 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Correct Me if I am Wrong: Interactive Learning for Robotic Manipulation
Oct 07, 2021
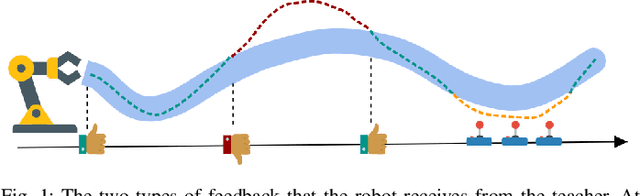
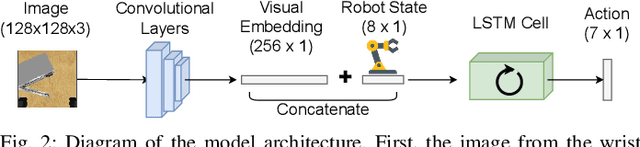

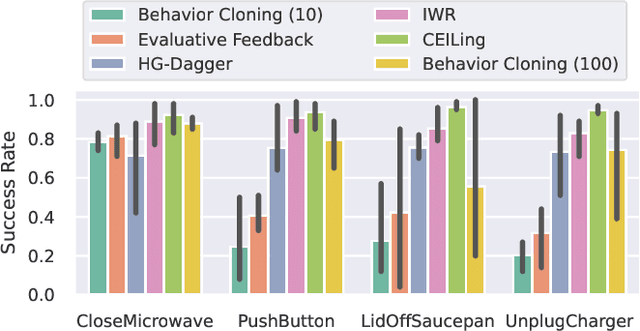
Learning to solve complex manipulation tasks from visual observations is a dominant challenge for real-world robot learning. Deep reinforcement learning algorithms have recently demonstrated impressive results, although they still require an impractical amount of time-consuming trial-and-error iterations. In this work, we consider the promising alternative paradigm of interactive learning where a human teacher provides feedback to the policy during execution, as opposed to imitation learning where a pre-collected dataset of perfect demonstrations is used. Our proposed CEILing (Corrective and Evaluative Interactive Learning) framework combines both corrective and evaluative feedback from the teacher to train a stochastic policy in an asynchronous manner, and employs a dedicated mechanism to trade off human corrections with the robot's own experience. We present results obtained with our framework in extensive simulation and real-world experiments that demonstrate that CEILing can effectively solve complex robot manipulation tasks directly from raw images in less than one hour of real-world training.
Using Machine Learning Approach for Computational Substructure in Real-Time Hybrid Simulation
Apr 04, 2020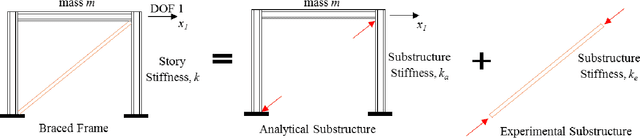

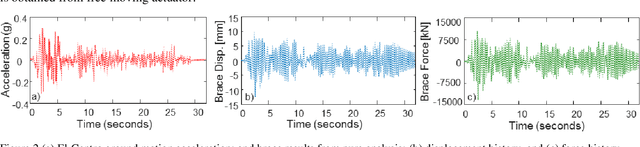
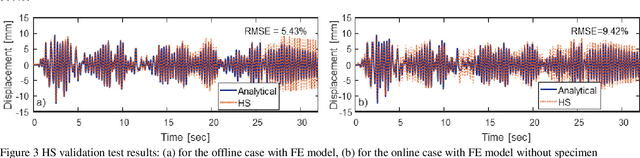
Hybrid simulation (HS) is a widely used structural testing method that combines a computational substructure with a numerical model for well-understood components and an experimental substructure for other parts of the structure that are physically tested. One challenge for fast HS or real-time HS (RTHS) is associated with the analytical substructures of relatively complex structures, which could have large number of degrees of freedoms (DOFs), for instance. These large DOFs computations could be hard to perform in real-time, even with the all current hardware capacities. In this study, a metamodeling technique is proposed to represent the structural dynamic behavior of the analytical substructure. A preliminary study is conducted where a one-bay one-story concentrically braced frame (CBF) is tested under earthquake loading by using a compact HS setup at the University of Nevada, Reno. The experimental setup allows for using a small-scale brace as the experimental substructure combined with a steel frame at the prototype full-scale for the analytical substructure. Two different machine learning algorithms are evaluated to provide a valid and useful metamodeling solution for analytical substructure. The metamodels are trained with the available data that is obtained from the pure analytical solution of the prototype steel frame. The two algorithms used for developing the metamodels are: (1) linear regression (LR) model, and (2) basic recurrent neural network (RNN). The metamodels are first validated against the pure analytical response of the structure. Next, RTHS experiments are conducted by using metamodels. RTHS test results using both LR and RNN models are evaluated, and the advantages and disadvantages of these models are discussed.
HydraSum: Disentangling Stylistic Features in Text Summarization using Multi-Decoder Models
Nov 03, 2021
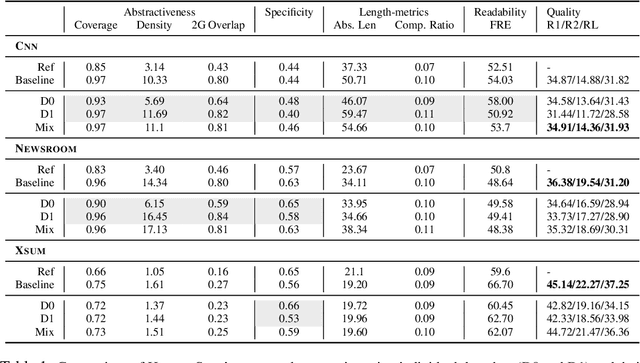
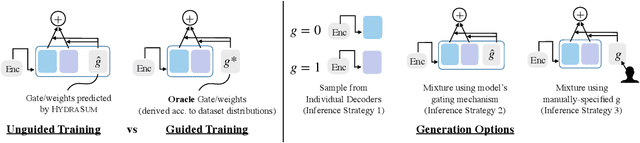

Existing abstractive summarization models lack explicit control mechanisms that would allow users to influence the stylistic features of the model outputs. This results in generating generic summaries that do not cater to the users needs or preferences. To address this issue we introduce HydraSum, a new summarization architecture that extends the single decoder framework of current models, e.g. BART, to a mixture-of-experts version consisting of multiple decoders. Our proposed model encourages each expert, i.e. decoder, to learn and generate stylistically-distinct summaries along dimensions such as abstractiveness, length, specificity, and others. At each time step, HydraSum employs a gating mechanism that decides the contribution of each individual decoder to the next token's output probability distribution. Through experiments on three summarization datasets (CNN, Newsroom, XSum), we demonstrate that this gating mechanism automatically learns to assign contrasting summary styles to different HydraSum decoders under the standard training objective without the need for additional supervision. We further show that a guided version of the training process can explicitly govern which summary style is partitioned between decoders, e.g. high abstractiveness vs. low abstractiveness or high specificity vs. low specificity, and also increase the stylistic-difference between individual decoders. Finally, our experiments demonstrate that our decoder framework is highly flexible: during inference, we can sample from individual decoders or mixtures of different subsets of the decoders to yield a diverse set of summaries and enforce single- and multi-style control over summary generation.
Statistically Efficient, Polynomial Time Algorithms for Combinatorial Semi Bandits
Feb 17, 2020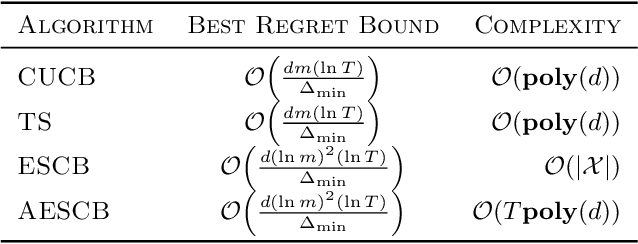
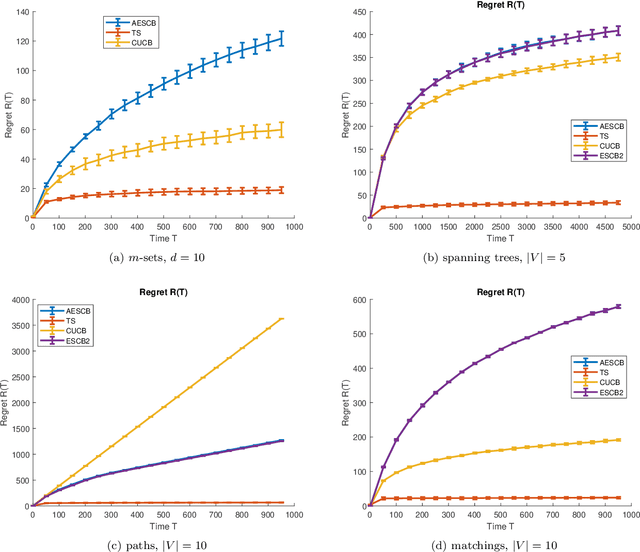
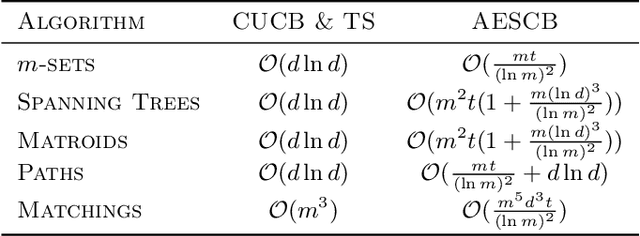
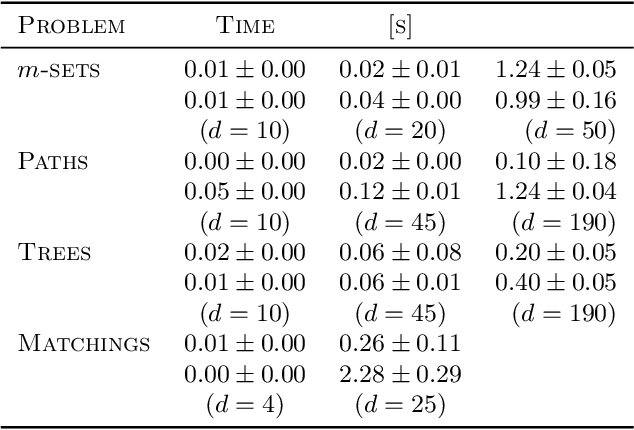
We consider combinatorial semi-bandits over a set of arms ${\cal X} \subset \{0,1\}^d$ where rewards are uncorrelated across items. For this problem, the algorithm ESCB yields the smallest known regret bound $R(T) = {\cal O}\Big( {d (\ln m)^2 (\ln T) \over \Delta_{\min} }\Big)$, but it has computational complexity ${\cal O}(|{\cal X}|)$ which is typically exponential in $d$, and cannot be used in large dimensions. We propose the first algorithm which is both computationally and statistically efficient for this problem with regret $R(T) = {\cal O} \Big({d (\ln m)^2 (\ln T)\over \Delta_{\min} }\Big)$ and computational complexity ${\cal O}(T {\bf poly}(d))$. Our approach involves carefully designing an approximate version of ESCB with the same regret guarantees, showing that this approximate algorithm can be implemented in time ${\cal O}(T {\bf poly}(d))$ by repeatedly maximizing a linear function over ${\cal X}$ subject to a linear budget constraint, and showing how to solve this maximization problems efficiently.
Using Robust Regression to Find Font Usage Trends
Jun 30, 2021
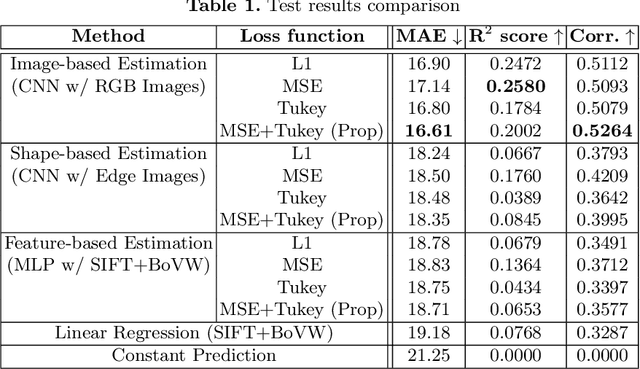

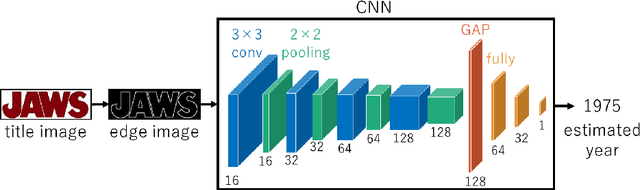
Fonts have had trends throughout their history, not only in when they were invented but also in their usage and popularity. In this paper, we attempt to specifically find the trends in font usage using robust regression on a large collection of text images. We utilize movie posters as the source of fonts for this task because movie posters can represent time periods by using their release date. In addition, movie posters are documents that are carefully designed and represent a wide range of fonts. To understand the relationship between the fonts of movie posters and time, we use a regression Convolutional Neural Network (CNN) to estimate the release year of a movie using an isolated title text image. Due to the difficulty of the task, we propose to use of a hybrid training regimen that uses a combination of Mean Squared Error (MSE) and Tukey's biweight loss. Furthermore, we perform a thorough analysis on the trends of fonts through time.
Boosting Graph Embedding on a Single GPU
Oct 19, 2021
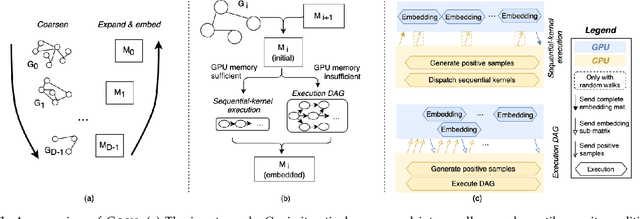
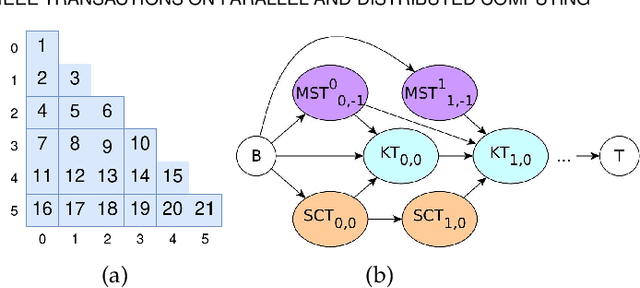
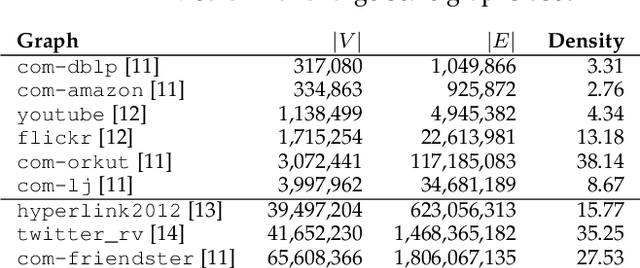
Graphs are ubiquitous, and they can model unique characteristics and complex relations of real-life systems. Although using machine learning (ML) on graphs is promising, their raw representation is not suitable for ML algorithms. Graph embedding represents each node of a graph as a d-dimensional vector which is more suitable for ML tasks. However, the embedding process is expensive, and CPU-based tools do not scale to real-world graphs. In this work, we present GOSH, a GPU-based tool for embedding large-scale graphs with minimum hardware constraints. GOSH employs a novel graph coarsening algorithm to enhance the impact of updates and minimize the work for embedding. It also incorporates a decomposition schema that enables any arbitrarily large graph to be embedded with a single GPU. As a result, GOSH sets a new state-of-the-art in link prediction both in accuracy and speed, and delivers high-quality embeddings for node classification at a fraction of the time compared to the state-of-the-art. For instance, it can embed a graph with over 65 million vertices and 1.8 billion edges in less than 30 minutes on a single GPU.
Exploring Rich and Efficient Spatial Temporal Interactions for Real Time Video Salient Object Detection
Aug 07, 2020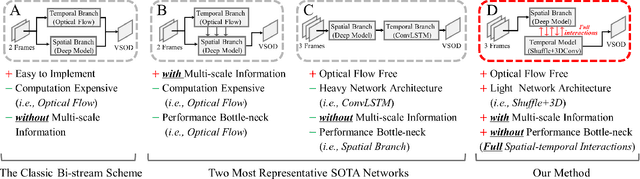
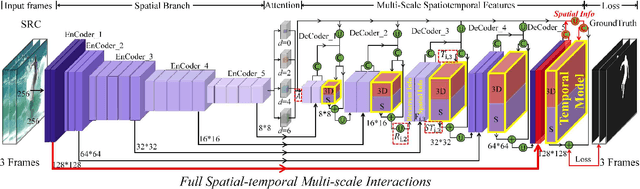
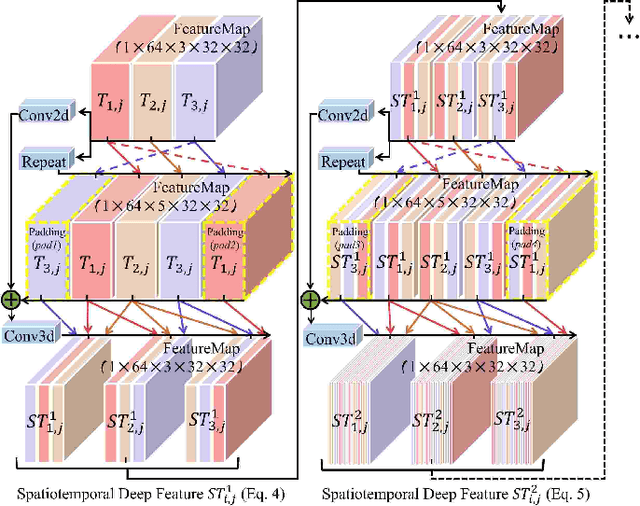
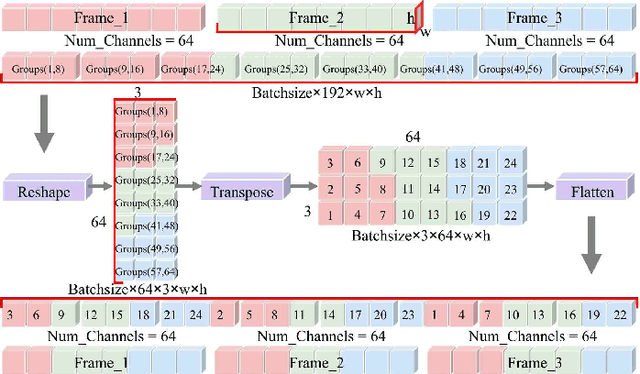
The current main stream methods formulate their video saliency mainly from two independent venues, i.e., the spatial and temporal branches. As a complementary component, the main task for the temporal branch is to intermittently focus the spatial branch on those regions with salient movements. In this way, even though the overall video saliency quality is heavily dependent on its spatial branch, however, the performance of the temporal branch still matter. Thus, the key factor to improve the overall video saliency is how to further boost the performance of these branches efficiently. In this paper, we propose a novel spatiotemporal network to achieve such improvement in a full interactive fashion. We integrate a lightweight temporal model into the spatial branch to coarsely locate those spatially salient regions which are correlated with trustworthy salient movements. Meanwhile, the spatial branch itself is able to recurrently refine the temporal model in a multi-scale manner. In this way, both the spatial and temporal branches are able to interact with each other, achieving the mutual performance improvement. Our method is easy to implement yet effective, achieving high quality video saliency detection in real-time speed with 50 FPS.
Constraint-Driven Optimal Control of Multi-Agent Systems: A Highway Platooning Case Study
Sep 13, 2021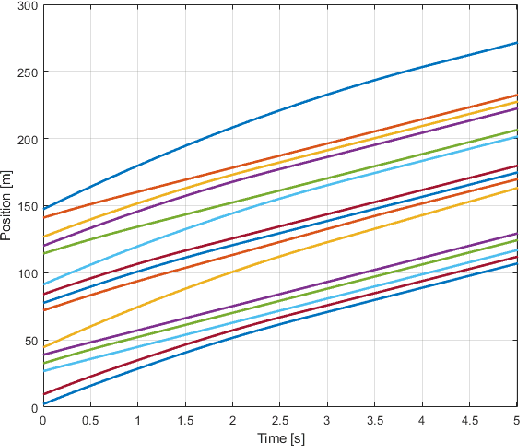
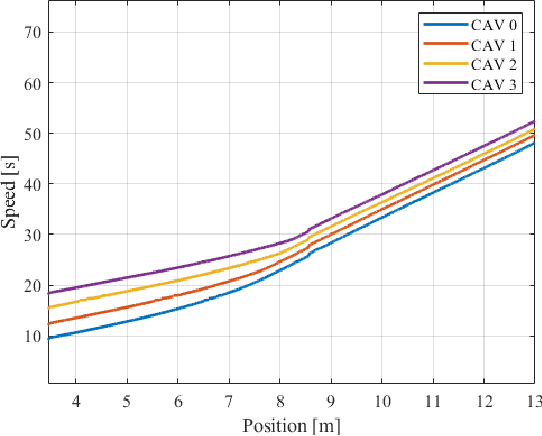
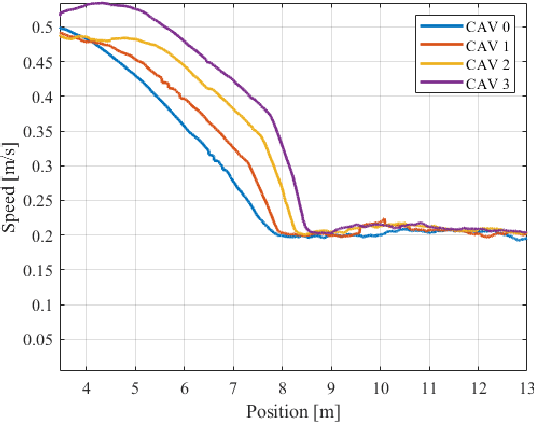
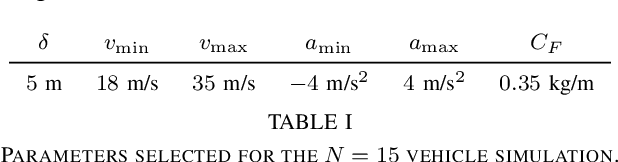
Platooning has been exploited as a method for vehicles to minimize energy consumption. In this article, we present a constraint-driven optimal control framework that yields emergent platooning behavior for connected and automated vehicles operating in an open transportation system. Our approach combines recent insights in constraint-driven optimal control with the physical aerodynamic interactions between vehicles in a highway setting. The result is a set of equations that describes when platooning is an appropriate strategy, as well as a descriptive optimal control law that yields emergent platooning behavior. Finally, we demonstrate these properties in simulation and with a real-time experiment in a scaled testbed.
Simple yet efficient real-time pose-based action recognition
Apr 19, 2019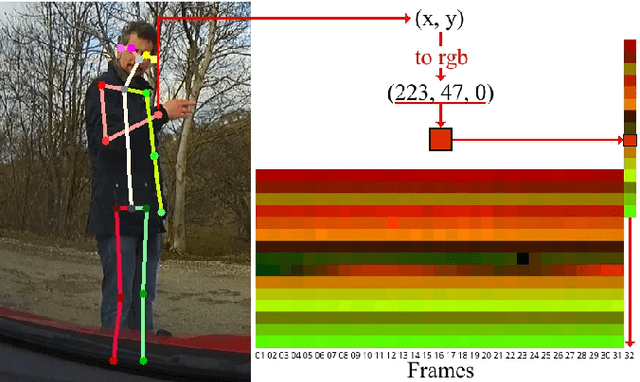

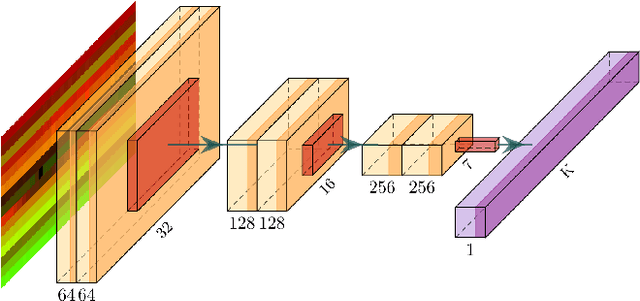

Recognizing human actions is a core challenge for autonomous systems as they directly share the same space with humans. Systems must be able to recognize and assess human actions in real-time. In order to train corresponding data-driven algorithms, a significant amount of annotated training data is required. We demonstrated a pipeline to detect humans, estimate their pose, track them over time and recognize their actions in real-time with standard monocular camera sensors. For action recognition, we encode the human pose into a new data format called Encoded Human Pose Image (EHPI) that can then be classified using standard methods from the computer vision community. With this simple procedure we achieve competitive state-of-the-art performance in pose-based action detection and can ensure real-time performance. In addition, we show a use case in the context of autonomous driving to demonstrate how such a system can be trained to recognize human actions using simulation data.
Learning Robotic Manipulation Skills Using an Adaptive Force-Impedance Action Space
Oct 19, 2021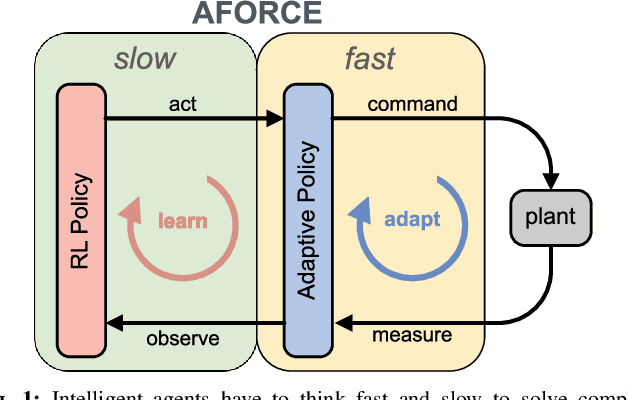
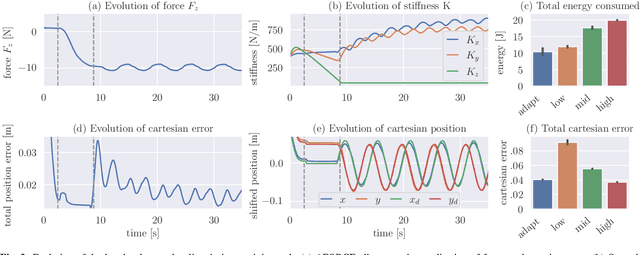
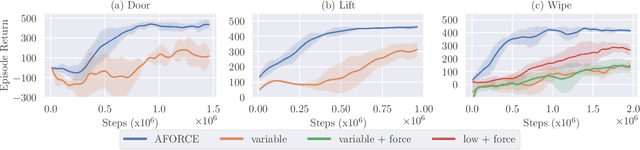
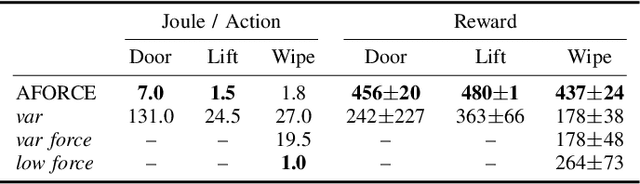
Intelligent agents must be able to think fast and slow to perform elaborate manipulation tasks. Reinforcement Learning (RL) has led to many promising results on a range of challenging decision-making tasks. However, in real-world robotics, these methods still struggle, as they require large amounts of expensive interactions and have slow feedback loops. On the other hand, fast human-like adaptive control methods can optimize complex robotic interactions, yet fail to integrate multimodal feedback needed for unstructured tasks. In this work, we propose to factor the learning problem in a hierarchical learning and adaption architecture to get the best of both worlds. The framework consists of two components, a slow reinforcement learning policy optimizing the task strategy given multimodal observations, and a fast, real-time adaptive control policy continuously optimizing the motion, stability, and effort of the manipulator. We combine these components through a bio-inspired action space that we call AFORCE. We demonstrate the new action space on a contact-rich manipulation task on real hardware and evaluate its performance on three simulated manipulation tasks. Our experiments show that AFORCE drastically improves sample efficiency while reducing energy consumption and improving safety.