 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractable Instances of Bilinear Maximization: Implementing LinUCB on Ellipsoids
Nov 10, 2025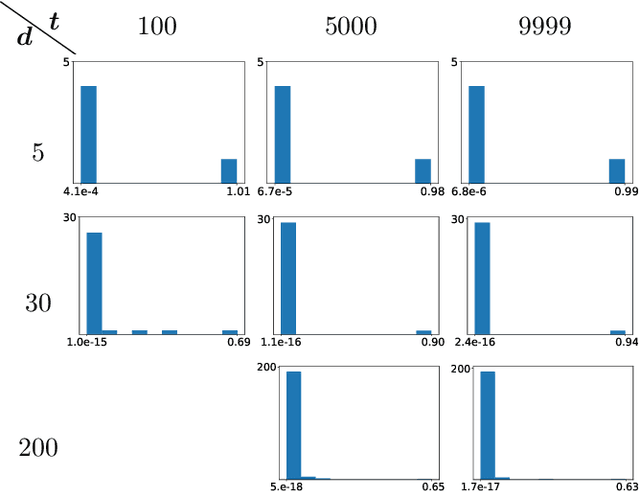
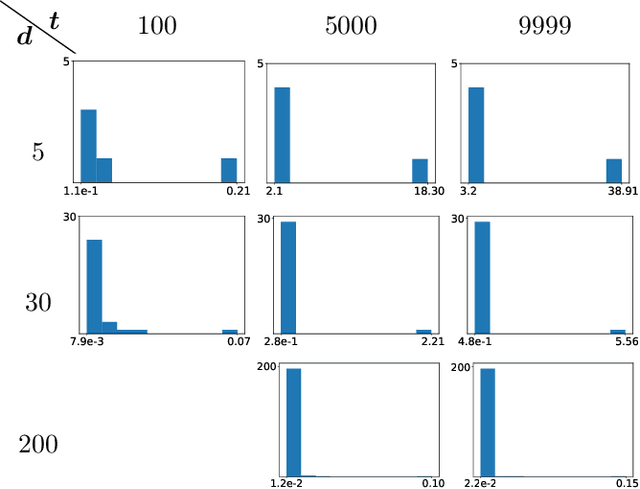
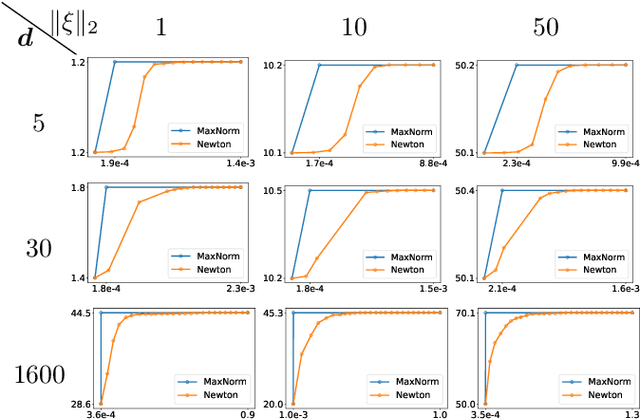
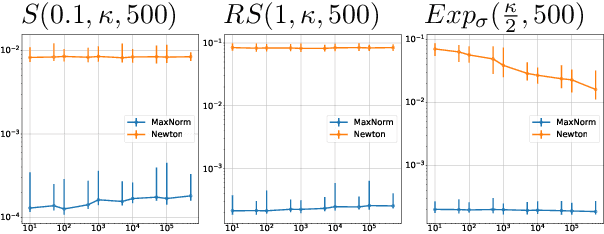
We consider the maximization of $x^\top θ$ over $(x,θ) \in \mathcal{X} \times Θ$, with $\mathcal{X} \subset \mathbb{R}^d$ convex and $Θ\subset \mathbb{R}^d$ an ellipsoid. This problem is fundamental in linear bandits, as the learner must solve it at every time step using optimistic algorithms. We first show that for some sets $\mathcal{X}$ e.g. $\ell_p$ balls with $p>2$, no efficient algorithms exist unless $\mathcal{P} = \mathcal{NP}$. We then provide two novel algorithms solving this problem efficiently when $\mathcal{X}$ is a centered ellipsoid. Our findings provide the first known method to implement optimistic algorithms for linear bandits in high dimensions.
Linear Bandits on Ellipsoids: Minimax Optimal Algorithms
Feb 24, 2025



We consider linear stochastic bandits where the set of actions is an ellipsoid. We provide the first known minimax optimal algorithm for this problem. We first derive a novel information-theoretic lower bound on the regret of any algorithm, which must be at least $\Omega(\min(d \sigma \sqrt{T} + d \|\theta\|_{A}, \|\theta\|_{A} T))$ where $d$ is the dimension, $T$ the time horizon, $\sigma^2$ the noise variance, $A$ a matrix defining the set of actions and $\theta$ the vector of unknown parameters. We then provide an algorithm whose regret matches this bound to a multiplicative universal constant. The algorithm is non-classical in the sense that it is not optimistic, and it is not a sampling algorithm. The main idea is to combine a novel sequential procedure to estimate $\|\theta\|$, followed by an explore-and-commit strategy informed by this estimate. The algorithm is highly computationally efficient, and a run requires only time $O(dT + d^2 \log(T/d) + d^3)$ and memory $O(d^2)$, in contrast with known optimistic algorithms, which are not implementable in polynomial time. We go beyond minimax optimality and show that our algorithm is locally asymptotically minimax optimal, a much stronger notion of optimality. We further provide numerical experiments to illustrate our theoretical findings.
Efficient Function Placement in Virtual Networks: An Online Learning Approach
Oct 17, 2024We propose a model for the virtual function placement problem and several novel algorithms using ideas based on multi-armed bandits. We prove that these algorithms learn the optimal placement policy rapidly, and their regret grows at a rate at most $O( N M \sqrt{T\ln T} )$ while respecting the feasibility constraints with high probability. We show through numerical experiments that those algorithms both have good practical performance and modest computational complexity. Using the proposed acceleration technique, they can be used to learn in large networks where computational power is limited. Our experiments are fully reproducible, and the code is publicly available.
Thompson Sampling For Combinatorial Bandits: Polynomial Regret and Mismatched Sampling Paradox
Oct 07, 2024We consider Thompson Sampling (TS) for linear combinatorial semi-bandits and subgaussian rewards. We propose the first known TS whose finite-time regret does not scale exponentially with the dimension of the problem. We further show the "mismatched sampling paradox": A learner who knows the rewards distributions and samples from the correct posterior distribution can perform exponentially worse than a learner who does not know the rewards and simply samples from a well-chosen Gaussian posterior. The code used to generate the experiments is available at https://github.com/RaymZhang/CTS-Mismatched-Paradox
Towards Optimal Algorithms for Multi-Player Bandits without Collision Sensing Information
Mar 24, 2021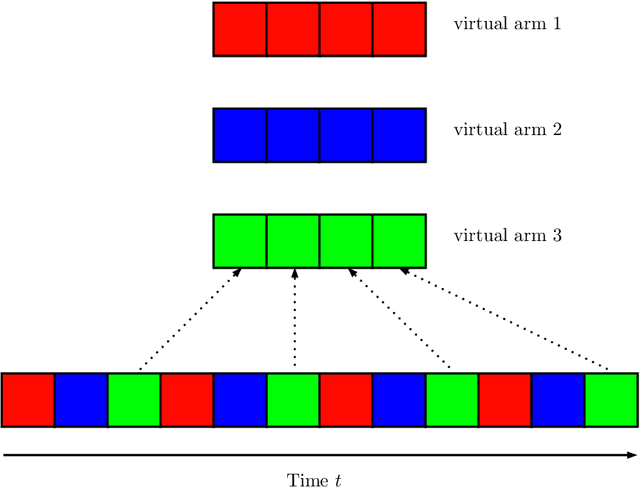
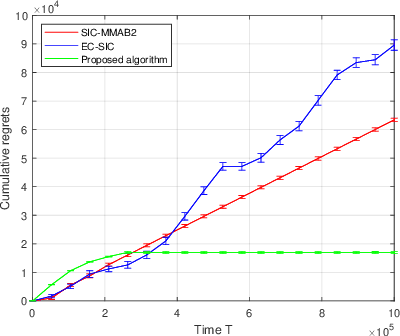
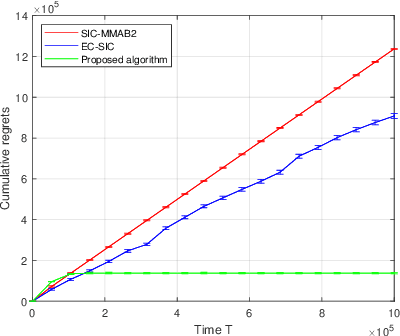
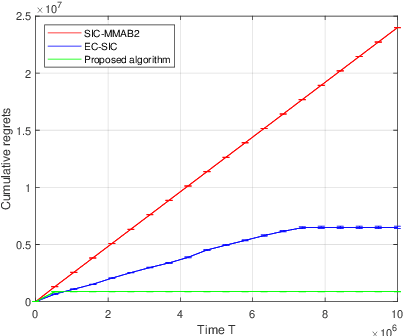
We propose a novel algorithm for multi-player multi-armed bandits without collision sensing information. Our algorithm circumvents two problems shared by all state-of-the-art algorithms: it does not need as an input a lower bound on the minimal expected reward of an arm, and its performance does not scale inversely proportionally to the minimal expected reward. We prove a theoretical regret upper bound to justify these claims. We complement our theoretical results with numerical experiments, showing that the proposed algorithm outperforms state-of-the-art in practice as well.
A High Performance, Low Complexity Algorithm for Multi-Player Bandits Without Collision Sensing Information
Feb 19, 2021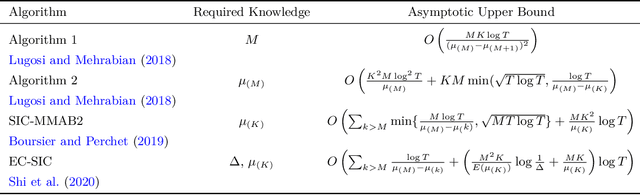
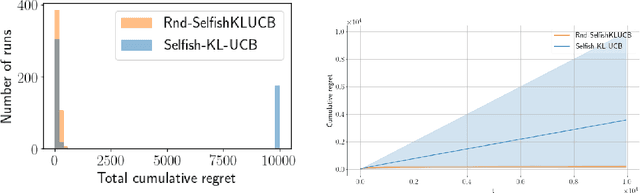
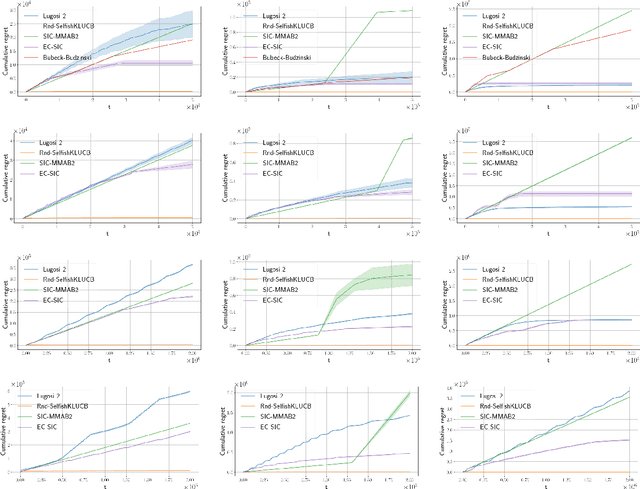
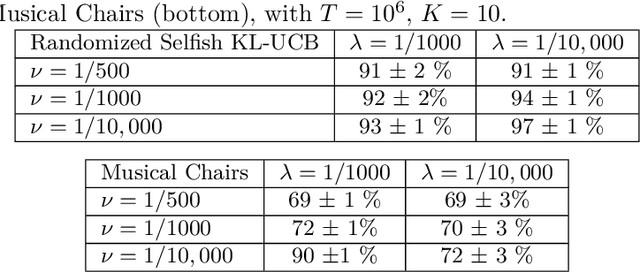
Motivated by applications in cognitive radio networks, we consider the decentralized multi-player multi-armed bandit problem, without collision nor sensing information. We propose Randomized Selfish KL-UCB, an algorithm with very low computational complexity, inspired by the Selfish KL-UCB algorithm, which has been abandoned as it provably performs sub-optimally in some cases. We subject Randomized Selfish KL-UCB to extensive numerical experiments showing that it far outperforms state-of-the-art algorithms in almost all environments, sometimes by several orders of magnitude, and without the additional knowledge required by state-of-the-art algorithms. We also emphasize the potential of this algorithm for the more realistic dynamic setting, and support our claims with further experiments. We believe that the low complexity and high performance of Randomized Selfish KL-UCB makes it the most suitable for implementation in practical systems amongst known algorithms.
Asymptotically Optimal Strategies For Combinatorial Semi-Bandits in Polynomial Time
Feb 14, 2021
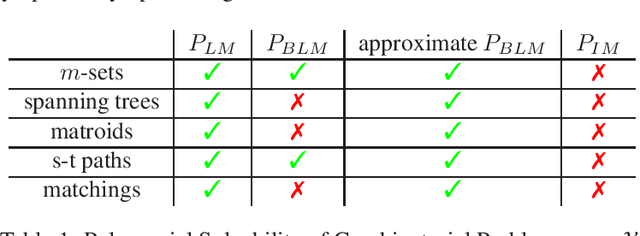


We consider combinatorial semi-bandits with uncorrelated Gaussian rewards. In this article, we propose the first method, to the best of our knowledge, that enables to compute the solution of the Graves-Lai optimization problem in polynomial time for many combinatorial structures of interest. In turn, this immediately yields the first known approach to implement asymptotically optimal algorithms in polynomial time for combinatorial semi-bandits.
On the Suboptimality of Thompson Sampling in High Dimensions
Feb 10, 2021

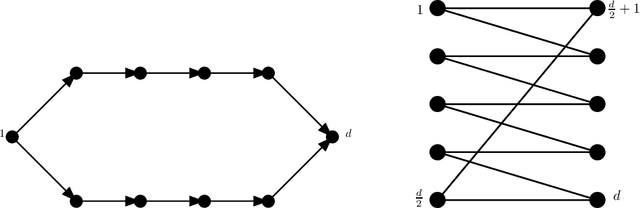
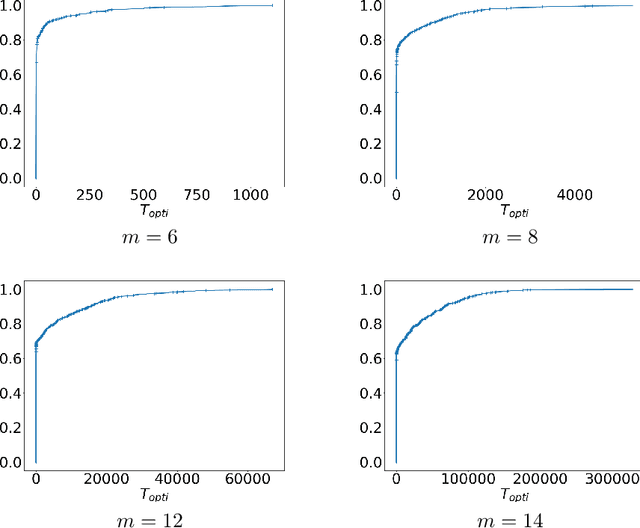
In this paper we consider Thompson Sampling for combinatorial semi-bandits. We demonstrate that, perhaps surprisingly, Thompson Sampling is sub-optimal for this problem in the sense that its regret scales exponentially in the ambient dimension, and its minimax regret scales almost linearly. This phenomenon occurs under a wide variety of assumptions including both non-linear and linear reward functions. We also show that including a fixed amount of forced exploration to Thompson Sampling does not alleviate the problem. We complement our theoretical results with numerical results and show that in practice Thompson Sampling indeed can perform very poorly in high dimensions.
Solving Random Parity Games in Polynomial Time
Jul 16, 2020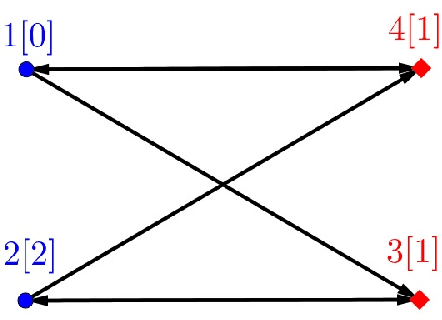
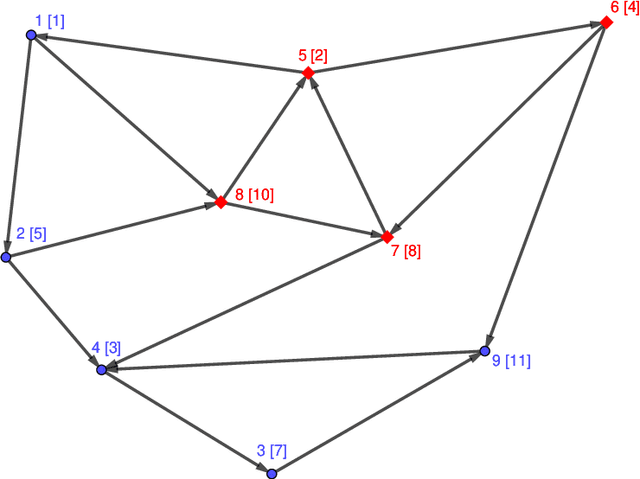
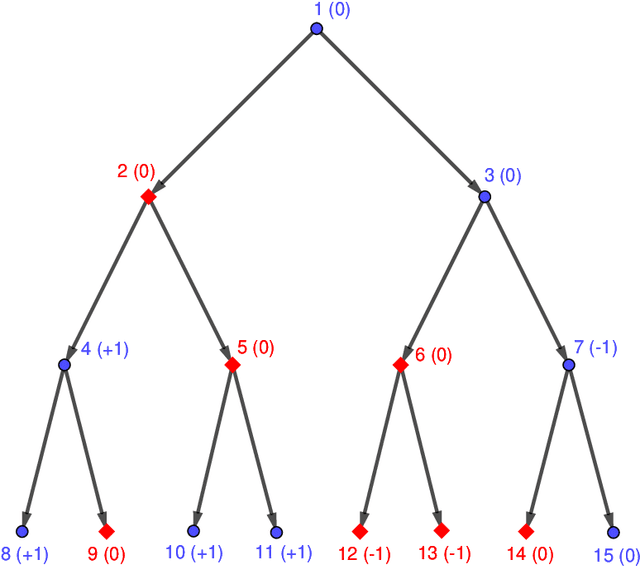
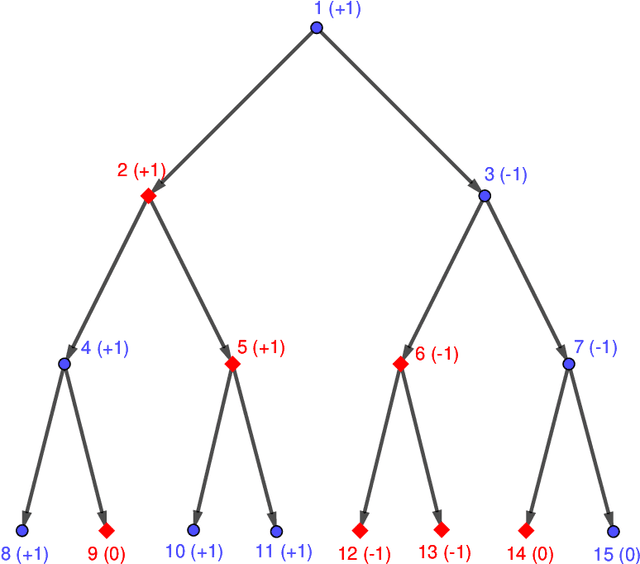
We consider the problem of solving random parity games. We prove that parity games exibit a phase transition threshold above $d_P$, so that when the degree of the graph that defines the game has a degree $d > d_P$ then there exists a polynomial time algorithm that solves the game with high probability when the number of nodes goes to infinity. We further propose the SWCP (Self-Winning Cycles Propagation) algorithm and show that, when the degree is large enough, SWCP solves the game with high probability. Furthermore, the complexity of SWCP is polynomial $O\Big(|{\cal V}|^2 + |{\cal V}||{\cal E}|\Big)$. The design of SWCP is based on the threshold for the appearance of particular types of cycles in the players' respective subgraphs. We further show that non-sparse games can be solved in time $O(|{\cal V}|)$ with high probability, and emit a conjecture concerning the hardness of the $d=2$ case.
Statistically Efficient, Polynomial Time Algorithms for Combinatorial Semi Bandits
Feb 17, 2020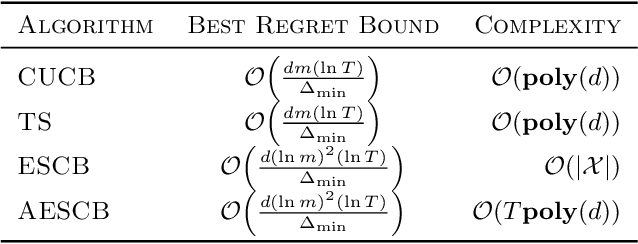
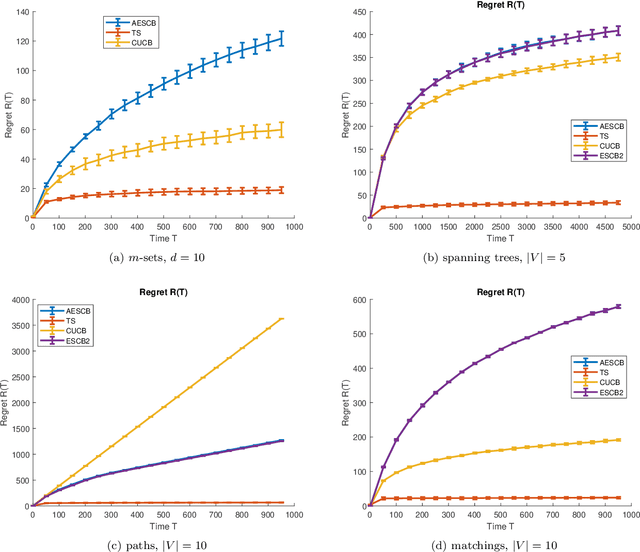
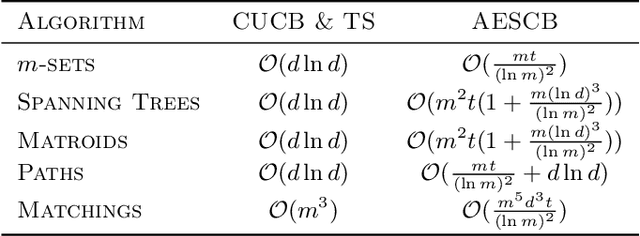
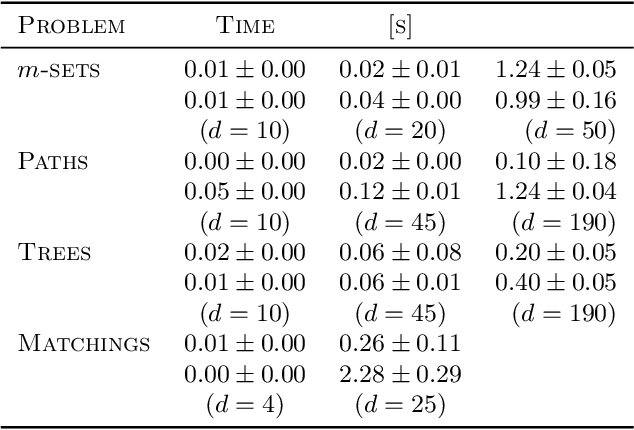
We consider combinatorial semi-bandits over a set of arms ${\cal X} \subset \{0,1\}^d$ where rewards are uncorrelated across items. For this problem, the algorithm ESCB yields the smallest known regret bound $R(T) = {\cal O}\Big( {d (\ln m)^2 (\ln T) \over \Delta_{\min} }\Big)$, but it has computational complexity ${\cal O}(|{\cal X}|)$ which is typically exponential in $d$, and cannot be used in large dimensions. We propose the first algorithm which is both computationally and statistically efficient for this problem with regret $R(T) = {\cal O} \Big({d (\ln m)^2 (\ln T)\over \Delta_{\min} }\Big)$ and computational complexity ${\cal O}(T {\bf poly}(d))$. Our approach involves carefully designing an approximate version of ESCB with the same regret guarantees, showing that this approximate algorithm can be implemented in time ${\cal O}(T {\bf poly}(d))$ by repeatedly maximizing a linear function over ${\cal X}$ subject to a linear budget constraint, and showing how to solve this maximization problems efficiently.