 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Prior for Computed Tomography Reconstruction
Feb 16, 2026We present a comprehensive overview of the Deep Image Prior (DIP) framework and its applications to image reconstruction in computed tomography. Unlike conventional deep learning methods that rely on large, supervised datasets, the DIP exploits the implicit bias of convolutional neural networks and operates in a fully unsupervised setting, requiring only a single measurement, even in the presence of noise. We describe the standard DIP formulation, outline key algorithmic design choices, and review several strategies to mitigate overfitting, including early stopping, explicit regularisation, and self-guided methods that adapt the network input. In addition, we examine computational improvements such as warm-start and stochastic optimisation methods to reduce the reconstruction time. The discussed methods are tested on real $μ$CT measurements, which allows examination of trade-offs among the different modifications and extensions.
CMAD: Cooperative Multi-Agent Diffusion via Stochastic Optimal Control
Feb 11, 2026Continuous-time generative models have achieved remarkable success in image restoration and synthesis. However, controlling the composition of multiple pre-trained models remains an open challenge. Current approaches largely treat composition as an algebraic composition of probability densities, such as via products or mixtures of experts. This perspective assumes the target distribution is known explicitly, which is almost never the case. In this work, we propose a different paradigm that formulates compositional generation as a cooperative Stochastic Optimal Control problem. Rather than combining probability densities, we treat pre-trained diffusion models as interacting agents whose diffusion trajectories are jointly steered, via optimal control, toward a shared objective defined on their aggregated output. We validate our framework on conditional MNIST generation and compare it against a naive inference-time DPS-style baseline replacing learned cooperative control with per-step gradient guidance.
Trajectory Stitching for Solving Inverse Problems with Flow-Based Models
Feb 09, 2026Flow-based generative models have emerged as powerful priors for solving inverse problems. One option is to directly optimize the initial latent code (noise), such that the flow output solves the inverse problem. However, this requires backpropagating through the entire generative trajectory, incurring high memory costs and numerical instability. We propose MS-Flow, which represents the trajectory as a sequence of intermediate latent states rather than a single initial code. By enforcing the flow dynamics locally and coupling segments through trajectory-matching penalties, MS-Flow alternates between updating intermediate latent states and enforcing consistency with observed data. This reduces memory consumption while improving reconstruction quality. We demonstrate the effectiveness of MS-Flow over existing methods on image recovery and inverse problems, including inpainting, super-resolution, and computed tomography.
Learning Binary Sampling Patterns for Single-Pixel Imaging using Bilevel Optimisation
Aug 26, 2025Single-Pixel Imaging enables reconstructing objects using a single detector through sequential illuminations with structured light patterns. We propose a bilevel optimisation method for learning task-specific, binary illumination patterns, optimised for applications like single-pixel fluorescence microscopy. We address the non-differentiable nature of binary pattern optimisation using the Straight-Through Estimator and leveraging a Total Deep Variation regulariser in the bilevel formulation. We demonstrate our method on the CytoImageNet microscopy dataset and show that learned patterns achieve superior reconstruction performance compared to baseline methods, especially in highly undersampled regimes.
Plug-and-Play Half-Quadratic Splitting for Ptychography
Dec 03, 2024



Ptychography is a coherent diffraction imaging method that uses phase retrieval techniques to reconstruct complex-valued images. It achieves this by sequentially illuminating overlapping regions of a sample with a coherent beam and recording the diffraction pattern. Although this addresses traditional imaging system challenges, it is computationally intensive and highly sensitive to noise, especially with reduced illumination overlap. Data-driven regularisation techniques have been applied in phase retrieval to improve reconstruction quality. In particular, plug-and-play (PnP) offers flexibility by integrating data-driven denoisers as implicit priors. In this work, we propose a half-quadratic splitting framework for using PnP and other data-driven priors for ptychography. We evaluate our method both on natural images and real test objects to validate its effectiveness for ptychographic image reconstruction.
Why do we regularise in every iteration for imaging inverse problems?
Nov 01, 2024



Regularisation is commonly used in iterative methods for solving imaging inverse problems. Many algorithms involve the evaluation of the proximal operator of the regularisation term in every iteration, leading to a significant computational overhead since such evaluation can be costly. In this context, the ProxSkip algorithm, recently proposed for federated learning purposes, emerges as an solution. It randomly skips regularisation steps, reducing the computational time of an iterative algorithm without affecting its convergence. Here we explore for the first time the efficacy of ProxSkip to a variety of imaging inverse problems and we also propose a novel PDHGSkip version. Extensive numerical results highlight the potential of these methods to accelerate computations while maintaining high-quality reconstructions.
Stochastic Optimisation Framework using the Core Imaging Library and Synergistic Image Reconstruction Framework for PET Reconstruction
Jun 21, 2024We introduce a stochastic framework into the open--source Core Imaging Library (CIL) which enables easy development of stochastic algorithms. Five such algorithms from the literature are developed, Stochastic Gradient Descent, Stochastic Average Gradient (-Am\'elior\'e), (Loopless) Stochastic Variance Reduced Gradient. We showcase the functionality of the framework with a comparative study against a deterministic algorithm on a simulated 2D PET dataset, with the use of the open-source Synergistic Image Reconstruction Framework. We observe that stochastic optimisation methods can converge in fewer passes of the data than a standard deterministic algorithm.
A Guide to Stochastic Optimisation for Large-Scale Inverse Problems
Jun 10, 2024



Stochastic optimisation algorithms are the de facto standard for machine learning with large amounts of data. Handling only a subset of available data in each optimisation step dramatically reduces the per-iteration computational costs, while still ensuring significant progress towards the solution. Driven by the need to solve large-scale optimisation problems as efficiently as possible, the last decade has witnessed an explosion of research in this area. Leveraging the parallels between machine learning and inverse problems has allowed harnessing the power of this research wave for solving inverse problems. In this survey, we provide a comprehensive account of the state-of-the-art in stochastic optimisation from the viewpoint of inverse problems. We present algorithms with diverse modalities of problem randomisation and discuss the roles of variance reduction, acceleration, higher-order methods, and other algorithmic modifications, and compare theoretical results with practical behaviour. We focus on the potential and the challenges for stochastic optimisation that are unique to inverse imaging problems and are not commonly encountered in machine learning. We conclude the survey with illustrative examples from imaging problems to examine the advantages and disadvantages that this new generation of algorithms bring to the field of inverse problems.
StreaMRAK a Streaming Multi-Resolution Adaptive Kernel Algorithm
Sep 07, 2021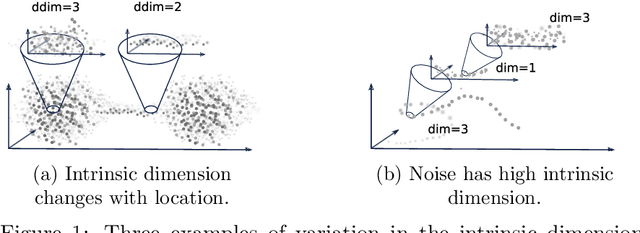
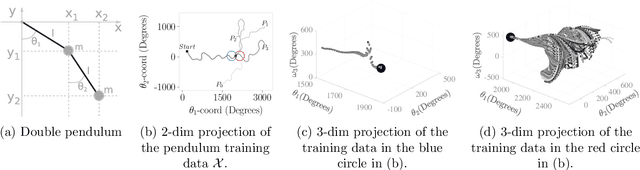
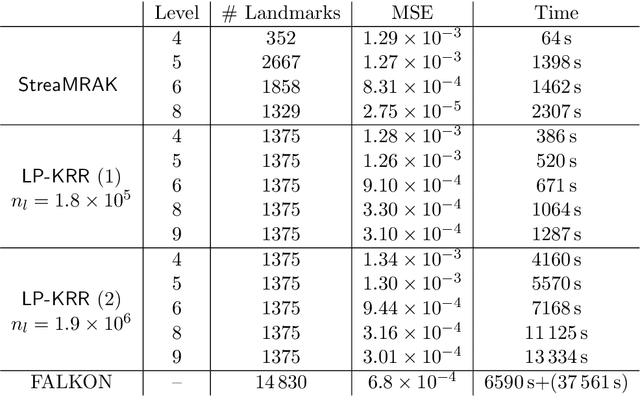
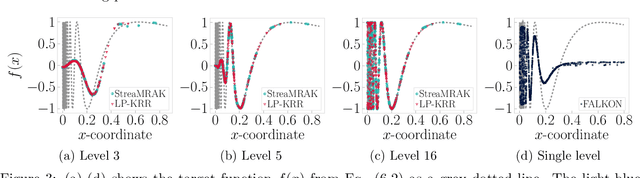
Kernel ridge regression (KRR) is a popular scheme for non-linear non-parametric learning. However, existing implementations of KRR require that all the data is stored in the main memory, which severely limits the use of KRR in contexts where data size far exceeds the memory size. Such applications are increasingly common in data mining, bioinformatics, and control. A powerful paradigm for computing on data sets that are too large for memory is the streaming model of computation, where we process one data sample at a time, discarding each sample before moving on to the next one. In this paper, we propose StreaMRAK - a streaming version of KRR. StreaMRAK improves on existing KRR schemes by dividing the problem into several levels of resolution, which allows continual refinement to the predictions. The algorithm reduces the memory requirement by continuously and efficiently integrating new samples into the training model. With a novel sub-sampling scheme, StreaMRAK reduces memory and computational complexities by creating a sketch of the original data, where the sub-sampling density is adapted to the bandwidth of the kernel and the local dimensionality of the data. We present a showcase study on two synthetic problems and the prediction of the trajectory of a double pendulum. The results show that the proposed algorithm is fast and accurate.
Unsupervised Knowledge-Transfer for Learned Image Reconstruction
Jul 06, 2021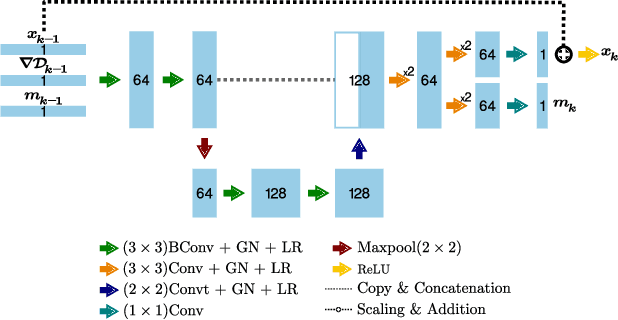
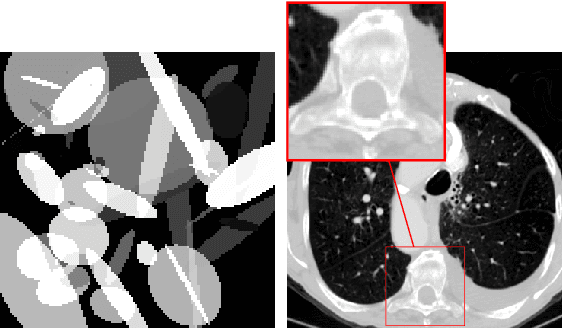
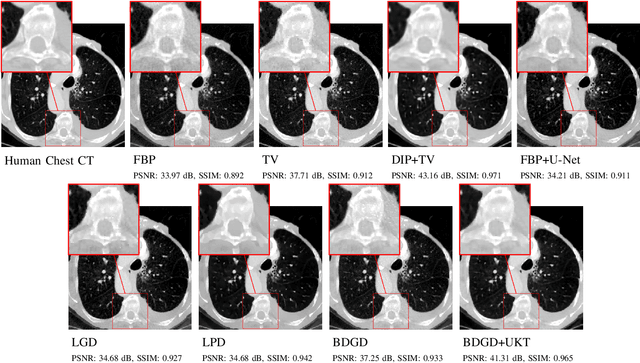
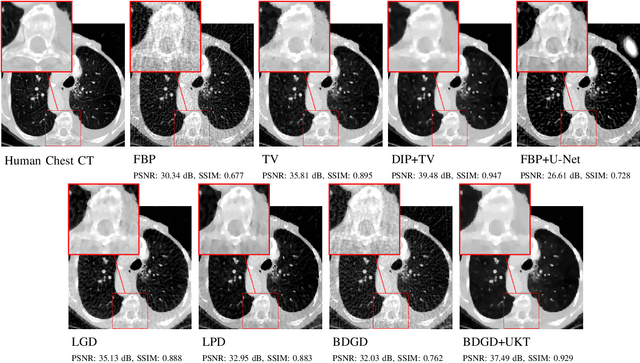
Deep learning-based image reconstruction approaches have demonstrated impressive empirical performance in many imaging modalities. These approaches generally require a large amount of high-quality training data, which is often not available. To circumvent this issue, we develop a novel unsupervised knowledge-transfer paradigm for learned iterative reconstruction within a Bayesian framework. The proposed approach learns an iterative reconstruction network in two phases. The first phase trains a reconstruction network with a set of ordered pairs comprising of ground truth images and measurement data. The second phase fine-tunes the pretrained network to the measurement data without supervision. Furthermore, the framework delivers uncertainty information over the reconstructed image. We present extensive experimental results on low-dose and sparse-view computed tomography, showing that the proposed framework significantly improves reconstruction quality not only visually, but also quantitatively in terms of PSNR and SSIM, and is competitive with several state-of-the-art supervised and unsupervised reconstruction techniques.