 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross-Layered Distributed Data-driven Framework For Enhanced Smart Grid Cyber-Physical Security
Nov 10, 2021
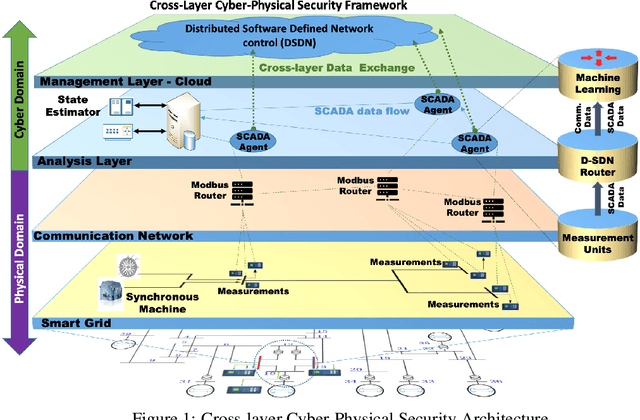
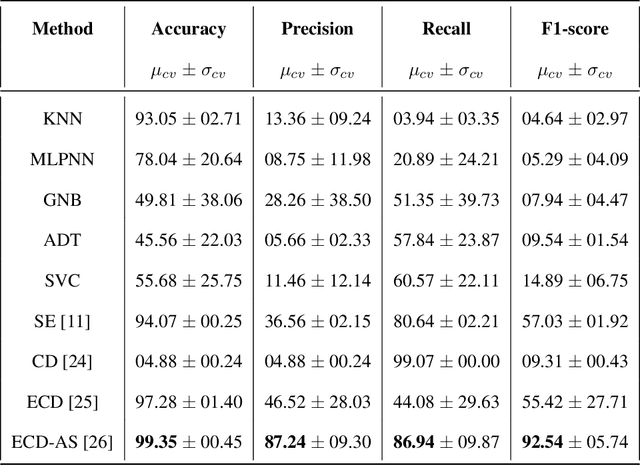
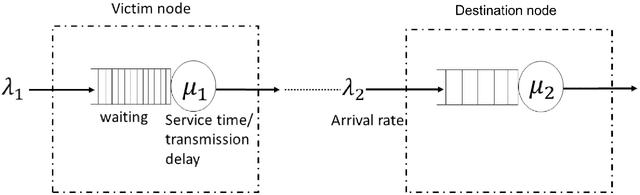
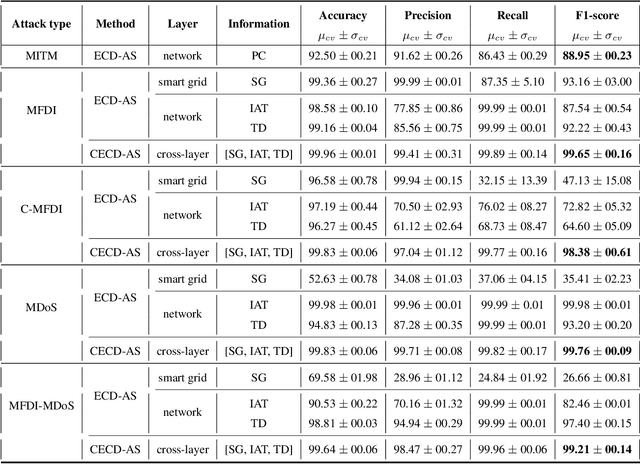
Smart Grid (SG) research and development has drawn much attention from academia, industry and government due to the great impact it will have on society, economics and the environment. Securing the SG is a considerably significant challenge due the increased dependency on communication networks to assist in physical process control, exposing them to various cyber-threats. In addition to attacks that change measurement values using False Data Injection (FDI) techniques, attacks on the communication network may disrupt the power system's real-time operation by intercepting messages, or by flooding the communication channels with unnecessary data. Addressing these attacks requires a cross-layer approach. In this paper a cross-layered strategy is presented, called Cross-Layer Ensemble CorrDet with Adaptive Statistics(CECD-AS), which integrates the detection of faulty SG measurement data as well as inconsistent network inter-arrival times and transmission delays for more reliable and accurate anomaly detection and attack interpretation. Numerical results show that CECD-AS can detect multiple False Data Injections, Denial of Service (DoS) and Man In The Middle (MITM) attacks with a high F1-score compared to current approaches that only use SG measurement data for detection such as the traditional physics-based State Estimation, Ensemble CorrDet with Adaptive Statistics strategy and other machine learning classification-based detection schemes.
Span Fine-tuning for Pre-trained Language Models
Aug 29, 2021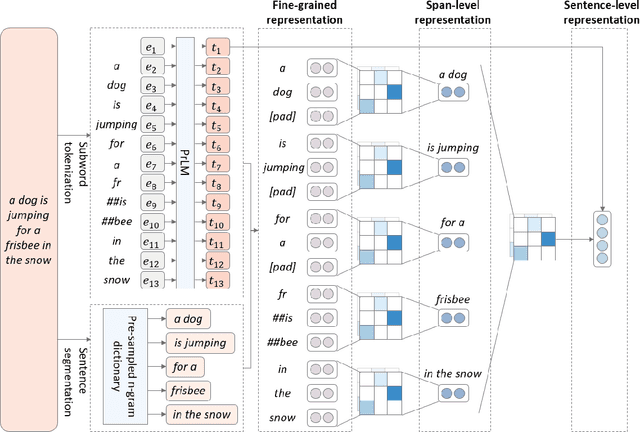
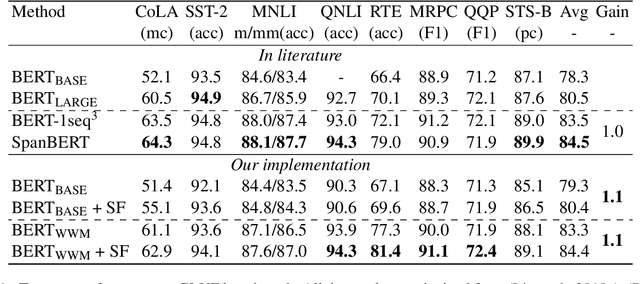

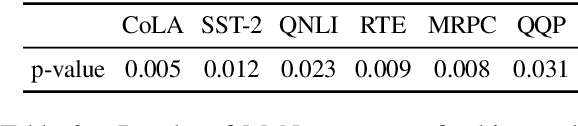
Pre-trained language models (PrLM) have to carefully manage input units when training on a very large text with a vocabulary consisting of millions of words. Previous works have shown that incorporating span-level information over consecutive words in pre-training could further improve the performance of PrLMs. However, given that span-level clues are introduced and fixed in pre-training, previous methods are time-consuming and lack of flexibility. To alleviate the inconvenience, this paper presents a novel span fine-tuning method for PrLMs, which facilitates the span setting to be adaptively determined by specific downstream tasks during the fine-tuning phase. In detail, any sentences processed by the PrLM will be segmented into multiple spans according to a pre-sampled dictionary. Then the segmentation information will be sent through a hierarchical CNN module together with the representation outputs of the PrLM and ultimately generate a span-enhanced representation. Experiments on GLUE benchmark show that the proposed span fine-tuning method significantly enhances the PrLM, and at the same time, offer more flexibility in an efficient way.
Deep Learning of Potential Outcomes
Oct 09, 2021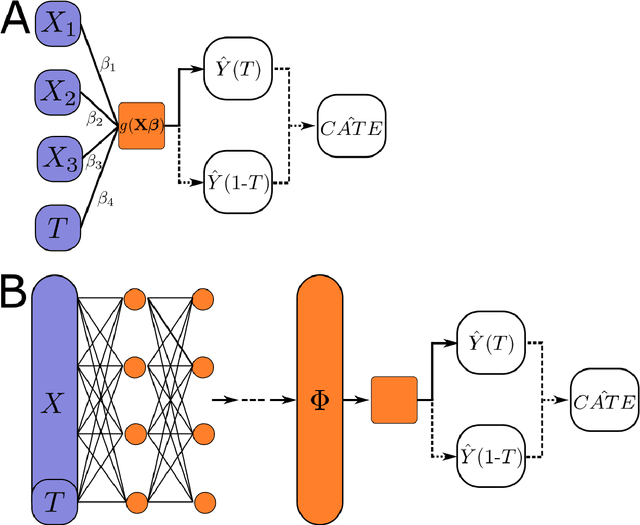
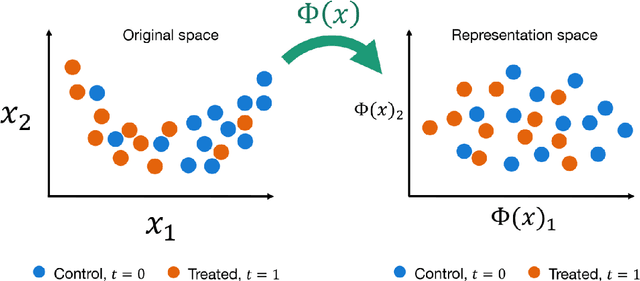
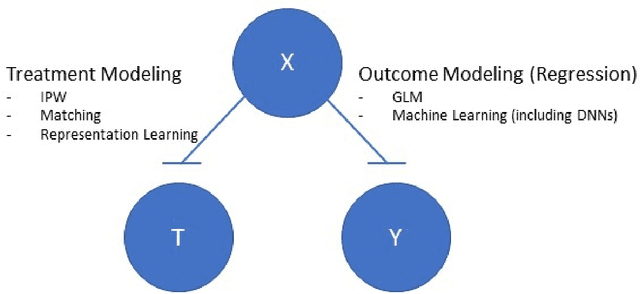
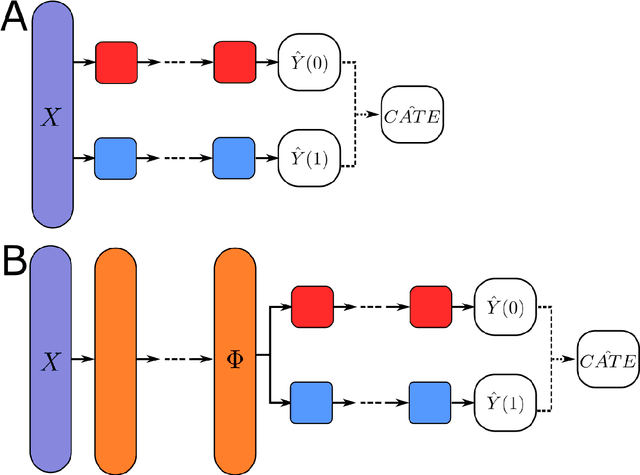
This review systematizes the emerging literature for causal inference using deep neural networks under the potential outcomes framework. It provides an intuitive introduction on how deep learning can be used to estimate/predict heterogeneous treatment effects and extend causal inference to settings where confounding is non-linear, time varying, or encoded in text, networks, and images. To maximize accessibility, we also introduce prerequisite concepts from causal inference and deep learning. The survey differs from other treatments of deep learning and causal inference in its sharp focus on observational causal estimation, its extended exposition of key algorithms, and its detailed tutorials for implementing, training, and selecting among deep estimators in Tensorflow 2 available at github.com/kochbj/Deep-Learning-for-Causal-Inference.
A Performance-Explainability Framework to Benchmark Machine Learning Methods: Application to Multivariate Time Series Classifiers
May 29, 2020

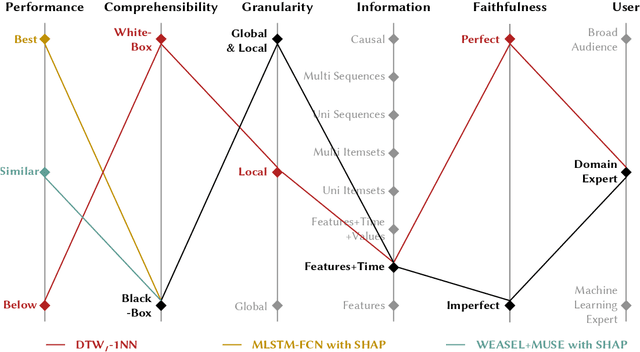
Our research aims to propose a new performance-explainability analytical framework to assess and benchmark machine learning methods. The framework details a set of characteristics that operationalize the performance-explainability assessment of existing machine learning methods. In order to illustrate the use of the framework, we apply it to benchmark the current state-of-the-art multivariate time series classifiers.
Longitudinal Analysis of Mask and No-Mask on Child Face Recognition
Nov 19, 2021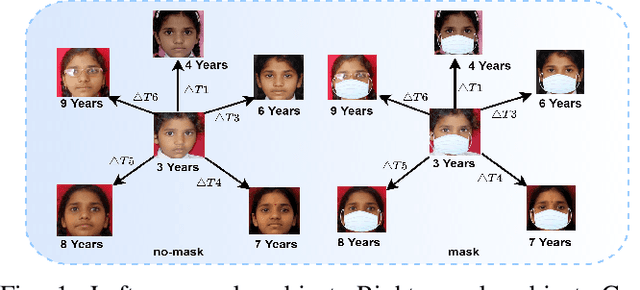
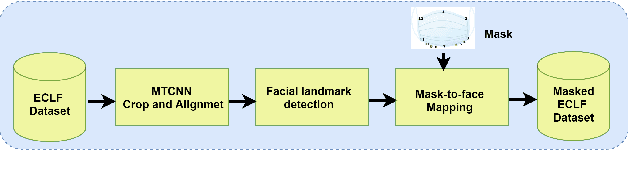
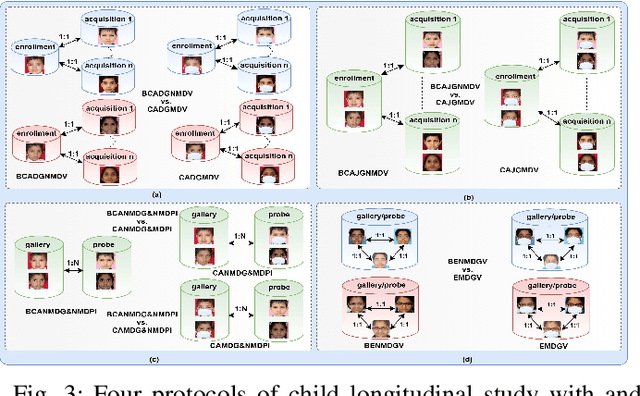
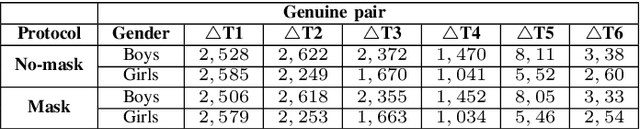
Face is one of the most widely employed traits for person recognition, even in many large-scale applications. Despite technological advancements in face recognition systems, they still face obstacles caused by pose, expression, occlusion, and aging variations. Owing to the COVID-19 pandemic, contactless identity verification has become exceedingly vital. To constrain the pandemic, people have started using face mask. Recently, few studies have been conducted on the effect of face mask on adult face recognition systems. However, the impact of aging with face mask on child subject recognition has not been adequately explored. Thus, the main objective of this study is analyzing the child longitudinal impact together with face mask and other covariates on face recognition systems. Specifically, we performed a comparative investigation of three top performing publicly available face matchers and a post-COVID-19 commercial-off-the-shelf (COTS) system under child cross-age verification and identification settings using our generated synthetic mask and no-mask samples. Furthermore, we investigated the longitudinal consequence of eyeglasses with mask and no-mask. The study exploited no-mask longitudinal child face dataset (i.e., extended Indian Child Longitudinal Face Dataset) that contains $26,258$ face images of $7,473$ subjects in the age group of $[2, 18]$ over an average time span of $3.35$ years. Due to the combined effects of face mask and face aging, the FaceNet, PFE, ArcFace, and COTS face verification system accuracies decrease approximately $25\%$, $22\%$, $18\%$, $12\%$, respectively.
Highly Scalable and Provably Accurate Classification in Poincare Balls
Sep 15, 2021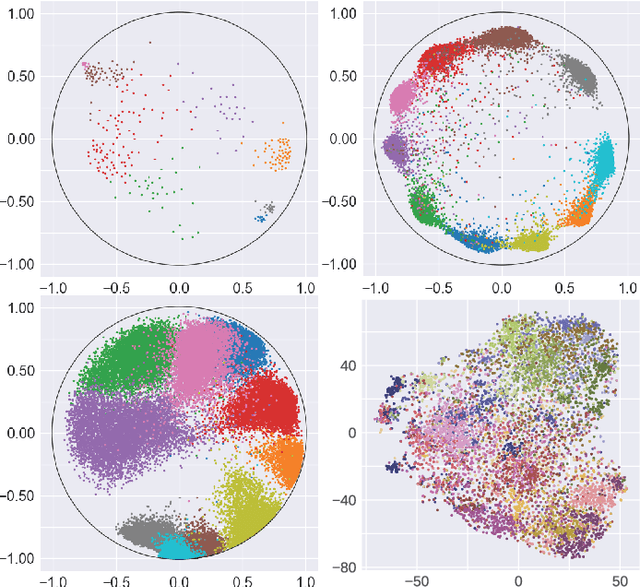
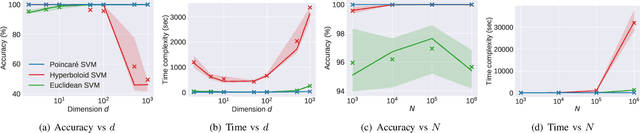
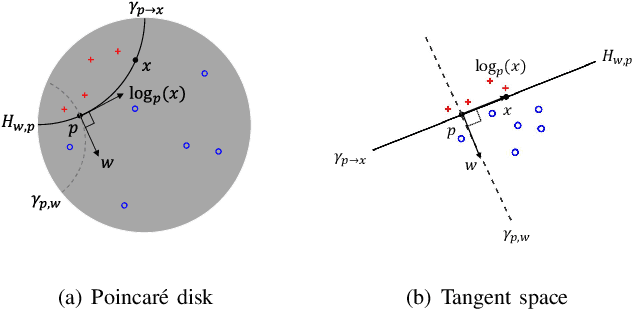
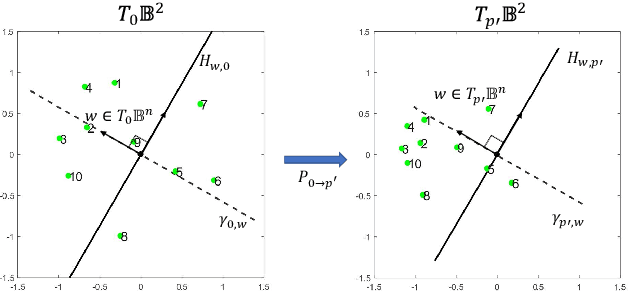
Many high-dimensional and large-volume data sets of practical relevance have hierarchical structures induced by trees, graphs or time series. Such data sets are hard to process in Euclidean spaces and one often seeks low-dimensional embeddings in other space forms to perform required learning tasks. For hierarchical data, the space of choice is a hyperbolic space since it guarantees low-distortion embeddings for tree-like structures. Unfortunately, the geometry of hyperbolic spaces has properties not encountered in Euclidean spaces that pose challenges when trying to rigorously analyze algorithmic solutions. Here, for the first time, we establish a unified framework for learning scalable and simple hyperbolic linear classifiers with provable performance guarantees. The gist of our approach is to focus on Poincar\'e ball models and formulate the classification problems using tangent space formalisms. Our results include a new hyperbolic and second-order perceptron algorithm as well as an efficient and highly accurate convex optimization setup for hyperbolic support vector machine classifiers. All algorithms provably converge and are highly scalable as they have complexities comparable to those of their Euclidean counterparts. Their performance accuracies on synthetic data sets comprising millions of points, as well as on complex real-world data sets such as single-cell RNA-seq expression measurements, CIFAR10, Fashion-MNIST and mini-ImageNet.
Robust Neural Regression via Uncertainty Learning
Oct 12, 2021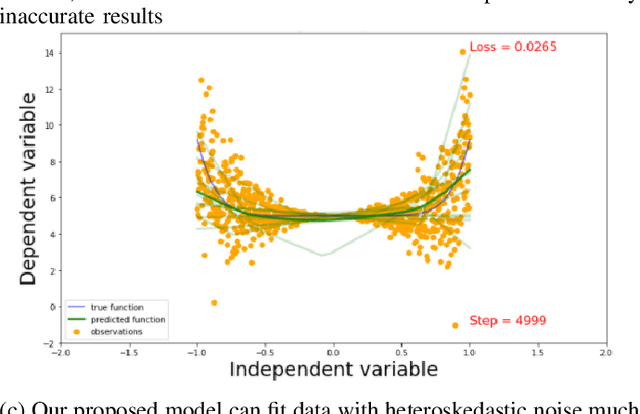
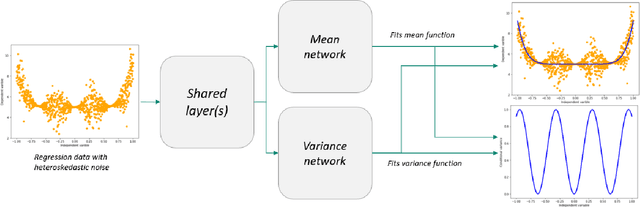
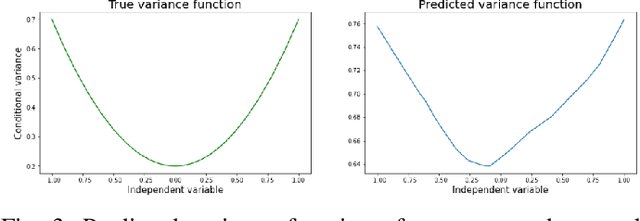
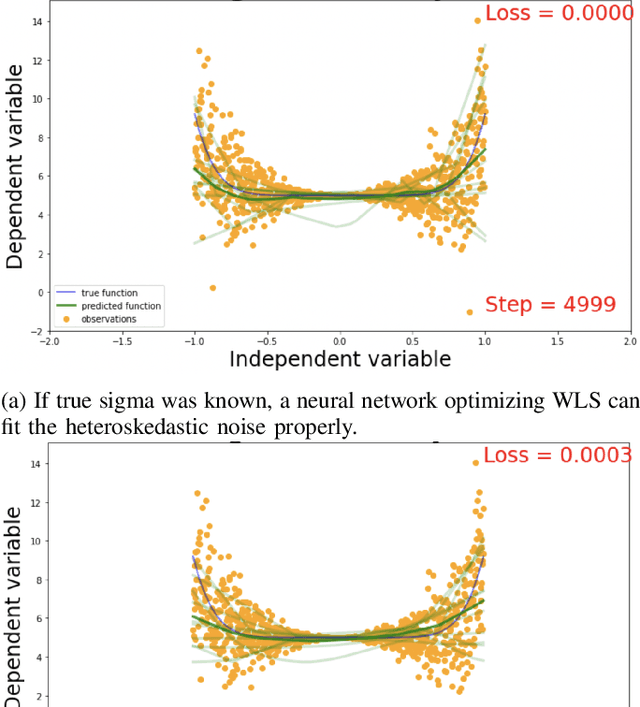
Deep neural networks tend to underestimate uncertainty and produce overly confident predictions. Recently proposed solutions, such as MC Dropout and SDENet, require complex training and/or auxiliary out-of-distribution data. We propose a simple solution by extending the time-tested iterative reweighted least square (IRLS) in generalised linear regression. We use two sub-networks to parametrise the prediction and uncertainty estimation, enabling easy handling of complex inputs and nonlinear response. The two sub-networks have shared representations and are trained via two complementary loss functions for the prediction and the uncertainty estimates, with interleaving steps as in a cooperative game. Compared with more complex models such as MC-Dropout or SDE-Net, our proposed network is simpler to implement and more robust (insensitive to varying aleatoric and epistemic uncertainty).
Swarm intelligence algorithms applied to Virtual Reference Feedback Tuning to increase controller robustness -- a one-shot technique
Nov 04, 2021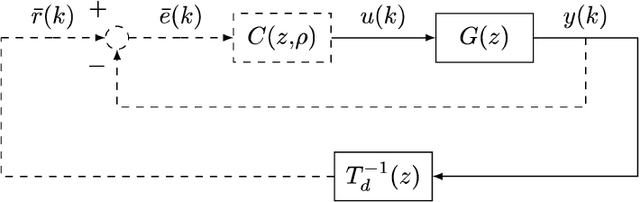

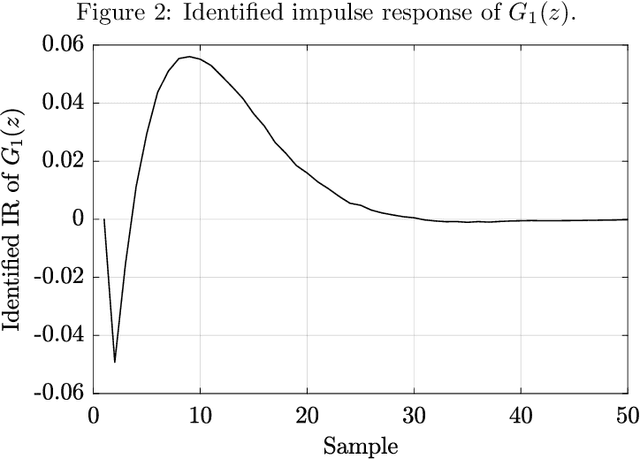

This work presents a data-driven one-shot method for increasing robustness of a discrete-time closed-loop system by changing the controller parameters using swarm intelligence algorithms. Four swarm intelligence algorithms - Particle Swarm Optimization (PSO), Artificial Bee Colony (ABC), Grey Wolf Optimization (GWO), and Improved Grey Wolf Optimization (I-GWO) - are described. Data-driven controller design is commented, focusing on the Virtual Reference Feedback Tuning (VRFT) algorithms. The estimation of the $\mathcal{H}_{\infty}$ norm of $S(z)$ via impulse response is presented. Two illustrative real-world based examples, regarding a Boost-like second order plant and a SEPIC-like fourth order plant, are tested for all commented swarm intelligence algorithms with the proposed method. Each algorithm at each case was run for 50 times, with 100 search agents, and maximum number of iterations limited to 100. For both examples, I-GWO presented the the best desired behavior, with the least number of outliers and no bad outlier in terms of fitness and $||S(z)||_{\infty}$ norm, as well as faster convergence, lowering the $||S(z)||_{\infty}$ norm of the plant from values greater than 2.0 to 1.8, still maintaining a low fitness value.
Sparsely Changing Latent States for Prediction and Planning in Partially Observable Domains
Oct 29, 2021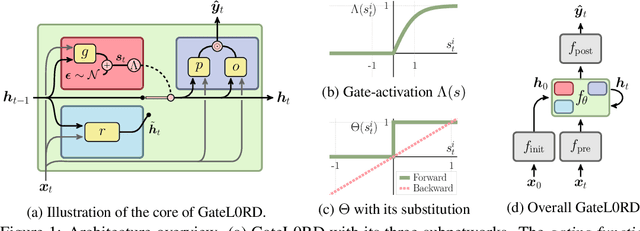
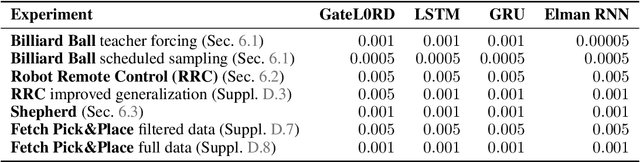
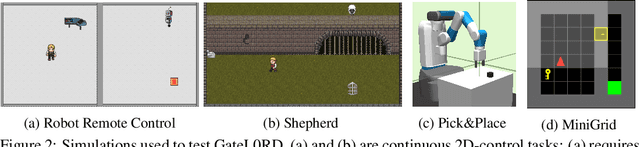

A common approach to prediction and planning in partially observable domains is to use recurrent neural networks (RNNs), which ideally develop and maintain a latent memory about hidden, task-relevant factors. We hypothesize that many of these hidden factors in the physical world are constant over time, changing only sparsely. Accordingly, we propose Gated $L_0$ Regularized Dynamics (GateL0RD), a novel recurrent architecture that incorporates the inductive bias to maintain stable, sparsely changing latent states. The bias is implemented by means of a novel internal gating function and a penalty on the $L_0$ norm of latent state changes. We demonstrate that GateL0RD can compete with or outperform state-of-the-art RNNs in a variety of partially observable prediction and control tasks. GateL0RD tends to encode the underlying generative factors of the environment, ignores spurious temporal dependencies, and generalizes better, improving sampling efficiency and prediction accuracy as well as behavior in model-based planning and reinforcement learning tasks. Moreover, we show that the developing latent states can be easily interpreted, which is a step towards better explainability in RNNs.
Binary classification of spoken words with passive elastic metastructures
Nov 14, 2021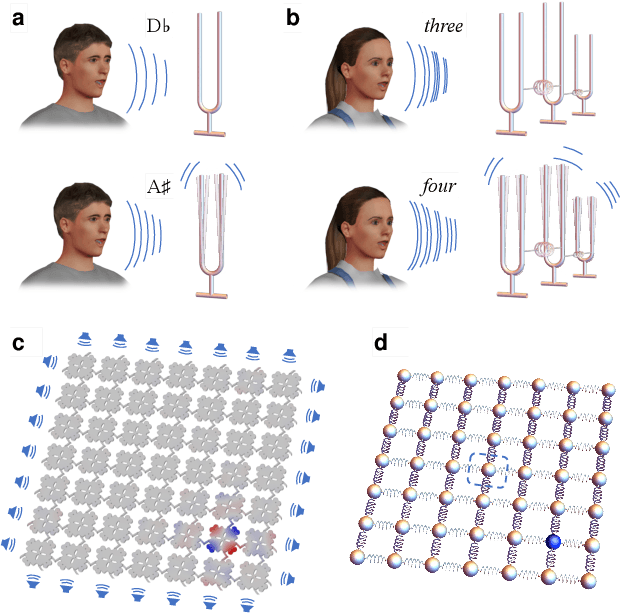
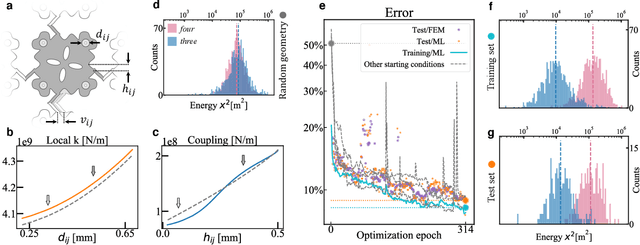
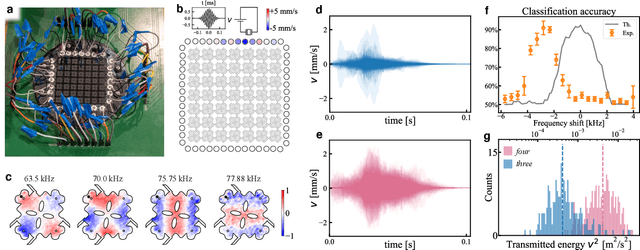
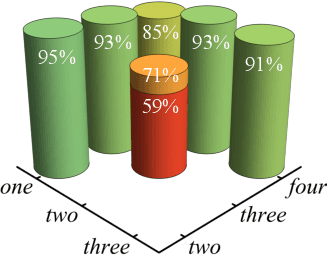
Many electronic devices spend most of their time waiting for a wake-up event: pacemakers waiting for an anomalous heartbeat, security systems on alert to detect an intruder, smartphones listening for the user to say a wake-up phrase. These devices continuously convert physical signals into electrical currents that are then analyzed on a digital computer -- leading to power consumption even when no event is taking place. Solving this problem requires the ability to passively distinguish relevant from irrelevant events (e.g. tell a wake-up phrase from a regular conversation). Here, we experimentally demonstrate an elastic metastructure, consisting of a network of coupled silicon resonators, that passively discriminates between pairs of spoken words -- solving the wake-up problem for scenarios where only two classes of events are possible. This passive speech recognition is demonstrated on a dataset from speakers with significant gender and accent diversity. The geometry of the metastructure is determined during the design process, in which the network of resonators ('mechanical neurones') learns to selectively respond to spoken words. Training is facilitated by a machine learning model that reduces the number of computationally expensive three-dimensional elastic wave simulations. By embedding event detection in the structural dynamics, mechanical neural networks thus enable novel classes of always-on smart devices with no standby power consumption.