 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Changes in European Solidarity Before and During COVID-19: Evidence from a Large Crowd- and Expert-Annotated Twitter Dataset
Aug 02, 2021
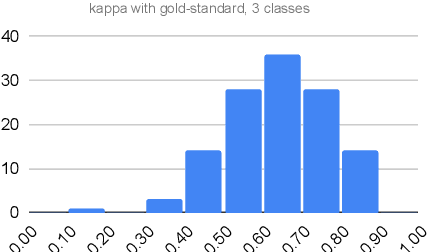

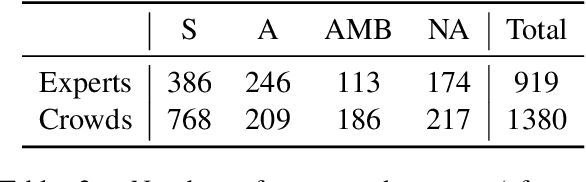

We introduce the well-established social scientific concept of social solidarity and its contestation, anti-solidarity, as a new problem setting to supervised machine learning in NLP to assess how European solidarity discourses changed before and after the COVID-19 outbreak was declared a global pandemic. To this end, we annotate 2.3k English and German tweets for (anti-)solidarity expressions, utilizing multiple human annotators and two annotation approaches (experts vs.\ crowds). We use these annotations to train a BERT model with multiple data augmentation strategies. Our augmented BERT model that combines both expert and crowd annotations outperforms the baseline BERT classifier trained with expert annotations only by over 25 points, from 58\% macro-F1 to almost 85\%. We use this high-quality model to automatically label over 270k tweets between September 2019 and December 2020. We then assess the automatically labeled data for how statements related to European (anti-)solidarity discourses developed over time and in relation to one another, before and during the COVID-19 crisis. Our results show that solidarity became increasingly salient and contested during the crisis. While the number of solidarity tweets remained on a higher level and dominated the discourse in the scrutinized time frame, anti-solidarity tweets initially spiked, then decreased to (almost) pre-COVID-19 values before rising to a stable higher level until the end of 2020.
Deep neural network Based Low-latency Speech Separation with Asymmetric analysis-Synthesis Window Pair
Jun 22, 2021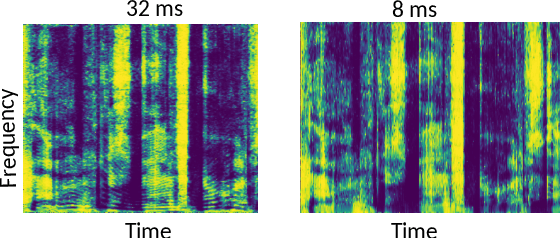
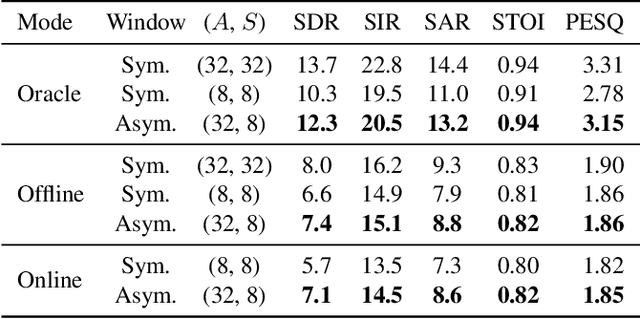
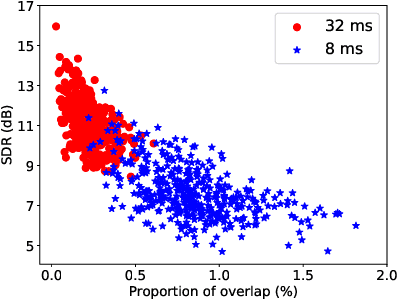
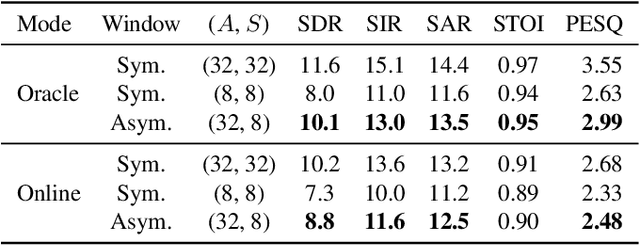
Time-frequency masking or spectrum prediction computed via short symmetric windows are commonly used in low-latency deep neural network (DNN) based source separation. In this paper, we propose the usage of an asymmetric analysis-synthesis window pair which allows for training with targets with better frequency resolution, while retaining the low-latency during inference suitable for real-time speech enhancement or assisted hearing applications. In order to assess our approach across various model types and datasets, we evaluate it with both speaker-independent deep clustering (DC) model and a speaker-dependent mask inference (MI) model. We report an improvement in separation performance of up to 1.5 dB in terms of source-to-distortion ratio (SDR) while maintaining an algorithmic latency of 8 ms.
A Deep Reinforcement Learning Approach for Fair Traffic Signal Control
Jul 21, 2021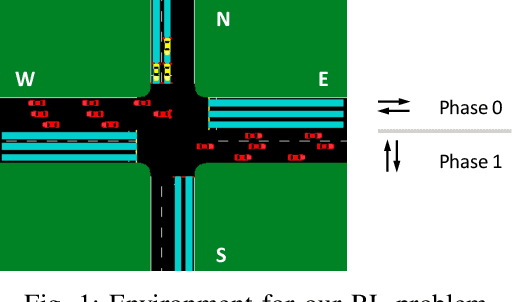
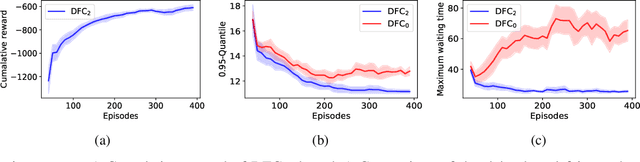
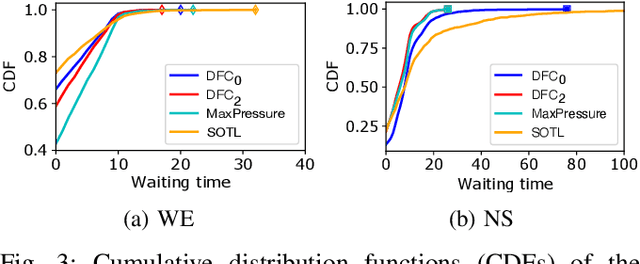
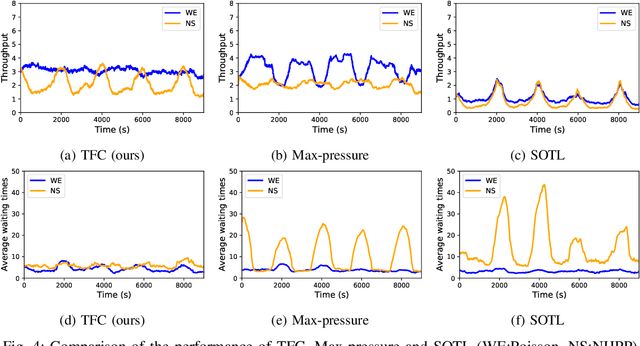
Traffic signal control is one of the most effective methods of traffic management in urban areas. In recent years, traffic control methods based on deep reinforcement learning (DRL) have gained attention due to their ability to exploit real-time traffic data, which is often poorly used by the traditional hand-crafted methods. While most recent DRL-based methods have focused on maximizing the throughput or minimizing the average travel time of the vehicles, the fairness of the traffic signal controllers has often been neglected. This is particularly important as neglecting fairness can lead to situations where some vehicles experience extreme waiting times, or where the throughput of a particular traffic flow is highly impacted by the fluctuations of another conflicting flow at the intersection. In order to address these issues, we introduce two notions of fairness: delay-based and throughput-based fairness, which correspond to the two issues mentioned above. Furthermore, we propose two DRL-based traffic signal control methods for implementing these fairness notions, that can achieve a high throughput as well. We evaluate the performance of our proposed methods using three traffic arrival distributions, and find that our methods outperform the baselines in the tested scenarios.
HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media
Oct 19, 2021

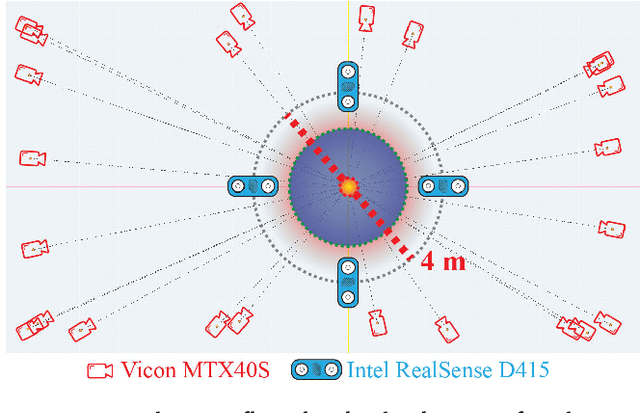
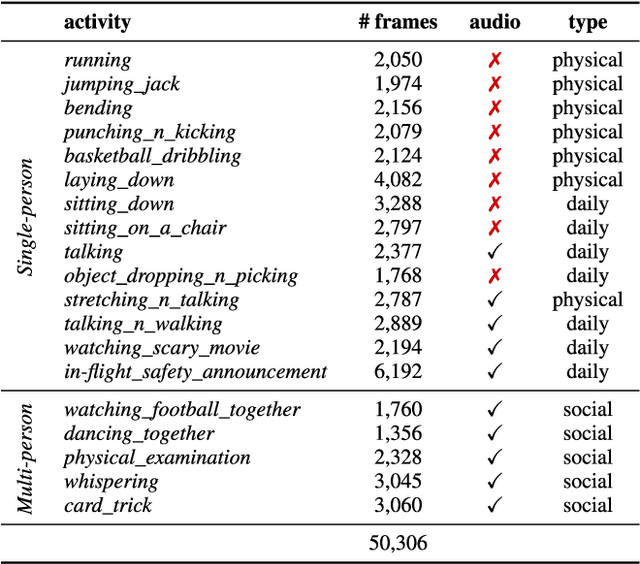
We introduce HUMAN4D, a large and multimodal 4D dataset that contains a variety of human activities simultaneously captured by a professional marker-based MoCap, a volumetric capture and an audio recording system. By capturing 2 female and $2$ male professional actors performing various full-body movements and expressions, HUMAN4D provides a diverse set of motions and poses encountered as part of single- and multi-person daily, physical and social activities (jumping, dancing, etc.), along with multi-RGBD (mRGBD), volumetric and audio data. Despite the existence of multi-view color datasets captured with the use of hardware (HW) synchronization, to the best of our knowledge, HUMAN4D is the first and only public resource that provides volumetric depth maps with high synchronization precision due to the use of intra- and inter-sensor HW-SYNC. Moreover, a spatio-temporally aligned scanned and rigged 3D character complements HUMAN4D to enable joint research on time-varying and high-quality dynamic meshes. We provide evaluation baselines by benchmarking HUMAN4D with state-of-the-art human pose estimation and 3D compression methods. For the former, we apply 2D and 3D pose estimation algorithms both on single- and multi-view data cues. For the latter, we benchmark open-source 3D codecs on volumetric data respecting online volumetric video encoding and steady bit-rates. Furthermore, qualitative and quantitative visual comparison between mesh-based volumetric data reconstructed in different qualities showcases the available options with respect to 4D representations. HUMAN4D is introduced to the computer vision and graphics research communities to enable joint research on spatio-temporally aligned pose, volumetric, mRGBD and audio data cues. The dataset and its code are available https://tofis.github.io/myurls/human4d.
Constructing Sub-scale Surrogate Model for Proppant Settling in Inclined Fractures from Simulation Data with Multi-fidelity Neural Network
Sep 25, 2021
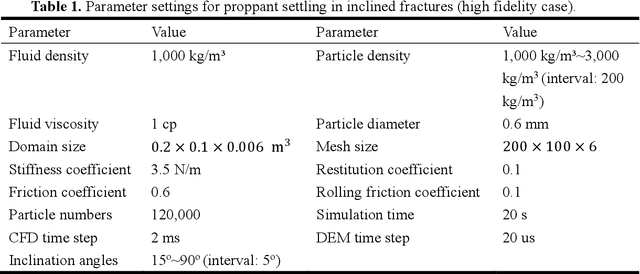
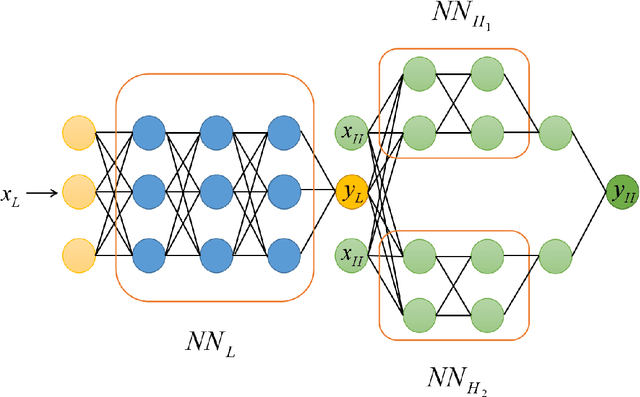
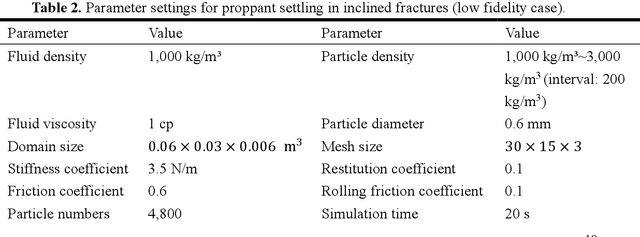
Particle settling in inclined channels is an important phenomenon that occurs during hydraulic fracturing of shale gas production. Generally, in order to accurately simulate the large-scale (field-scale) proppant transport process, constructing a fast and accurate sub-scale proppant settling model, or surrogate model, becomes a critical issue, since mapping between physical parameters and proppant settling velocity is complex. Previously, particle settling has usually been investigated via high-fidelity experiments and meso-scale numerical simulations, both of which are time-consuming. In this work, a new method is proposed and utilized, i.e., the multi-fidelity neural network (MFNN), to construct a settling surrogate model, which could utilize both high-fidelity and low-fidelity (thus, less expensive) data. The results demonstrate that constructing the settling surrogate with the MFNN can reduce the need for high-fidelity data and thus computational cost by 80%, while the accuracy lost is less than 5% compared to a high-fidelity surrogate. Moreover, the investigated particle settling surrogate is applied in macro-scale proppant transport simulation, which shows that the settling model is significant to proppant transport and yields accurate results. This opens novel pathways for rapidly predicting proppant settling velocity in reservoir applications.
Generative Zero-Shot Learning for Semantic Segmentation of 3D Point Cloud
Aug 23, 2021
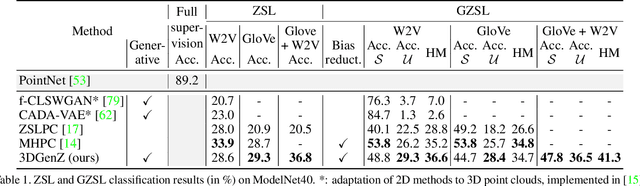
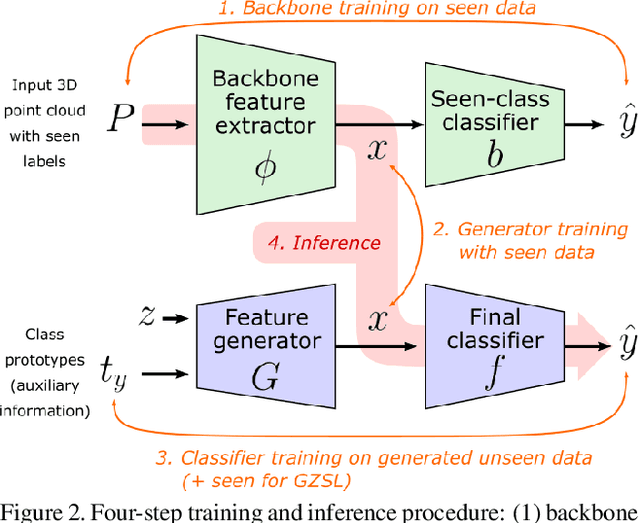
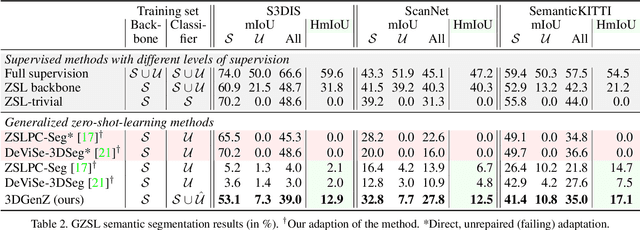
While there has been a number of studies on Zero-Shot Learning (ZSL) for 2D images, its application to 3D data is still recent and scarce, with just a few methods limited to classification. We present the first generative approach for both ZSL and Generalized ZSL (GZSL) on 3D data, that can handle both classification and, for the first time, semantic segmentation. We show that it reaches or outperforms the state of the art on ModelNet40 classification for both inductive ZSL and inductive GZSL. For semantic segmentation, we created three benchmarks for evaluating this new ZSL task, using S3DIS, ScanNet and SemanticKITTI. Our experiments show that our method outperforms strong baselines, which we additionally propose for this task.
Few-shot time series segmentation using prototype-defined infinite hidden Markov models
Feb 07, 2021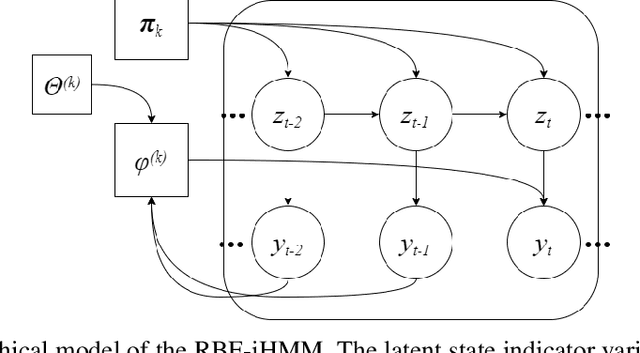

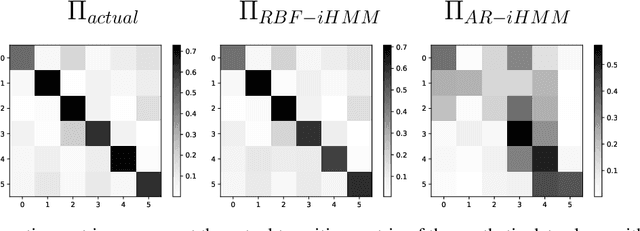

We propose a robust framework for interpretable, few-shot analysis of non-stationary sequential data based on flexible graphical models to express the structured distribution of sequential events, using prototype radial basis function (RBF) neural network emissions. A motivational link is demonstrated between prototypical neural network architectures for few-shot learning and the proposed RBF network infinite hidden Markov model (RBF-iHMM). We show that RBF networks can be efficiently specified via prototypes allowing us to express complex nonstationary patterns, while hidden Markov models are used to infer principled high-level Markov dynamics. The utility of the framework is demonstrated on biomedical signal processing applications such as automated seizure detection from EEG data where RBF networks achieve state-of-the-art performance using a fraction of the data needed to train long-short-term memory variational autoencoders.
Multi-Agent Pathfinding (MAPF) with Continuous Time
Jan 16, 2019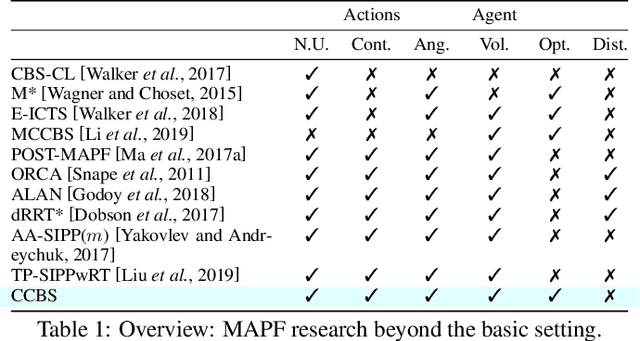
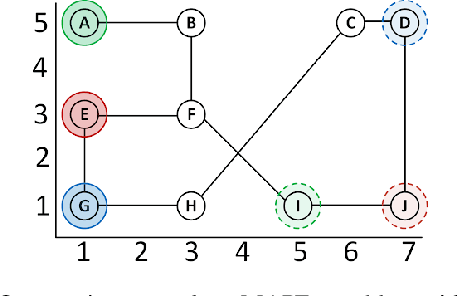
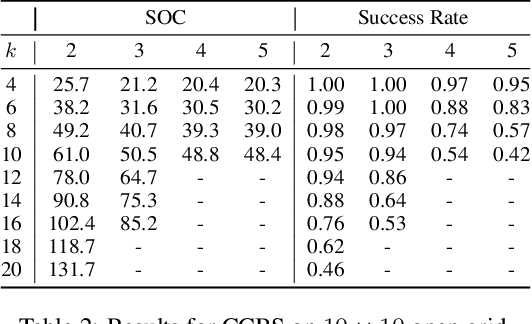
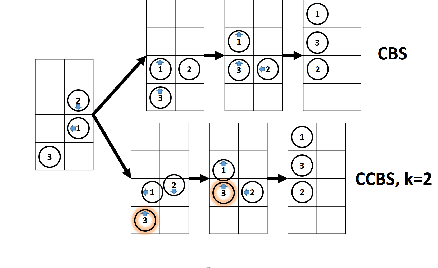
MAPF is the problem of finding paths for multiple agents such that every agent reaches its goal and the agents do not collide. Most prior work on MAPF were on grid, assumed all actions cost the same, agents do not have a volume, and considered discrete time steps. In this work we propose a MAPF algorithm that do not assume any of these assumptions, is complete, and provides provably optimal solutions. This algorithm is based on a novel combination of SIPP, a continuous time single agent planning algorithms, and CBS, a state of the art multi-agent pathfinding algorithm. We analyze this algorithm, discuss its pros and cons, and evaluate it experimentally on several standard benchmarks.
Time-Smoothed Gradients for Online Forecasting
May 21, 2019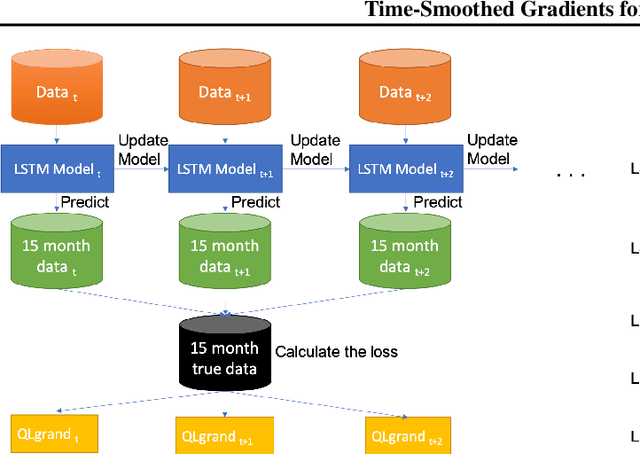
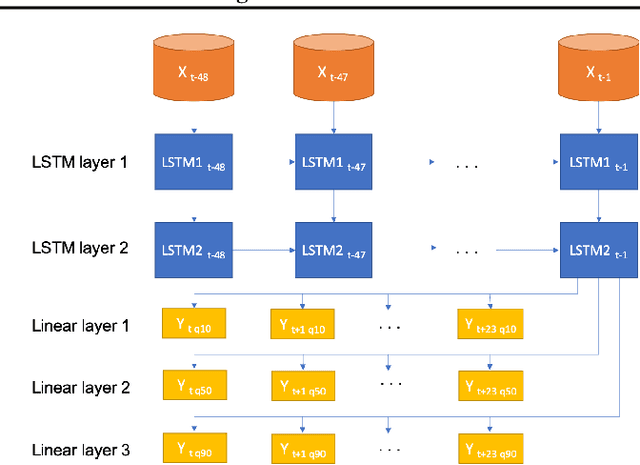
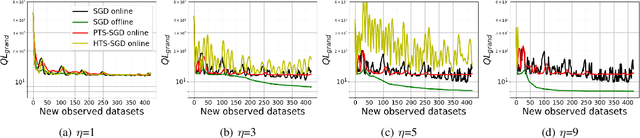
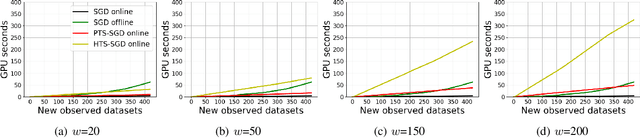
Here, we study different update rules in stochastic gradient descent (SGD) for online forecasting problems. The selection of the learning rate parameter is critical in SGD. However, it may not be feasible to tune this parameter in online learning. Therefore, it is necessary to have an update rule that is not sensitive to the selection of the learning parameter. Inspired by the local regret metric that we introduced previously, we propose to use time-smoothed gradients within SGD update. Using the public data set-- GEFCom2014, we validate that our approach yields more stable results than the other existing approaches. Furthermore, we show that such a simple approach is computationally efficient compared to the alternatives.
ABC: Attention with Bounded-memory Control
Oct 06, 2021
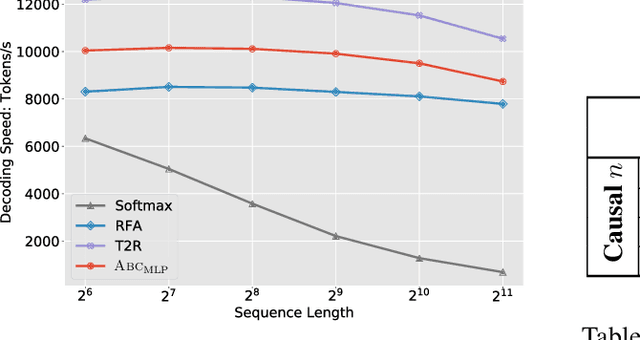
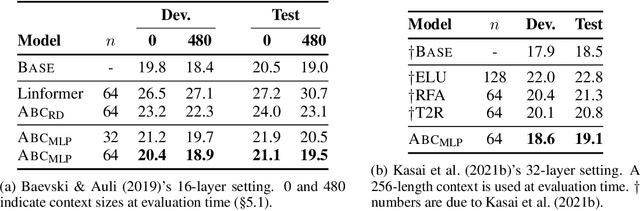
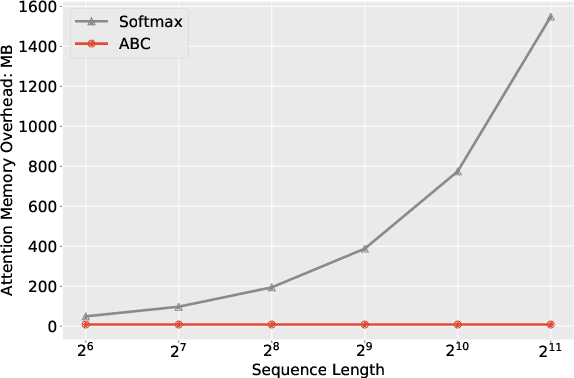
Transformer architectures have achieved state-of-the-art results on a variety of sequence modeling tasks. However, their attention mechanism comes with a quadratic complexity in sequence lengths, making the computational overhead prohibitive, especially for long sequences. Attention context can be seen as a random-access memory with each token taking a slot. Under this perspective, the memory size grows linearly with the sequence length, and so does the overhead of reading from it. One way to improve the efficiency is to bound the memory size. We show that disparate approaches can be subsumed into one abstraction, attention with bounded-memory control (ABC), and they vary in their organization of the memory. ABC reveals new, unexplored possibilities. First, it connects several efficient attention variants that would otherwise seem apart. Second, this abstraction gives new insights--an established approach (Wang et al., 2020b) previously thought to be not applicable in causal attention, actually is. Last, we present a new instance of ABC, which draws inspiration from existing ABC approaches, but replaces their heuristic memory-organizing functions with a learned, contextualized one. Our experiments on language modeling, machine translation, and masked language model finetuning show that our approach outperforms previous efficient attention models; compared to the strong transformer baselines, it significantly improves the inference time and space efficiency with no or negligible accuracy loss.