 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Future of AI with AI: High-quality link prediction in an exponentially growing knowledge network
Sep 23, 2022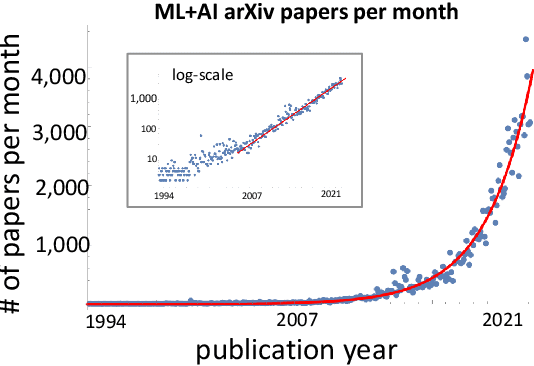
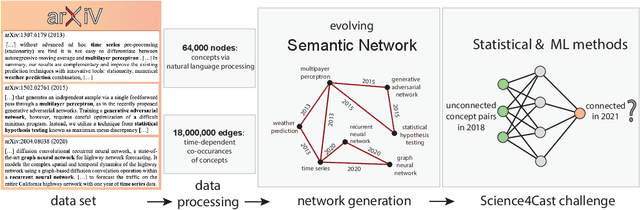
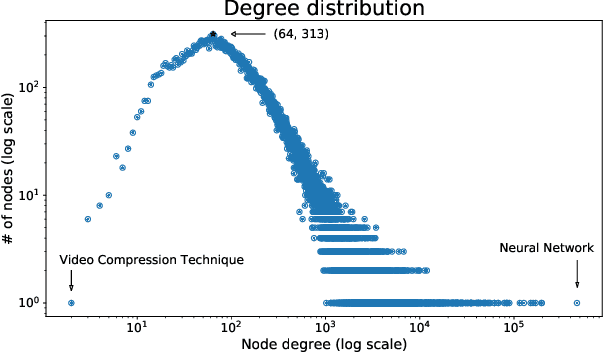
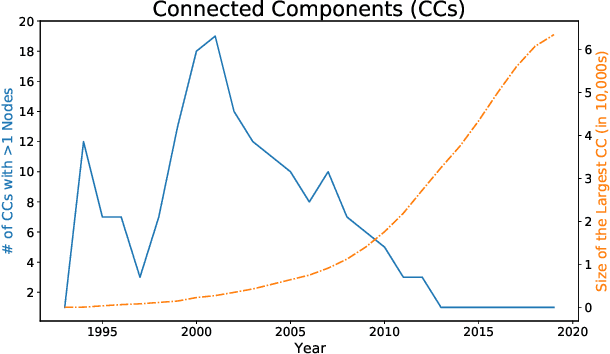
A tool that could suggest new personalized research directions and ideas by taking insights from the scientific literature could significantly accelerate the progress of science. A field that might benefit from such an approach is artificial intelligence (AI) research, where the number of scientific publications has been growing exponentially over the last years, making it challenging for human researchers to keep track of the progress. Here, we use AI techniques to predict the future research directions of AI itself. We develop a new graph-based benchmark based on real-world data -- the Science4Cast benchmark, which aims to predict the future state of an evolving semantic network of AI. For that, we use more than 100,000 research papers and build up a knowledge network with more than 64,000 concept nodes. We then present ten diverse methods to tackle this task, ranging from pure statistical to pure learning methods. Surprisingly, the most powerful methods use a carefully curated set of network features, rather than an end-to-end AI approach. It indicates a great potential that can be unleashed for purely ML approaches without human knowledge. Ultimately, better predictions of new future research directions will be a crucial component of more advanced research suggestion tools.
Deep Learning of Potential Outcomes
Oct 09, 2021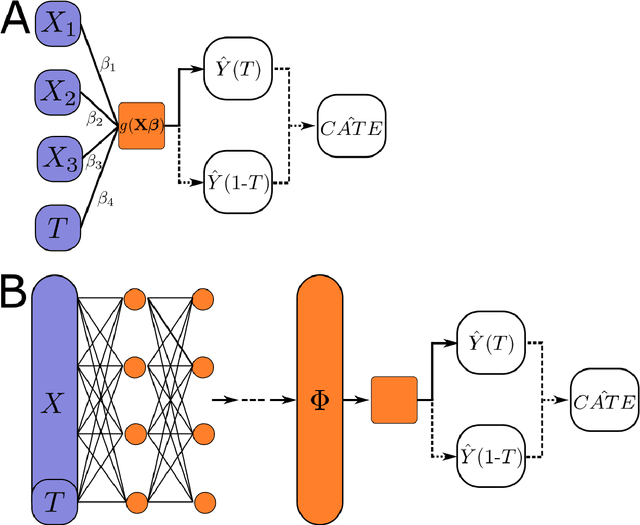
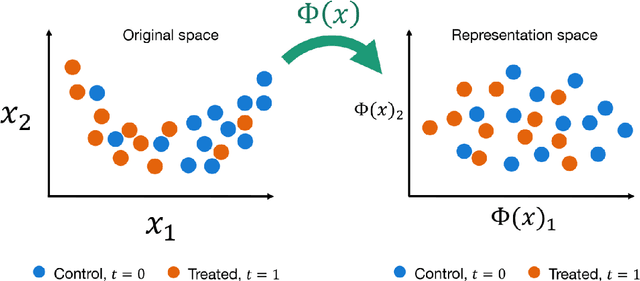
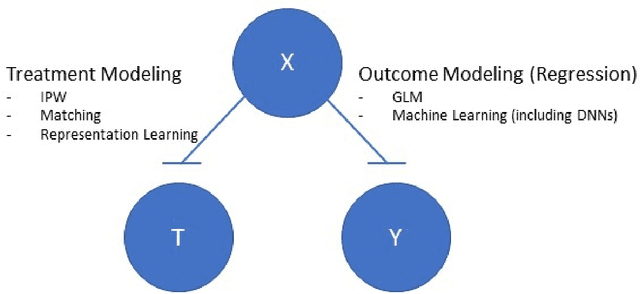
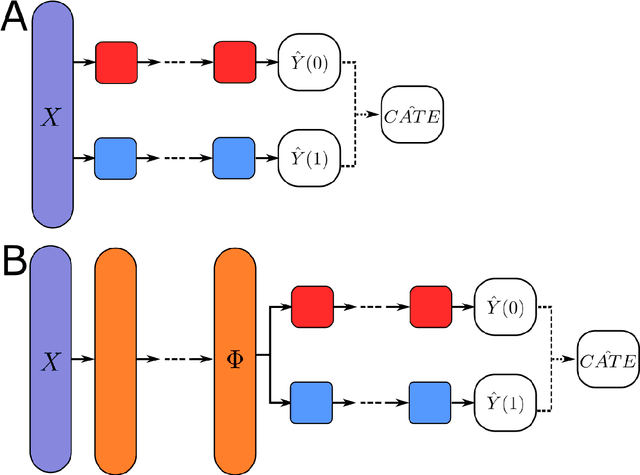
This review systematizes the emerging literature for causal inference using deep neural networks under the potential outcomes framework. It provides an intuitive introduction on how deep learning can be used to estimate/predict heterogeneous treatment effects and extend causal inference to settings where confounding is non-linear, time varying, or encoded in text, networks, and images. To maximize accessibility, we also introduce prerequisite concepts from causal inference and deep learning. The survey differs from other treatments of deep learning and causal inference in its sharp focus on observational causal estimation, its extended exposition of key algorithms, and its detailed tutorials for implementing, training, and selecting among deep estimators in Tensorflow 2 available at github.com/kochbj/Deep-Learning-for-Causal-Inference.
Integrating topic modeling and word embedding to characterize violent deaths
Jun 28, 2021
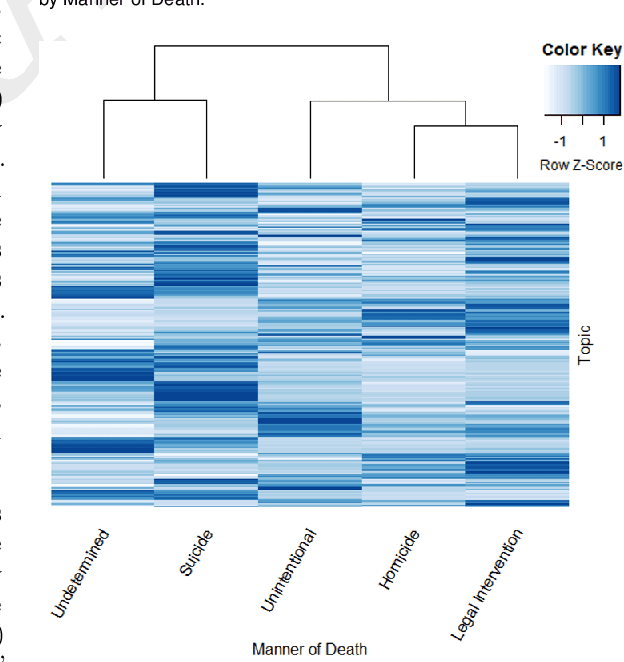
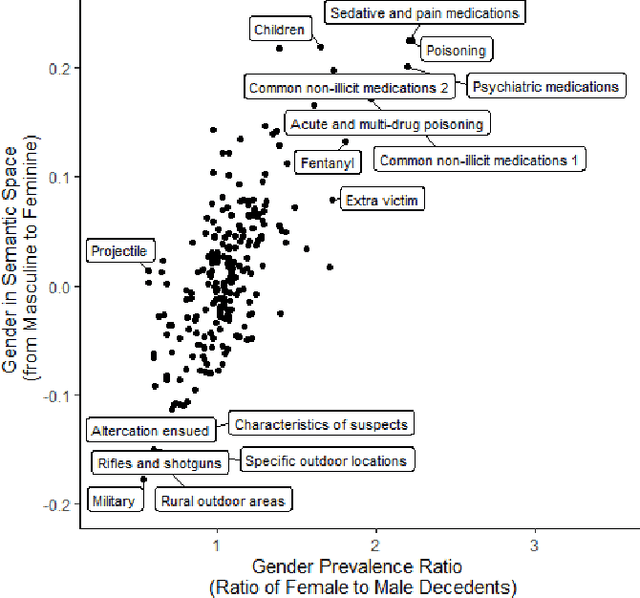
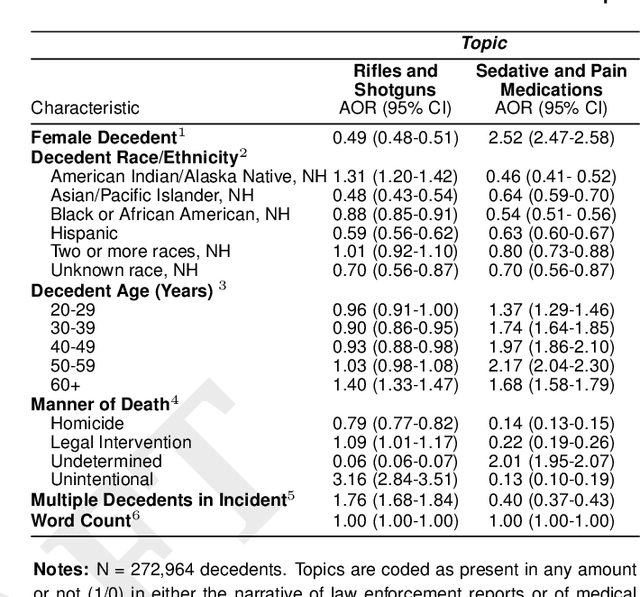
There is an escalating need for methods to identify latent patterns in text data from many domains. We introduce a new method to identify topics in a corpus and represent documents as topic sequences. Discourse Atom Topic Modeling draws on advances in theoretical machine learning to integrate topic modeling and word embedding, capitalizing on the distinct capabilities of each. We first identify a set of vectors ("discourse atoms") that provide a sparse representation of an embedding space. Atom vectors can be interpreted as latent topics: Through a generative model, atoms map onto distributions over words; one can also infer the topic that generated a sequence of words. We illustrate our method with a prominent example of underutilized text: the U.S. National Violent Death Reporting System (NVDRS). The NVDRS summarizes violent death incidents with structured variables and unstructured narratives. We identify 225 latent topics in the narratives (e.g., preparation for death and physical aggression); many of these topics are not captured by existing structured variables. Motivated by known patterns in suicide and homicide by gender, and recent research on gender biases in semantic space, we identify the gender bias of our topics (e.g., a topic about pain medication is feminine). We then compare the gender bias of topics to their prevalence in narratives of female versus male victims. Results provide a detailed quantitative picture of reporting about lethal violence and its gendered nature. Our method offers a flexible and broadly applicable approach to model topics in text data.