 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GenReg: Deep Generative Method for Fast Point Cloud Registration
Nov 23, 2021
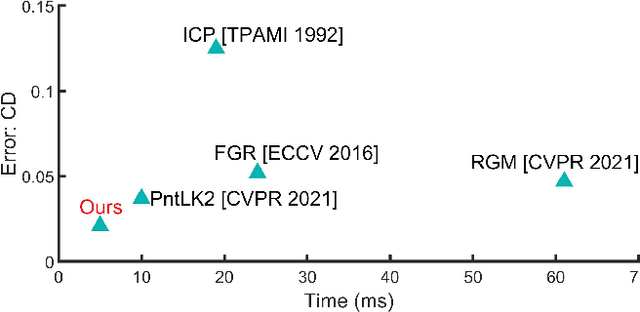
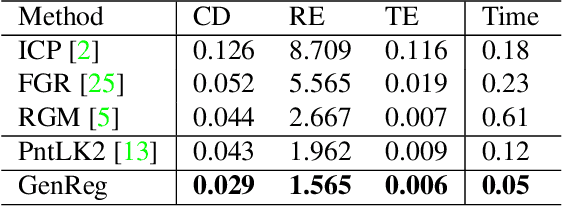


Accurate and efficient point cloud registration is a challenge because the noise and a large number of points impact the correspondence search. This challenge is still a remaining research problem since most of the existing methods rely on correspondence search. To solve this challenge, we propose a new data-driven registration algorithm by investigating deep generative neural networks to point cloud registration. Given two point clouds, the motivation is to generate the aligned point clouds directly, which is very useful in many applications like 3D matching and search. We design an end-to-end generative neural network for aligned point clouds generation to achieve this motivation, containing three novel components. Firstly, a point multi-perception layer (MLP) mixer (PointMixer) network is proposed to efficiently maintain both the global and local structure information at multiple levels from the self point clouds. Secondly, a feature interaction module is proposed to fuse information from cross point clouds. Thirdly, a parallel and differential sample consensus method is proposed to calculate the transformation matrix of the input point clouds based on the generated registration results. The proposed generative neural network is trained in a GAN framework by maintaining the data distribution and structure similarity. The experiments on both ModelNet40 and 7Scene datasets demonstrate that the proposed algorithm achieves state-of-the-art accuracy and efficiency. Notably, our method reduces $2\times$ in registration error (CD) and $12\times$ running time compared to the state-of-the-art correspondence-based algorithm.
ABIDES-Gym: Gym Environments for Multi-Agent Discrete Event Simulation and Application to Financial Markets
Oct 27, 2021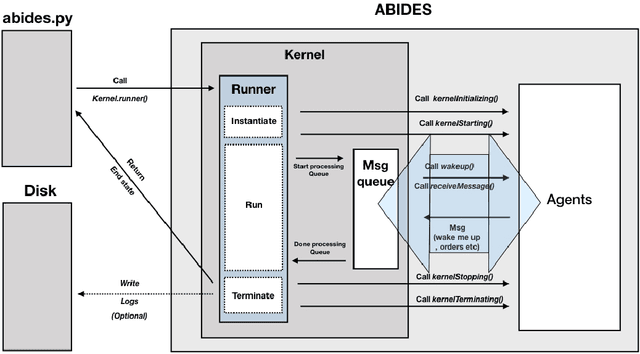
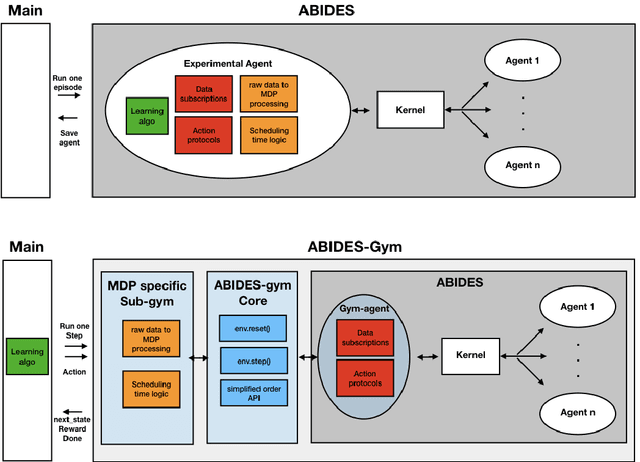
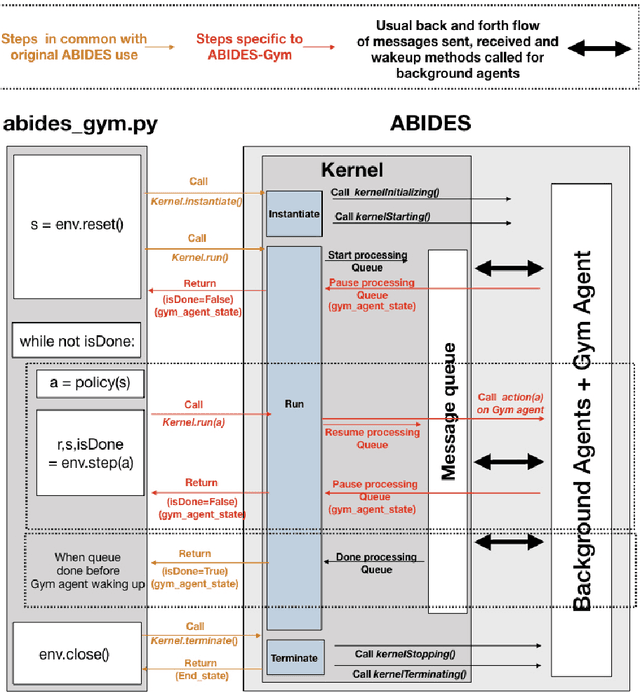
Model-free Reinforcement Learning (RL) requires the ability to sample trajectories by taking actions in the original problem environment or a simulated version of it. Breakthroughs in the field of RL have been largely facilitated by the development of dedicated open source simulators with easy to use frameworks such as OpenAI Gym and its Atari environments. In this paper we propose to use the OpenAI Gym framework on discrete event time based Discrete Event Multi-Agent Simulation (DEMAS). We introduce a general technique to wrap a DEMAS simulator into the Gym framework. We expose the technique in detail and implement it using the simulator ABIDES as a base. We apply this work by specifically using the markets extension of ABIDES, ABIDES-Markets, and develop two benchmark financial markets OpenAI Gym environments for training daily investor and execution agents. As a result, these two environments describe classic financial problems with a complex interactive market behavior response to the experimental agent's action.
On Kurtosis-limited Enumerative Sphere Shaping for Reach Increase in Single-span Systems
Aug 23, 2021
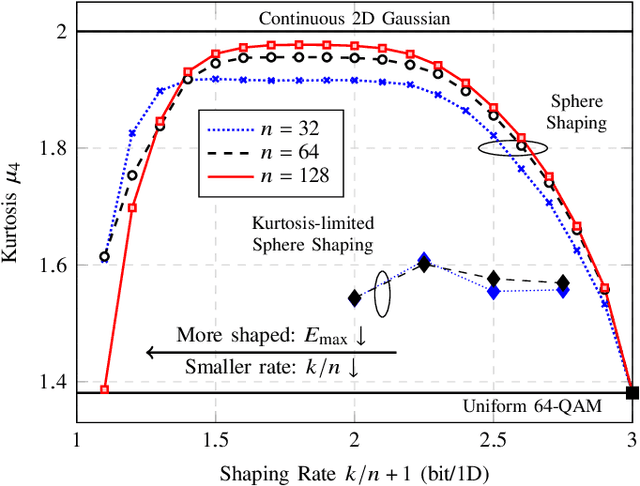
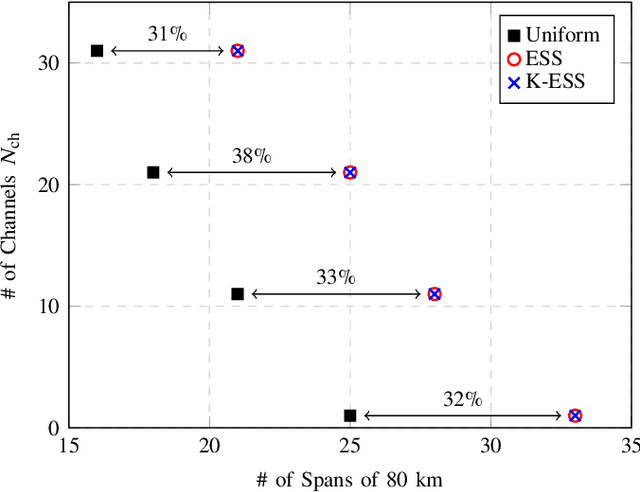
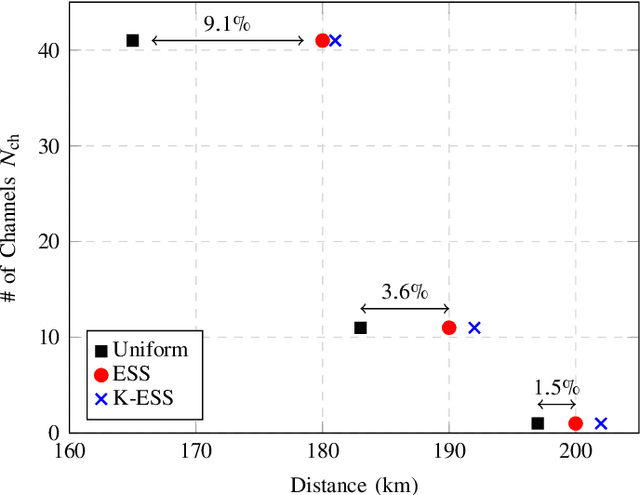
The effect of decreasing the kurtosis of channel inputs is investigated for the first time with an algorithmic shaping implementation. No significant gains in decoding performance are observed for multi-span systems, while an increase in reach is obtained for single-span transmission.
Vision Transformer for Classification of Breast Ultrasound Images
Oct 27, 2021
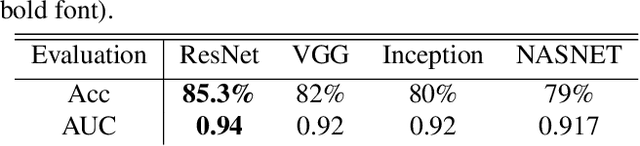
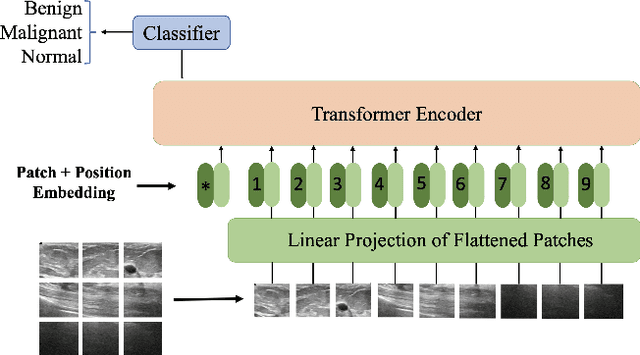

Medical ultrasound (US) imaging has become a prominent modality for breast cancer imaging due to its ease-of-use, low-cost and safety. In the past decade, convolutional neural networks (CNNs) have emerged as the method of choice in vision applications and have shown excellent potential in automatic classification of US images. Despite their success, their restricted local receptive field limits their ability to learn global context information. Recently, Vision Transformer (ViT) designs that are based on self-attention between image patches have shown great potential to be an alternative to CNNs. In this study, for the first time, we utilize ViT to classify breast US images using different augmentation strategies. The results are provided as classification accuracy and Area Under the Curve (AUC) metrics, and the performance is compared with the state-of-the-art CNNs. The results indicate that the ViT models have comparable efficiency with or even better than the CNNs in classification of US breast images.
Investigating Entropy for Extractive Document Summarization
Sep 30, 2021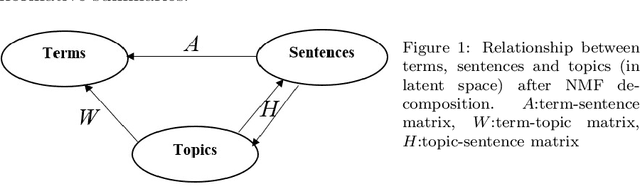

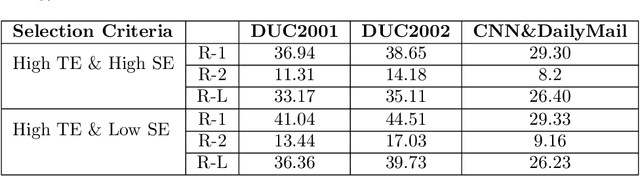
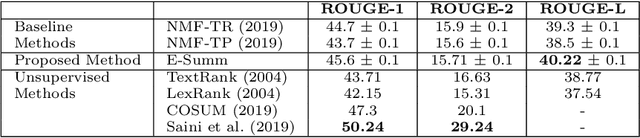
Automatic text summarization aims to cut down readers time and cognitive effort by reducing the content of a text document without compromising on its essence. Ergo, informativeness is the prime attribute of document summary generated by an algorithm, and selecting sentences that capture the essence of a document is the primary goal of extractive document summarization. In this paper, we employ Shannon entropy to capture informativeness of sentences. We employ Non-negative Matrix Factorization (NMF) to reveal probability distributions for computing entropy of terms, topics, and sentences in latent space. We present an information theoretic interpretation of the computed entropy, which is the bedrock of the proposed E-Summ algorithm, an unsupervised method for extractive document summarization. The algorithm systematically applies information theoretic principle for selecting informative sentences from important topics in the document. The proposed algorithm is generic and fast, and hence amenable to use for summarization of documents in real time. Furthermore, it is domain-, collection-independent and agnostic to the language of the document. Benefiting from strictly positive NMF factor matrices, E-Summ algorithm is transparent and explainable too. We use standard ROUGE toolkit for performance evaluation of the proposed method on four well known public data-sets. We also perform quantitative assessment of E-Summ summary quality by computing its semantic similarity w.r.t the original document. Our investigation reveals that though using NMF and information theoretic approach for document summarization promises efficient, explainable, and language independent text summarization, it needs to be bolstered to match the performance of deep neural methods.
Maximizing Efficiency of Language Model Pre-training for Learning Representation
Oct 13, 2021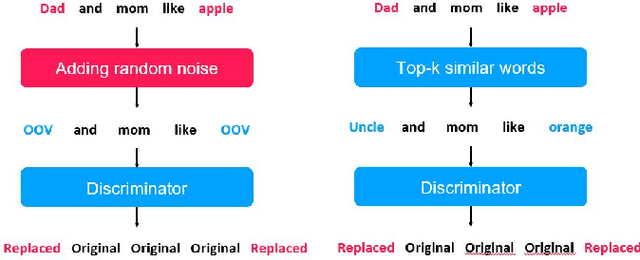
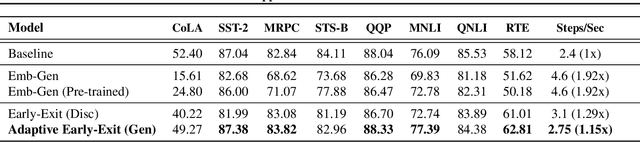
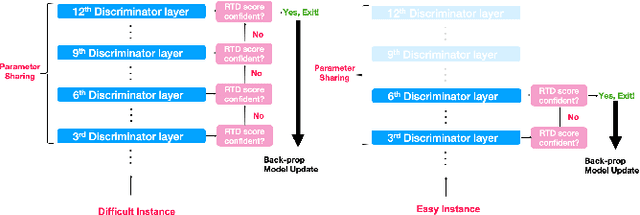
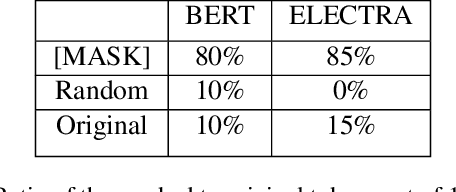
Pre-trained language models in the past years have shown exponential growth in model parameters and compute time. ELECTRA is a novel approach for improving the compute efficiency of pre-trained language models (e.g. BERT) based on masked language modeling (MLM) by addressing the sample inefficiency problem with the replaced token detection (RTD) task. Our work proposes adaptive early exit strategy to maximize the efficiency of the pre-training process by relieving the model's subsequent layers of the need to process latent features by leveraging earlier layer representations. Moreover, we evaluate an initial approach to the problem that has not succeeded in maintaining the accuracy of the model while showing a promising compute efficiency by thoroughly investigating the necessity of the generator module of ELECTRA.
Learning to Estimate Without Bias
Oct 24, 2021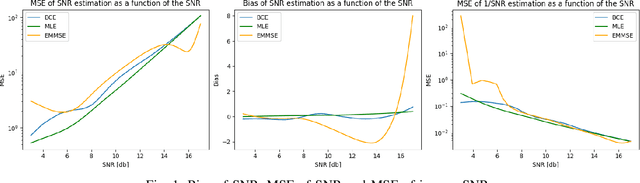
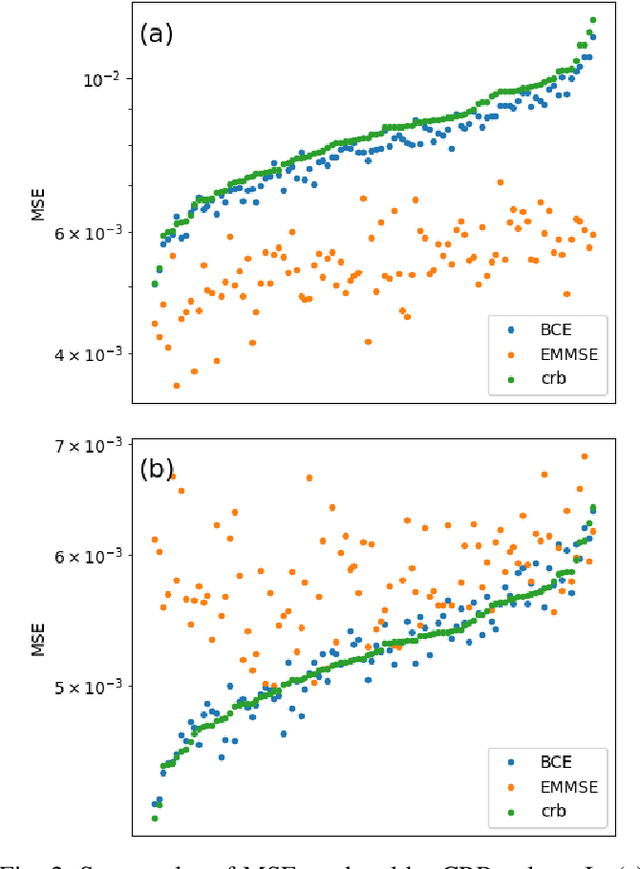
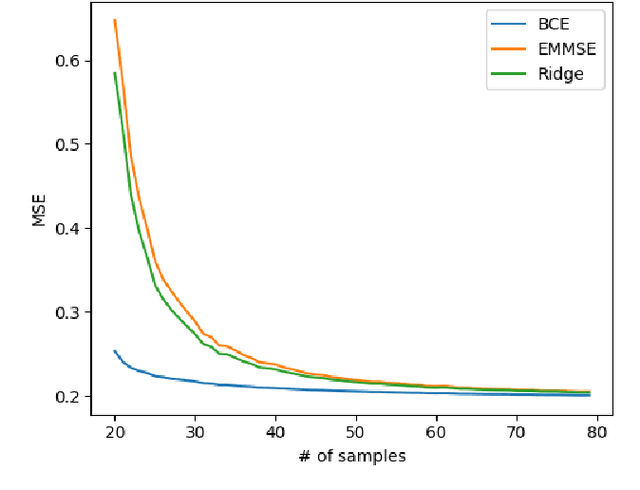
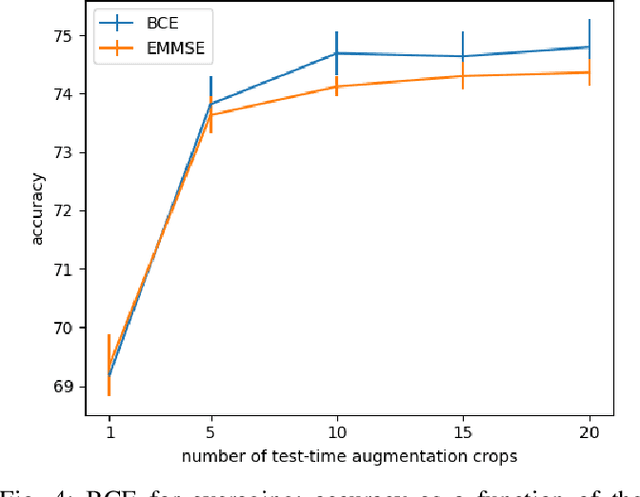
We consider the use of deep learning for parameter estimation. We propose Bias Constrained Estimators (BCE) that add a squared bias term to the standard mean squared error (MSE) loss. The main motivation to BCE is learning to estimate deterministic unknown parameters with no Bayesian prior. Unlike standard learning based estimators that are optimal on average, we prove that BCEs converge to Minimum Variance Unbiased Estimators (MVUEs). We derive closed form solutions to linear BCEs. These provide a flexible bridge between linear regrssion and the least squares method. In non-linear settings, we demonstrate that BCEs perform similarly to MVUEs even when the latter are computationally intractable. A second motivation to BCE is in applications where multiple estimates of the same unknown are averaged for improved performance. Examples include distributed sensor networks and data augmentation in test-time. In such applications, unbiasedness is a necessary condition for asymptotic consistency.
A big data intelligence marketplace and secure analytics experimentation platform for the aviation industry
Nov 18, 2021
The unprecedented volume, diversity and richness of aviation data that can be acquired, generated, stored, and managed provides unique capabilities for the aviation-related industries and pertains value that remains to be unlocked with the adoption of the innovative Big Data Analytics technologies. Despite the large efforts and investments on research and innovation, the Big Data technologies introduce a number of challenges to its adopters. Besides the effective storage and access to the underlying big data, efficient data integration and data interoperability should be considered, while at the same time multiple data sources should be effectively combined by performing data exchange and data sharing between the different stakeholders. However, this reveals additional challenges for the crucial preservation of the information security of the collected data, the trusted and secure data exchange and data sharing, as well as the robust data access control. The current paper aims to introduce the ICARUS big data-enabled platform that aims provide a multi-sided platform that offers a novel aviation data and intelligence marketplace accompanied by a trusted and secure analytics workspace. It holistically handles the complete big data lifecycle from the data collection, data curation and data exploration to the data integration and data analysis of data originating from heterogeneous data sources with different velocity, variety and volume in a trusted and secure manner.
A Secure Experimentation Sandbox for the design and execution of trusted and secure analytics in the aviation domain
Nov 18, 2021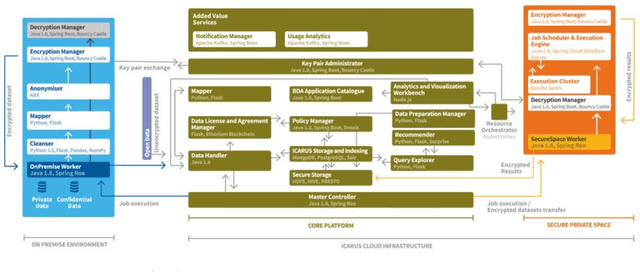
The aviation industry as well as the industries that benefit and are linked to it are ripe for innovation in the form of Big Data analytics. The number of available big data technologies is constantly growing, while at the same time the existing ones are rapidly evolving and empowered with new features. However, the Big Data era imposes the crucial challenge of how to effectively handle information security while managing massive and rapidly evolving data from heterogeneous data sources. While multiple technologies have emerged, there is a need to find a balance between multiple security requirements, privacy obligations, system performance and rapid dynamic analysis on large datasets. The current paper aims to introduce the ICARUS Secure Experimentation Sandbox of the ICARUS platform. The ICARUS platform aims to provide a big data-enabled platform that aspires to become an 'one-stop shop' for aviation data and intelligence marketplace that provides a trusted and secure 'sandboxed' analytics workspace, allowing the exploration, integration and deep analysis of original and derivative data in a trusted and fair manner. Towards this end, a Secure Experimentation Sandbox has been designed and integrated in the ICARUS platform offering, that enables the provisioning of a sophisticated environment that can completely guarantee the safety and confidentiality of data, allowing to any interested party to utilise the platform to conduct analytical experiments in closed-lab conditions.
End-to-end LSTM based estimation of volcano event epicenter localization
Oct 27, 2021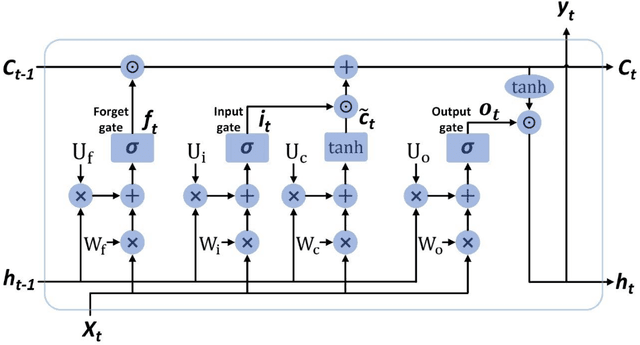
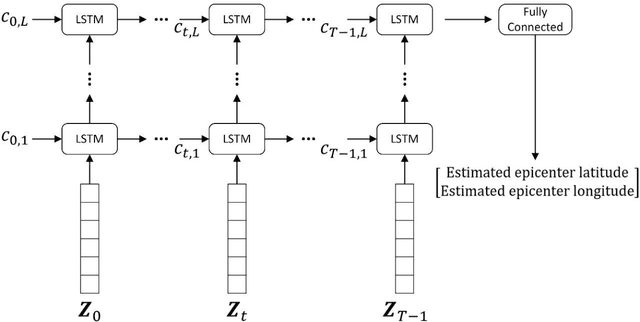
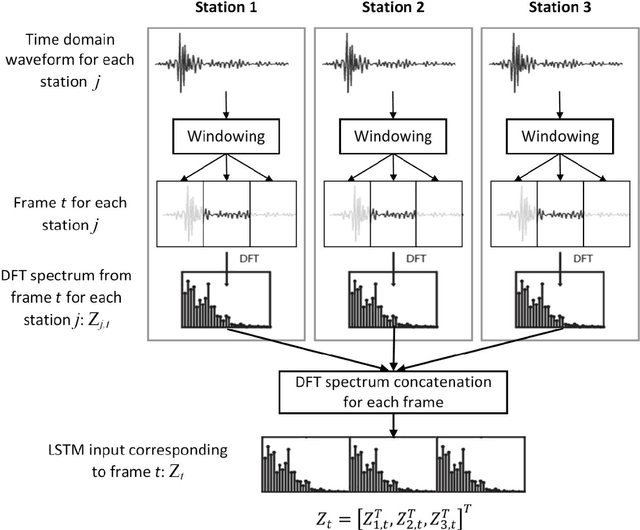
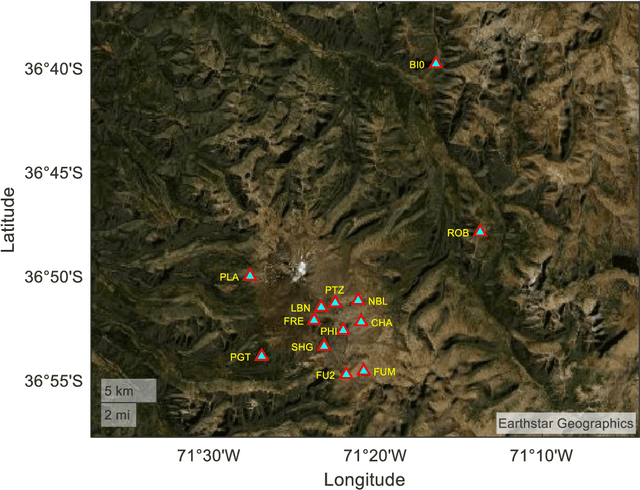
In this paper, an end-to-end based LSTM scheme is proposed to address the problem of volcano event localization without any a priori model relating phase picking with localization estimation. It is worth emphasizing that automatic phase picking in volcano signals is highly inaccurate because of the short distances between the event epicenters and the seismograph stations. LSTM was chosen due to its capability to capture the dynamics of time varying signals, and to remove or add information within the memory cell state and model long-term dependencies. A brief insight into LSTM is also discussed here. The results presented in this paper show that the LSTM based architecture provided a success rate, i.e., an error smaller than 1.0Km, equal to 48.5%, which in turn is dramatically superior to the one delivered by automatic phase picking. Moreover, the proposed end-to-end LSTM based method gave a success rate 18% higher than CNN.