 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FinRL: Deep Reinforcement Learning Framework to Automate Trading in Quantitative Finance
Nov 07, 2021
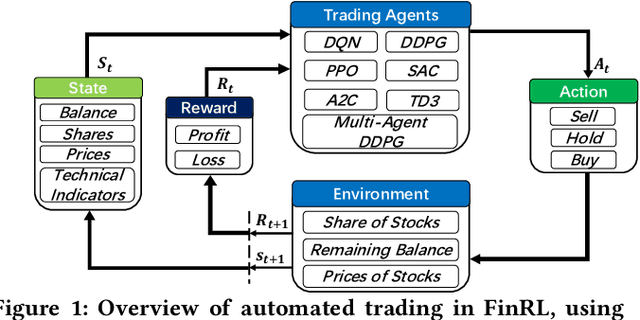
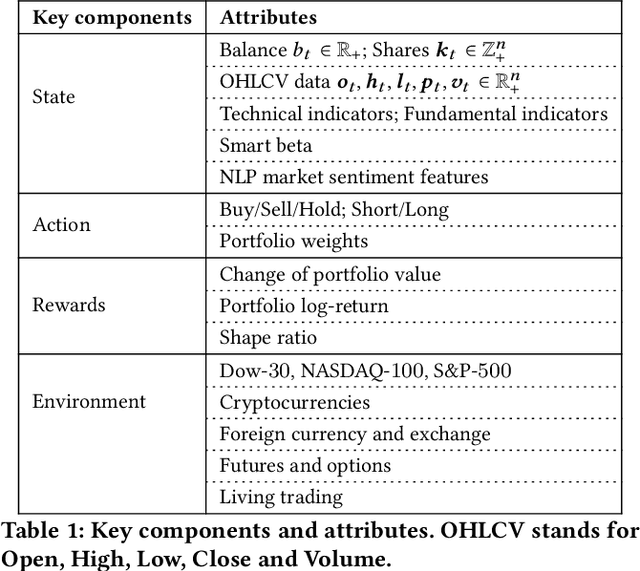
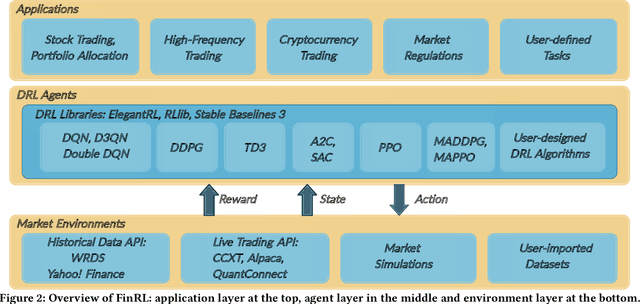

Deep reinforcement learning (DRL) has been envisioned to have a competitive edge in quantitative finance. However, there is a steep development curve for quantitative traders to obtain an agent that automatically positions to win in the market, namely \textit{to decide where to trade, at what price} and \textit{what quantity}, due to the error-prone programming and arduous debugging. In this paper, we present the first open-source framework \textit{FinRL} as a full pipeline to help quantitative traders overcome the steep learning curve. FinRL is featured with simplicity, applicability and extensibility under the key principles, \textit{full-stack framework, customization, reproducibility} and \textit{hands-on tutoring}. Embodied as a three-layer architecture with modular structures, FinRL implements fine-tuned state-of-the-art DRL algorithms and common reward functions, while alleviating the debugging workloads. Thus, we help users pipeline the strategy design at a high turnover rate. At multiple levels of time granularity, FinRL simulates various markets as training environments using historical data and live trading APIs. Being highly extensible, FinRL reserves a set of user-import interfaces and incorporates trading constraints such as market friction, market liquidity and investor's risk-aversion. Moreover, serving as practitioners' stepping stones, typical trading tasks are provided as step-by-step tutorials, e.g., stock trading, portfolio allocation, cryptocurrency trading, etc.
* ACM International Conference on AI in Finance
Online Meta-Learning for Scene-Diverse Waveform-Agile Radar Target Tracking
Oct 21, 2021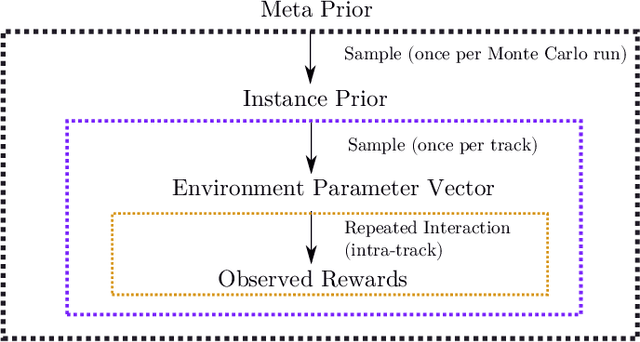
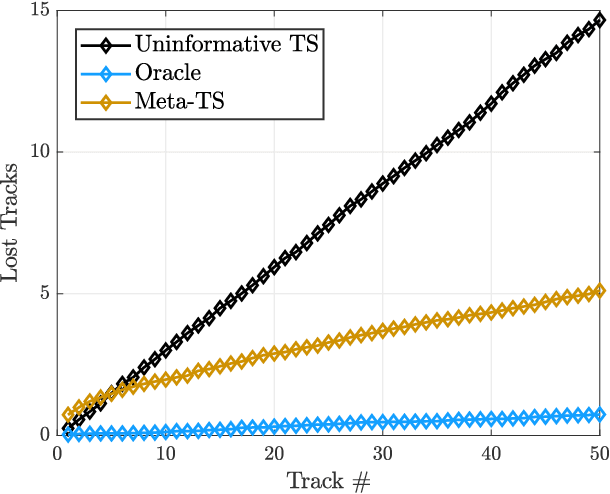
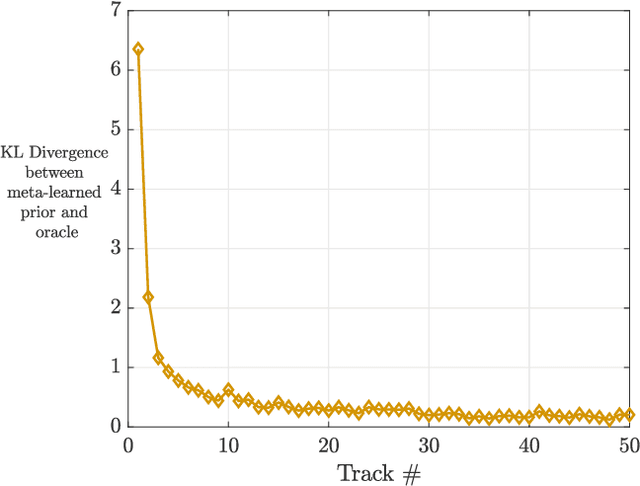
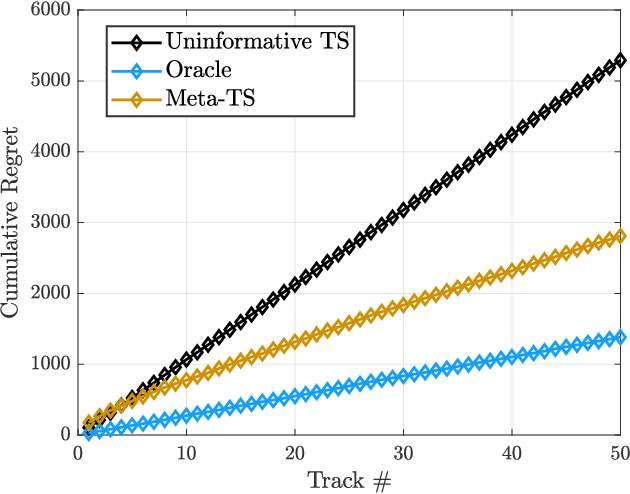
A fundamental problem for waveform-agile radar systems is that the true environment is unknown, and transmission policies which perform well for a particular tracking instance may be sub-optimal for another. Additionally, there is a limited time window for each target track, and the radar must learn an effective strategy from a sequence of measurements in a timely manner. This paper studies a Bayesian meta-learning model for radar waveform selection which seeks to learn an inductive bias to quickly optimize tracking performance across a class of radar scenes. We cast the waveform selection problem in the framework of sequential Bayesian inference, and introduce a contextual bandit variant of the recently proposed meta-Thompson Sampling algorithm, which learns an inductive bias in the form of a prior distribution. Each track is treated as an instance of a contextual bandit learning problem, coming from a task distribution. We show that the meta-learning process results in an appreciably faster learning, resulting in significantly fewer lost tracks than a conventional learning approach equipped with an uninformative prior.
Streaming Generalized Canonical Polyadic Tensor Decompositions
Oct 27, 2021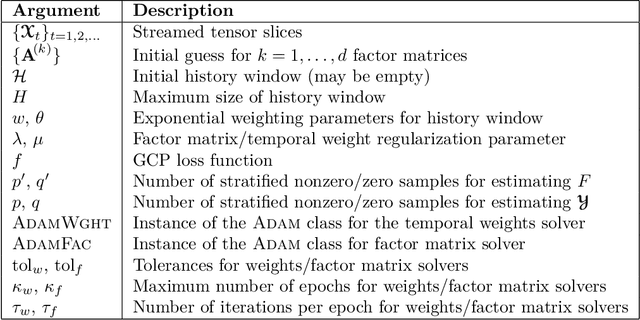
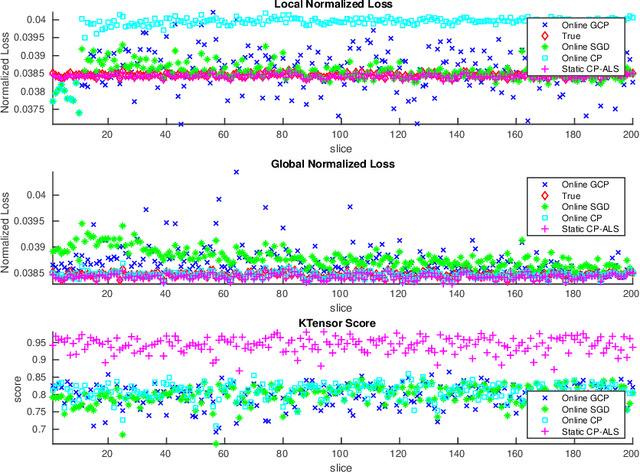
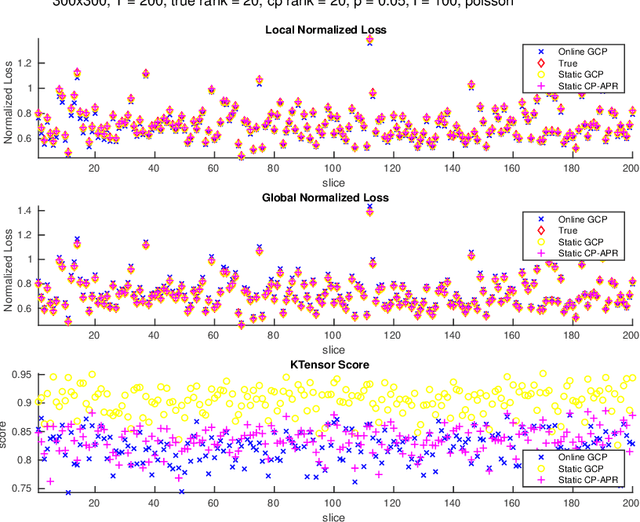
In this paper, we develop a method which we call OnlineGCP for computing the Generalized Canonical Polyadic (GCP) tensor decomposition of streaming data. GCP differs from traditional canonical polyadic (CP) tensor decompositions as it allows for arbitrary objective functions which the CP model attempts to minimize. This approach can provide better fits and more interpretable models when the observed tensor data is strongly non-Gaussian. In the streaming case, tensor data is gradually observed over time and the algorithm must incrementally update a GCP factorization with limited access to prior data. In this work, we extend the GCP formalism to the streaming context by deriving a GCP optimization problem to be solved as new tensor data is observed, formulate a tunable history term to balance reconstruction of recently observed data with data observed in the past, develop a scalable solution strategy based on segregated solves using stochastic gradient descent methods, describe a software implementation that provides performance and portability to contemporary CPU and GPU architectures and integrates with Matlab for enhanced useability, and demonstrate the utility and performance of the approach and software on several synthetic and real tensor data sets.
BRAIN2DEPTH: Lightweight CNN Model for Classification of Cognitive States from EEG Recordings
Jun 12, 2021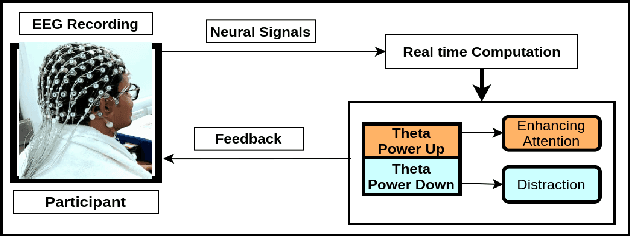

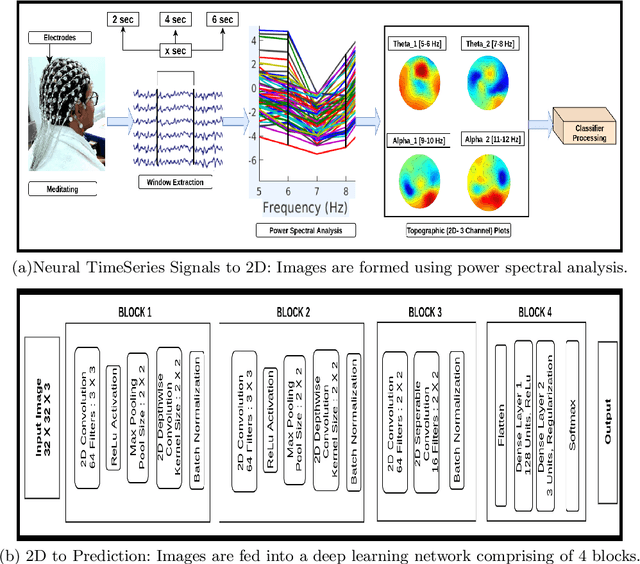
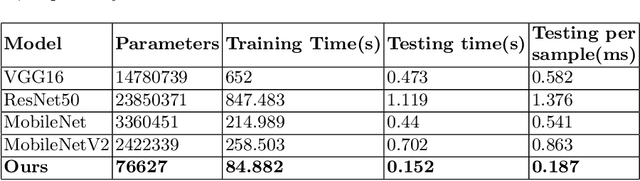
Several Convolutional Deep Learning models have been proposed to classify the cognitive states utilizing several neuro-imaging domains. These models have achieved significant results, but they are heavily designed with millions of parameters, which increases train and test time, making the model complex and less suitable for real-time analysis. This paper proposes a simple, lightweight CNN model to classify cognitive states from Electroencephalograph (EEG) recordings. We develop a novel pipeline to learn distinct cognitive representation consisting of two stages. The first stage is to generate the 2D spectral images from neural time series signals in a particular frequency band. Images are generated to preserve the relationship between the neighboring electrodes and the spectral property of the cognitive events. The second is to develop a time-efficient, computationally less loaded, and high-performing model. We design a network containing 4 blocks and major components include standard and depth-wise convolution for increasing the performance and followed by separable convolution to decrease the number of parameters which maintains the tradeoff between time and performance. We experiment on open access EEG meditation dataset comprising expert, nonexpert meditative, and control states. We compare performance with six commonly used machine learning classifiers and four state of the art deep learning models. We attain comparable performance utilizing less than 4\% of the parameters of other models. This model can be employed in a real-time computation environment such as neurofeedback.
Data Smashing 2.0: Sequence Likelihood (SL) Divergence For Fast Time Series Comparison
Oct 08, 2019
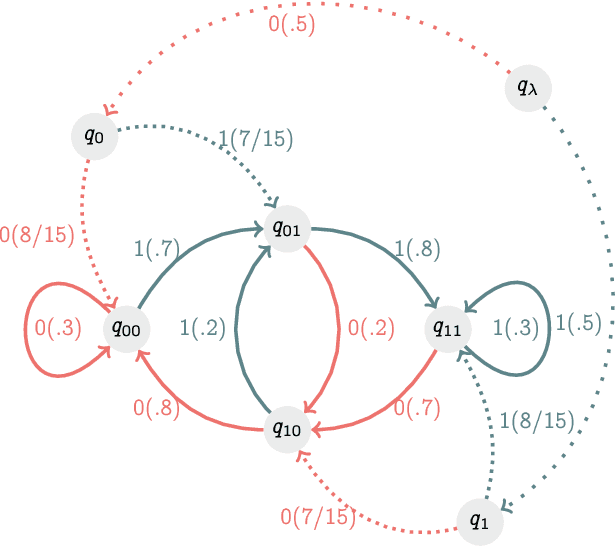
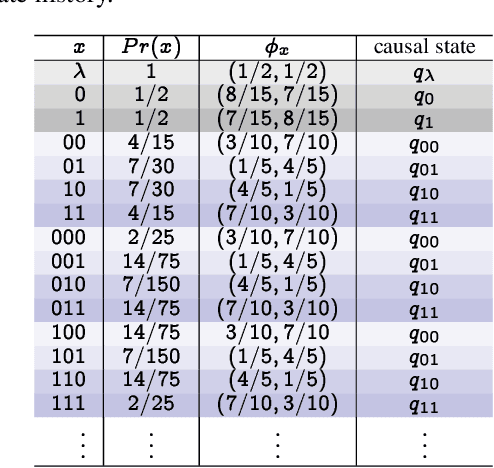
Recognizing subtle historical patterns is central to modeling and forecasting problems in time series analysis. Here we introduce and develop a new approach to quantify deviations in the underlying hidden generators of observed data streams, resulting in a new efficiently computable universal metric for time series. The proposed metric is in the sense that we can compare and contrast data streams regardless of where and how they are generated and without any feature engineering step. The approach proposed in this paper is conceptually distinct from our previous work on data smashing, and vastly improves discrimination performance and computing speed. The core idea here is the generalization of the notion of KL divergence often used to compare probability distributions to a notion of divergence in time series. We call this the sequence likelihood (SL) divergence, which may be used to measure deviations within a well-defined class of discrete-valued stochastic processes. We devise efficient estimators of SL divergence from finite sample paths and subsequently formulate a universal metric useful for computing distance between time series produced by hidden stochastic generators.
Novel EEG based Schizophrenia Detection with IoMT Framework for Smart Healthcare
Nov 19, 2021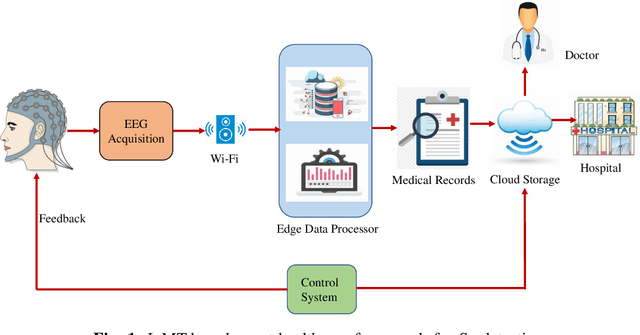
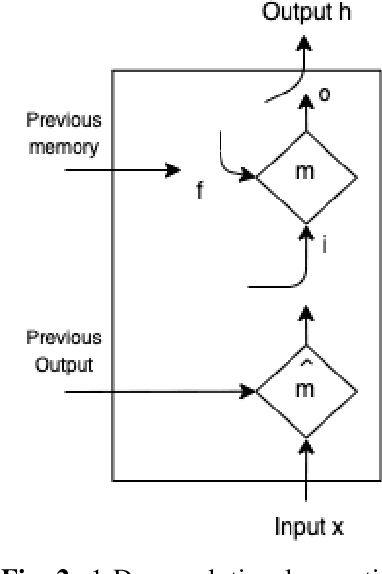
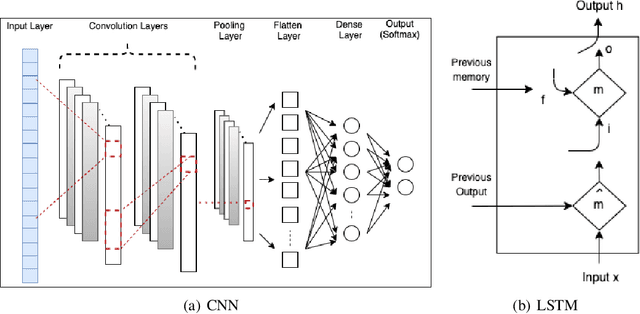
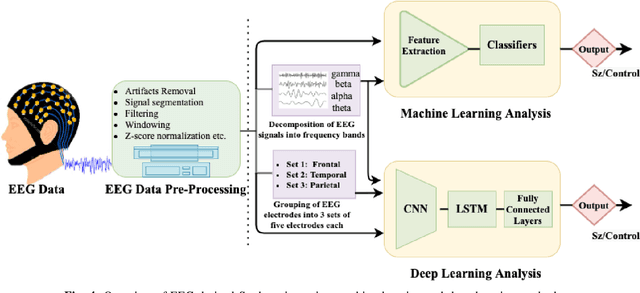
In the field of neuroscience, Brain activity analysis is always considered as an important area. Schizophrenia(Sz) is a brain disorder that severely affects the thinking, behaviour, and feelings of people all around the world. Electroencephalography (EEG) is proved to be an efficient biomarker in Sz detection. EEG is a non-linear time-seriesi signal and utilizing it for investigation is rather crucial due to its non-linear structure. This paper aims to improve the performance of EEG based Sz detection using a deep learning approach. A novel hybrid deep learning model known as SzHNN (Schizophrenia Hybrid Neural Network), a combination of Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) has been proposed. CNN network is used for local feature extraction and LSTM has been utilized for classification. The proposed model has been compared with CNN only, LSTM only, and machine learning-based models. All the models have been evaluated on two different datasets wherein Dataset 1 consists of 19 subjects and Dataset 2 consists of 16 subjects. Several experiments have been conducted for the same using various parametric settings on different frequency bands and using different sets of electrodes on the scalp. Based on all the experiments, it is evident that the proposed hybrid model (SzHNN) provides the highest classification accuracy of 99.9% in comparison to other existing models. The proposed model overcomes the influence of different frequency bands and even showed a much better accuracy of 91% with only 5 electrodes. The proposed model is also evaluated on the Internet of Medical Things (IoMT) framework for smart healthcare and remote monitoring applications.
The Surprising Simplicity of the Early-Time Learning Dynamics of Neural Networks
Jun 25, 2020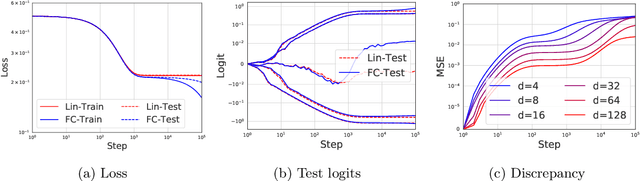
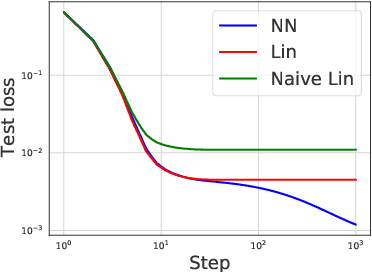
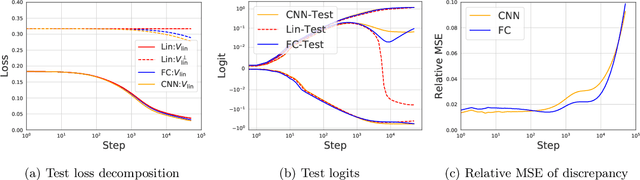
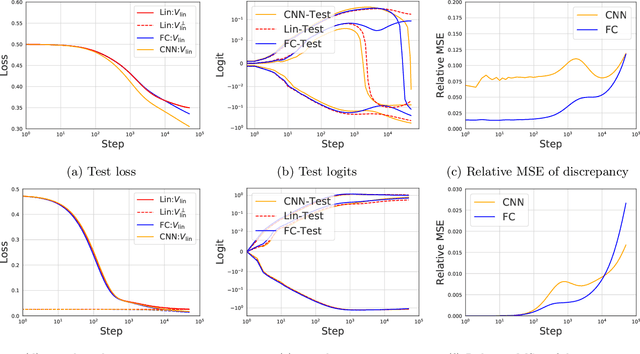
Modern neural networks are often regarded as complex black-box functions whose behavior is difficult to understand owing to their nonlinear dependence on the data and the nonconvexity in their loss landscapes. In this work, we show that these common perceptions can be completely false in the early phase of learning. In particular, we formally prove that, for a class of well-behaved input distributions, the early-time learning dynamics of a two-layer fully-connected neural network can be mimicked by training a simple linear model on the inputs. We additionally argue that this surprising simplicity can persist in networks with more layers and with convolutional architecture, which we verify empirically. Key to our analysis is to bound the spectral norm of the difference between the Neural Tangent Kernel (NTK) at initialization and an affine transform of the data kernel; however, unlike many previous results utilizing the NTK, we do not require the network to have disproportionately large width, and the network is allowed to escape the kernel regime later in training.
Error-feedback Stochastic Configuration Strategy on Convolutional Neural Networks for Time Series Forecasting
Feb 03, 2020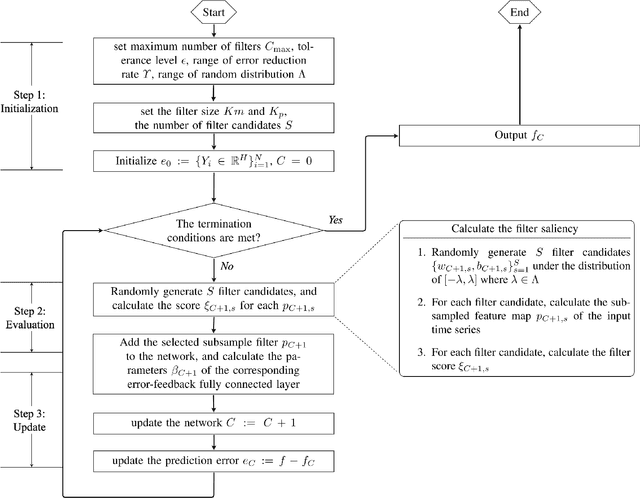
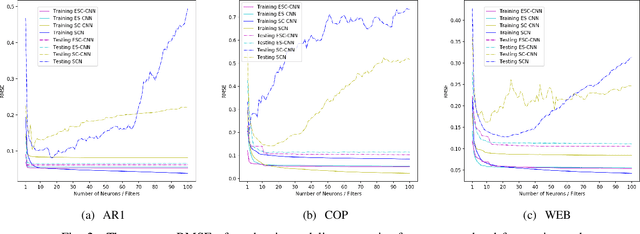
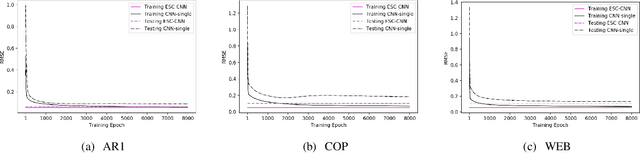
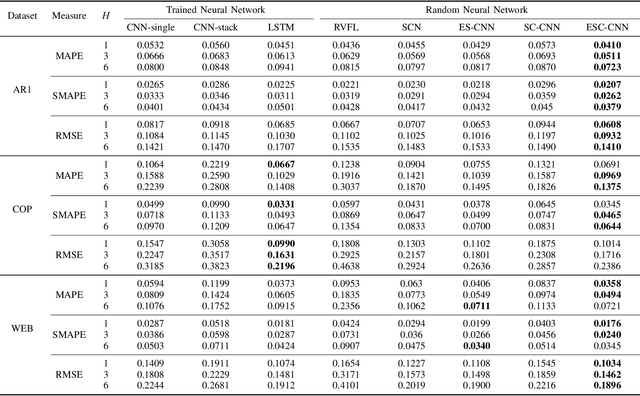
Despite the superiority of convolutional neural networks demonstrated in time series modeling and forecasting, it has not been fully explored on the design of the neural network architecture as well as the tuning of the hyper-parameters. Inspired by the iterative construction strategy for building a random multilayer perceptron, we propose a novel Error-feedback Stochastic Configuration (ESC) strategy to construct a random Convolutional Neural Network (ESC-CNN) for time series forecasting task, which builds the network architecture adaptively. The ESC strategy suggests that random filters and neurons of the error-feedback fully connected layer are incrementally added in a manner that they can steadily compensate the prediction error during the construction process, and a filter selection strategy is introduced to secure that ESC-CNN holds the universal approximation property, providing helpful information at each iterative process for the prediction. The performance of ESC-CNN is justified on its prediction accuracy for one-step-ahead and multi-step-ahead forecasting tasks. Comprehensive experiments on a synthetic dataset and two real-world datasets show that the proposed ESC-CNN not only outperforms the state-of-art random neural networks, but also exhibits strong predictive power in comparison to trained Convolution Neural Networks and Long Short-Term Memory models, demonstrating the effectiveness of ESC-CNN in time series forecasting.
On games and simulators as a platform for development of artificial intelligence for command and control
Oct 21, 2021

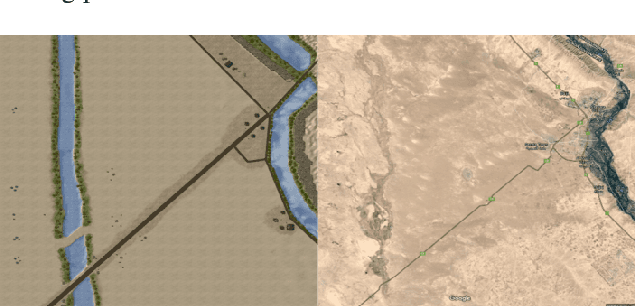
Games and simulators can be a valuable platform to execute complex multi-agent, multiplayer, imperfect information scenarios with significant parallels to military applications: multiple participants manage resources and make decisions that command assets to secure specific areas of a map or neutralize opposing forces. These characteristics have attracted the artificial intelligence (AI) community by supporting development of algorithms with complex benchmarks and the capability to rapidly iterate over new ideas. The success of artificial intelligence algorithms in real-time strategy games such as StarCraft II have also attracted the attention of the military research community aiming to explore similar techniques in military counterpart scenarios. Aiming to bridge the connection between games and military applications, this work discusses past and current efforts on how games and simulators, together with the artificial intelligence algorithms, have been adapted to simulate certain aspects of military missions and how they might impact the future battlefield. This paper also investigates how advances in virtual reality and visual augmentation systems open new possibilities in human interfaces with gaming platforms and their military parallels.
Biologically Plausible Learning Rules for Perceptual Systems that Maximize Mutual Information
Sep 07, 2021It is widely believed that the perceptual system of an organism is optimized for the properties of the environment to which it is exposed. A specific instance of this principle known as the Infomax principle holds that the purpose of early perceptual processing is to maximize the mutual information between the neural coding and the incoming sensory signal. In this article, we show a model to implement this principle accurately with spatio-temporal local, spike-based, and continuous-time learning rules.