into several levels of resolution, which allows continual refinement to the predictions. The algorithm reduces the memory requirement by continuously and efficiently integrating new samples into the training model. With a novel sub-sampling scheme, StreaMRAK reduces memory and computational complexities by creating a sketch of the original data, where the sub-sampling density is adapted to the bandwidth of the kernel and the local dimensionality of the data. We present a showcase study on two synthetic problems and the prediction of the trajectory of a double pendulum. The results show that the proposed algorithm is fast and accurate.
Effective and interpretable dispatching rules for dynamic job shops via guided empirical learning
Sep 07, 2021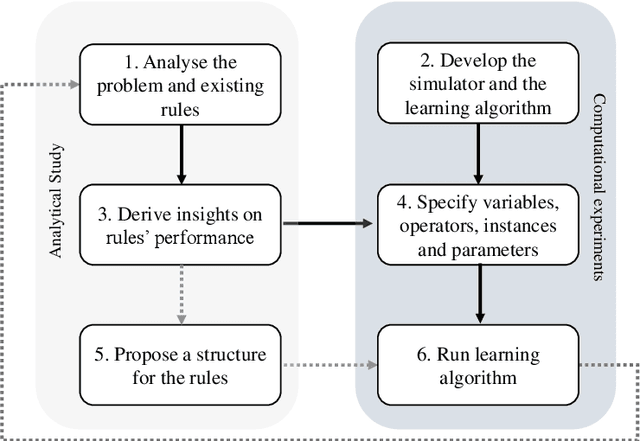
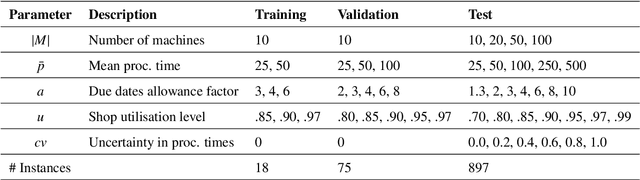
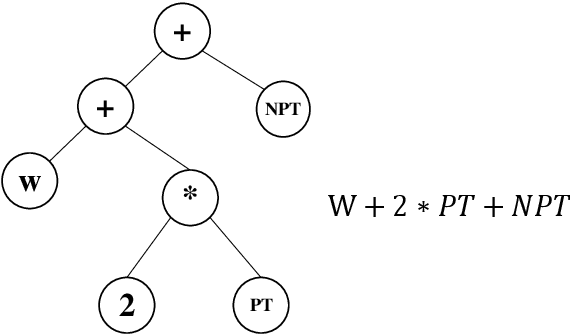
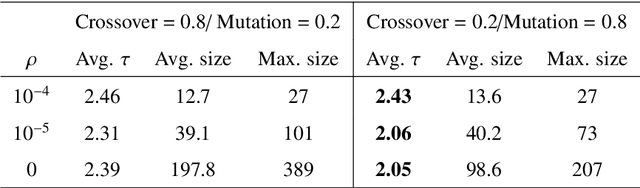
The emergence of Industry 4.0 is making production systems more flexible and also more dynamic. In these settings, schedules often need to be adapted in real-time by dispatching rules. Although substantial progress was made until the '90s, the performance of these rules is still rather limited. The machine learning literature is developing a variety of methods to improve them, but the resulting rules are difficult to interpret and do not generalise well for a wide range of settings. This paper is the first major attempt at combining machine learning with domain problem reasoning for scheduling. The idea consists of using the insights obtained with the latter to guide the empirical search of the former. Our hypothesis is that this guided empirical learning process should result in dispatching rules that are effective and interpretable and which generalise well to different instance classes. We test our approach in the classical dynamic job shop scheduling problem minimising tardiness, which is one of the most well-studied scheduling problems. Nonetheless, results suggest that our approach was able to find new state-of-the-art rules, which significantly outperform the existing literature in the vast majority of settings, from loose to tight due dates and from low utilisation conditions to congested shops. Overall, the average improvement is 19%. Moreover, the rules are compact, interpretable, and generalise well to extreme, unseen scenarios.
The UEA multivariate time series classification archive, 2018
Oct 31, 2018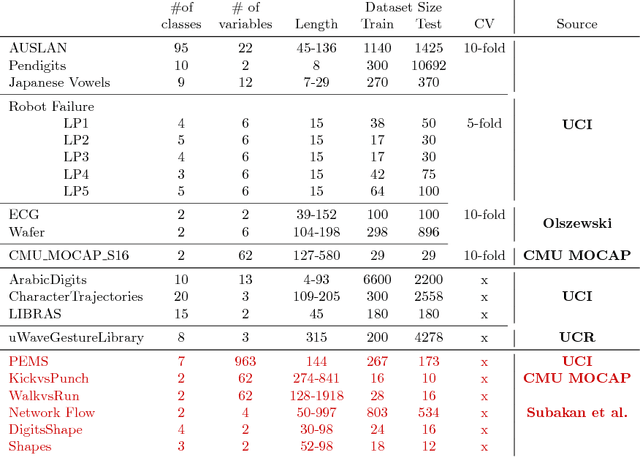
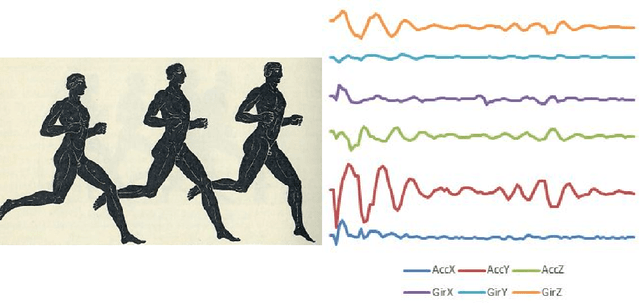
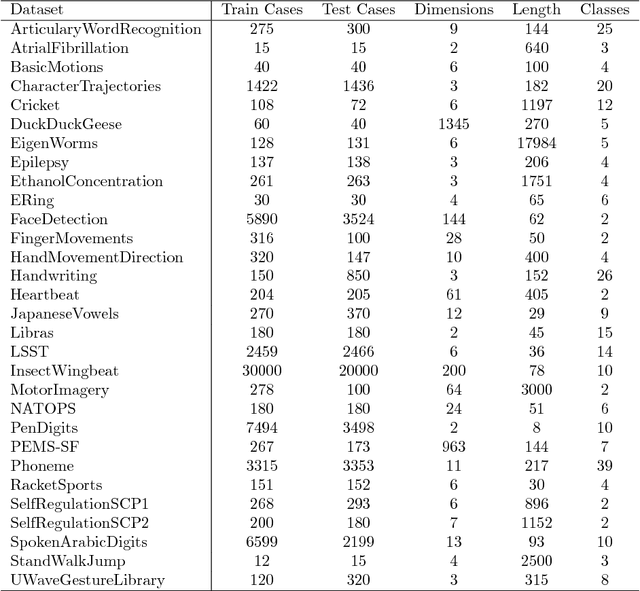
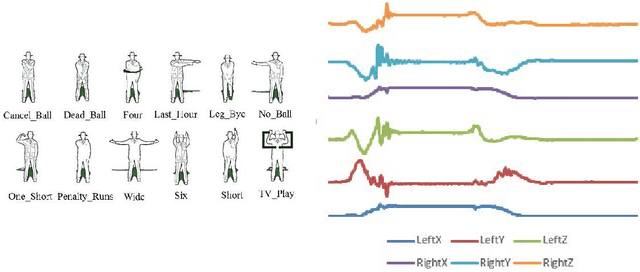
In 2002, the UCR time series classification archive was first released with sixteen datasets. It gradually expanded, until 2015 when it increased in size from 45 datasets to 85 datasets. In October 2018 more datasets were added, bringing the total to 128. The new archive contains a wide range of problems, including variable length series, but it still only contains univariate time series classification problems. One of the motivations for introducing the archive was to encourage researchers to perform a more rigorous evaluation of newly proposed time series classification (TSC) algorithms. It has worked: most recent research into TSC uses all 85 datasets to evaluate algorithmic advances. Research into multivariate time series classification, where more than one series are associated with each class label, is in a position where univariate TSC research was a decade ago. Algorithms are evaluated using very few datasets and claims of improvement are not based on statistical comparisons. We aim to address this problem by forming the first iteration of the MTSC archive, to be hosted at the website www.timeseriesclassification.com. Like the univariate archive, this formulation was a collaborative effort between researchers at the University of East Anglia (UEA) and the University of California, Riverside (UCR). The 2018 vintage consists of 30 datasets with a wide range of cases, dimensions and series lengths. For this first iteration of the archive we format all data to be of equal length, include no series with missing data and provide train/test splits.