 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkerless Robot Detection and 6D Pose Estimation for Multi-Agent SLAM
Feb 18, 2026The capability of multi-robot SLAM approaches to merge localization history and maps from different observers is often challenged by the difficulty in establishing data association. Loop closure detection between perceptual inputs of different robotic agents is easily compromised in the context of perceptual aliasing, or when perspectives differ significantly. For this reason, direct mutual observation among robots is a powerful way to connect partial SLAM graphs, but often relies on the presence of calibrated arrays of fiducial markers (e.g., AprilTag arrays), which severely limits the range of observations and frequently fails under sharp lighting conditions, e.g., reflections or overexposure. In this work, we propose a novel solution to this problem leveraging recent advances in Deep-Learning-based 6D pose estimation. We feature markerless pose estimation as part of a decentralized multi-robot SLAM system and demonstrate the benefit to the relative localization accuracy among the robotic team. The solution is validated experimentally on data recorded in a test field campaign on a planetary analogous environment.
Conditional Latent Diffusion Models for Zero-Shot Instance Segmentation
Aug 06, 2025This paper presents OC-DiT, a novel class of diffusion models designed for object-centric prediction, and applies it to zero-shot instance segmentation. We propose a conditional latent diffusion framework that generates instance masks by conditioning the generative process on object templates and image features within the diffusion model's latent space. This allows our model to effectively disentangle object instances through the diffusion process, which is guided by visual object descriptors and localized image cues. Specifically, we introduce two model variants: a coarse model for generating initial object instance proposals, and a refinement model that refines all proposals in parallel. We train these models on a newly created, large-scale synthetic dataset comprising thousands of high-quality object meshes. Remarkably, our model achieves state-of-the-art performance on multiple challenging real-world benchmarks, without requiring any retraining on target data. Through comprehensive ablation studies, we demonstrate the potential of diffusion models for instance segmentation tasks.
How Important are Data Augmentations to Close the Domain Gap for Object Detection in Orbit?
Oct 21, 2024



We investigate the efficacy of data augmentations to close the domain gap in spaceborne computer vision, crucial for autonomous operations like on-orbit servicing. As the use of computer vision in space increases, challenges such as hostile illumination and low signal-to-noise ratios significantly hinder performance. While learning-based algorithms show promising results, their adoption is limited by the need for extensive annotated training data and the domain gap that arises from differences between synthesized and real-world imagery. This study explores domain generalization in terms of data augmentations -- classical color and geometric transformations, corruptions, and noise -- to enhance model performance across the domain gap. To this end, we conduct an large scale experiment using a hyperparameter optimization pipeline that samples hundreds of different configurations and searches for the best set to bridge the domain gap. As a reference task, we use 2D object detection and evaluate on the SPEED+ dataset that contains real hardware-in-the-loop satellite images in its test set. Moreover, we evaluate four popular object detectors, including Mask R-CNN, Faster R-CNN, YOLO-v7, and the open set detector GroundingDINO, and highlight their trade-offs between performance, inference speed, and training time. Our results underscore the vital role of data augmentations in bridging the domain gap, improving model performance, robustness, and reliability for critical space applications. As a result, we propose two novel data augmentations specifically developed to emulate the visual effects observed in orbital imagery. We conclude by recommending the most effective augmentations for advancing computer vision in challenging orbital environments. Code for training detectors and hyperparameter search will be made publicly available.
Software for the SpaceDREAM Robotic Arm
Sep 26, 2024



Impedance-controlled robots are widely used on Earth to perform interaction-rich tasks and will be a key enabler for In-Space Servicing, Assembly and Manufacturing (ISAM) activities. This paper introduces the software architecture used on the On-Board Computer (OBC) for the planned SpaceDREAM mission aiming to validate such robotic arm in Lower Earth Orbit (LEO) conducted by the German Aerospace Center (DLR) in cooperation with KINETIK Space GmbH and the Technical University of Munich (TUM). During the mission several free motion as well as contact tasks are to be performed in order to verify proper functionality of the robot in position and impedance control on joint level as well as in cartesian control. The tasks are selected to be representative for subsequent servicing missions e.g. requiring interface docking or precise manipulation. The software on the OBC commands the robot's joints via SpaceWire to perform those mission tasks, reads camera images and data from additional sensors and sends telemetry data through an Ethernet link via the spacecraft down to Earth. It is set up to execute a predefined mission after receiving a start signal from the spacecraft while it should be extendable to receive commands from Earth for later missions. Core design principle was to reuse as much existing software and to stay as close as possible to existing robot software stacks at DLR. This allowed for a quick full operational start of the robot arm compared to a custom development of all robot software, a lower entry barrier for software developers as well as a reuse of existing libraries. While not every line of code can be tested with this design, most of the software has already proven its functionality through daily execution on multiple robot systems.
6D Object Pose Estimation from Approximate 3D Models for Orbital Robotics
Mar 31, 2023



We present a novel technique to estimate the 6D pose of objects from single images where the 3D geometry of the object is only given approximately and not as a precise 3D model. To achieve this, we employ a dense 2D-to-3D correspondence predictor that regresses 3D model coordinates for every pixel. In addition to the 3D coordinates, our model also estimates the pixel-wise coordinate error to discard correspondences that are likely wrong. This allows us to generate multiple 6D pose hypotheses of the object, which we then refine iteratively using a highly efficient region-based approach. We also introduce a novel pixel-wise posterior formulation by which we can estimate the probability for each hypothesis and select the most likely one. As we show in experiments, our approach is capable of dealing with extreme visual conditions including overexposure, high contrast, or low signal-to-noise ratio. This makes it a powerful technique for the particularly challenging task of estimating the pose of tumbling satellites for in-orbit robotic applications. Our method achieves state-of-the-art performance on the SPEED+ dataset and has won the SPEC2021 post-mortem competition.
Learning Robotic Manipulation Skills Using an Adaptive Force-Impedance Action Space
Oct 20, 2021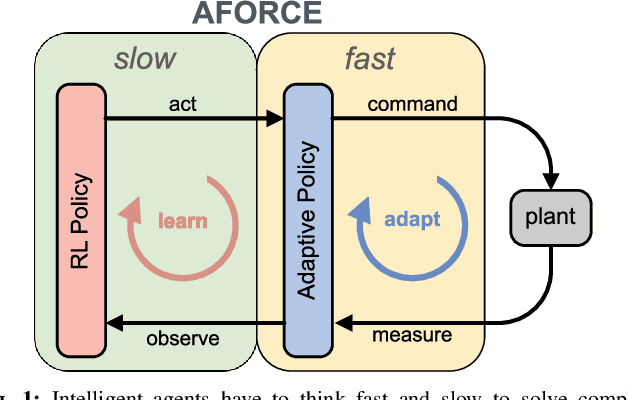
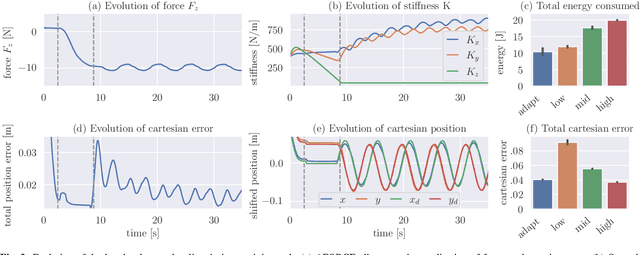
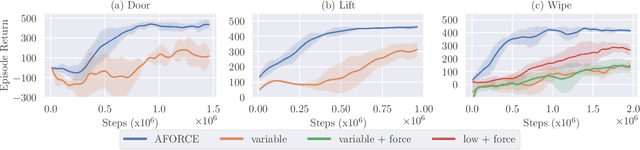
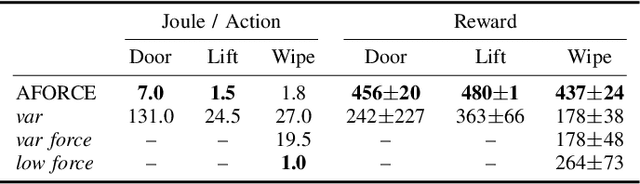
Intelligent agents must be able to think fast and slow to perform elaborate manipulation tasks. Reinforcement Learning (RL) has led to many promising results on a range of challenging decision-making tasks. However, in real-world robotics, these methods still struggle, as they require large amounts of expensive interactions and have slow feedback loops. On the other hand, fast human-like adaptive control methods can optimize complex robotic interactions, yet fail to integrate multimodal feedback needed for unstructured tasks. In this work, we propose to factor the learning problem in a hierarchical learning and adaption architecture to get the best of both worlds. The framework consists of two components, a slow reinforcement learning policy optimizing the task strategy given multimodal observations, and a fast, real-time adaptive control policy continuously optimizing the motion, stability, and effort of the manipulator. We combine these components through a bio-inspired action space that we call AFORCE. We demonstrate the new action space on a contact-rich manipulation task on real hardware and evaluate its performance on three simulated manipulation tasks. Our experiments show that AFORCE drastically improves sample efficiency while reducing energy consumption and improving safety.
Seeking Visual Discomfort: Curiosity-driven Representations for Reinforcement Learning
Oct 02, 2021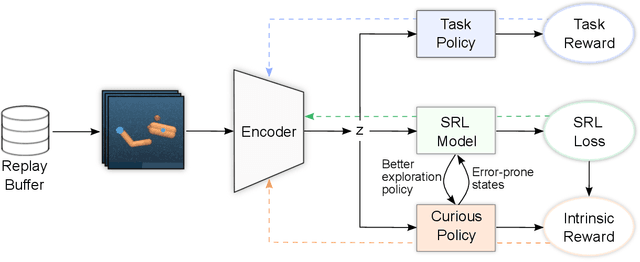
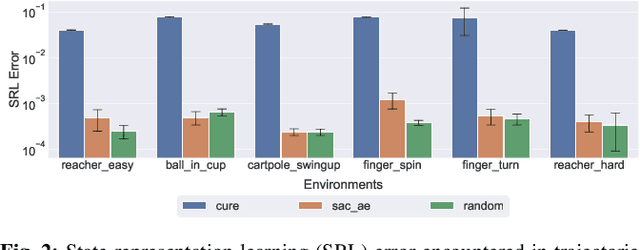
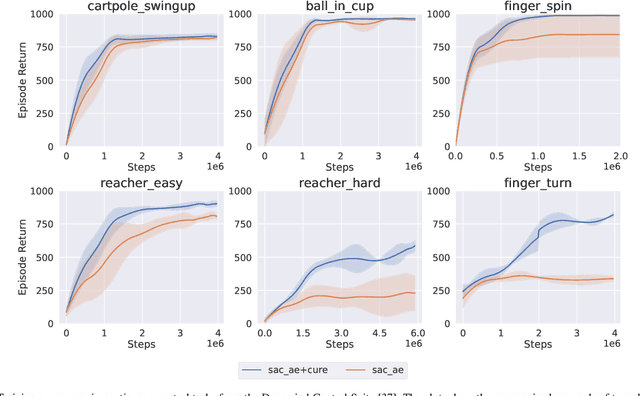
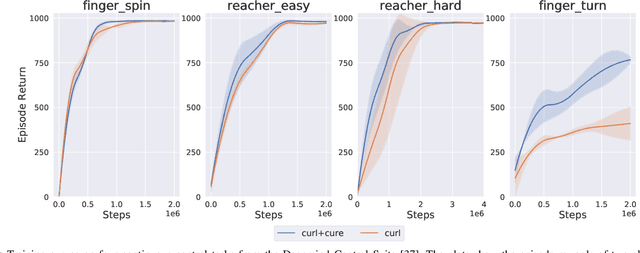
Vision-based reinforcement learning (RL) is a promising approach to solve control tasks involving images as the main observation. State-of-the-art RL algorithms still struggle in terms of sample efficiency, especially when using image observations. This has led to increased attention on integrating state representation learning (SRL) techniques into the RL pipeline. Work in this field demonstrates a substantial improvement in sample efficiency among other benefits. However, to take full advantage of this paradigm, the quality of samples used for training plays a crucial role. More importantly, the diversity of these samples could affect the sample efficiency of vision-based RL, but also its generalization capability. In this work, we present an approach to improve sample diversity for state representation learning. Our method enhances the exploration capability of RL algorithms, by taking advantage of the SRL setup. Our experiments show that our proposed approach boosts the visitation of problematic states, improves the learned state representation, and outperforms the baselines for all tested environments. These results are most apparent for environments where the baseline methods struggle. Even in simple environments, our method stabilizes the training, reduces the reward variance, and promotes sample efficiency.
Making Curiosity Explicit in Vision-based RL
Sep 28, 2021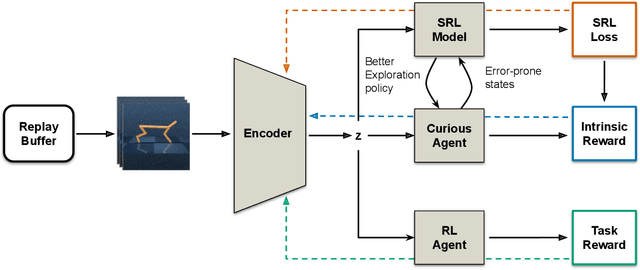
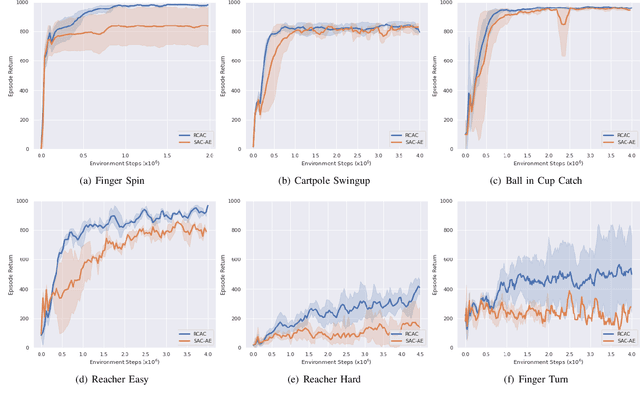

Vision-based reinforcement learning (RL) is a promising technique to solve control tasks involving images as the main observation. State-of-the-art RL algorithms still struggle in terms of sample efficiency, especially when using image observations. This has led to an increased attention on integrating state representation learning (SRL) techniques into the RL pipeline. Work in this field demonstrates a substantial improvement in sample efficiency among other benefits. However, to take full advantage of this paradigm, the quality of samples used for training plays a crucial role. More importantly, the diversity of these samples could affect the sample efficiency of vision-based RL, but also its generalization capability. In this work, we present an approach to improve the sample diversity. Our method enhances the exploration capability of the RL algorithms by taking advantage of the SRL setup. Our experiments show that the presented approach outperforms the baseline for all tested environments. These results are most apparent for environments where the baseline method struggles. Even in simple environments, our method stabilizes the training, reduces the reward variance and boosts sample efficiency.
Learning Vision-based Reactive Policies for Obstacle Avoidance
Oct 30, 2020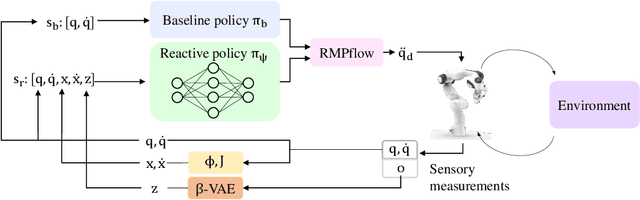
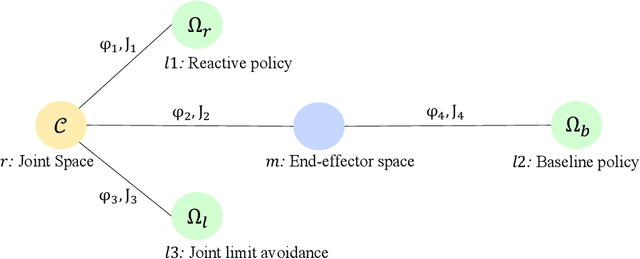

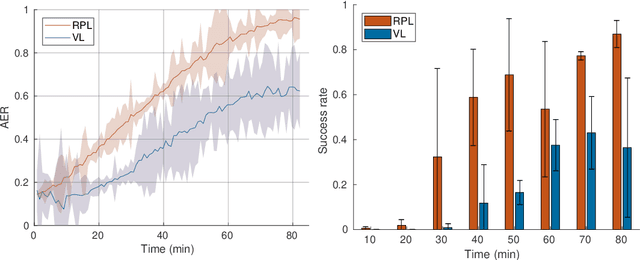
In this paper, we address the problem of vision-based obstacle avoidance for robotic manipulators. This topic poses challenges for both perception and motion generation. While most work in the field aims at improving one of those aspects, we provide a unified framework for approaching this problem. The main goal of this framework is to connect perception and motion by identifying the relationship between the visual input and the corresponding motion representation. To this end, we propose a method for learning reactive obstacle avoidance policies. We evaluate our method on goal-reaching tasks for single and multiple obstacles scenarios. We show the ability of the proposed method to efficiently learn stable obstacle avoidance strategies at a high success rate, while maintaining closed-loop responsiveness required for critical applications like human-robot interaction.