 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MaIL: A Unified Mask-Image-Language Trimodal Network for Referring Image Segmentation
Nov 25, 2021
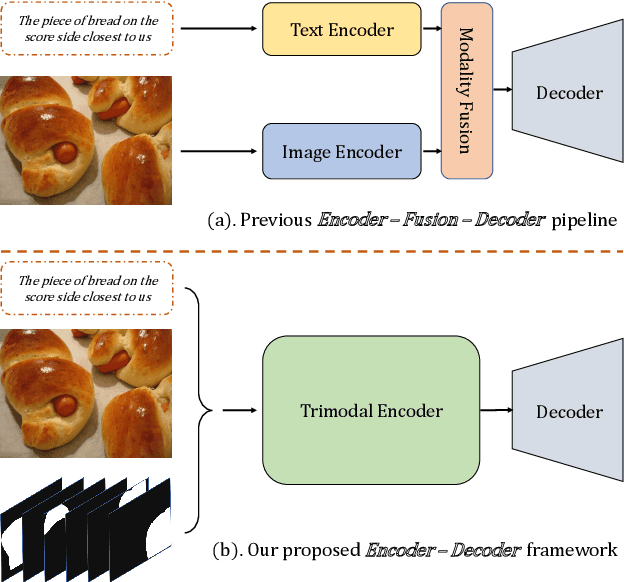
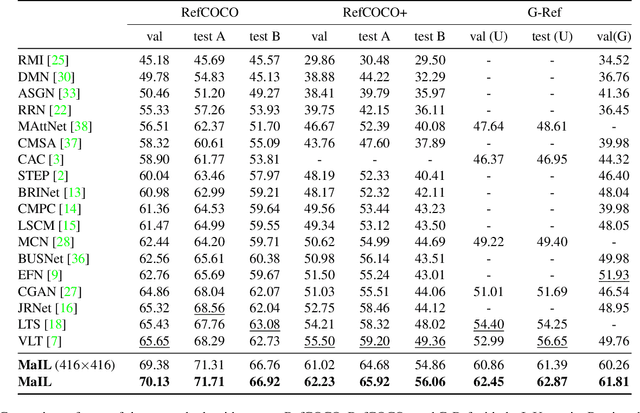
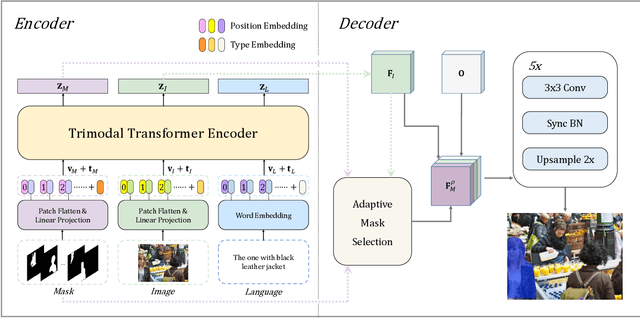
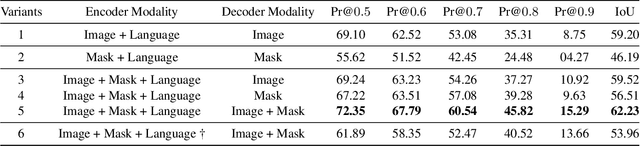
Referring image segmentation is a typical multi-modal task, which aims at generating a binary mask for referent described in given language expressions. Prior arts adopt a bimodal solution, taking images and languages as two modalities within an encoder-fusion-decoder pipeline. However, this pipeline is sub-optimal for the target task for two reasons. First, they only fuse high-level features produced by uni-modal encoders separately, which hinders sufficient cross-modal learning. Second, the uni-modal encoders are pre-trained independently, which brings inconsistency between pre-trained uni-modal tasks and the target multi-modal task. Besides, this pipeline often ignores or makes little use of intuitively beneficial instance-level features. To relieve these problems, we propose MaIL, which is a more concise encoder-decoder pipeline with a Mask-Image-Language trimodal encoder. Specifically, MaIL unifies uni-modal feature extractors and their fusion model into a deep modality interaction encoder, facilitating sufficient feature interaction across different modalities. Meanwhile, MaIL directly avoids the second limitation since no uni-modal encoders are needed anymore. Moreover, for the first time, we propose to introduce instance masks as an additional modality, which explicitly intensifies instance-level features and promotes finer segmentation results. The proposed MaIL set a new state-of-the-art on all frequently-used referring image segmentation datasets, including RefCOCO, RefCOCO+, and G-Ref, with significant gains, 3%-10% against previous best methods. Code will be released soon.
OSSEM: one-shot speaker adaptive speech enhancement using meta learning
Nov 10, 2021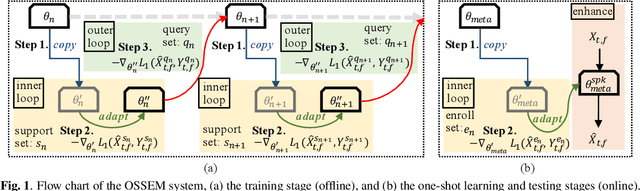
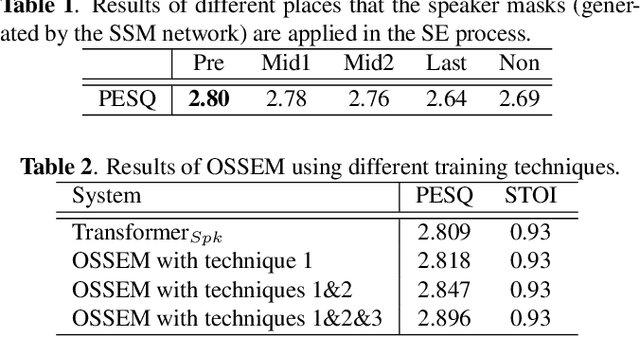
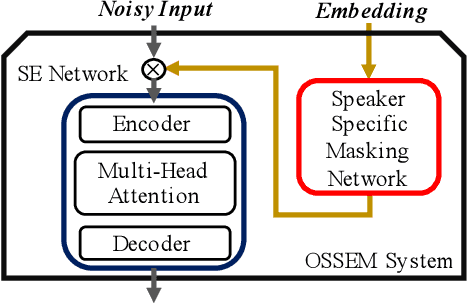
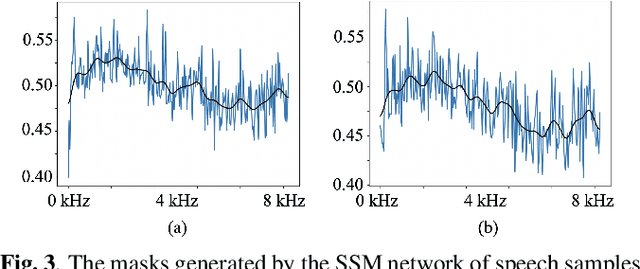
Although deep learning (DL) has achieved notable progress in speech enhancement (SE), further research is still required for a DL-based SE system to adapt effectively and efficiently to particular speakers. In this study, we propose a novel meta-learning-based speaker-adaptive SE approach (called OSSEM) that aims to achieve SE model adaptation in a one-shot manner. OSSEM consists of a modified transformer SE network and a speaker-specific masking (SSM) network. In practice, the SSM network takes an enrolled speaker embedding extracted using ECAPA-TDNN to adjust the input noisy feature through masking. To evaluate OSSEM, we designed a modified Voice Bank-DEMAND dataset, in which one utterance from the testing set was used for model adaptation, and the remaining utterances were used for testing the performance. Moreover, we set restrictions allowing the enhancement process to be conducted in real time, and thus designed OSSEM to be a causal SE system. Experimental results first show that OSSEM can effectively adapt a pretrained SE model to a particular speaker with only one utterance, thus yielding improved SE results. Meanwhile, OSSEM exhibits a competitive performance compared to state-of-the-art causal SE systems.
DECAF: Generating Fair Synthetic Data Using Causally-Aware Generative Networks
Nov 04, 2021
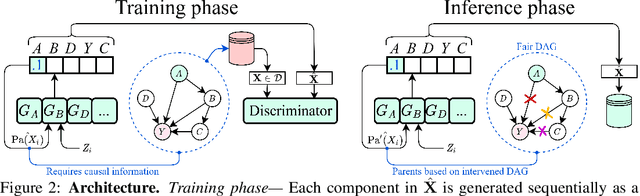
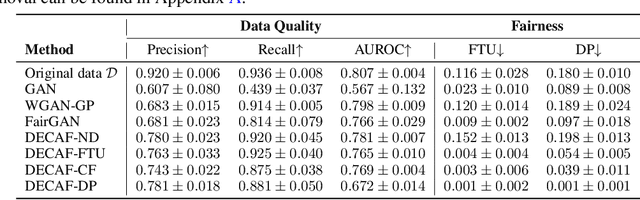
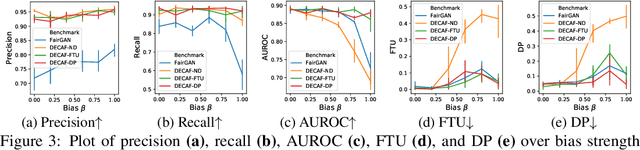
Machine learning models have been criticized for reflecting unfair biases in the training data. Instead of solving for this by introducing fair learning algorithms directly, we focus on generating fair synthetic data, such that any downstream learner is fair. Generating fair synthetic data from unfair data - while remaining truthful to the underlying data-generating process (DGP) - is non-trivial. In this paper, we introduce DECAF: a GAN-based fair synthetic data generator for tabular data. With DECAF we embed the DGP explicitly as a structural causal model in the input layers of the generator, allowing each variable to be reconstructed conditioned on its causal parents. This procedure enables inference time debiasing, where biased edges can be strategically removed for satisfying user-defined fairness requirements. The DECAF framework is versatile and compatible with several popular definitions of fairness. In our experiments, we show that DECAF successfully removes undesired bias and - in contrast to existing methods - is capable of generating high-quality synthetic data. Furthermore, we provide theoretical guarantees on the generator's convergence and the fairness of downstream models.
A Multi-criteria Approach to Evolve Sparse Neural Architectures for Stock Market Forecasting
Nov 15, 2021
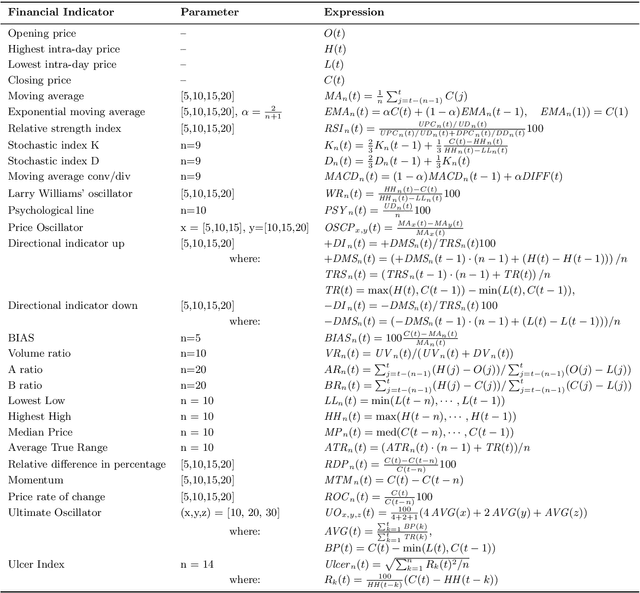
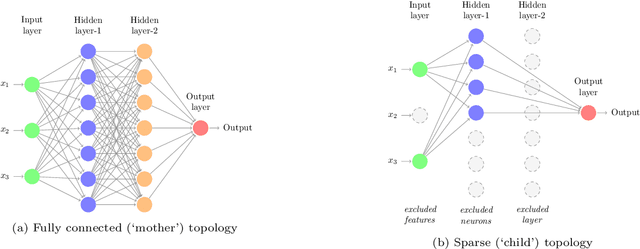
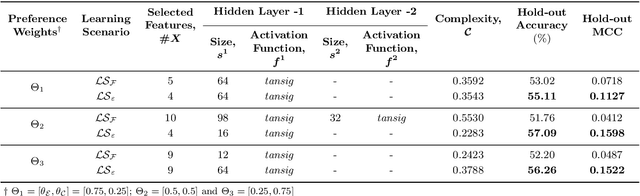
This study proposes a new framework to evolve efficacious yet parsimonious neural architectures for the movement prediction of stock market indices using technical indicators as inputs. In the light of a sparse signal-to-noise ratio under the Efficient Market hypothesis, developing machine learning methods to predict the movement of a financial market using technical indicators has shown to be a challenging problem. To this end, the neural architecture search is posed as a multi-criteria optimization problem to balance the efficacy with the complexity of architectures. In addition, the implications of different dominant trading tendencies which may be present in the pre-COVID and within-COVID time periods are investigated. An $\epsilon-$ constraint framework is proposed as a remedy to extract any concordant information underlying the possibly conflicting pre-COVID data. Further, a new search paradigm, Two-Dimensional Swarms (2DS) is proposed for the multi-criteria neural architecture search, which explicitly integrates sparsity as an additional search dimension in particle swarms. A detailed comparative evaluation of the proposed approach is carried out by considering genetic algorithm and several combinations of empirical neural design rules with a filter-based feature selection method (mRMR) as baseline approaches. The results of this study convincingly demonstrate that the proposed approach can evolve parsimonious networks with better generalization capabilities.
On the Tractability of Neural Causal Inference
Oct 22, 2021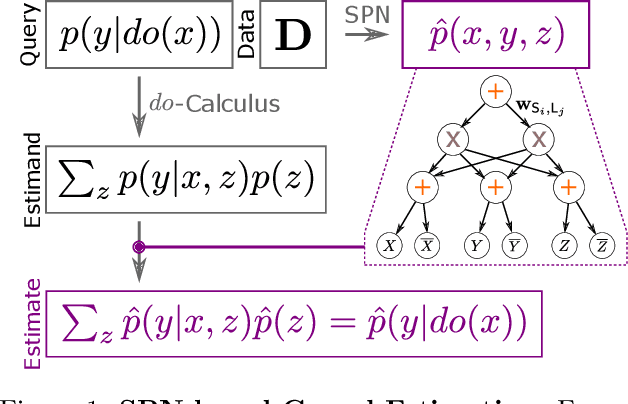

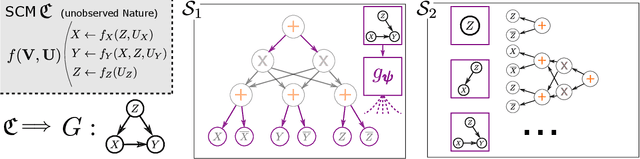
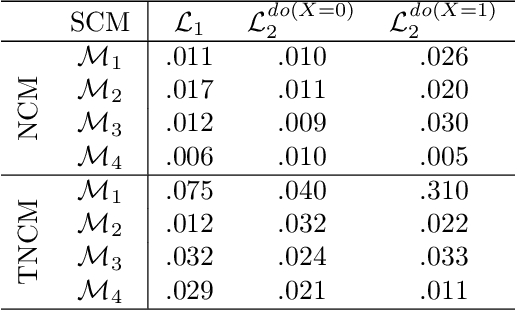
Roth (1996) proved that any form of marginal inference with probabilistic graphical models (e.g. Bayesian Networks) will at least be NP-hard. Introduced and extensively investigated in the past decade, the neural probabilistic circuits known as sum-product network (SPN) offers linear time complexity. On another note, research around neural causal models (NCM) recently gained traction, demanding a tighter integration of causality for machine learning. To this end, we present a theoretical investigation of if, when, how and under what cost tractability occurs for different NCM. We prove that SPN-based causal inference is generally tractable, opposed to standard MLP-based NCM. We further introduce a new tractable NCM-class that is efficient in inference and fully expressive in terms of Pearl's Causal Hierarchy. Our comparative empirical illustration on simulations and standard benchmarks validates our theoretical proofs.
TreeGCN-ED: Encoding Point Cloud using a Tree-Structured Graph Network
Oct 11, 2021

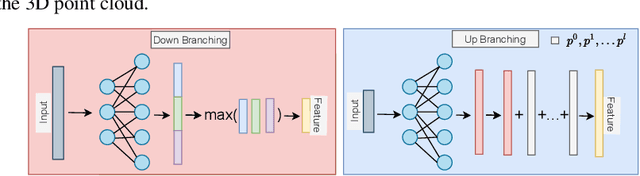
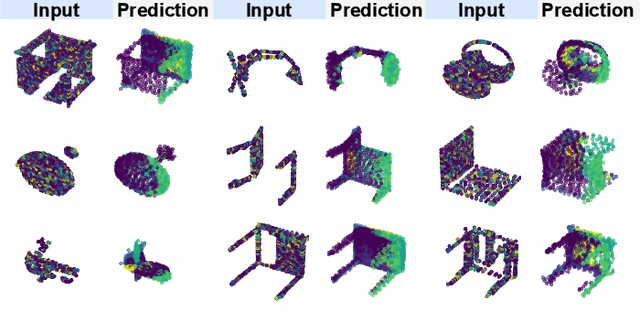
Point cloud is an efficient way of representing and storing 3D geometric data. Deep learning algorithms on point clouds are time and memory efficient. Several methods such as PointNet and FoldingNet have been proposed for processing point clouds. This work proposes an autoencoder based framework to generate robust embeddings for point clouds by utilizing hierarchical information using graph convolution. We perform multiple experiments to assess the quality of embeddings generated by the proposed encoder architecture and visualize the t-SNE map to highlight its ability to distinguish between different object classes. We further demonstrate the applicability of the proposed framework in applications like: 3D point cloud completion and Single image based 3D reconstruction.
Data-driven estimation of system norms via impulse response
Nov 04, 2021
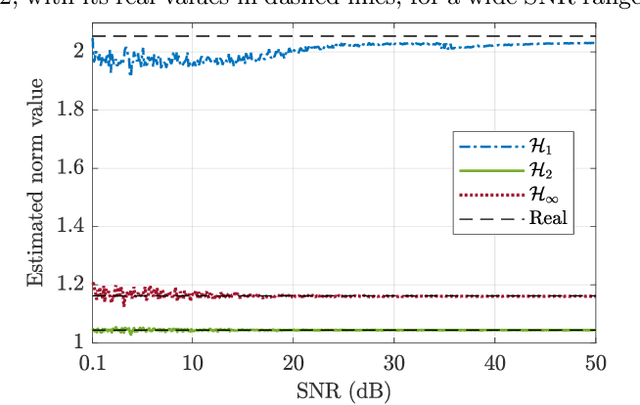
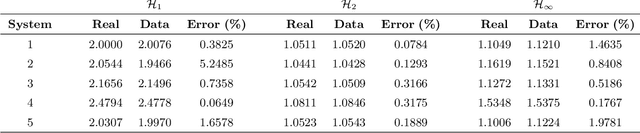
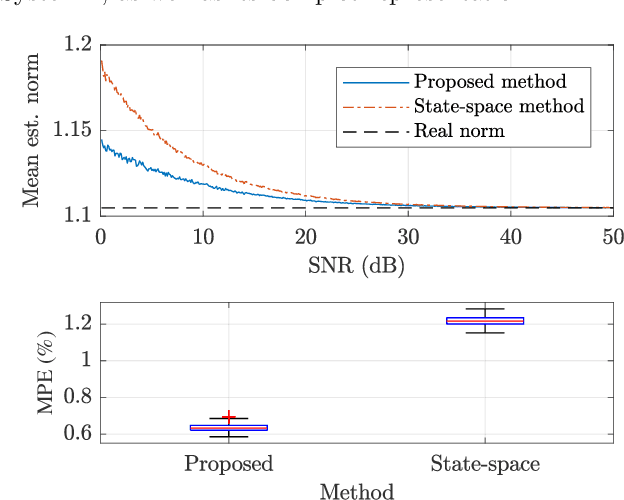
This paper proposes a method for estimating the norms of a system in a pure data-driven fashion based on their identified Impulse Response (IR) coefficients. The calculation of norms is briefly reviewed and the main expressions for the IR-based estimations are presented. As a case study, the $\mathcal{H}_{1}$, $\mathcal{H}_2$, and $\mathcal{H}_{\infty}$ norms of the sensitivity transfer function of five different discrete-time closed-loop systems are estimated for a Signal-to-Noise-Ratio (SNR) of 10 dB, achieving low percent error values if compared to the real value. To verify the influence of the noise amplitude, norms are estimated considering a wide range of SNR values, for a specific system, presenting low Mean Percent Error (MPE) if compared to the real norms. The proposed technique is also compared to an existing state-space-based method in terms of $\mathcal{H}_{\infty}$, through Monte Carlo, showing a reduction of approximately 48 % in the MPE for a wide range of SNR values.
Fast Estimation Method for the Stability of Ensemble Feature Selectors
Aug 03, 2021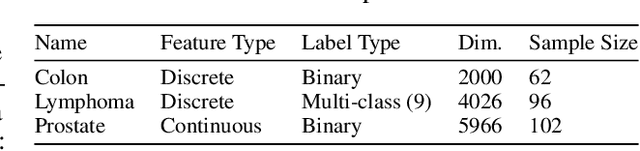
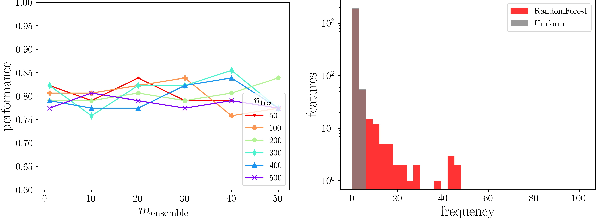

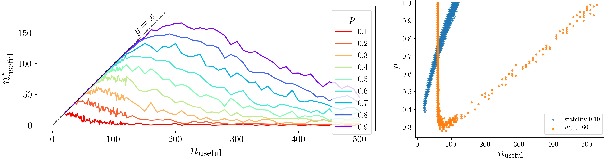
It is preferred that feature selectors be \textit{stable} for better interpretabity and robust prediction. Ensembling is known to be effective for improving the stability of feature selectors. Since ensembling is time-consuming, it is desirable to reduce the computational cost to estimate the stability of the ensemble feature selectors. We propose a simulator of a feature selector, and apply it to a fast estimation of the stability of ensemble feature selectors. To the best of our knowledge, this is the first study that estimates the stability of ensemble feature selectors and reduces the computation time theoretically and empirically.
Temporal Network Embedding via Tensor Factorization
Aug 22, 2021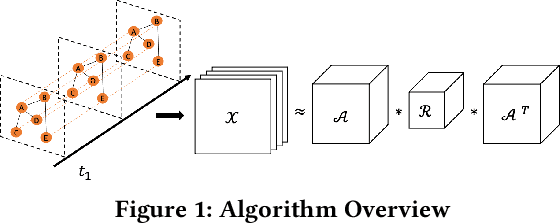
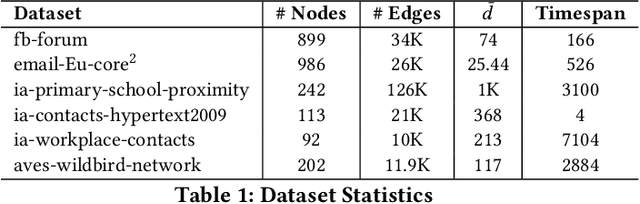
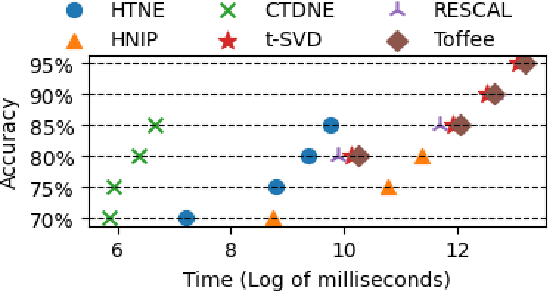
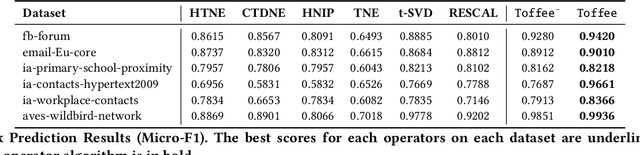
Representation learning on static graph-structured data has shown a significant impact on many real-world applications. However, less attention has been paid to the evolving nature of temporal networks, in which the edges are often changing over time. The embeddings of such temporal networks should encode both graph-structured information and the temporally evolving pattern. Existing approaches in learning temporally evolving network representations fail to capture the temporal interdependence. In this paper, we propose Toffee, a novel approach for temporal network representation learning based on tensor decomposition. Our method exploits the tensor-tensor product operator to encode the cross-time information, so that the periodic changes in the evolving networks can be captured. Experimental results demonstrate that Toffee outperforms existing methods on multiple real-world temporal networks in generating effective embeddings for the link prediction tasks.
Computer Model Calibration with Time Series Data using Deep Learning and Quantile Regression
Sep 08, 2020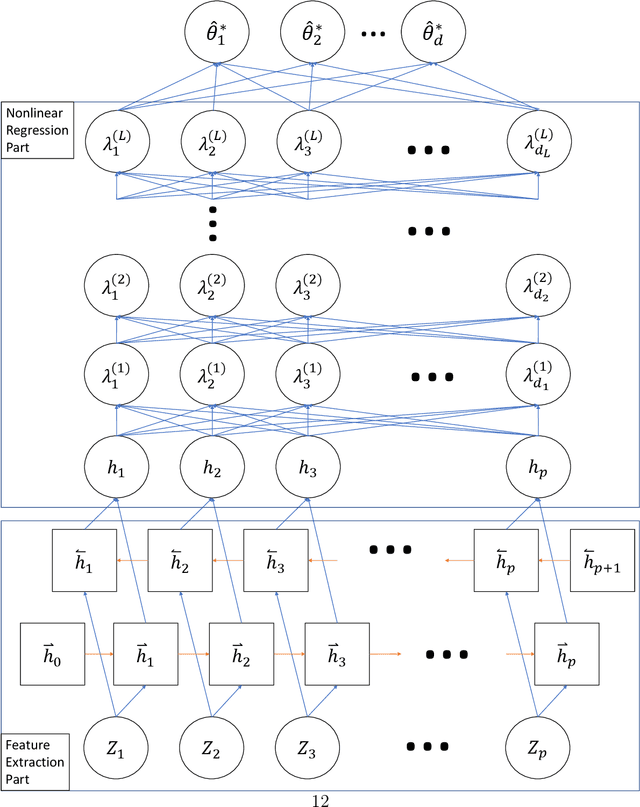
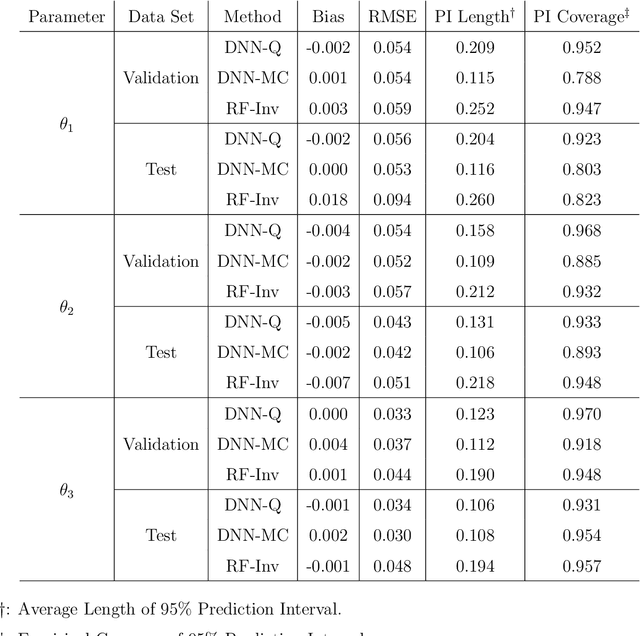
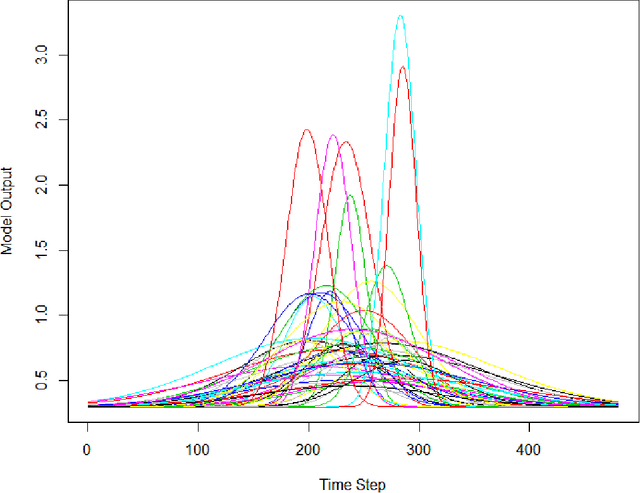
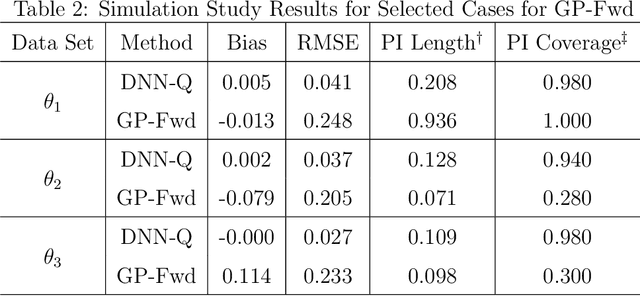
Computer models play a key role in many scientific and engineering problems. One major source of uncertainty in computer model experiment is input parameter uncertainty. Computer model calibration is a formal statistical procedure to infer input parameters by combining information from model runs and observational data. The existing standard calibration framework suffers from inferential issues when the model output and observational data are high-dimensional dependent data such as large time series due to the difficulty in building an emulator and the non-identifiability between effects from input parameters and data-model discrepancy. To overcome these challenges we propose a new calibration framework based on a deep neural network (DNN) with long-short term memory layers that directly emulates the inverse relationship between the model output and input parameters. Adopting the 'learning with noise' idea we train our DNN model to filter out the effects from data model discrepancy on input parameter inference. We also formulate a new way to construct interval predictions for DNN using quantile regression to quantify the uncertainty in input parameter estimates. Through a simulation study and real data application with WRF-hydro model we show that our approach can yield accurate point estimates and well calibrated interval estimates for input parameters.